【文章简介】
在信息技术的现代背景下,高效地处理和分析文本数据对于知识获取和决策支持至关重要。Markdown文件因其易读性和高效性,在文档编写和知识共享中占据了重要地位。然而,传统的文本处理方法往往忽视了Markdown的结构化特性,未能充分挖掘文本的深层含义和主题。本文介绍了一种创新的结构化分割方法,利用Langchain技术,通过MarkdownHeaderTextSplitter工具,根据标题层级进行精确分割,同时保留文本的上下文和结构信息。这种方法特别适合处理报告、教程等结构化文档,有助于提升文本向量化(embedding)的效果。
正如Pinecone所指出的,当整个段落或文档被嵌入时,嵌入过程会同时考虑整体上下文和文本内部句子与短语之间的关系,从而产生更全面的向量表示,捕获文本的更广泛含义和主题。
此外,RecursiveCharacterTextSplitter工具适用于需要均匀文本块的自然语言处理任务,而UnstructuredMarkdownLoader则将Markdown文件转换为Langchain对象,通过mode="elements"选项,进一步增强了文本块的独立性和分析的灵活性。这种方法不仅提高了文本分析的效率和准确性,而且通过优化embedding过程,显著增强了RAG(Retrieval-Augmented
Generation)效果,为Markdown文件的深入利用和知识管理开辟了新路径。
MarkDown
Markdown是一种轻量级标记语言,用于使用纯文本编辑器创建格式化文本。
使用MarkdownHeaderTextSplitter获取markdown结构
调用方法
%pip install -qU langchain-text-splitters
我们可以自己规定分割的chunksize、标题层级
标题层级分割
# 1 标题
## 1.1 标题
### 1.1.1 标题
#### 1.1.1.1 标题
1.1.1.1 内容
# 2 标题
2 内容
## 2.2 标题
2.2 内容
# 读取markdown内容
content_path= r"xxx.md"
with open(content_path, "r") as f:
page_content = f.read()
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = page_content
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
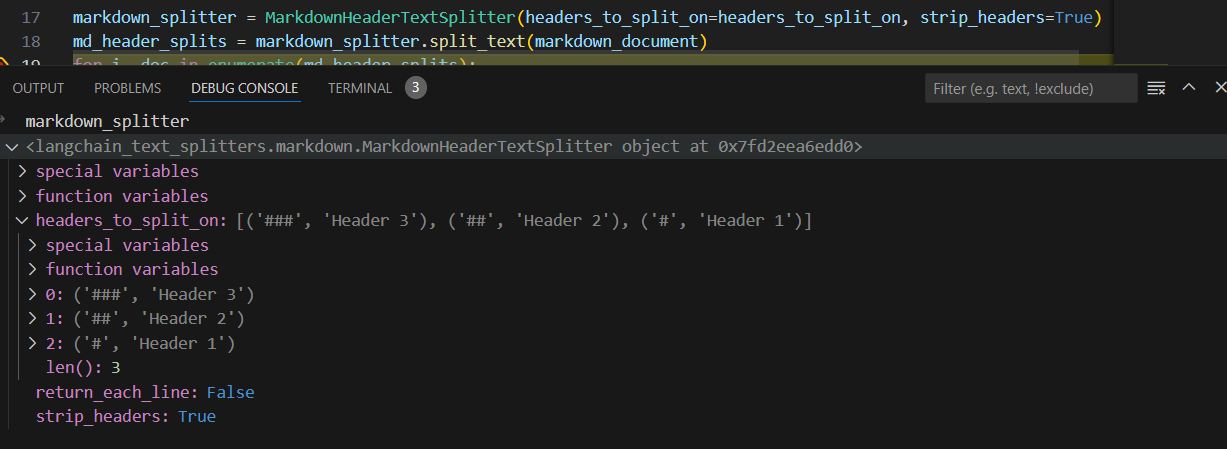
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
for i, doc in enumerate(md_header_splits):
print("-------------------------------------------------------")
print(f"Document {i+1}:")
print("Page content:")
print(doc.page_content)
print("Metadata:")
for key, value in doc.metadata.items():
print(f"{key}: {value}")
print("\n")
-------------------------------------------------------
Document 1:
Page content:
#### 1.1.1.1 标题
1.1.1.1 内容
Metadata:
Header 1: 1 标题
Header 2: 1.1 标题
Header 3: 1.1.1 标题
-------------------------------------------------------
Document 2:
Page content:
2 内容
Metadata:
Header 1: 2 标题
-------------------------------------------------------
Document 3:
Page content:
2.2 内容
Metadata:
Header 1: 2 标题
Header 2: 2.2 标题
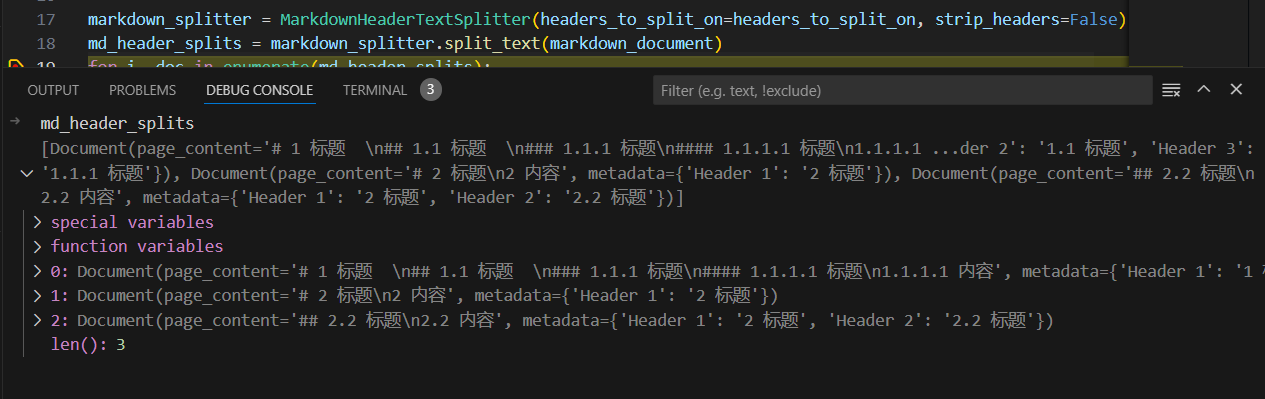
strip_headers = False 禁止剥离标题
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on, strip_headers=False
)
-------------------------------------------------------
Document 1:
Page content:
# 1 标题
## 1.1 标题
### 1.1.1 标题
#### 1.1.1.1 标题
1.1.1.1 内容
-------------------------------------------------------
Document 2:
Page content:
# 2 标题
2 内容
-------------------------------------------------------
Document 3:
Page content:
## 2.2 标题
2.2 内容
对比剥离标题情况
strip_headers=False
strip_headers=True
适应各种文本分割器
# MD splits
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on, strip_headers=False
)
md_header_splits = markdown_splitter.split_text(markdown_document)
# Char-level splits
from langchain_text_splitters import RecursiveCharacterTextSplitter
chunk_size = 250
chunk_overlap = 30
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
# Split
splits = text_splitter.split_documents(md_header_splits)
splits
【额外补充】markdown转为langchain对象 UnstructuredMarkdownLoader 方法 调用
# !pip install unstructured > /dev/null
from langchain_community.document_loaders import UnstructuredMarkdownLoader
markdown_path = "../../../../../README.md"
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
data
