文章目录
- 1.1 安装zookeeper集群
- 1.2 Zookeeper 配置
- 1.2 安装kafka集群
- 1.3 部署filebeat服务
- 1.4 部署logstash
- 1.5 部署es和kibana服务
- 1.6 配置kibana ui界面
- 1.7 对nginx进行日志分析
Filebeat采集日志kafka topic存起来日志->logstash去kafka获取日志,进行格式转换->elasticsearch->kibana
虚拟机Ubuntu - 安装虚拟机
1.1 安装zookeeper集群
准备三台机器安装zookeeper高可用集群
zoo1: 192.168.64.101
zoo2: 192.168.64.102
zoo3: 192.168.64.103
虚拟机Ubuntu - 修改IP地址
虚拟机Ubuntu - 修改主机名
1、zookeeper简介
zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小猪)、kafka消息系统的管理员, Apache Hbase 和 Apache Solr 的分布式集群都用到了 zookeeper;Zookeeper是一个分布式的、开源的程序协调服务,是 hadoop 项目下的一个子项目。他提供的主要功能包括:配置管理、名字服务、分布式锁、集群管理。
Zookeeper主要作用在于:
- 节点选举:Master节点,主节点挂了之后,从节点就会接手工作 ,并且,保证这个节点是唯一的,这就是首脑模式,从而保证集群的高可用
- 统一配置文件管理:只需部署一台服务器可以把相同的配置文件,同步更新到其他服务器。比如,修改了Hadoop,Kafka,redis统一配置等
- 发布与订阅消息:类似于消息队列,发布者把数据存在znode节点上,订阅者会读取这个数据
- 集群管理
- 集群中保证数据的一致性
- Zookeeper的选举机制===>过半机制
- 安装的台数:奇数台(否则无法过半机制)
- 多得好处在于可靠性高,但是过的话会导致通信延时长
2、zookeeper角色:
- leader 领导者
- follower 跟随者
- observer 观察者
- leader: 负责发起选举和决议的,更新系统状态
- follower: 接收客户端的请求,给客户端返回结果,在选主的过程参与投票
- observe: 接收客户端的连接,同步leader状态,不参与选主
1.2 Zookeeper 配置
虚拟机Ubuntu - Zookeeper安装配置
- 解压文件:
[root@zoo1 ~]#mkdir /opt
[root@zoo1 ~]#tar zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /opt/
[root@zoo1 ~]#mv /opt/apache-zookeeper-3.8.0-bin/ /opt/zookeeper

- 在/opt/zookeeper/目录下创建数据文件目录和日志文件目录:
[root@zoo1 ~]# mkdir /opt/zookeeper/zkData
[root@zoo1 ~]# mkdir /opt/zookeeper/zkLog

- 复制配置文件并修改:
[root@zoo3 ~]# cd /opt/zookeeper/conf/
[root@zoo3 conf]# cp zoo_sample.cfg zoo.cfg
[root@zoo3 conf]# mkdir -p /opt/zookeeper/zkLog
[root@zoo3 conf]# vim zoo.cfg
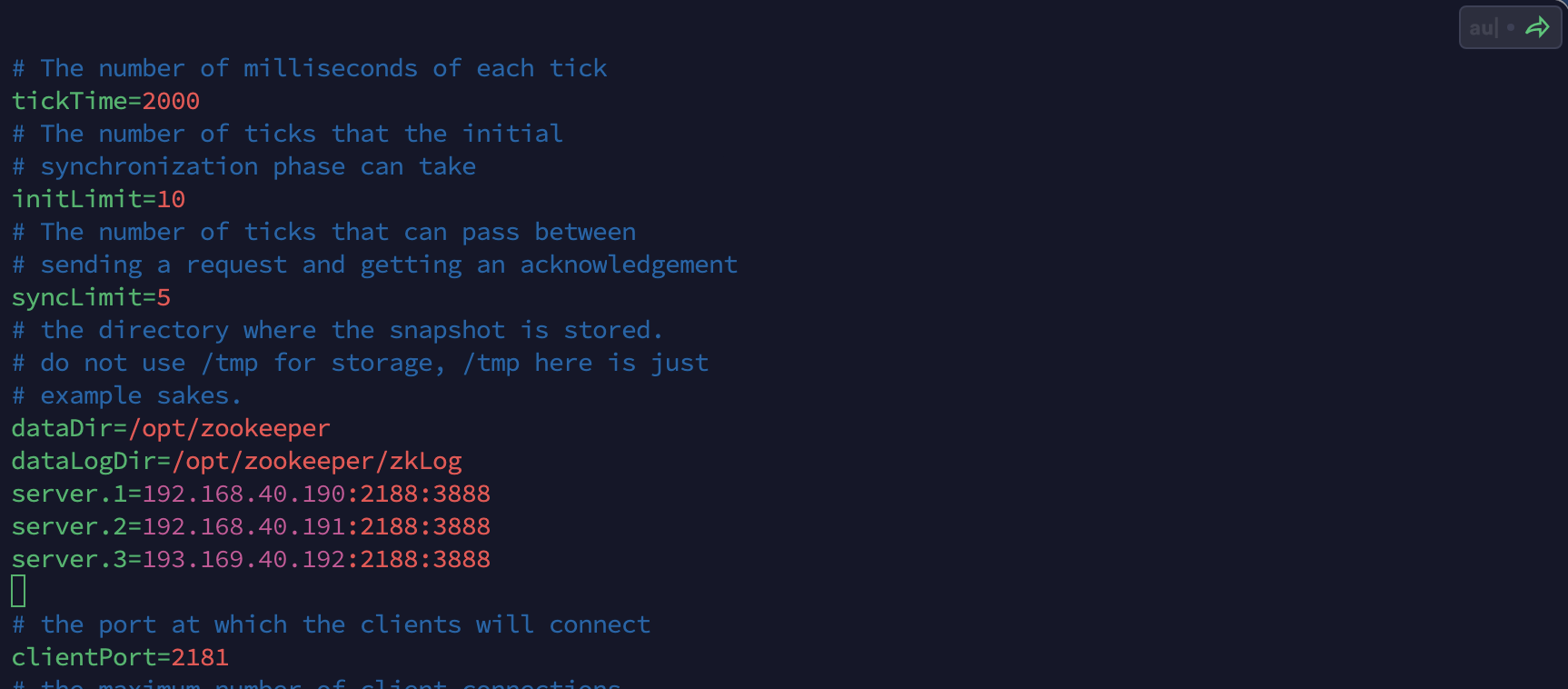
- 在原有配置基础上修改内容如下:
dataDir=/opt/zookeeper
dataLogDir=/opt/zookeeper/zkLog
server.1=192.168.40.190:2188:3888
server.2=192.168.40.191:2188:3888
server.3=192.168.40.192:2188:3888
注意:ip地址改为自己设置的
- 启动zookeeper:(需要安装JDK)
虚拟机Ubuntu - JDK安装配置

- 启动zookeeper:
[root@zoo1 conf]# cd /opt/zookeeper/
[root@zoo1 zookeeper]# echo 1 > myid
[root@zoo1 ~]#cd /opt/zookeeper/bin && nohup ./zkServer.sh start …/conf/zoo.cfg &

权限问题:Permission denied:sudo chmod 777 -R /opt/zookeeper
- 测试zookeeper:
[root@zoo3 ~]# cd /opt/zookeeper/bin/
[root@zoo3 ~]#./zkCli.sh -server 127.0.0.1:2181
- 创建节点,以及和它关联的字符串
[zk: 127.0.0.1:2181(CONNECTED) 1] create /test “lucky”
- 获取刚才创建的节点信息
[zk: 127.0.0.1:2181(CONNECTED) 2] get /test
“lucky”
- 修改节点信息
