在本章和下一章中,我们将注意力从程序设计转移到主要的编程工具——C++语言上。我们会介绍一些语言的技术细节,来给出一个C++的基本功能的稍宽的视角,并从更系统化的角度讨论这些功能。
8.1 技术细节
程序设计(programming)(即如何用代码表达思想)远比程序设计语言的特性(技术细节)更有意思。但是,当你开始编程时,你必须学习编程语言的“语法和词汇”,这就是本章和下一章要做的事。但是请不要忘记:我们要学习的主要是程序设计,我们的输出是程序/系统,程序设计语言(只)是工具。
8.2 声明和定义
声明(declaration)是将名字引入作用域的语句,其作用是
- 为命名实体(例如变量或函数)指定类型
- (可选)进行初始化(例如初始值或函数体)
如果一个声明完整指定了所声明的实体,则称之为定义(definition)。定义都是声明,但声明不都是定义。习惯上用“声明”表示“不是定义的声明”。例如:
int a = 7; // variable definition
extern int a; // variable declaration
const double d = 8.7; // constant definition
extern const double d; // constant declaration
double sqrt(double d) { ... } // function definition
double sqrt(double); // function declaration
变量定义会为该变量分配内存空间,函数定义会为函数指定函数体(也需要保存在内存中),因此不能重复定义。相反,声明不会分配内存或指定函数体,因此可以重复任意多次,只要一致即可。
C++程序中的名字都必须先声明后使用。一个名字只要声明了就可以在代码中使用,即可以编译通过;但每个声明必须在代码的其他位置给出对应的定义,否则会导致链接错误。
例如,在最简单的Hello world程序中,名字cout和<<在标准库头文件<iostream>中声明,在程序中不必了解其定义细节即可直接使用。
考虑下面的程序:
#include <iostream>
using namespace std;
extern int a;
int f(int);
int main() {
cout << f(a) << '\n';
return 0;
}
int a = 8;
int f(int x) {
return x + 1;
}
截止到main()函数,编译器只看见了变量a和函数f的声明,main()函数已经可以使用这两个名字了,而对应的定义在main()函数之后才给出。此时程序能够输出期望的结果 “9”。
如果将变量a和函数f的声明移至一个头文件foo.h,定义移至对应的源文件foo.cpp:
foo.h
extern int a;
int f(int);
foo.cpp
#include "foo.h"
int a = 8;
int f(int x) {
return x + 1;
}
main.cpp
#include <iostream>
#include "foo.h"
using namespace std;
int main() {
cout << f(a) << '\n';
return 0;
}
由于main.cpp包含了foo.h,因此仍然有变量a和函数f的声明,但没有其定义。因此,单独编译main.cpp能够编译通过,但尝试将其链接为可执行文件时会报错“未定义的引用”,必须与foo.cpp一起链接,因为名字a和f的定义在foo.cpp中。
# main.cpp编译通过
$ g++ -c -o main.o main.cpp
# 链接失败
$ g++ -o main main.o
main.o: In function `main':
main.cpp:(.text+0x6): undefined reference to `a'
main.cpp:(.text+0xd): undefined reference to `f(int)'
collect2: error: ld returned 1 exit status
# 与foo.cpp一起链接,成功
$ g++ -c -o foo.o foo.cpp
$ g++ -o main main.o foo.o
$ ./main
9
为什么C++同时提供声明和定义?这两者之间的区别反映了接口(“如何使用一个实体”)和实现(“这个实体如何完成它应该做的事情”)之间的本质区别。
8.2.1 声明的种类
C++允许程序员定义很多种实体,我们最关心的有:
- 变量
- 常量
- 函数(见8.5节)
- 命名空间(见8.7节)
- 类型(类和枚举,见第9章)
- 模板(见第19章)
8.2.2 变量和常量声明
变量或常量声明需要指定名字、类型和可选的初始值。例如:
int a; // no initializer
double d = 7; // initializer using the = syntax
vector<int> vi(10); // initializer using the () syntax
vector<int> vi2{1,2,3,4}; // initializer using the {} syntax
const int x = 7; // initializer using the = syntax
const int x2{9}; // initializer using the {} syntax
const int y; // error: no initializer
常量必须初始化;最好也对变量进行初始化,未初始化的变量会导致隐蔽的错误。例如:
void f(int z) {
int x; // uninitialized
// ... no assignment to x here...
if (z > x) {
// ...
}
// ...
x = 7; // give x a value
// ...
