12 月 3 日、4日,2022 Apache IoTDB 物联网生态大会在线上圆满落幕。大会上发布 Apache IoTDB 的分布式 1.0 版本,并分享 Apache IoTDB 实现的数据管理技术与物联网场景实践案例,深入探讨了 Apache IoTDB 与物联网企业如何共建活跃生态,企业如何与开源社区紧密配合,实现共赢。
我们邀请到天谋科技欧洲技术负责人 Dr. Julian Feinauer 参加此次大会,并做主题演讲——《Apache IoTDB 在德国汽车生产线多级数据同步中的应用实践》。以下为英文内容和中文翻译全文。

目录
Motivation 项目动机
Data Collection 数据采集架构
Summary 项目总结
今天我将为大家分享一个非常有趣的 Apache IoTDB 应用案例,一个我们与某德国汽车生产商共同完成的项目。我们使用了 IoTDB 的一个相当独特的功能,即多主机同步能力,来完成一个多级数据同步应用程序以处理汽车生产过程中的海量数据。
这里是我将要做的报告目录。我将简要介绍一下项目的背景,数据来源于电动机,作为气动夹紧器的改进。气动夹紧器不仅被大量应用于汽车行业,在很多其他行业也被广泛使用。
报告的主要内容将介绍我们使用 Apache IoTDB 实现的数据收集以及设计架构,然后我将对我们实现的增益与学到的经验做简短的总结。
I can report you today about a very interesting application with Apache IoTDB that we have done together with a German automotive OEM. We used one of its rather unique features, namely the multi-master syncing ability, to generate a multi-level data syncing application to handle quite large amount of data that come up in automotive production.
Here's a short agenda what I want to talk about. I would shortly give a motivation introduction into the background of the project because the data was generated from electric motors, which are used to supplement pneumatic clamps, which are used a lot not only in automotive industry, but also in many other industries.
And the main part will be about the data collection and architecture we applied using Apache IoTDB, and then I'll end with a short summary of what we've done and what we've learned.
01
Motivation 项目动机
首先我们来谈谈项目的动机。我先介绍一下气动夹紧器。它是一组用于许多行业和许多应用的执行器。
在这里您可以看到 3 张来自汽车生产线的图片。可能不是很容易分辨,但在所有这些图片中,您会看到那些用来固定钢材、夹住或推动某种材料的笨重夹具。在常规的汽车生产工厂中,有数百至数千个用于处理任意运动或动作的夹具或执行器。
So let's come up to motivation. I will talk about pneumatic clamps. It’s a set of actuators which is used in many industries and in many applications.
Here you see 3 pictures from automotive production. It’s perhaps hard to see, but in all those pictures you see those bulky little clamps which are there to fix a steel, to clip or push some kind of materials. In a regular automotive production plant, there are several hundred, up to several thousand of those clamps or actuators which handle arbitrary movements or actions there.

本次报告的案例主要围绕气动夹紧器——当然还有其他气动执行器被广泛应用,不过我们将只讨论夹紧器,它在理论上是一种非常简单的设备。
这是某个夹紧器的详细描述,它会与其他很多夹紧器以相同功能运作。它在两个位置之间移动其夹紧臂:即打开和关闭。这种运动,抑或说它施加到材料上的力通常来自气动阀。
图片的下半部分是该气动阀,它通常连接到工厂中的某中央压缩机,最终产生高达 5 巴甚至更高压力的压缩空气。阀门打开或关闭,夹紧臂就会相应地改变其位置。
这是一项非常成熟的技术,非常强健的技术,也是非常经济的技术。由于唯一的活动部件是阀门,它非常稳固并且易于操控。它承载的信息量很小,即打开或关闭,此外没有任何其他信息。它可以承载强大的力量,因为其带有若干巴的压缩空气,并且它通常免于维护。
不过这类气动夹紧器有两个弊端。其中一个缺点并非是今天的主题,即精确导航做起来有点复杂,比如在生产工程中从一个车型换到另一个车型时,由于气动阀不能存储不同的位置——只能以相同的位置关闭和打开,重新部署将会变得很复杂;另一件非常重要并且非常糟糕的问题是能源效率。能源效率是世界范围内的一个重要议题,在德国更是一个焦点话题。整个工业界都在想方设法提高能源使用效率。
In this talk, the application focuses on a clamp – there are also other pneumatic actuators, but we will talk about the clamp, which is a very simple device in theory.
