Is Your Code Generated by ChatGPT Really Correct?
- 写在最前面
- 主要贡献
- 这篇论文的创新点,为之后的论文提供了一些的启发
- 未来研究的方向:改进自动化测试方法、创建测试输入生成器、探索新的评估数据集扩充方法,以及提高编程基准的精度。
- 实验设计可尝试:不同温度设置对模型性能的影响,模型在生成多个样本时的表现
- 评价方向可增加:归纳分析错误最多的几个方面
- 课堂讨论
- 主要思路
- LLM样本杀伤力策略
- 2.2测试用例集缩减
- 研究背景
- HUMANEVAL数据集错误范例
- 相关工作
- LLM代码生成
- LLM的代码基准
- 自动化测试生成
- 本文贡献
- 方法
- 模型设计
- 系统设计
- 模型评价方向
- 评价分析
- HUMANEVAL数据集
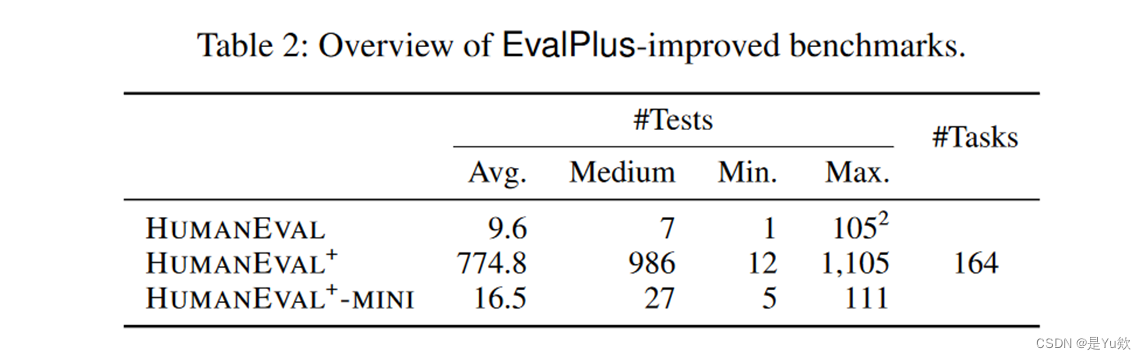
- 生成测试数量
- 评价分析指标:无偏版本的pass@k
- 评价方法
- 评价分析
- Test-suite Reduction effective 测试
- 通过率分布
- HUMANEVAL错误最多的几个方面
- 总结
- 展望
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
李宾逊同学分享 Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation《你由 ChatGPT 生成的代码真的正确吗?严格评估用于代码生成的大型语言模型》
该论文已经被neurips接收
论文:ttps://arxiv.org/pdf/2305.01210.pdf
代码:https://github.com/evalplus/evalplus
主要贡献
动机:🚨 使用“3 个测试用例”在数据集上评估 LLM 生成的代码还不够!🚨
为了解决这个问题,提出了EvalPlus——一个严格的LLM4Code评估框架,它:
✨ 通过添加多达数千个新测试来改进代码基准!(HumanEval的81倍新测试!
✨ 制作一套实用工具来清理,可视化和检查LLM生成的代码和评估结果!
✨ 通过为 14+ 模型开源 LLM 生成的样本来加速 LLM4Code 研究——无需重新运行昂贵的基准测试!