}
因为x未初始化,执行z > x是未定义的行为,在不同机器上、同一台机器两次运行都可能会给出不同的结果。
记住,很多“愚蠢的错误”(例如使用未初始化的变量)都是在你忙碌或疲倦的时候(写代码)发生的。请不要因为忘记初始化你自己定义的变量而引入错误。
8.2.3 默认初始化
我们通常不对string、vector等进行初始化。例如:
vector<string> v;
string s;
这是因为vector和string类的定义使得在没有显式提供这些类型的变量的初始值时使用默认值对其进行初始化。因此,v是空向量,s是空字符串。这种保证默认初始化的机制称为默认构造函数(default constructor)(见9.7.3节)。
然而,C++不允许对内置类型进行默认初始化。全局变量会被自动初始化为0,但最常用的变量(局部变量和类成员)是未初始化的,除非提供了初始化或默认构造函数。
8.3 头文件
通常在编写程序时,我们使用的大多数定义都不是我们写的,我们只是使用它们,例如cout和sqrt()。
在C++中,管理在“别处”定义的声明的关键是头文件。本质上,头文件(header file)是一个声明的集合,通过#include包含到源文件中。计算器程序使用头文件组织源代码的方式见6.9节。
习惯上,后缀.h用于C++头文件,.cpp用于C++源文件。实际上,C++语言并不关心文件后缀(例如C++标准库头文件没有后缀名),但你的代码应该遵循这一惯例。
实际上,#include "file.h"只是简单地将file.h中的声明拷贝到文件中的#include指令处。例如:
f.h
int f(int);
user.cpp
#include "f.h"
int g(int i) {
return f(i);
}
当编译user.cpp时,编译器会执行#include指令并编译以下程序:
int f(int);
int g(int i) {
return f(i);
}
逻辑上#include发生在编译器执行任何其他动作之前,因此属于预处理(preprocessing)过程的一部分。
为了方便一致性检查,我们在使用声明的源文件和给出定义的源文件中都包含头文件(见8.2节示例)。
一个头文件通常会被很多源文件包含(include)。这意味着头文件只能包含(contain)可以重复多次的声明(例如函数声明、类定义和数值常量定义)。
8.4 作用域
作用域(scope)是一个程序文本区域。每个名字都声明在一个作用域中,从声明点到作用域结束的范围内有效。
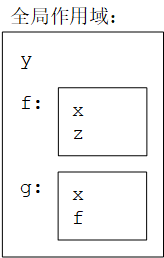
一个作用域中的名字在其嵌套作用域中也是可见的。不同作用域中相同的名字不会冲突(clash)。内部作用域中的名字会隐藏(shadow)外部作用域中相同的名字。例如:
int y = 2; // y is global
void f(int x) { // f is global; x is local to f
int z = x + y; // z is local; y is global
}
int g(int x) { // g is global; x is local to g
int f = x + 2; // f is local (shadows global f)
return 2 * f;
}
上面代码中的作用域关系如下图所示。其中,f()的x和g()的x是不同的变量,它们不会冲突;g()中的f隐藏了全局的f();全局变量y对于f()和g()都是可见的。
C++支持多种作用域,用于控制名字可以使用的位置:
- 全局作用域:在任何其他作用域之外的区域
- 命名空间作用域:嵌套于全局作用域或另一个命名空间中的命名的作用域
- 类作用域:类内的区域
- 局部作用域:语句块的
{}之间或者函数的参数表 - 语句作用域:例如
for语句内部
作用域的主要目的是保持名字的局部性,使之不影响声明在其他地方的名字。因此,不同的函数可以声明相同的局部变量和形式参数。你应该尽量保持名字的局部性,避免复杂的嵌套和隐藏。
一个名字的作用域越大,名字就应该越长、越有描述性。在程序中尽量不要使用全局变量,主要原因是很难知道哪个函数修改了它们。
注意,大多数定义了作用域的C++语法结构都可以嵌套:
- 类中的函数:成员函数。这是最常见、最有用的情况。
- 类中的类:成员类。这只在复杂的类中才有用,理想情况是保持类短小、简单。
- 函数中的类:局部类。避免这种用法,如果你觉得需要一个局部类,那么你的函数可能太长了。
- 函数中的函数:局部函数。这在C++中是不合法的。
- 语句块中的语句块:嵌套块。嵌套块是避免不了的,但要注意复杂的嵌套容易隐藏错误。
C++还提供了一种语言特性:命名空间,专门用于表达作用域,见8.7节。
在代码中应当使用一致的缩进格式来表示嵌套,否则嵌套结构会很难阅读。
8.5 函数调用和返回
函数是我们表示操作和计算的方式。当我们要做某件事,并且值得起一个名字,就可以编写一个函数。
8.5.1 声明参数和返回类型
函数声明由返回值类型、函数名和括号中的参数表组成。函数定义还包括函数体(调用函数时执行的语句),而非定义的声明只有一个分号。例如:
double fct(int a, double d); // declaration of fct (no body)
double fct(int a, double d) { return a * d; } // definition of fct
形式参数(formal argument)通常称为参数(parameter)。如果不希望函数接受参数,可以省略参数表。例如:
int current_power(); // current_power doesn't take an argument
如果不希望函数返回值,可以将返回值类型设置为void。例如:
void increase_power(int level); // increase_power doesn’t return a value