Here you see a detailed description of such a clamp, and in the end all the clamps do the same. It moves its clamping arms between 2 positions: open and close. This movement or the force it applies to the material then comes usually from a pneumatic valve.
In the lower part you see a pneumatic valve, which is usually connected to some kind of central compressor in a plant, which produces compressed air in the end with up to 5 bars or even higher. And the valve then either opens or closes, and the arm changes its position accordingly.
It's a very established technology, extremely robust technology, and also very cheap technology. Because the only moving part there is the valve, basically, which is quite robust and it's very simple to control. There is only a bit of information, basically, open or close, and nothing in between. You can apply strong forces to it because it has a stream of compressed air with several bars, and it’s also more or less maintenance free.
There are 2 major drawbacks in the application of those clamps, both related to pneumatics. One is, which we will not talk about today, that it’s a bit complicated to do the fine navigation, for example, if you change from one car model to the other one in the plant, then the layer of the sheets changes and arrangement is a bit complex, because this valve cannot store different positions – just the same position close and same position open. The other thing which is quite important, which is quite bad, is the energy efficiency. The energy efficiency is a big topic worldwide, and here in Germany it's even a bigger topic. The whole industry tries to get more efficient with energy consumption.

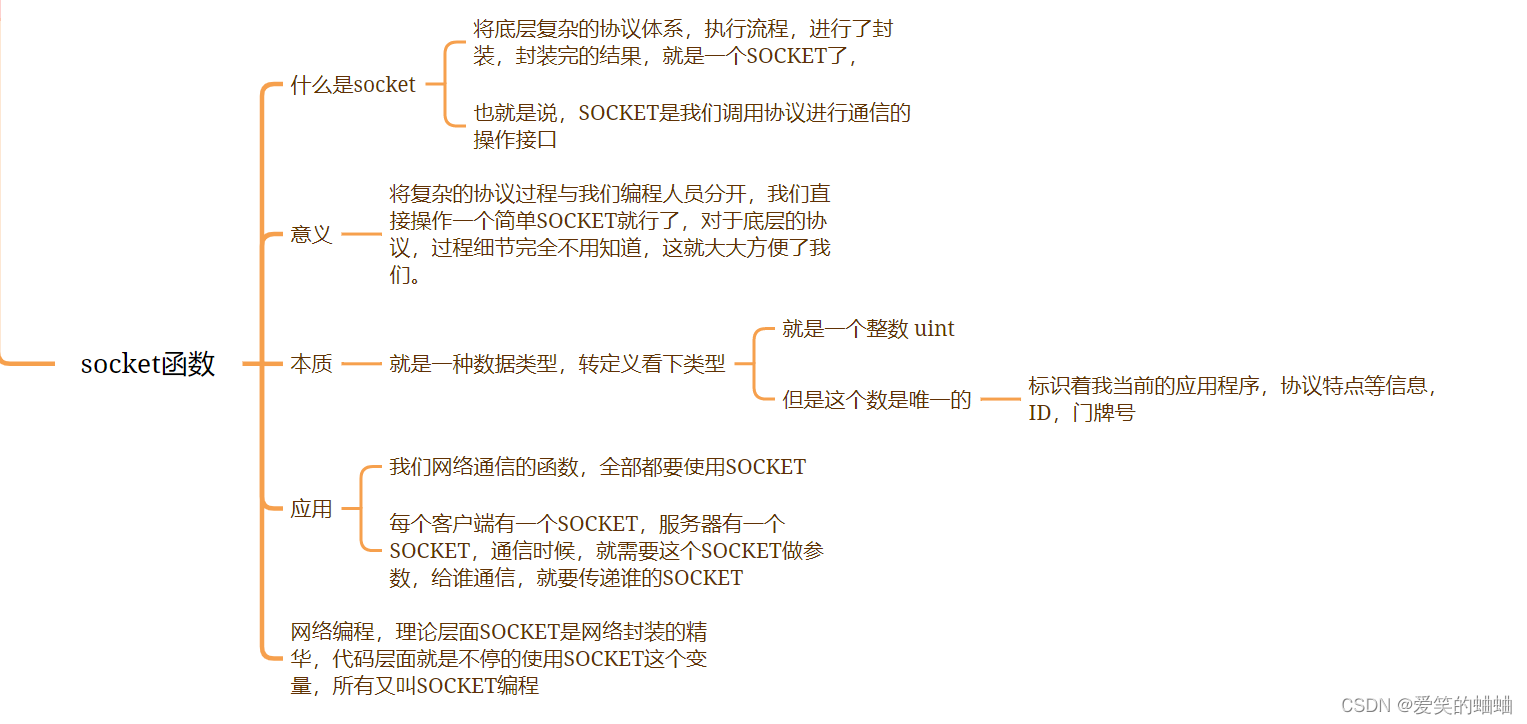
这里有几张很有意义的图片。最左侧是一张关于总能耗的统计图表,但仅限于压缩空气。即并非工业生产中的总能源消耗,而只是纯粹用于压缩空气的这部分能源消耗。而在右侧,您会看到一张对比图,比较了气动执行器和电动执行器。
我们刚才看到的设备就是图中偏左这个气动执行器。这张图表达了,首先我们有一个中央压缩机,它通常是服务于工厂大部分设备的中央压缩机。为此需要相当大的电流和电压以输出压缩空气,因此它会消耗大量电能,然后这些压缩空气被输送到工厂的各个环节。
问题在于,即使在最佳工况下的压缩机,其效率最高也只能达到 20%,即单单在压缩和通过管道输送压缩空气的过程中,已经产生了约 80% 的能量损失。然后在下一个生产环节,即我刚刚展示气动阀和夹紧器装置,又将产生大约 ¼ 的能量损失,这样一来初始的能源投入中只有约 5% 最终被有效利用——只有 5% 的能量是转化为生产力。
