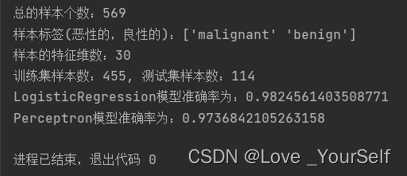
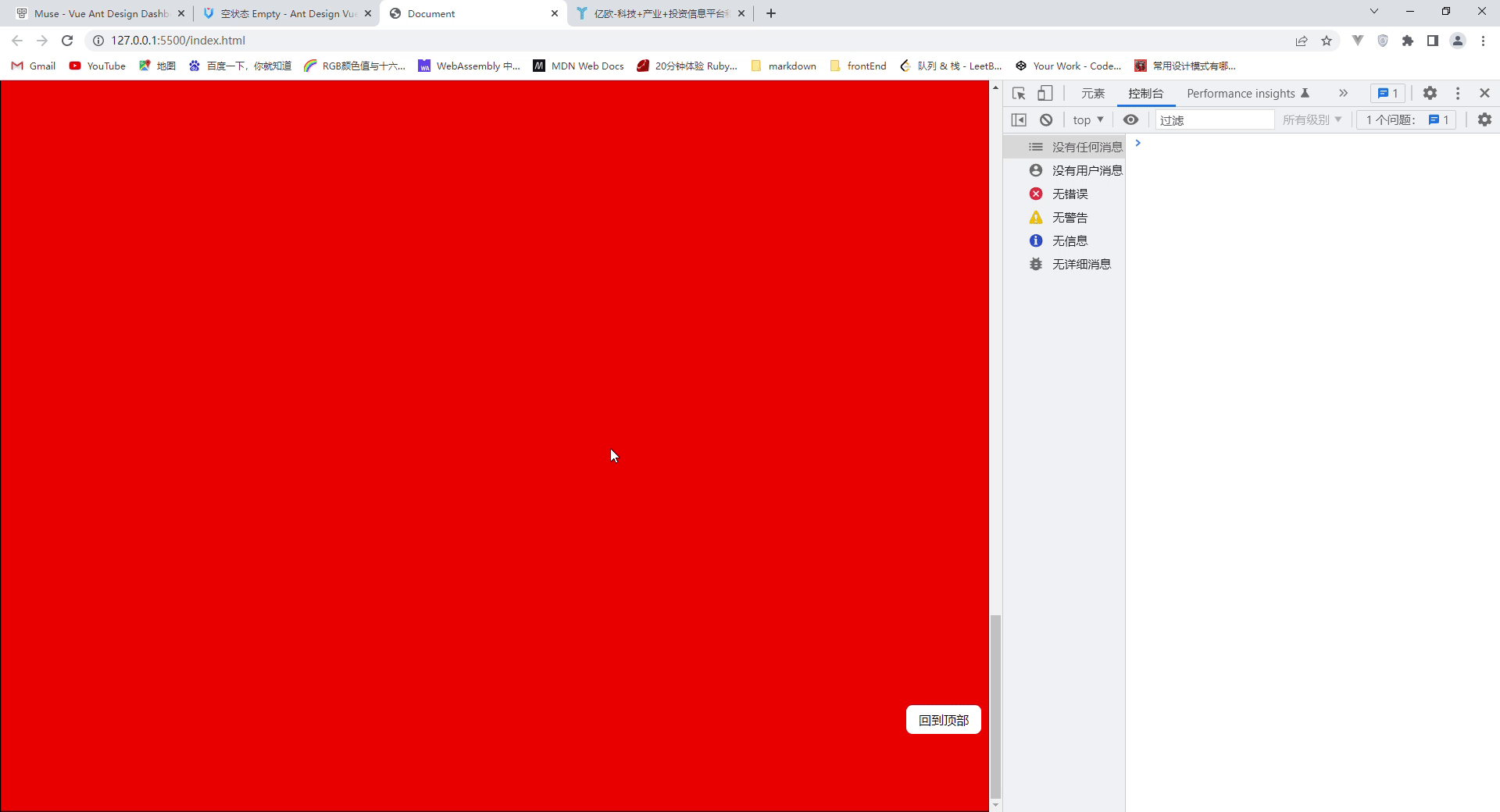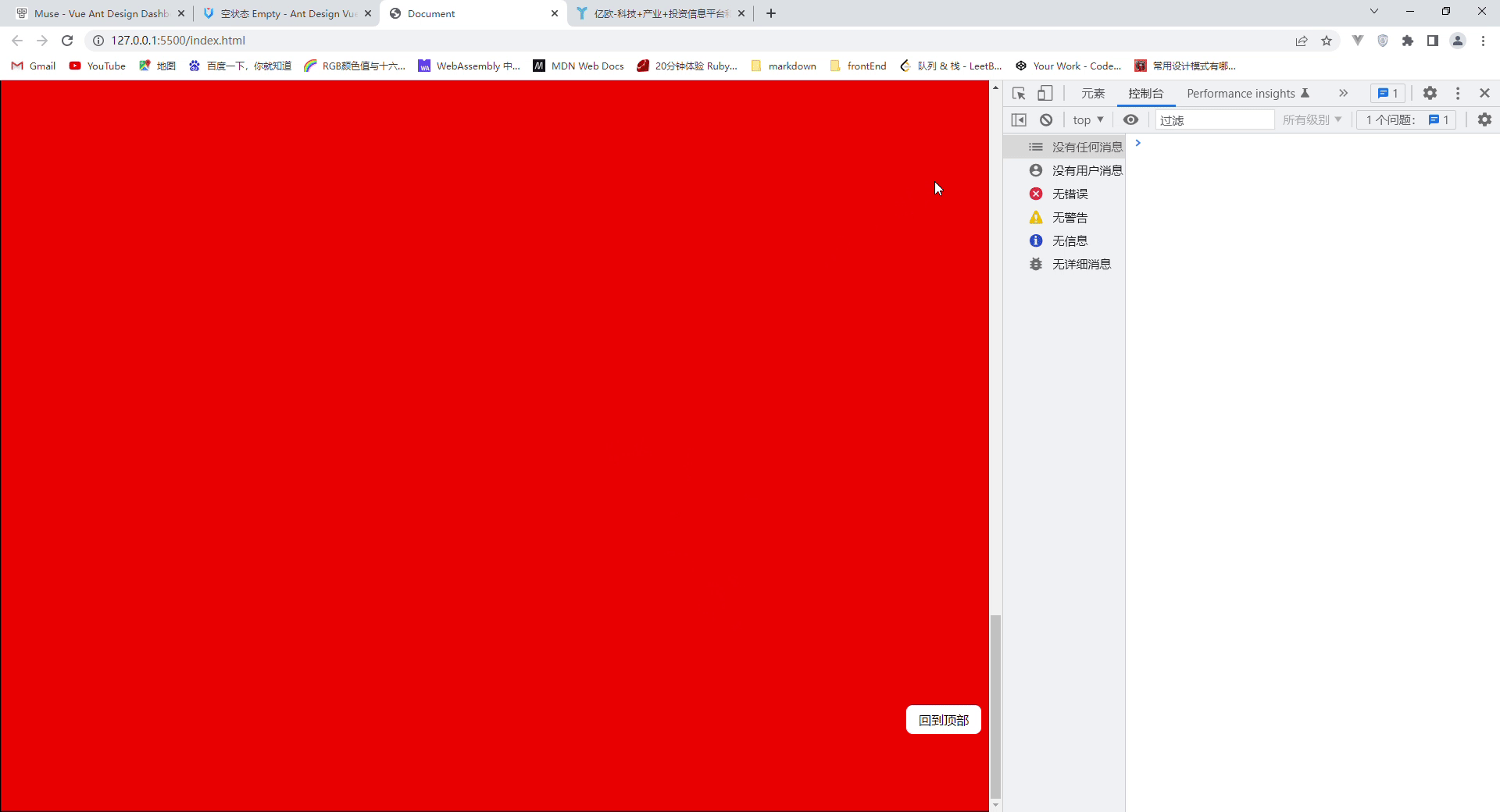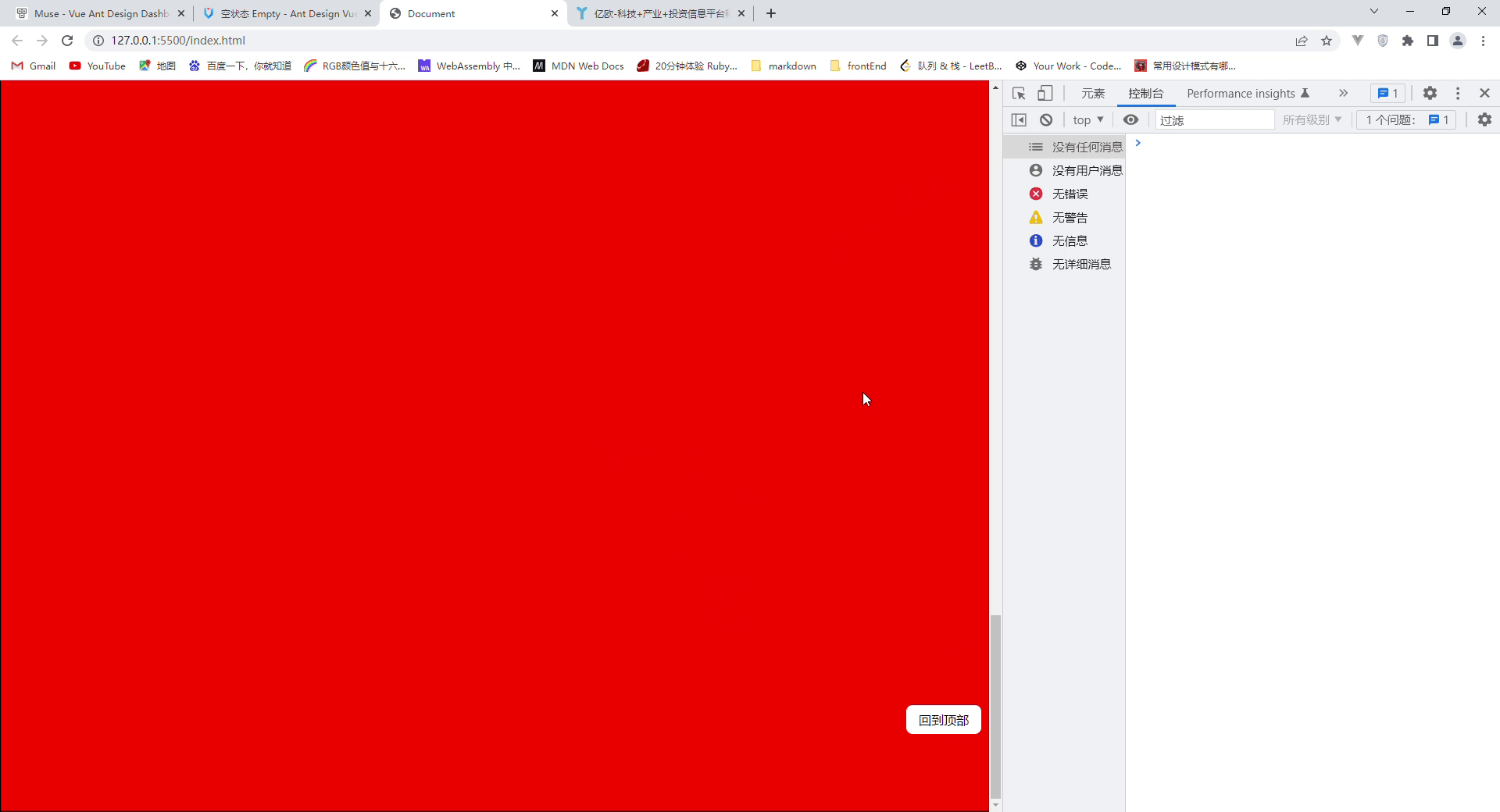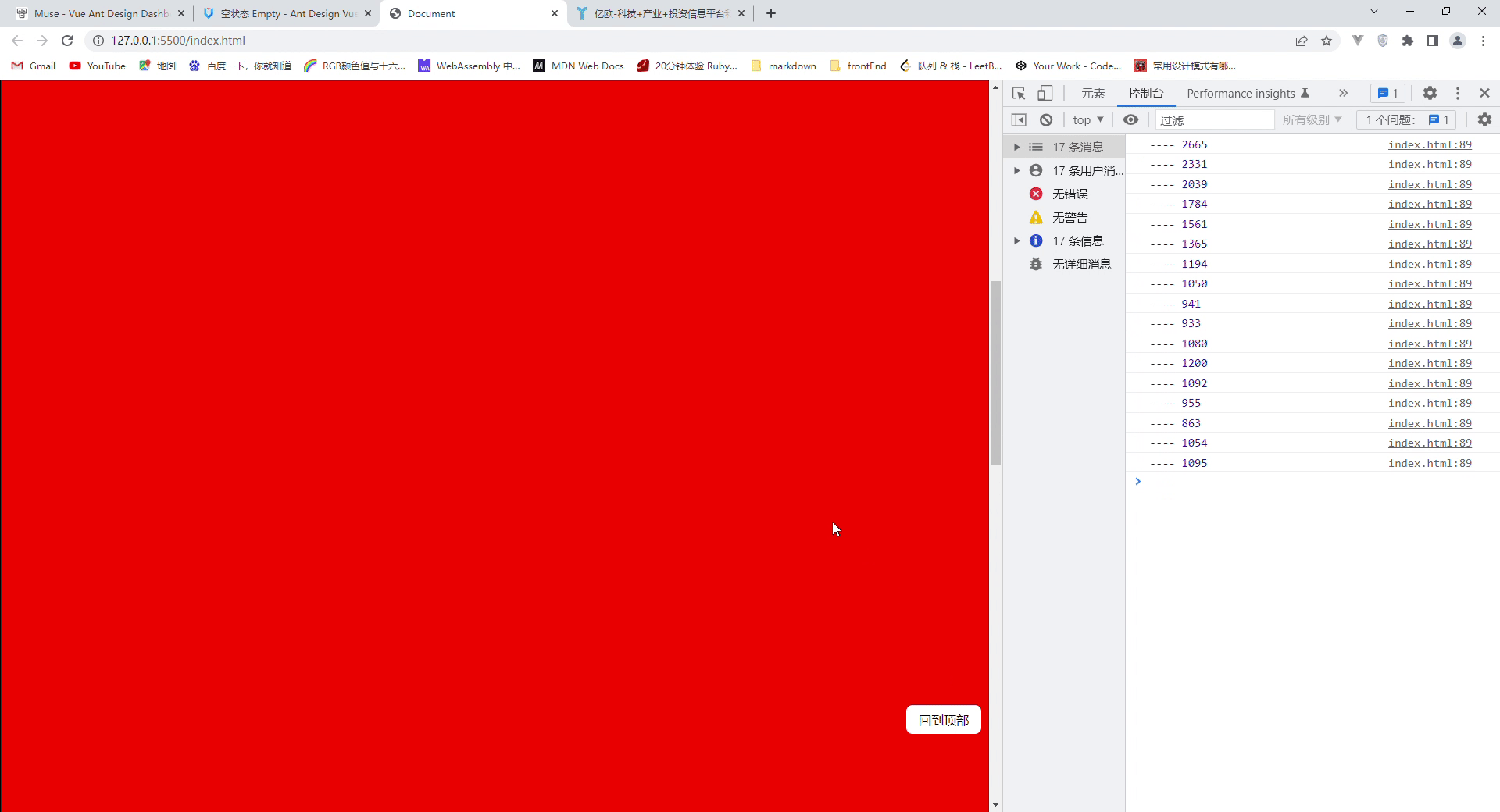
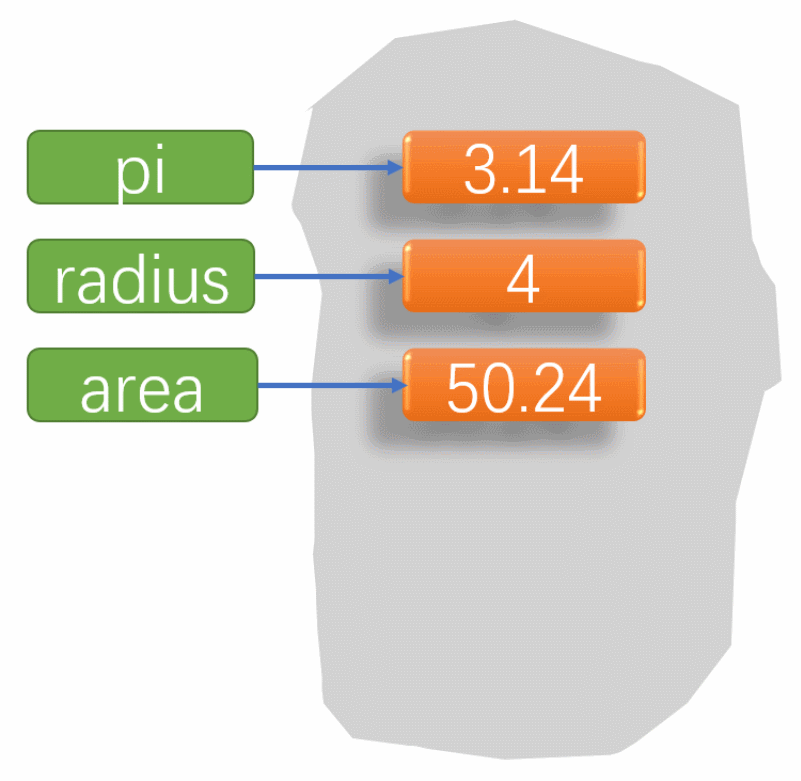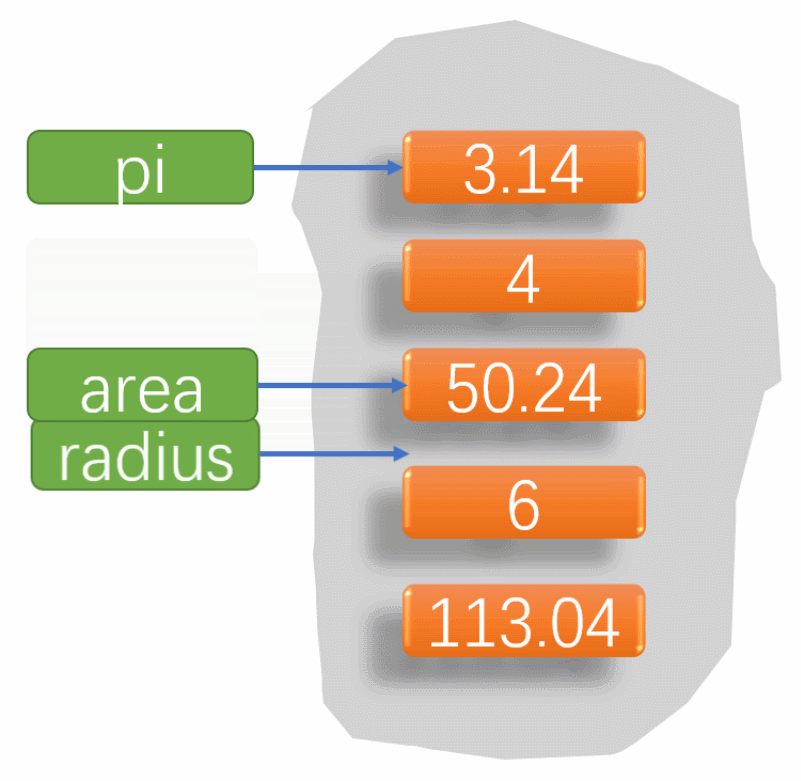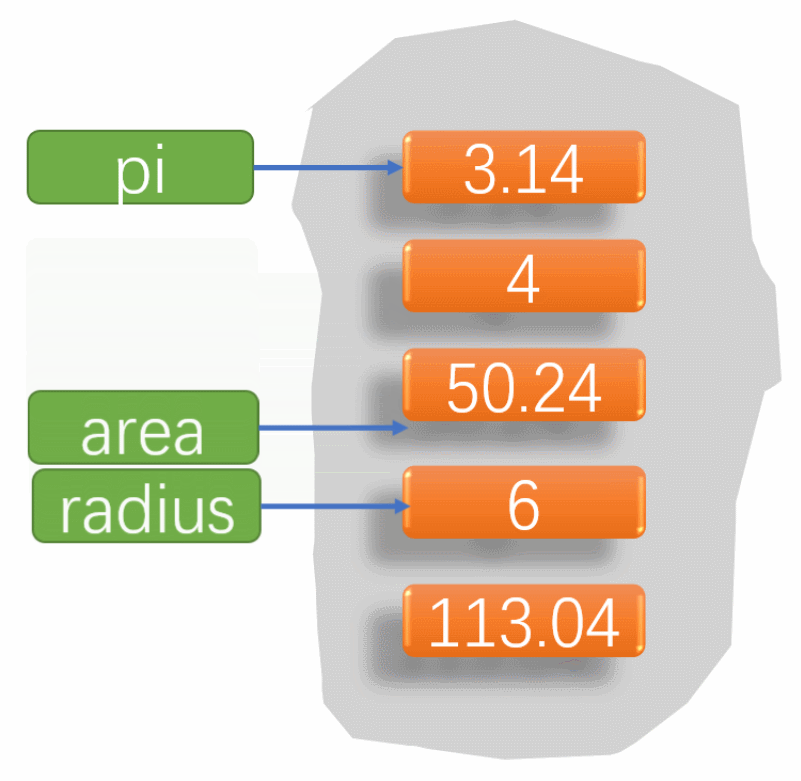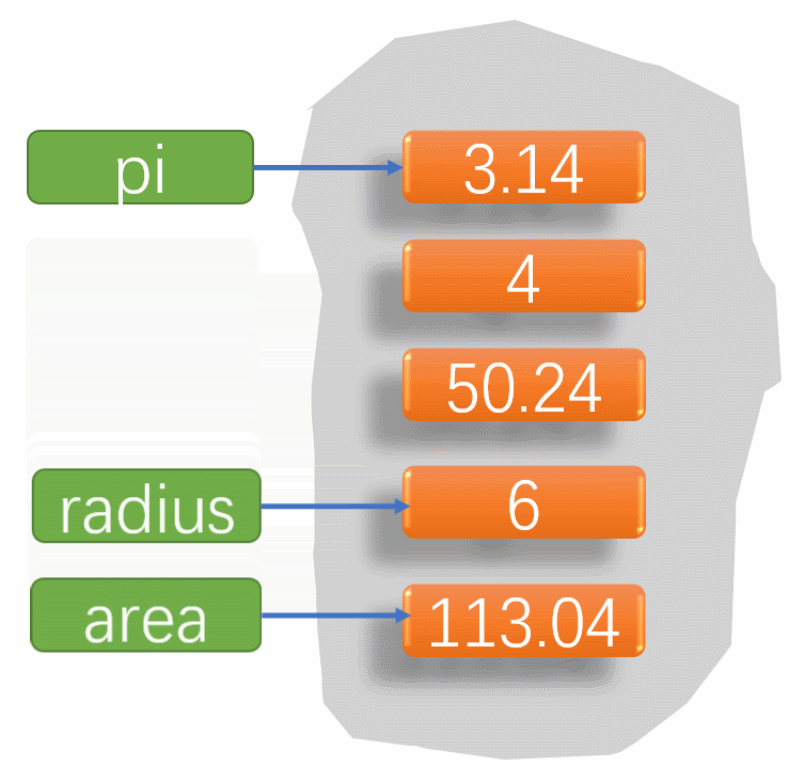
本文参考:5-剪枝后模型参数赋值_哔哩哔哩_bilibiliz
https://github.com/foolwood/pytorch-slimming
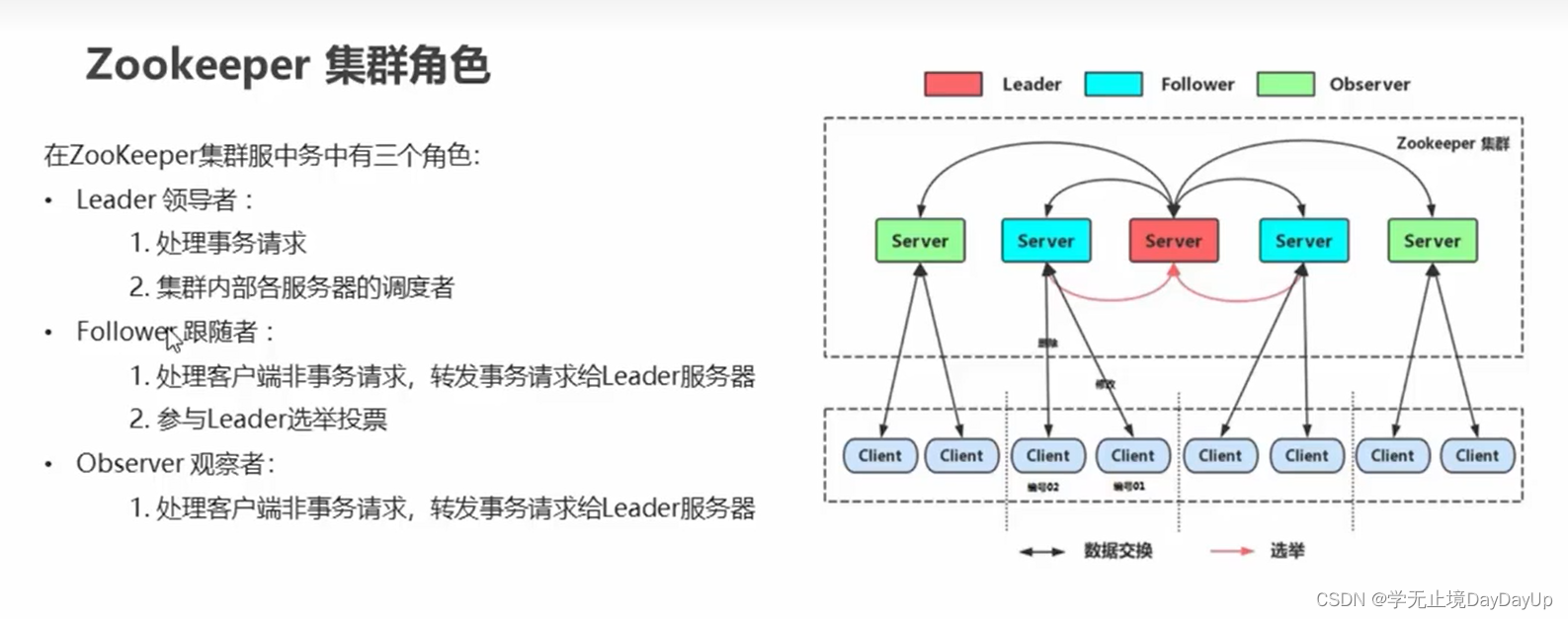
一、模型剪枝理论说明
论文:Learning Efficient Convolutional Networks through Network Slimming
(1)卷积后得到多个特征图(channel=64, 128, 256…),这些图不一定都重要,所以量化计算特征图的重要性
(2)训练模型的时候需要加入一些策略,让权重参数有明显的大小之分,从而筛选重要的特征图
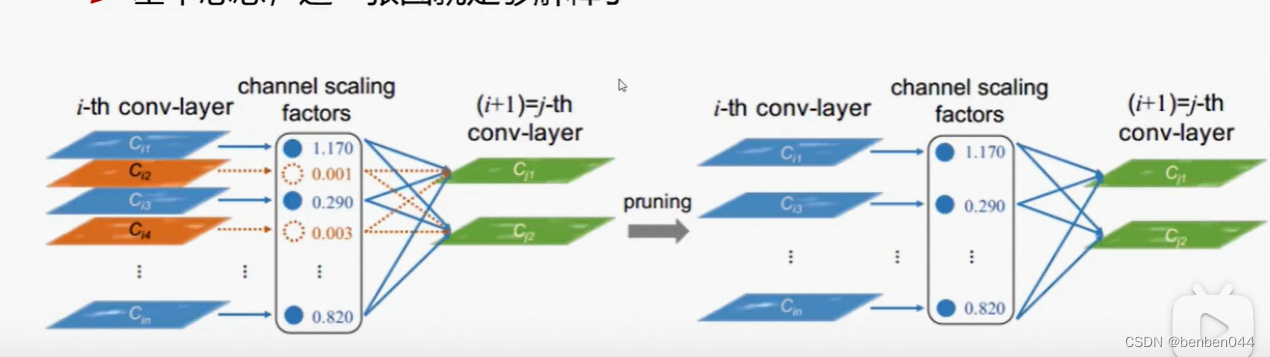
Channel scaling factors里面的数值为特征图的打分,直观理解为分值大的特征图需要保留,分值小的特征图可以去掉。
二、计算特征图重要性
Network slimming ,利用BN层中的缩放因子Ƴ
BN的理论支持:
![]() ,使得数据为(0,1)正态分布。
,使得数据为(0,1)正态分布。
整体感觉是一个归一化操作,但是BN中需要额外引入两个可训练的参数:Ƴ和β
BatchNorm的本质:
(1)BN要做的就是把越来越偏离的分布给拉回来
(2)再重新规范化到均值为0方差为1的标准正态分布
(3)这样能够使得激活函数在数值层面更敏感,训练更快。
(4)产生的问题:经过BN之后,把数值分布强制在了非线性函数的线性区域中。
针对第(3)点解释:
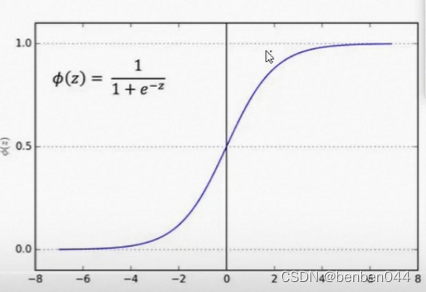
在激活函数中,两边处于饱和区域不敏感,接近于0位置非饱和处于敏感区域。
针对第(4)点解释:
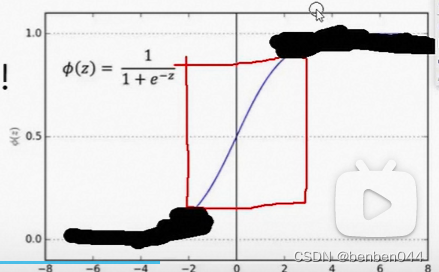
BN将数据强制压缩到中间红色区域的线性部分,F(x)只做仿射变化,F=sigmoid,多个仿射变化的叠加仍然是仿射变化,添加再多隐藏层与单层神经网络是等价的。
所以,BN需要保证一些非线性,对规范后的结果再进行变化。
添加两个参数后重新训练:
![]() ,这两个参数是网络训练过程中得到的,而不是超参给的。