在函数声明和定义中,可以为参数命名也可以不命名。通常会命名函数定义中的所有参数,不命名的情况例如不再使用的参数。
8.5.2 返回值
使用return语句从函数中返回一个值。
声明有返回值(即返回类型不是void)的函数必须返回一个值,否则将导致错误。例如:
double my_abs(int x) {
// warning: buggy code
if (x < 0)
return –x;
else if (x > 0)
return x;
// error: no value returned if x is 0
}
必须保证函数的每种执行路径都有一个return语句或者抛出异常。
由于历史原因,main()是一个特例。执行到main()的末尾而未返回值等价于返回0,表示程序“成功完成”。
在一个不返回值的函数中,可以使用没有值的return语句从函数中返回。例如:
void print_until_s(vector<string> v, string quit) {
for (int s : v) {
if (s == quit) return;
cout << s << '\n';
}
}
8.5.3 传值参数
向函数传递参数最简单的方式是传值(pass-by-value),即将参数的值拷贝一份给函数。函数的参数是每次调用时都会初始化的局部变量。例如:
// pass-by-value (give the function a copy of the value passed)
int f(int x) {
x = x + 1; // give the local x a new value
return x;
}
int main() {
int xx = 0;
cout << f(xx) << '\n'; // write: 1
cout << xx << '\n'; // write: 0; f() doesn't change xx
int yy = 7;
cout << f(yy) << '\n'; // write: 8
cout << yy << '\n'; // write: 7; f() doesn't change yy
}
由于传递的是拷贝,因此f()中的x = x + 1不会改变实际参数xx和yy的值,如下图所示:
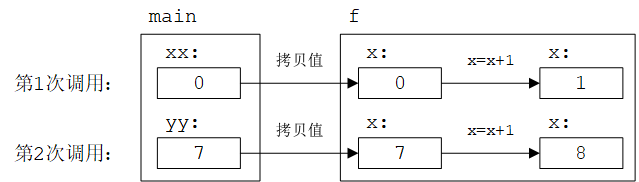
传值方式非常直接,其代价就是拷贝值的代价。
8.5.4 传常量引用参数
当传递非常小的值(例如int、double或Token)时,传值方式非常简单、直接、高效。但当值很大时,拷贝的代价就会非常高(例如包含几千个元素的大向量或包含几百个字符的长字符串)。例如,编写一个打印浮点数向量的函数:
// pass-by-value; appropriate?
void print(vector<double> v) {
cout << "{ ";
for (int i = 0; i < v.size(); ++i) {
cout << v[i];
if (i != v.size() – 1) cout << ", ";
}
cout << " }\n";
}
我们可以将这个print()用于所有规模的向量。例如:
void f(int x) {
vector<double> vd1(10); // small vector
vector<double> vd2(1000000); // large vector
vector<double> vd3(x); // vector of some unknown size
// fill vd1, vd2, vd3 with values...
print(vd1);
print(vd2);
print(vd3);
}
这段代码能够工作,但第一次调用print()需要拷贝10个double (80 B),第二次调用需要拷贝100万个double (8 MB),而不知道第三次调用需要拷贝多少字节。在这里我们只是想打印向量,而不需要拷贝所有元素。因此,我们需要一种能够将要打印的向量的“地址”而不是拷贝传递给print()函数的方法,这种“地址”称为引用(reference)。传常量引用(pass-by-const-reference)的使用方法如下:
// pass-by-const-reference
void print(const vector<double>& v) {
cout << "{ ";
for (int i = 0; i < v.size(); ++i) {
cout << v[i];
if (i != v.size() – 1) cout << ", ";
}
cout << " }\n";
}
其中&表示“引用”,const用于防止print()无意中修改其参数。除了修改参数声明外,其他代码与之前完全一致。唯一的变化是print()不再对副本进行操作,而是直接引用(refer back)了实际参数。这种参数之所以称为引用,是因为它们“引用”(refer to)了定义在其他地方的对象。
调用print()的方式也和之前一样。传常量引用方式如下图所示:
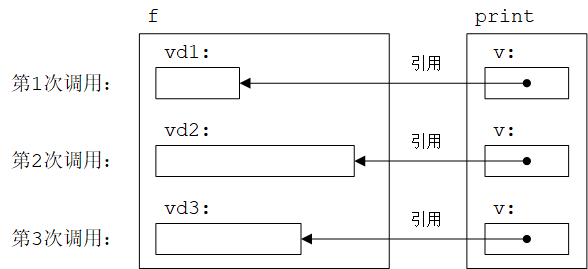
常量引用的一个非常有用的特性是:不能修改引用的对象,否则会导致编译错误。
传常量引用是一种有用的、常用的机制。
8.5.5 传引用参数
如果确实希望函数修改其参数,可以使用传引用(pass-by-reference)方式。例如,需要一个init()函数为向量元素赋值:
// pass-by-reference
void init(vector<double>& v) {
for (int i = 0; i < v.size(); ++i) v[i] = i;
}
void g(int x) {