最右侧图片展示了,如果我们不使用压缩空气、而是使用电动执行器完成生产的能源利用过程,为此我们需要一个直流变压器,其效率约为 80%,此外还有一个电机和传动装置等设备,在这部分处理操作完成以后,依旧保有60% 的总能量。它还带来了其他好处:该系统不再需要高压驱动,因此可以采用分布式部署,如在工厂顶部安装太阳能电池;此外这种设计还有诸多其他优势。
这也是工业生产中很多应用中从气动逐渐转向电动的主要驱动力,因为如果将 5% 的能效与 60% 的能效进行比较,这是 12 倍系数的变革——12 倍的能效提升。
Here is an interesting picture. On the left side, you see a chart about the total energy consumption, but only for compressed air. It is not the total energy consumption of the industry but only the part which goes into compressed air applications. And on the right side you see a chart which compares pneumatic actors to electric driven actors.
The actor which we have just seen at the moment is the left one. And it goes like that, you have a central compressor, which is usually a central compressor for large part of the plant. You need pretty high currents and high voltages there so it consumes a lot of electrical energy and then it outputs compressed air, which goes to all parts of the plant via wirings.
And a compressor has, in the best case, an efficiency of up to 20%, so you lose about 80% of the energy already during compression and transportation of the air for the plant through pipes. Then you have the next device which I've just shown, the electric valve together with the clamping unit, where you again lose about ¼ energy, so you end up only utilizing 5% of the energy you put in initially – only 5% energy is transformed into force applied to your process.
On the right side you see the picture that if we do not use compressed air but electrical actuators, then you need one DC-DC charger, which has an efficiency of about 80% and then you also have a motor and gears, but you end up keeping on 60% of the total energy. It also brings other benefits: you need no high voltage to power the system, so it can be installed decentralized, for example with solar cells on top of the plant, and many other benefits.
This is basically the driving force why the industry is looking to shift from pneumatic to electric in many applications, because if you compare the 5% energy efficient with 60%, it's a factor of 12 – 12 times of the power you can use in your process from the energy you spent already.