[zk: 127.0.0.1:2181(CONNECTED) 4] set /test “luckylucky”
[zk: 127.0.0.1:2181(CONNECTED) 5] get /test
“luckylucky”
1.2 安装kafka集群
1、kafka介绍:
Kafka 是一种高吞吐量的分布式发布订阅消息系统,即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。采用生产者消费者模型
zookeeper在kafka中的作用:
管理broker、consumer,创建Broker后,向zookeeper注册新的broker信息,实现在服务器正常运行下的水平拓展。
2、相关术语:
Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer:负责发布消息到Kafka broker
Consumer:消息消费者,向Kafka broker读取消息的客户端。
3、安装kafka单节点
- 在zoo3上部署kafka服务
- 解压压缩包到指定目录:
[root@zoo3 ~]# tar -xzf kafka_2.13-3.1.0.tgz
[root@zoo3 ~]#cd kafka_2.13-3.1.0
- 修改config目录下vi server.propertie文件:
[root@zoo3]# cd /root/kafka_2.13-3.1.0/config
[root@zoo3 config]# vim server.properties
listeners=PLAINTEXT://192.168.64.102:9092
zookeeper.connect=192.168.64.101:2181,192.168.64.102:2181,192.168.64.103:2181

备注:
zookeeper.connect是指定zookeper集群地址
listeners=PLAINTEXT://192.168.40.192:9092 这个ip写的是部署kafka机器的ip
- 启动kafka:
[root@zoo3 config]# cd /root/kafka_2.13-3.1.0/bin && ./kafka-server-start.sh -daemon …/config/server.properties
- 登录zookeeper客户端,查看/brokers/ids
[root@zoo3 ~]# cd /opt/zookeeper/bin/
[root@zoo3 ~]#./zkCli.sh -server 127.0.0.1:2181
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /brokers/ids
显示如下:
[0]
- 生产者和消费者测试
(1)创建主题,主题名是 quickstart-events
[root@zoo3 config]# cd /root/kafka_2.13-3.1.0/bin
[root@zoo3 bin] ./kafka-topics.sh --create --topic quickstart-events --bootstrap-server 192.168.40.192:9092
(2)查看topic
[root@zoo3 bin]# ./kafka-topics.sh --describe --topic quickstart-events --bootstrap-server 192.168.40.192:9092
(3)topic写入消息
[root@zoo3 bin]# ./kafka-console-producer.sh --topic quickstart-events --bootstrap-server 192.168.40.192:9092
> hello
> welcome
(4)打开新的终端,从topic读取信息
[root@zoo3]# cd /root/kafka_2.13-3.1.0/bin
[root@zoo3 bin]# ./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server 192.168.40.192:9092
显示如下:
4.安装kafka高可用集群
假如现在有两台服务器192.168.40.192,192.168.40.190
kafka的安装与配置如上,两台服务器唯一不同的地方就是配置文件中的broker.id和listeners监听的主机ip
[root@zoo3 ~]# scp -r kafka_2.13-3.1.0 192.168.40.190:/root/
修改192.168.40.190机器config目录下server.propertie文件
[root@zoo1 ~]# cd kafka_2.13-3.1.0/config/
[root@zoo1 config]# vim server.properties
broker.id=1
listeners=PLAINTEXT://192.168.40.190:9092
启动kafka
[root@zoo1]# cd /root/kafka_2.13-3.1.0/bin && ./kafka-server-start.sh -daemon …/config/server.properties
登录zookeeper客户端,查看/brokers/ids
[root@zoo3 ~]# cd /opt/zookeeper/bin/
