文章目录
- 1 前言
- 2 什么是图像内容填充修复
- 3 原理分析
- 3.1 第一步:将图像理解为一个概率分布的样本
- 3.2 补全图像
- 3.3 快速生成假图像
- 3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构
- 3.5 使用G(z)生成伪图像
- 4 在Tensorflow上构建DCGANs
- 5 最后
1 前言
🔥 Hi,大家好,这里是丹成学长的毕设系列文章!
🔥 对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
🚩基于深度学习的图像修复 图像补全
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
2 什么是图像内容填充修复
内容识别填充(译注: Content-aware fill ,是 photoshop 的一个功能)是一个强大的工具,设计师和摄影师可以用它来填充图片中不想要的部分或者缺失的部分。在填充图片的缺失或损坏的部分时,图像补全和修复是两种密切相关的技术。有很多方法可以实现内容识别填充,图像补全和修复。
- 首先我们将图像理解为一个概率分布的样本。
- 基于这种理解,学*如何生成伪图片。
- 然后我们找到最适合填充回去的伪图片。

自动删除不需要的部分(海滩上的人)

最经典的人脸补充
补充前:

补充后:

3 原理分析
3.1 第一步:将图像理解为一个概率分布的样本
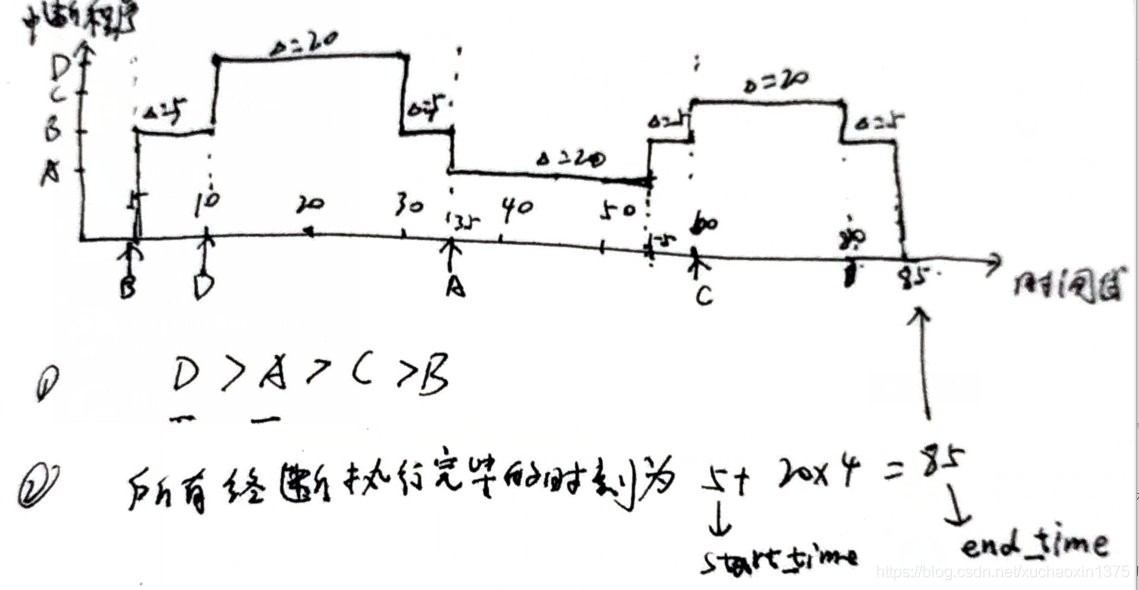
你是怎样补全缺失信息的呢?
在上面的例子中,想象你正在构造一个可以填充缺失部分的系统。你会怎么做呢?你觉得人类大脑是怎么做的呢?你使用了什么样的信息呢?
在博文中,我们会关注两种信息:
语境信息:你可以通过周围的像素来推测缺失像素的信息。
感知信息:你会用“正常”的部分来填充,比如你在现实生活中或其它图片上看到的样子。
两者都很重要。没有语境信息,你怎么知道填充哪一个进去?没有感知信息,通过同样的上下文可以生成无数种可能。有些机器学*系统看起来“正常”的图片,人类看起来可能不太正常。
如果有一种确切的、直观的算法,可以捕获前文图像补全步骤介绍中提到的两种属性,那就再好不过了。对于特定的情况,构造这样的算法是可行的。但是没有一般的方法。目前最好的解决方案是通过统计和机器学习来得到一个类似的技术。