[Document(page_content="ð\x9f¦\x9cï¸\x8fð\x9f”\x97 LangChain\n\nâ\x9a¡ Building applications with LLMs through composability â\x9a¡\n\nLooking for the JS/TS version? Check out LangChain.js.\n\nProduction Support: As you move your LangChains into production, we'd love to offer more comprehensive support.\nPlease fill out this form and we'll set up a dedicated support Slack channel.\n\nQuick Install\n\npip install langchain\nor\nconda install langchain -c conda-forge\n\nð\x9f¤” What is this?\n\nLarge language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. However, using these LLMs in isolation is often insufficient for creating a truly powerful app - the real power comes when you can combine them with other sources of computation or knowledge.\n\nThis library aims to assist in the development of those types of applications. Common examples of these applications include:\n\nâ\x9d“ Question Answering over specific documents\n\nDocumentation\n\nEnd-to-end Example: Question Answering over Notion Database\n\nð\x9f’¬ Chatbots\n\nDocumentation\n\nEnd-to-end Example: Chat-LangChain\n\nð\x9f¤\x96 Agents\n\nDocumentation\n\nEnd-to-end Example: GPT+WolframAlpha\n\nð\x9f“\x96 Documentation\n\nPlease see here for full documentation on:\n\nGetting started (installation, setting up the environment, simple examples)\n\nHow-To examples (demos, integrations, helper functions)\n\nReference (full API docs)\n\nResources (high-level explanation of core concepts)\n\nð\x9f\x9a\x80 What can this help with?\n\nThere are six main areas that LangChain is designed to help with.\nThese are, in increasing order of complexity:\n\nð\x9f“\x83 LLMs and Prompts:\n\nThis includes prompt management, prompt optimization, a generic interface for all LLMs, and common utilities for working with LLMs.\n\nð\x9f”\x97 Chains:\n\nChains go beyond a single LLM call and involve sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.\n\nð\x9f“\x9a Data Augmented Generation:\n\nData Augmented Generation involves specific types of chains that first interact with an external data source to fetch data for use in the generation step. Examples include summarization of long pieces of text and question/answering over specific data sources.\n\nð\x9f¤\x96 Agents:\n\nAgents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end-to-end agents.\n\nð\x9f§\xa0 Memory:\n\nMemory refers to persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.\n\nð\x9f§\x90 Evaluation:\n\n[BETA] Generative models are notoriously hard to evaluate with traditional metrics. One new way of evaluating them is using language models themselves to do the evaluation. LangChain provides some prompts/chains for assisting in this.\n\nFor more information on these concepts, please see our full documentation.\n\nð\x9f’\x81 Contributing\n\nAs an open-source project in a rapidly developing field, we are extremely open to contributions, whether it be in the form of a new feature, improved infrastructure, or better documentation.\n\nFor detailed information on how to contribute, see here.", metadata={'source': '../../../../../README.md'})]
Retain Elements
Unstructured为不同的文本块创建不同的“元素”。默认情况下,我们将这些联合收割机组合在一起,但您可以通过指定 mode="elements" 轻松地保持这种分离。
loader = UnstructuredMarkdownLoader(markdown_path, mode="elements")
data = loader.load()
data[0]
Document(page_content='ð\x9f¦\x9cï¸\x8fð\x9f”\x97 LangChain', metadata={'source': '../../../../../README.md', 'page_number': 1, 'category': 'Title'})