vector<double> vd1(10); // small vector
vector<double> vd2(1000000); // large vector
vector<double> vd3(x); // vector of some unknown size
init(vd1);
init(vd2);
init(vd3);
}
这里,我们希望init()修改参数向量,因此不使用传值或传常量引用,而是传普通引用。
从技术角度,引用相当于对象的别名。例如,int&是int的引用,因此
int i = 7;
int& r = i; // r is a reference to i
r = 9; // i becomes 9
i = 10;
cout << r << ' ' << i << '\n'; // write: 10 10
即任何对r的使用实际上使用的是i。
使用指针(pointer)的等价写法如下:
int i = 7;
int* p = &i; // p is a pointer to i
*p = 9; // i becomes 9
i = 10;
cout << *p << ' ' << i << '\n'; // write: 10 10
注:C++的引用和指针类似,本质上都是变量的内存地址,也是一个整数。只是在语法上,引用不需要使用&取地址、*解引用。作为函数参数时,本质上仍然是传值,只不过拷贝的是一个4字节的地址整数,而不是其指向的对象本身。详见《C程序设计语言》笔记 第5章 指针与数组。
引用的一个用途是作为简写形式。例如:
vector<vector<double>> v; // vector of vector of double
double& var = v[f(x)][g(y)]; // var is a reference to v[f(x)][g(y)]
var = var/2 + sqrt(var);
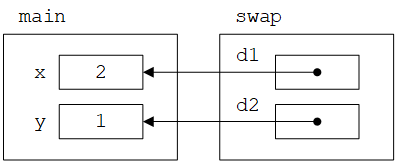
传引用是一种非常强大的机制,可以让函数直接操作被引用的对象。例如,交换两个值是很多算法(例如排序)中非常重要的操作。利用引用可以编写交换两个double的函数:
void swap(double& d1, double& d2) {
double temp = d1;
d1 = d2;
d2 = temp;
}
int main() {
double x = 1;
double y = 2;
cout << "x==" << x << " y==" << y << '\n'; // write: x==1 y==2
swap(x, y);
cout << "x==" << x << " y==" << y << '\n'; // write: x==2 y==1
}
8.5.6 传值与传引用的对比
我们的根本原则是:
- 使用传值方式传递非常小的对象。
- 使用传常量引用方式传递不需要修改的大对象。
- 让函数返回一个值,而不是通过引用参数修改对象。
- 仅在必要时使用传引用方式。
这些原则最简单、最不易出错且最高效的代码。
“非常小”的意思是一个或两个int、一个或两个double或者差不多大小的对象。
如果看到一个以非常量引用方式传递的参数,我们必须假设被调用的函数会修改这个参数。如果只是想避免拷贝操作,应该使用常量引用。
非常量引用在有些情况下是必需的:
- 用于操作容器(比如向量)或其他大对象
- 用于改变多个对象的函数(只能返回一个值)
例如:
// make each element in v1 the larger of the corresponding
// elements in v1 and v2;
// similarly, make each element of v2 the smaller
void larger(vector<int>& v1, vector<int>& v2) {
if (v1.size() != v2.size())
error("larger(): different sizes");
for (int i = 0; i < v1.size(); ++i)
if (v1[i] < v2[i])
swap(v1[i], v2[i]);
}
8.5.7 参数检查和转换
传递参数的过程就是用函数调用中指定的实际参数初始化函数的形式参数的过程。考虑如下代码:
void f(T x);
f(y);
T x = y; // initialize x with y
只要初始化T x = y;是合法的,函数调用f(y)就是合法的,此时两个x将获得相同的值。例如,x是double、y是int,则用y初始化x时,隐式地将int转换为double;在调用f()时会进行同样的操作。
类型转换通常是很有用的,但偶尔会带来奇怪的结果(见3.9.2节)。例如,向要求int的函数传递一个double就不是一个好主意:
void f(int);
void g(double x) {
f(x); // how would you know if this makes sense?
int x = y;
}
如果确实是想一个double截断为int,应使用显式类型转换T(y)或static_cast<T>(y):
void g(double x) {
int x1 = x; // truncate x
int x2 = int(x); // explicit conversion
int x3 = static_cast<int>(x); // very explicit conversion
f(x); // truncate x
f(int(x)); // explicit conversion
f(static_cast<int>(x)); // very explicit conversion
}
这样,下一个阅读这段代码的程序员可以看出你考虑了类型转换问题。