,这两个参数是网络训练过程中得到的,而不是超参给的。
该公式相当于BN的逆变换,
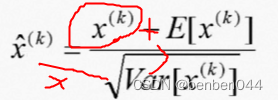
相当于对正态分布进行一些改变,拉动一下,变一下形状,做适当的还原。
Ƴ值越大越重要,那么该特征图调整的幅度越大,说明该特征图越重要。
三、让特征图重要度两极分化更明显
使用L1正则化对参数进行稀疏操作。

L1求导后为:sign(Θ),相当于稳定前进,都为1,最后学成0了
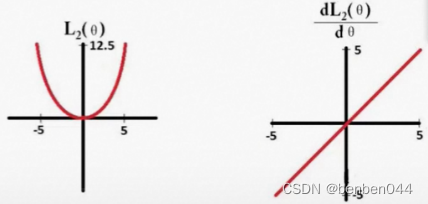
L2求导后为:Θ,相当于越来越慢,很多参数都接近0,平滑。
论文核心:

四、剪枝流程
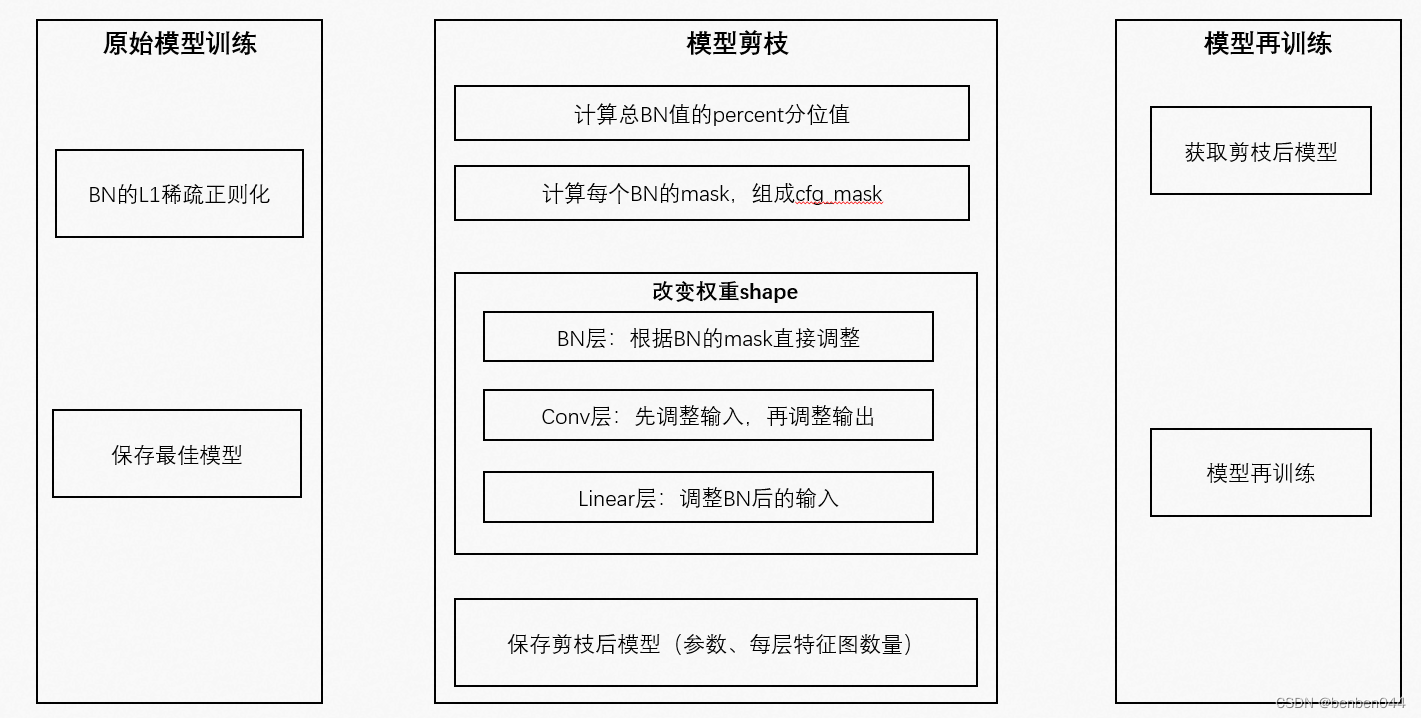
使用到的vgg模型架构:
import torch
import torch.nn as nn
import math
from torch.autograd import Variable
class vgg(nn.Module):
def __init__(self, dataset='cifar10', init_weights=True, cfg=None):
super(vgg, self).__init__()
if cfg is None:
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512]
self.feature = self.make_layers(cfg, True)
if dataset == 'cifar10':
num_classes = 10
elif dataset == 'cifar100':
num_classes = 100
self.classifier = nn.Linear(cfg[-1], num_classes)
if init_weights:
self._initialize_weights()
def make_layers(self, cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1, bias=False)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
def forward(self, x):
x = self.feature(x)
x = nn.AvgPool2d(2)(x)
x = x.view(x.size(0), -1)
y = self.classifier(x)
return y
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(0.5)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
if __name__ == '__main__':
net = vgg()
x = Variable(torch.FloatTensor(16, 3, 40, 40))
y = net(x)
print(y.data.shape)1、原始模型训练:
(1)BN的L1稀疏正则化:使用次梯度下降法,对BN层的权重进行再调整
(2)训练完成后主要保存原始模型的参数信息
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from vgg import vgg
import shutil
from tqdm import tqdm
learning_rate = 0.1
momentum = 0.9
weight_decay = 1e-4
epochs = 3
log_interval = 100
batch_size = 100
sparsity_regularization = True
scale_sparse_rate = 0.0001
checkpoint_model_path = 'checkpoint,pth.tar'
best_model_path = 'model_best.pth.tar'
train_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('D:\\ai_data\\cifar10', train=True, download=True,
transform=transforms.Compose([
transforms.Pad(4),
transforms.RandomCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('D:\\ai_data\\cifar10', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=batch_size, shuffle=True)
model = vgg()
model.cuda()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum, weight_decay=weight_decay)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(tqdm(train_loader)):
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
if sparsity_regularization:
updateBN()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.1f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test():
model.eval()
test_loss = 0
correct = 0
for data, target in tqdm(test_loader):
data , target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
test_loss += F.cross_entropy(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.1f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
def save_checkpoint(state, is_best, filename=checkpoint_model_path):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, best_model_path)
def updateBN():
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(scale_sparse_rate * torch.sign(m.weight.data)) # L1,使用次梯度下降
best_prec = 0
for epoch in range(epochs):
train(epoch)
prec = test()
is_best = prec > best_prec
best_prec = max(prec, best_prec)
save_checkpoint({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'best_prec': best_prec,
'optimizer': optimizer.state_dict()
}, is_best)
2、模型剪枝
(1)剪枝过程主要分为两部分:第一部分是计算mask,第二部分是根据mask调整各层的shape
(2)BN层通道数:Conv -> BN -> ReLU -> MaxPool--à Linear,所以BN的输入维度对应Conv的输出通道数
(3)BN层总通道数:将所有BN层的通道数进行汇总
(4)BN层剪枝百分位:取总通道数的百分位得到具体的float值,大于该值的通道对应的mask置为1,否则对应的mask置为0
(5)改变权重weight:BN层抽取mask为1的通道数的值,该操作会改变BN的shape,从而上下游操作中的Conv和Linear也需要被动做出调整,对Maxpool和ReLu的通道数无影响
(6)Conv层的参数为[out_channels, in_channels, kernel_size1, kernel_size2],所以需要调整两次,先对in_channels进行调整,再对out_channels进行调整。Conv初始输入为RGB的3通道。
假如计算出的保留通道数信息为:
[48, 60, 115, 118, 175, 163, 141, 130, 259, 267, 258, 249, 225, 212, 234, 97]
Conv的输入输出变为:
In shape: 3 Out shape:48
In shape: 48 Out shape:60
In shape: 60 Out shape:115
In shape: 115 Out shape:118
……
In shape: 234 Out shape:97