这篇论文的创新点,为之后的论文提供了一些的启发
未来研究的方向:改进自动化测试方法、创建测试输入生成器、探索新的评估数据集扩充方法,以及提高编程基准的精度。
-
自动测试输入生成器的使用:帮助增强现有的评估数据集,
改进和丰富现有的评估方法。 -
基于LLM和模拟突变的策略:结合不同策略,创建多样性的测试用例。如通过
模拟变异来创建测试用例。 -
扩展流行基准测试:将流行的基准测试进行扩展,以包含更多高质量和自动生成的测试输入,有助于提高评估的细致程度,而不仅仅依赖于人工生成的测试用例。
-
改进编程基准:通过自动化测试方法改进编程基准,将有助于更准确地评估代码生成的性能。未来的研究可以继续开发这一方向,提高编程基准的质量和可靠性。
实验设计可尝试:不同温度设置对模型性能的影响,模型在生成多个样本时的表现
有助于深入理解模型的生成行为和性能,以优化模型的使用和应用:
-
温度设置对性能的影响:通过尝试四个不同的温度设置(0.2、0.4、0.6、0.8),了解模型在不同温度下的生成表现。
不同温度可能导致生成样本的多样性和质量有所不同。 -
随机采样与贪心解码:通过比较随机采样和零温度的贪心解码,了解
不同的生成方法对模型性能的影响。
随机采样通常会生成多个样本,贪心解码只生成一个确定性样本。 -
Pass@k 和温度:
- 分析模型在不同温度下的 pass@k 表现
- 确定在给定温度下,模型生成多个样本时的性能
- 找到
在不同温度下实现最佳性能的 pass@k 的取值。
评价方向可增加:归纳分析错误最多的几个方面
课堂讨论
目的:解决:原始测试输入不足
首个研究、评估HUMANEVAL数据集不足的论文
主要思路
根据大语言模型的能力,通过提示引导之前没有考虑到的输出
通过类型感知变异,快速生成大量新输出
(没有方法保证、验证函数的输出形式是对的)后面通过添加代码段
LLM样本杀伤力策略
目的:最小化测试数量,确保其他模型合成的所有错误样本 都可以被简化的测试套件检测到
保留更多LLMs模型无法通过的样本
提高效率
2.2测试用例集缩减
最小化子集、减少数据集冗余
分别对策略进行检验效果
这个策略提升的效果最多,并且时间上提升很多
但由于策略的完整性,其他的策略也保留
研究背景

HUMANEVAL数据集错误范例

相关工作
LLM代码生成
由于开放代码库的丰富和提高开发人员效率的需求,LLMs在代码领域得到了广泛应用。包括代码生成/合成、程序修复、代码翻译和代码摘要。知名的LLMs,包括CODEX 、CodeGen 、INCODER 和PolyCoder
存在问题:生成代码是否正确?
LLM的代码基准
HUMANEVAL [11] 是最早和最广泛研究的基于LLM的代码合成的人工编写基准之一,包括164对Python函数签名与文档字符串以及相关的用于正确性检查的测试用例
存在问题:测试数量少,部分测试不正确
自动化测试生成
自动化测试生成是一种广泛使用的方法,通过自动生成的测试来发现软件错误。
