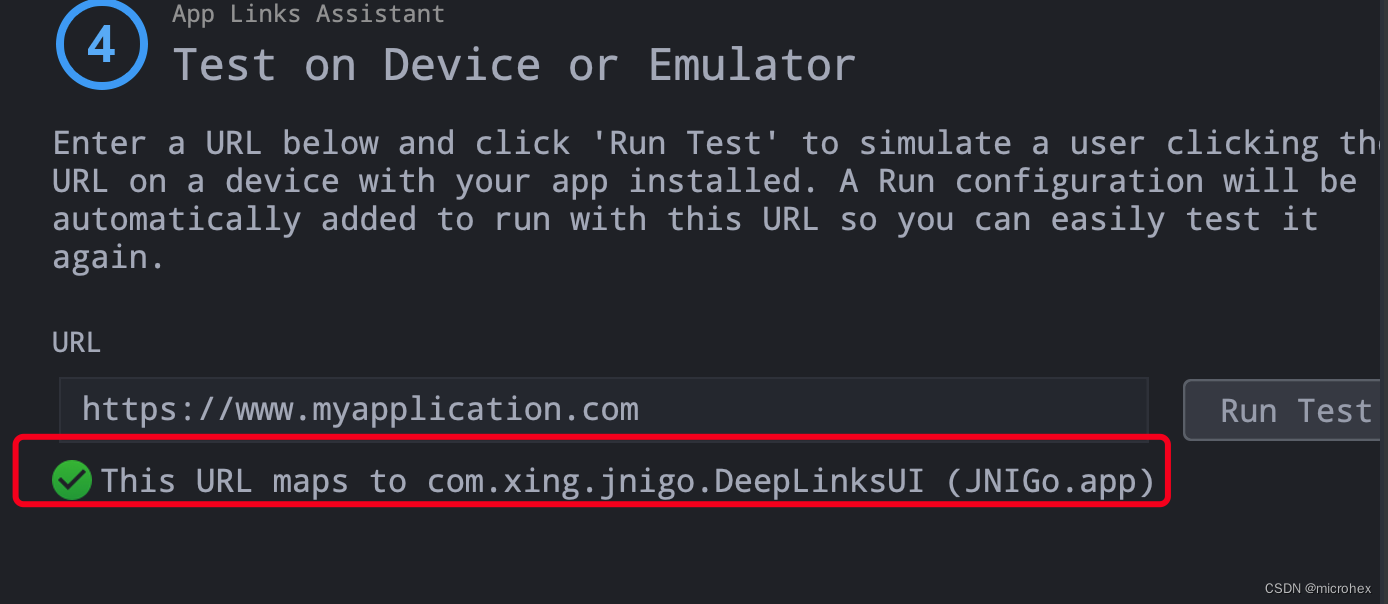
做车牌识别项目前试一试tesseract识别中文。tesseract的安装使用请参考:
Python OCR工具pytesseract详解 - 知乎pytesseract是基于Python的OCR工具, 底层使用的是Google的Tesseract-OCR 引擎,支持识别图片中的文字,支持jpeg, png, gif, bmp, tiff等图片格式。本文介绍如何使用pytesseract 实现图片文字识别。 引言OCR(Opti…![]() https://zhuanlan.zhihu.com/p/448253254
https://zhuanlan.zhihu.com/p/448253254
import pytesseract as tst
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
#参考资料
#https://zhuanlan.zhihu.com/p/448253254
original_img = cv.imread("../../SampleImages/chineseCharacters.jpg", cv.IMREAD_COLOR)
#图片转换为灰度图
img = cv.cvtColor(original_img, cv.COLOR_BGR2GRAY)
#二值化
ret,img = cv.threshold(img, 160, 255, cv.THRESH_BINARY)
plt.imshow(img, cmap='gray')
imgH,imgW = img.shape
print(imgH)
print(imgW)
#显示支持的语言列表
print(tst.get_languages(config=''))
#使用image_to_string将图片中的文字转换出来
print(tst.image_to_string(img, lang='chi_sim'))
#使用image_to_boxes返回识别的字符及边框
boxes = tst.image_to_boxes(img, lang='chi_sim')
print(boxes)
#返回值:
# 字符 左下角X 左下角Y 右上角X 右上角Y
# 例子: 稳 116 616 268 690 0
#绘制边框
#注意,opencv的坐标系以左上角为原点,boxes中的参数是以左下角为原点
for box in boxes.splitlines():
elements = box.split()
print(elements)
x1,y1,x2,y2 = int(elements[1]), int(elements[2]), int(elements[3]), int(elements[4])
#转换到opencv坐标系
charHeight = y2 - y1
y1 = imgH - y1 - charHeight
y2 = imgH - y2 + charHeight
print("Opencv character position:" + str(x1) + ' ' + str(y1) + ' ' + str(x2) + ' ' + str(y2))
cv.rectangle(original_img, (x1, y1), (x2, y2), (0,255,0), 2)
plt.imshow(original_img[:,:,::-1])image_to_boxes方法返回的坐标是以左下角为原点的,可以从打印中印证这一点。