如前述,该设备下半部分当前是一个气动阀,它将被电动机取代——在我们的实践中已经被全面取代。右图显示了作为改进措施的电动机,它们被专门设计制造,具有大致相同的尺寸,可以安装在这种执行器中。
气动阀和电动机之间存在不小的差异。之前介绍过,气动阀的功能非常简单,只承载了非常简单的控制信号,即阀门打开或阀门关闭。而与气动阀相比,电动机是一个非常复杂的组件,在我们的实践中通常使用无刷直流电机。首先需要一个电机的控制器,并且电机中有一组传感器,即霍尔传感器和编码器,以提供电机的反馈信息。
因此,与只气动阀相比,电动机承载了更多更复杂的信息——对气动阀来说,我们只给出了“打开”或“关闭”的输入信号,却不知道其是否真的真的被打开或关闭,我们只是根据气动夹紧器的运动判断它执行了这个操作。
As already said, the lower part here, which is currently a pneumatic valve, will be replaced – and in the application I’m talking about it was already replaced – by an electric motor. The picture on the right shows such electric motors, which are built already in a specific way to have about the same size and to be installable in this kind of actuators.
There are several differences already between having a valve and having a motor. A valve, as I said, is very simple, which you have only a bit of control signal, basically, which is either valve open or valve close. A motor is a very complex component compared to the valve, and in this application usually brushless DC motors are used. You need a motor controller which controls the motor already, and then you have a set of sensors in the motor which are Hall sensors and also encoders, which give you back information of the motor.
So you have quite a lot more of information compared to the valve which has only a bit – you only say “open” or “close” without knowing if the valve really is open or closed, you just think it is like that because of the sheer force that the pneumatic clamp brought in, but you are not certain.

02
Data Collection 数据采集架构
接下来我将介绍一下在我们实践中的数据来源以及我们设计的架构。
在我们这个汽车生产线的项目中,有大约 10,000 个气动执行器(夹紧器),现在已被电动机所取代——所有的气动阀都被取出并替换为电动机,即生产线上最终有 10,000 个电机。每个电机有约 10 个不同测点,并且测点数将来会更多,包括电压、电流、扭矩、倾角等。目前它们以 1,000 Hz 的频率运行,因此我们每毫秒从所有这 10 个测点获取一个样本。
最初的想法只是将功能强大的时序数据库 Apache IoTDB 应用在我们的案例中。然后我们做了一些测试并计算了原始数据量——如果我们发送来自所有 10,000 个电机的所有信号,最终会向服务器输入大约 6.1 Gbit(每秒)的数据流。也许服务器尚能处理这个数据量,但网络带宽无法承受,因为数据来自工厂的生产线,而工厂中的网络并不如数据中心的网络强大。
工厂中最好网络条件约有 1 Gbit/s 的带宽,而最坏的情况下,可能只有 100 Mbit/s 的带宽,所以最简单的 IoTDB 部署是行不通的。
Now we talk about the data coming out of this application and the architecture we have applied there.
In such an automotive power plant where we have the application, we have about 10,000 of those pneumatic actors (clamps), which are replaced now by motors – all the valves were taken out and replaced by motors, then we end up with 10,000 motors in the plant. Each motor generates currently about 10 different measurements, which will be more in the future, including voltage, current, torque, angles, etc. Currently, they operate at 1,000 Hz so we have one sample of all those 10 measurements each millisecond.
The initial idea was to just install powerful database Apache IoTDB in our case. Then we did some tests and did the math, and the raw volume of data – if we would just send over all those signals from all 10,000 motors, we would end up with an incoming data stream to the server of about 6.1 Gbit (per second). The server could still handle, I guess, but the network could not handle it, because it is in a plant and the network in plants are not that powerful as networks in data centers.
We have in the best case scenario, 1 Gbit/s network and in worst case scenario, we might even only have 100 Mbit/s network bandwidth, so the simple approach does not work.