[root@zoo3 ~]#./zkCli.sh -server 127.0.0.1:2181
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /brokers/ids
显示如下:
[0,1]
把zoo2加入到kafka集群:
[root@zoo3 ~]# scp -r kafka_2.13-3.1.0 192.168.40.191:/root/
修改192.168.40.190机器config目录下server.propertie文件
[root@zoo2 ~]# cd kafka_2.13-3.1.0/config/
[root@zoo2 config]# vim server.properties
broker.id=2
listeners=PLAINTEXT://192.168.40.191:9092
启动kafka
[root@zoo2]# cd /root/kafka_2.13-3.1.0/bin && ./kafka-server-start.sh -daemon …/config/server.properties
登录zookeeper客户端,查看/brokers/ids
[root@zoo3 ~]# cd /opt/zookeeper/bin/
[root@zoo3 ~]#./zkCli.sh -server 127.0.0.1:2181
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /brokers/ids
显示如下:
[0,1,2]
1.3 部署filebeat服务
在zoo2上部署
filebeat是轻量级的日志收集组件
zoo2安装nginx,利用filebeat采集nginx日志:
[root@zoo2 ~]# yum install nginx -y
[root@zoo2 ~]# service nginx start
请求nginx
[root@zoo2 ~]# curl 192.168.40.191
Kafka集群创建topic,用来存放日志数据
[root@zoo3]# cd /root/kafka_2.13-3.1.0/bin
[root@zoo3 bin]# ./kafka-topics.sh --create --topic test-topic --bootstrap-server 192.168.40.192:9092,192.168.40.191:9092,192.168.40.190:9092
安装filebeat服务
[root@zoo2 ~]# tar zxvf filebeat-7.13.1-linux-x86_64.tar.gz -C /opt/
[root@zoo2 ~]# cd /opt/filebeat-7.13.1-linux-x86_64/
[root@zoo2 filebeat-7.13.1-linux-x86_64]# ./filebeat modules enable nginx
配置filebeat_nginx.yml (记得注释kafka version,不然报错)
vim filebeat_nginx.yml
filebeat.modules:
- module: nginx
access:
enabled: true
var.paths: ["/var/log/nginx/access.log*"]
error:
enabled: true
var.paths: ["/var/log/nginx/error.log*"]
#----------------------------------Kafka output--------------------------------#
output.kafka:
enabled: true
hosts: ['192.168.40.192:9092', '192.168.40.190:9092','192.168.40.191:9092']
topic: 'test-topic' #kafka的topic,需要提前创建好,上面步骤已经创建过了
required_acks: 1 #default
compression: gzip #default
max_message_bytes: 1000000 #default
codec.format:
string: '%{[message]}'
启动filebeat
[root@zoo2 filebeat-7.13.1-linux-x86_64]# nohup ./filebeat -e -c filebeat_nginx.yml &
请求nginx
[root@zoo2 ~]# curl 192.168.40.191
#查看kafka topic是否有日志数据
[root@zoo3]# cd /root/kafka_2.13-3.1.0/bin
[root@zoo3 bin]# ./kafka-console-consumer.sh --topic test-topic --from-beginning --bootstrap-server 192.168.40.192:9092,192.168.40.190:9092,192.168.40.191:9092
1.4 部署logstash
在zoo2上部署
logstash是日志收集组件,但是占用的资源较多,一般都是用来对日志格式进行转换
[root@zoo2 ~]# cd /opt/