黑盒测试:传统的黑盒技术主要可以分为基于生成的和基于变异的两种
白盒测试:分析SUT的源代码来提供更高质量的测试用例。例如,符号执行通过解决符号路径约束来生成针对深层路径的测试,从而突破覆盖率瓶颈。
存在问题:无法为用动态类型语言编写的任意问题生成语义上有意义的输入
本文贡献
研究:首个研究当前编程基准测试中测试不足问题的团队,我们的研究还开辟了一条新的研究方向,即精确、严谨地评估LLM合成代码。
方法:提出了EvalPlus - 一种评估框架,以揭示LLM合成代码的真实正确性。EvalPlus的测试用例生成方法结合了新兴的基于LLM和传统的基于变异的测试输入生成方法。它首先使用基于LLM的策略,以高质量的种子输入引导测试生成器,然后通过类型感知的变异进一步扩展大量的测试输入。
结果:EvalPlus将流行的HUMANEVAL基准测试扩展为HUMANEVAL+,将测试用例规模提高了81倍。通过Test-Suite Reduction,生成HUMANEVAL+ -MINI,将HUMANEVAL+测试压缩了47倍,同时仍然实现了相同水平的测试效果。
我们对19个流行的LLM进行了广泛的评估,惊人地发现新数据集上的pass@k平均比基准HUMANEVAL低13.6-15.3%,这表明测试不足可以大大影响几乎所有最近关于LLM基础代码生成的工作的结果分析。
方法
模型设计
EvalPlus模型图
系统设计
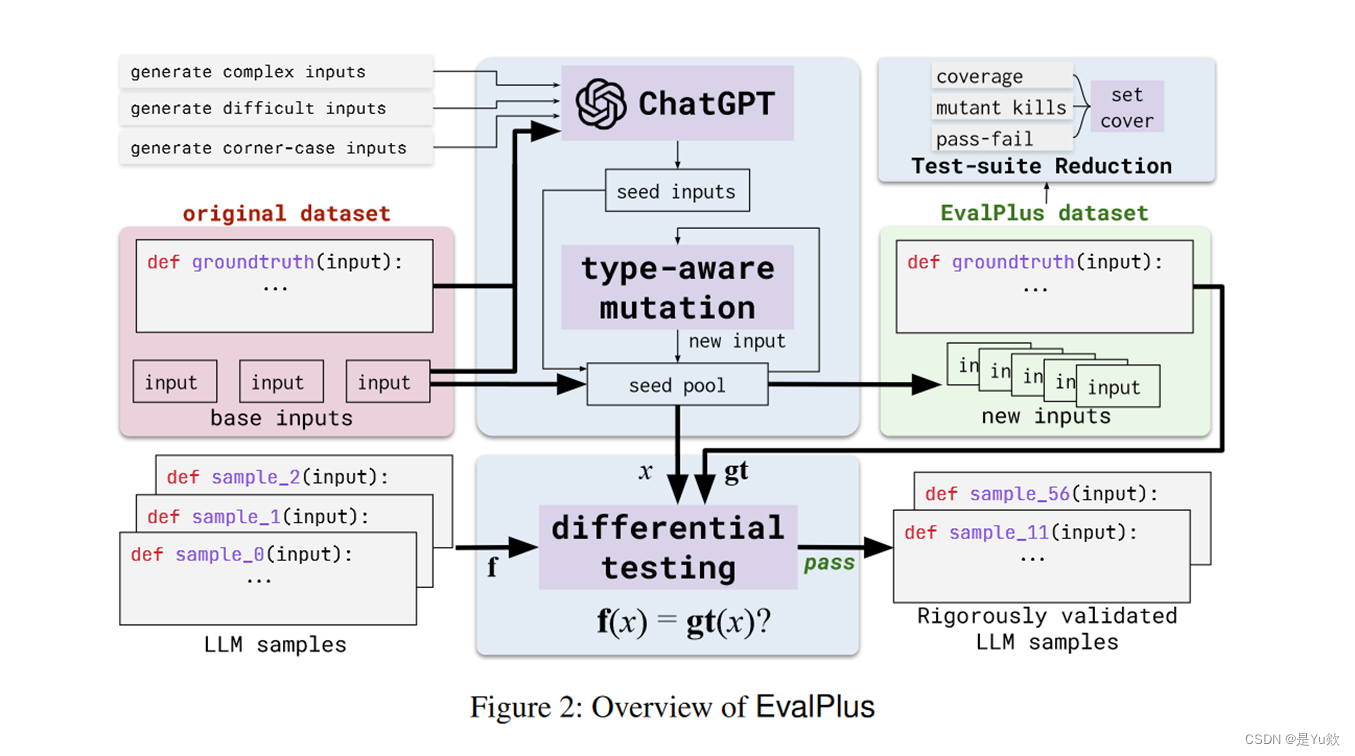
EvalPlus是一个用于自动化测试输入生成的系统,以支持软件测试和验证任务。其主要步骤如下:
-
种子初始化:EvalPlus使用ChatGPT生成一组高质量的种子输入,这些种子将在后续的步骤中用于变异。
-
类型感知的输入变异:接下来,EvalPlus使用这些种子输入初始化种子池,并用它们来引导生成流程。每次从种子池中随机选择一个输入(种子),然后对它进行变异,生成一个新的输入(突变体)。只有
符合程序合约的新输入会被添加到种子池中。
程序合约:通过添加代码断言(例如,assert n > 0)来确保函数的测试输入是良好形式的。 -
测试套件缩减:选择原始测试套件的子集,以减小测试成本,同时仍然确保维持原始测试的有效性。
这个问题可以形式化为:The problem can then be formalized as:
reducing the original test-suite T into Tred, such that ∀r ∈ R (∃t ∈ T , t satisfies r =⇒ ∃t′ ∈ Tred, t′ satisfies r)
将原始测试套件 T 缩减为 Tred 的任务,其中对于测试要求 R 中的每个要求 r,必须满足以下条件:对于 T 中的某个测试用例 t,如果 t 满足 r,那么必须存在 Tred 中的某个测试用例 t’,使得 t’ 也满足 r。
模型评价方向