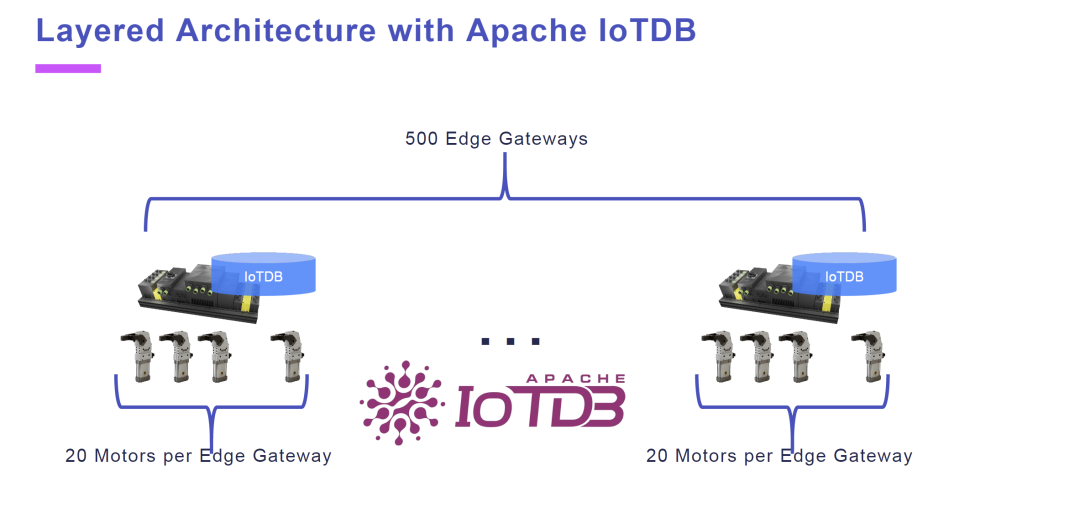
所以我们最终采用了 2 层结构,由于一些其他原因,生产线上已经安装了网关设备。每个网关控制 20 个电机,在这些网关上安装 IoTDB 副本,就可以在本地运行了。
在这种情况下,我们将有 500 个测点——共 10,000 个电机,但每 20 个连接到一个网关。我们在所有这些网关上,部署了 IoTDB 服务器并存储数据。
So we ended up with a 2-layer approach, and for other reasons there are already gateways installed. About 20 motors are controlled by one gateway, and on these gateways we can install instance of IoTDB, then they can run locally.
In this scenario, we have 500 tags – 10,000 motors overall, but 20 connected to one gateway. On all those gateways, we put an instance of IoTDB, then we can store the data there.
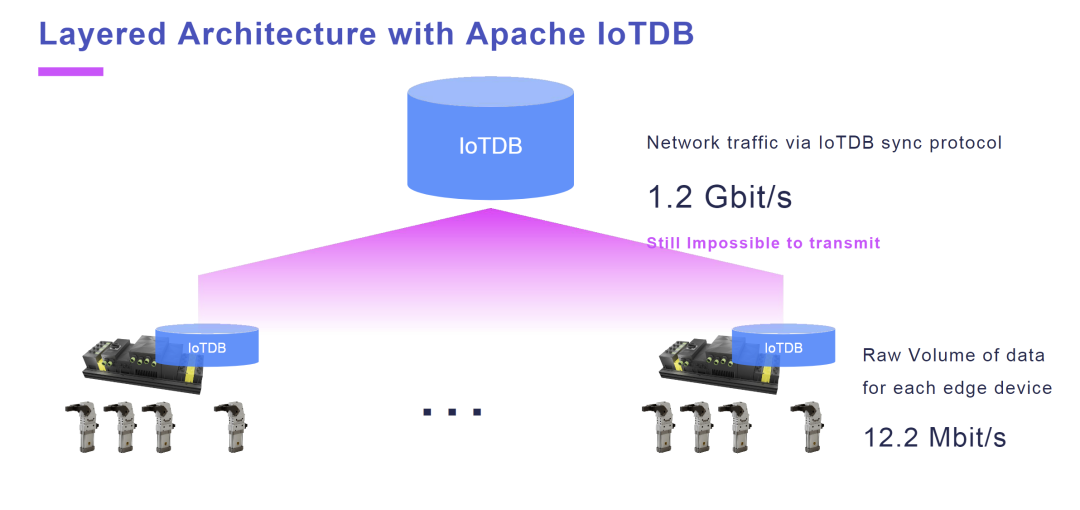
如图所示,每个边缘网关的原始数据量约为 12.2 Mbit/s,这样数据处理就简单得多。
现在我们已经存储了所有数据,这固然很好,但是要处理所有数据就不太方便了,因为我们需要连接到 500 个数据库来完成数据处理。我们希望将数据存放在中央数据库中,因此我们设置了另一个中央数据库并使用 IoTDB 的同步协议将数据转发到中央服务器。
正如我们通过 IoTDB 同步协议实现的效果,我们已经观察到,需要传输的数据量从超过 6 Gbit/s 减少到仅 1.2 Gbit/s,这是因为我们并没有传输未经处理的原始数据,而是高效压缩后的TsFile 数据文件。因此,在我们的真实生产场景中,数据量被缩小了5倍,当然这个数值可能更大也可能更小,具体取决于应用场景中的数据类型。
在我们的实践中,数据量已经被压缩到1.2 Gbit/s,这与原始数据量相比当然已经很好,但在处理起来依旧有些困难。
And you see, the raw volume of data for each of those edge gateways from 20 sensors we measure is about 12.2 Mbit/s, so it's easily handleable.