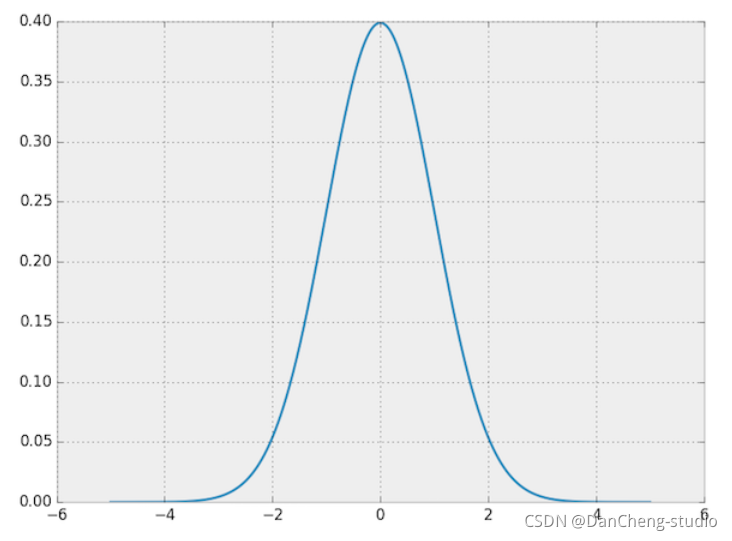
从这个分布中采样,就可以得到一些数据。需要搞清楚的是PDF和样本之间的联系。
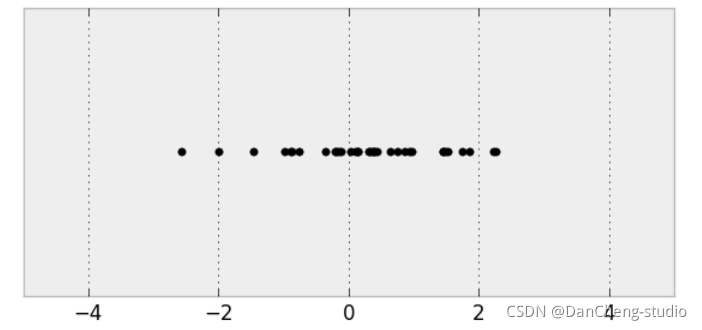
从正态分布中的采样
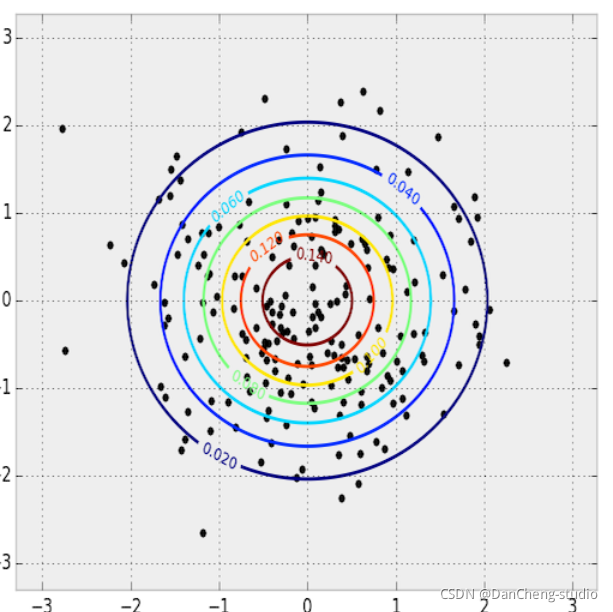
2维图像的PDF和采样。 PDF 用等高线图表示,样本点画在上面。
3.2 补全图像
首先考虑多变量正态分布, 以求得到一些启发。给定 x=1 , 那么 y 最可能的值是什么?我们可以固定x的值,然后找到使PDF最大的 y。
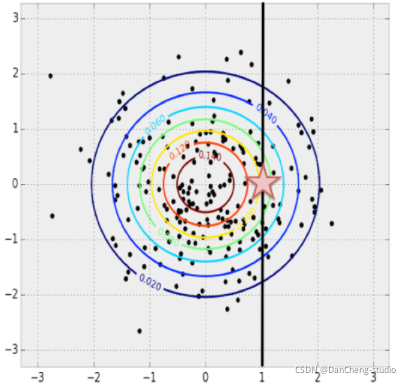
在多维正态分布中,给定x,得到最大可能的y
这个概念可以很自然地推广到图像概率分布。我们已知一些值,希望补全缺失值。这可以简单理解成一个最大化问题。我们搜索所有可能的缺失值,用于补全的图像就是可能性最大的值。
从正态分布的样本来看,只通过样本,我们就可以得出PDF。只需挑选你喜欢的 统计模型, 然后拟合数据即可。
然而,我们实际上并没有使用这种方法。对于简单分布来说,PDF很容易得出来。但是对于更复杂的图像分布来说,就十分困难,难以处理。之所以复杂,一部分原因是复杂的条件依赖:一个像素的值依赖于图像中其它像素的值。另外,最大化一个一般的PDF是一个非常困难和棘手的非凸优化问题。
3.3 快速生成假图像
在未知概率分布情况下,学习生成新样本
除了学如何计算PDF之外,统计学中另一个成熟的想法是学怎样用 生成模型 生成新的(随机)样本。生成模型一般很难训练和处理,但是后来深度学*社区在这个领域有了一个惊人的突破。Yann LeCun 在这篇 Quora 回答中对如何进行生成模型的训练进行了一番精彩的论述,并将它称为机器学习领域10年来最有意思的想法。
3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构
使用微步长卷积,对图像进行上采样
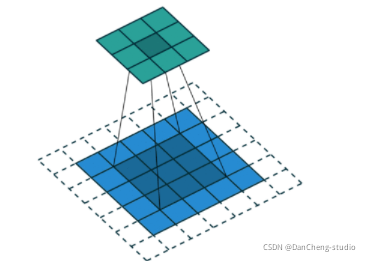
现在我们有了微步长卷积结构,可以得到G(z)的表达,以一个向量z∼pz 作为输入,输出一张 64x64x3 的RGB图像。
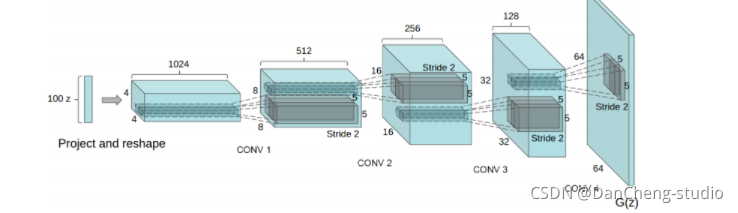
3.5 使用G(z)生成伪图像
基于DCGAN的人脸代数运算 DCGAN论文 。