(7)保存模型时,一方面把有用的参数信息保存了下来,同时剪枝后的最新的模型结构参数也保存了,方便后续再训练时构建新的模型结构
import os
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import datasets, transforms
from vgg import vgg
import numpy as np
from tqdm import tqdm
percent = 0.5
batch_size = 100
raw_model_path = 'model_best.pth.tar'
save_model_path = 'prune_model.pth.tar'
model = vgg()
model.cuda()
if os.path.isfile(raw_model_path):
print("==> loading checkpoint '{}'".format(raw_model_path))
checkpoint = torch.load(raw_model_path)
start_epoch = checkpoint['epoch']
best_prec = checkpoint['best_prec']
model.load_state_dict(checkpoint['state_dict'])
print("==> loaded checkpoint '{}'(epoch {}) Prec:{:f}".format(raw_model_path, start_epoch, best_prec) )
print(model)
total = 0
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
total += m.weight.data.shape[0]
bn = torch.zeros(total)
index = 0
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
size = m.weight.data.shape[0]
bn[index : index + size] = m.weight.data.abs().clone()
index += size
y, i = torch.sort(bn)
thre_index = int(total * percent)
thre = y[thre_index]
pruned = 0
cfg = []
cfg_mask = []
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):
weight_copy = m.weight.data.clone()
mask = weight_copy.abs().gt(thre).float().cuda()
pruned += mask.shape[0] - torch.sum(mask)
m.weight.data.mul_(mask)
m.bias.data.mul_(mask)