[root@zoo2 opt]# wget https://artifacts.elastic.co/downloads/logstash/logstash-7.9.2.tar.gz
[root@zoo2 opt]# tar zxvf logstash-7.9.2.tar.gz
[root@zoo2 opt]# cd logstash-7.9.2/config
[root@zoo2 config]# vim nginx.conf
input{
kafka {
bootstrap_servers => [“192.168.40.192:9092,192.168.40.190:9092 ,192.168.40.191:9092”]
auto_offset_reset => “latest”
consumer_threads => 3
decorate_events => true
topics => [“test-topic”]
codec => “json”
}
}
output {
elasticsearch {
hosts => [“192.168.40.191:9200”]
index => “kafkalog-%{+YYYY.MM.dd}” # 这里定义的index就是kibana里面显示的索引名称
}
}
备注:bootstrap_servers => [“192.168.40.192:9092,192.168.40.190:9092”]指定kafka集群地址
hosts => [“192.168.40.191:9200”]指定es主机地址
启动logstash服务
[root@zoo2 config]# cd …/bin
[root@zoo2 bin]# nohup ./logstash -f …/config/nginx.conf >> logstash.log &
1.5 部署es和kibana服务
在zoo2上部署
elasticsearch是一个实时的,分布式的,可扩展的搜索引擎,它允许进行全文本和结构化搜索以及对日志进行分析。它通常用于索引和搜索大量日志数据,也可以用于搜索许多不同种类的文档。elasticsearch具有三大功能,搜索、分析、存储数据
安装es服务
[root@zoo2]# mkdir /es_data
[root@zoo2 ~]# chmod 777 /es_data
[root@zoo2 ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@zoo2 ~]# yum install docker-ce -y
[root@zoo2 ~]# systemctl start docker
[root@zoo2 ~]# systemctl enable docker
[root@zoo2 ~]# docker load -i elasticsearch.tar.gz
[root@zoo2 ~]#docker run -p 9200:9200 -p 9330:9300 -itd -e “discovery.type=single-node” --name es -v /es_data:/usr/share/elasticsearch/data docker.elastic.co/elasticsearch/elasticsearch:7.9.2
kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在Elasticsearch指标中的日志数据。Kibana功能众多,在“Visualize” 菜单界面可以将查询出的数据进行可视化展示,“Dev Tools” 菜单界面可以让户方便地通过浏览器直接与 Elasticsearch 进行交互,发送 RESTFUL对 Elasticsearch 数据进行增删改查。。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
安装kibana服务
[root@zoo2 ~]# docker load -i kibana.tar.gz
[root@zoo2 ~]# docker run -p 5601:5601 -it -d --link es -e ELASTICSEARCH_URL=http://192.168.40.191:9200 --name kibana kibana:7.9.2
修改kibana配置文件:
[root@zoo2 ~]# docker exec -it kibana /bin/bash
[root@zoo2 ~]# vi config/kibana.yml
elasticsearch.hosts: [ “http://192.168.40.191:9200/” ]
[root@zoo2 ~]# docker restart kibana
1.6 配置kibana ui界面
http://192.168.40.191:5601/app/home#/
Kibana添加索引
http://192.168.40.191:5601/app/management/kibana/indexPatterns
需要再次curl访问nginx,才会产生数据
回到kibana首页,点击Discover查看日志:







![[Docker]二.Docker 镜像,仓库,容器介绍以及详解](https://img-blog.csdnimg.cn/f2b34e5a69b84fadaa92914edcd43e00.png)