4 在Tensorflow上构建DCGANs
部分代码:
def generator(self, z):
self.z_, self.h0_w, self.h0_b = linear(z, self.gf_dim*8*4*4, 'g_h0_lin', with_w=True)
self.h0 = tf.reshape(self.z_, [-1, 4, 4, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
self.h1, self.h1_w, self.h1_b = conv2d_transpose(h0,
[self.batch_size, 8, 8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
h2, self.h2_w, self.h2_b = conv2d_transpose(h1,
[self.batch_size, 16, 16, self.gf_dim*2], name='g_h2', with_w=True)
h2 = tf.nn.relu(self.g_bn2(h2))
h3, self.h3_w, self.h3_b = conv2d_transpose(h2,
[self.batch_size, 32, 32, self.gf_dim*1], name='g_h3', with_w=True)
h3 = tf.nn.relu(self.g_bn3(h3))
h4, self.h4_w, self.h4_b = conv2d_transpose(h3,
[self.batch_size, 64, 64, 3], name='g_h4', with_w=True)
return tf.nn.tanh(h4)
def discriminator(self, image, reuse=False):
if reuse:
tf.get_variable_scope().reuse_variables()
h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))
h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))
h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))
h4 = linear(tf.reshape(h3, [-1, 8192]), 1, 'd_h3_lin')
return tf.nn.sigmoid(h4), h4
当我们初始化这个类的时候,将要用到这两个函数来构建模型。我们需要两个判别器,它们共享(复用)参数。一个用于来自数据分布的小批图像,另一个用于生成器生成的小批图像。
self.G = self.generator(self.z)
self.D, self.D_logits = self.discriminator(self.images)
self.D_, self.D_logits_ = self.discriminator(self.G, reuse=True)
接下来,我们定义损失函数。这里我们不用求和,而是用D的预测值和真实值之间的交叉熵(cross entropy),因为它更好用。判别器希望对所有“真”数据的预测都是1,对所有生成器生成的“伪”数据的预测都是0。生成器希望判别器对两者的预测都是1 。
self.d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits,
tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,
tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,
tf.ones_like(self.D_)))
self.d_loss = self.d_loss_real + self.d_loss_fake
下面我们遍历数据。每一次迭代,我们采样一个小批数据,然后使用优化器来更新网络。有趣的是,如果G只更新一次,鉴别器的损失不会变成0。另外,我认为最后调用 d_loss_fake 和 d_loss_real 进行了一些不必要的计算, 因为这些值在 d_optim 和 g_optim 中已经计算过了。 作为Tensorflow 的一个联系,你可以试着优化这一部分,并发送PR到原始的repo。
for epoch in xrange(config.epoch):
...
for idx in xrange(0, batch_idxs):
batch_images = ...
batch_z = np.random.uniform(-1, 1, [config.batch_size, self.z_dim]) \
.astype(np.float32)
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={ self.images: batch_images, self.z: batch_z })
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
errD_fake = self.d_loss_fake.eval({self.z: batch_z})
errD_real = self.d_loss_real.eval({self.images: batch_images})
errG = self.g_loss.eval({self.z: batch_z})