cfg.append(int(torch.sum(mask)))
cfg_mask.append(mask.clone())
print('layer index: {:d} \t total channel: {:d} \t remaining channel: {:d}'.format(k, mask.shape[0], int(torch.sum(mask))))
elif isinstance(m, nn.MaxPool2d):
cfg.append('M')
pruned_ratio = pruned / total
print('pruned_ratio: {},Pre-processing Successful!'.format(pruned_ratio))
# simple test model after Pre-processing prune(simple set BN scales to zeros)
def test():
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('D:\\ai_data\\cifar10', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=batch_size, shuffle=True)
model.eval()
correct = 0
for data, target in tqdm(test_loader):
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
print('\nTest set: Accuracy: {}/{} ({:.1f}%)\n'.format(
correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
test()
# make real prune
print(cfg)
new_model = vgg(cfg=cfg)
new_model.cuda()
layer_id_in_cfg = 0 # cfg中的层数索引
start_mask = torch.ones(3)
end_mask = cfg_mask[layer_id_in_cfg]
for [m0, m1] in zip(model.modules(), new_model.modules()):
if isinstance(m0, nn.BatchNorm2d):
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
m1.weight.data = m0.weight.data[idx1].clone()
m1.bias.data = m0.bias.data[idx1].clone()
m1.running_mean = m0.running_mean[idx1].clone()
m1.running_var = m0.running_var[idx1].clone()
layer_id_in_cfg += 1