Now we get all data stored, that is nice, but to work with the data that's not good, because we need to connect to 500 databases to do things with the data. We want to have the data in a central database, so we set up another central database and used IoTDB’s sync protocol to just forward the data to the central server.
As we have done it via IoTDB sync protocol, what we already observed is, we get a nice reduction of data we need to transfer from over 6 Gibt/s to only 1.2 Gbit/s, because we are not transferring raw data but we are transferring TsFile in the end, which are highly compressed data sets. So in our real use case scenario, we saw a reduction of factor 5, which could even be more or could also be less, depending on what kind of data what we have.
In our case, we ended up with 1.2 Gbit/s, which is way better of course, but it's still too much to handle in our scenario.
那么,我们最后又做了什么改进呢?如之前描述,每个电机都有约 10 个不同测点,在与客户的讨论中,我们发现并非所有测量值都同等重要。有些很重要,客户想对它们进行分析处理,而另一些只是先存储,以备日后不时之需。
因此,我们重新配置了边缘版数据库以将所有数据保存,但只有其中一部分数据点会被传输到中央服务器。我们最终只选取了这 10 个测点中的 2 个最重要的、需要保持始终可用的实时数据的测点,这即是所谓的“热路径”。
对于中央服务器来说,来自所有 10,000 台设备的这两个测点的数据都是实时可用的。相对的,所有其他的数据点都只被存储在边缘 IoTDB 服务器上,而不会被自动同步。我们要么将这些数据保留在边缘侧,要么根据需求通过磁盘将它们传输——只需到边缘服务器取出数据,然后导出到中央服务器。因为主要问题不在于获得的数据量,而只在于网络带宽的局限,其不足以实时传输所有数据。
所以这就是我们最终的场景,即从这 10 个测点数据中取出 2 个实时同步到中央服务器,在我们的实践中最终所需大约 250 Mbit/s 的网络带宽,其余带宽仍然可用于其他目的。这就是我们实践中的最终方案。
从我们的角度来看,这有两个好处:一方面,我们存储了所有数据;另一方面,进行数据分析时,我们不需要连接到 500 个数据库来收集重要数据,而是连接到一个中央服务器即可。
So, what we did in the end? As I said, every motor generates about 10 different measurements and in the discussions with the customer, we saw that not all are equally important. Some are important and they want to do analysis on them, and others are just there to be stored in the first and later they might use them for analytics.
So what we did is we reconfigured our edge databases to store all those data, but only some of those data points are forward to the central server. We ended up with only taking 2 of those 10 measurements, which we considered are important that we want them to be always live available, and this is what I called “hot path”.
These data are basically live available for all the 10,000 devices on the central server. And all the other data points are stored on the edge IoTDB servers, but are not synced automatically. We either leave them on the edges or, from time to time, we transfer them over by a hard disk – just go to the edge server and take out the data, then go to the central server and export there. Because the problem is not the amount of data just came in, but is really just the bandwidth of the network, which is not enough to transfer the data live.
So this is the scenario that we ended up with, with the decision to take 2 out of those 10 values to a central server, and we ended up with a network bandwidth of about 250 Mbit/s we needed for our application, then the network is still available for other applications. So this is the scenario we have taken here.