start_mask = end_mask.clone()
if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC
end_mask = cfg_mask[layer_id_in_cfg]
elif isinstance(m0, nn.Conv2d):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: {:d} Out shape:{:d}'.format(idx0.shape[0], idx1.shape[0]))
w = m0.weight.data[:, idx0, :, :].clone()
w = w[idx1, :, :, :].clone()
m1.weight.data = w.clone()
elif isinstance(m0, nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
m1.weight.data = m0.weight.data[:, idx0].clone()
torch.save({'cfg': cfg, 'state_dict': new_model.state_dict()}, save_model_path)
print(new_model)
model = new_model
test()
3、再训练
剪枝后保存的模型参数相当于训练过程中的一个checkpoint,根据新的模型结构,在此checkpoint的基础上再进行训练,直到得到满意的指标。
import torch
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from vgg import vgg
import shutil
from tqdm import tqdm
learning_rate = 0.1
momentum = 0.9
weight_decay = 1e-4
epochs = 3
log_interval = 100
batch_size = 100
sparsity_regularization = True
scale_sparse_rate = 0.0001
prune_model_path = 'prune_model.pth.tar'
prune_checkpoint_path = 'pruned_checkpoint.pth.tar'
prune_best_model_path = 'pruned_model_best.pth.tar'
train_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('D:\\ai_data\\cifar10', train=True, download=True,
transform=transforms.Compose([
transforms.Pad(4),
transforms.RandomCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('D:\\ai_data\\cifar10', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=batch_size, shuffle=True)
checkpoint = torch.load(prune_model_path)
model = vgg(cfg=checkpoint['cfg'])
model.cuda()
model.load_state_dict(checkpoint['state_dict'])
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum, weight_decay=weight_decay)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(tqdm(train_loader)):
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.1f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test():
model.eval()
test_loss = 0
correct = 0
for data, target in tqdm(test_loader):
data , target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
test_loss += F.cross_entropy(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.1f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
def save_checkpoint(state, is_best, filename=prune_checkpoint_path):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, prune_best_model_path)
best_prec = 0
for epoch in range(epochs):
train(epoch)
prec = test()
is_best = prec > best_prec
best_prec = max(prec, best_prec)
save_checkpoint({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'best_prec': best_prec,
'optimizer': optimizer.state_dict()
}, is_best)
4、原始模型和剪枝后模型比较:
在cifar10上通过vgg模型分别迭代3次。
原始模型为156M,准确率为70%左右
剪枝后模型为36M,准确率为76%左右
备注:最好是原始模型达到顶峰时再剪枝,此时再比较剪枝前后的准确率影响。