This has both benefits from our perspective: on one hand, we get all data stored; and on the other hand, for data analytics you don't need to connect to 500 databases to gather the important data but only to 1 central server.

03
Summary 项目总结
最后我将对刚才介绍的案例做个总结。如前述,这是在一家德国汽车制造商的生产工厂中进行的实践,并且很快也会推广到其他制造商。有趣的是,一般来说,这是提高生产工厂能源效率的大趋势,即从气动执行器到电动执行器的转型,而这会导致生产线中的数据量大量增加,因为为了实现流程优化与精细化控制而使用的电动机本身会产生更多数据。
要知道,在德国,这个案例中遇到的问题是非常典型的情况,因为德国许多生产工厂的 IT 基础设施都不是顶级的,因而我们必须密切关注可用网络带宽。这是我们的经验,验证了可以通过一个运行在边缘的 IoTDB 和另一个运行在其他地方的 IoTDB 完成数据同步,因为数据通过已经高度压缩的 TsFile 传输,是开箱即用的。另一个要点是,在我们的实践中,压缩比下降到原始网络带宽量的 20%——新方案确实带来了其他的开销,但完成了大约 5 倍的提升。即在这个压缩率下,只需要原始网络带宽的 20%。
值得一提的是,我所展示的所有架构不会涉及导入数据的系统或数据应用系统的任意一行代码的变动,因为我们需要更改的只是要连接到哪些 IoTDB 的配置,或者(在 IoTDB中)同步服务器和同步接收器功能的配置,而所有这些配置的变动都不会影响任何原始代码。
我刚才谈到的另一件点是,我们将数据分为两条路径:一是热数据,每个电机集中可用的热数据基本上是实时的,因为它一直在被同步;二是冷数据,只被存储在边缘设备上,对冷数据的处理会有些复杂,因为需要连接到这些客户端,然后在那里调用数据或手动将其传输到中央服务器。
我们在这个过程中所做的另一个发现是——我不知道这是否已经被提起过——同步服务器协议可以很好地扩展,在我们有 500 个数据库的情况下,数据可以被完好并且稳定的发送到一个同步接收器。
以上就是我想和大家分享的应用实例。
I want to give you a short summary of what I have just talked about and shown you. As said already, the things I've shown here are from a German automotive OEM’s production plant, and will soon be rolled out also to other OEMs. Interesting takeaways are, generally speaking, this trend to improve the energy efficiency of production plants, there is general change from pneumatic actors to electric actors, and this leads to a massive increase in the amount of data that is generated, because motors just generate way more data that can be used for more fine-grained control for optimizations.
One thing to keep in mind is, this is something we see especially in Germany, because in Germany the IT infrastructure of many production plants are not top, and we have to keep an eye on the on the available network bandwidth. This is something we learnt and definitely can make sense of one IoTDB instance running on the edge and another one running somewhere else just doing synchronization, because then the data is already transferred via highly compressed TsFiles, basically out of the box. Another takeaway that I would just talk about is, in our experiments we saw a compression down to 20% of the raw volume of network bandwidth – we have some overhead, but this is a benefit about a factor of 5. So with this compression ratio you only need 20% of the original network bandwidth.
And all the architecture I've shown you basically involved no change in a single line of code of the systems importing data or the systems using the data, because all we need to change there are configuration settings of which IoTDB instances to be connected to, or (in IoTDB instances) the configuration settings for the sync server and sync receiver functionality, so all of these is carried out without that somebody has to change a single line of code.
And another thing I’ve just talked about was, we split up the data in two paths: the hot data, which is centrally available for each motor, is basically live because it was synced all the time; and the cold data which is stored, but on edge devices and the process to gather the data is a bit more complicated because you need to connect to these instances, and then browse the data there or to manually transfer it to the central server.
And another observation which we have done in the process is that – I don't know if this has already ever been investigated – the sync server protocol scales pretty well with the amount of servers that they send the data, in our case of 500 databases to one single sync receiver, and it works quite well.
This is what I wanted to tell you about our use case.

可加欧欧获取大会相关PPT
微信号:apache_iotdb