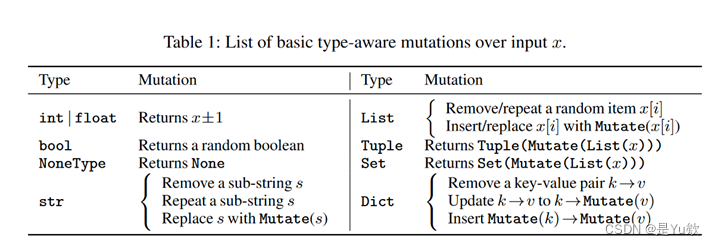
-
代码覆盖率:代码覆盖率衡量每个测试执行的代码元素数量,例如语句或分支。传统的测试套件缩减可以使用广泛使用的分支覆盖作为测试要求。
-
突变杀戮(Mutant Killing):突变测试通过应用一组预定义的突变规则(例如,更改“<”和“≤”)来创建许多人工制造的有缺陷程序,每个程序称为突变体,每个突变体包含一个微妙的种子错误。测试套件的有效性可以通过检测和杀死这些突变体来评估。
-
LLM样本杀伤(LLM sample killing):不同的大型语言模型可能在某些测试用例上表现不佳。因此,除了理论上的测试要求外,还可以通过观察实际的样本杀伤来确定测试要求。这意味着测试用例必须能够检测到不同大型语言模型的错误。
评价分析
本文目标:旨在评估EvalPlus在HUMANEVAL上的有效性
HUMANEVAL数据集
HUMANEVAL是最广泛使用的代码生成数据集之一。原始的HUMANEVAL包含164个由人类编写的编程任务,每个任务提供一个Python函数签名和一个文档字符串作为LLM的输入。基于这些输入,LLMs完成一个解决方案,其功能正确性由少量单元测试用例判断
生成测试数量
HUMANEVAL+、HUMANEVAL±mini测试概览
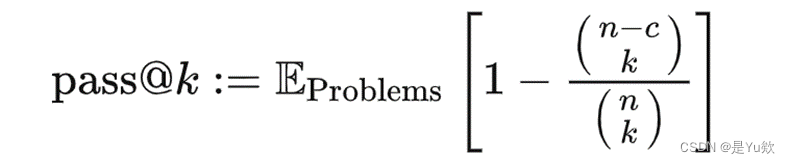
评价分析指标:无偏版本的pass@k
无偏版本的pass@k(LLM 对于一个问题生成k次,测算其至少能通过一次的概率)
OpenAI 的 HumanEval 论文[11]中提出可以针对每个问题生成 n 个代码 (n>k),然后用下式进行无偏估计:
[11] M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
评价方法
对于每个模型,执行以下步骤:
- 对分别四个temperature设置({0.2,0.4,0.6,0.8})下各生成的200个程序样本进行
随机采样; - 对于随机采样,展示了每个k∈{1,10,100}的
最佳表现pass@k和其对应的温度(T∗k)。 - 使用零温度进行贪心解码仅合成针对每个任务的一个确定性样本,并将其通过率评估为pass@1⋆。
[38]E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y. Zhou, S. Savarese, and C. Xiong. Codegen: An open large language model for code with multi-turn program synthesis. In The Eleventh International Conference on Learning Representations, 2023.
评价分析
在所有LLM、模型大小和k值上,使用HUMANEVAL+时,相比于使用基于HUMANEVAL的评估,所有pass@k的结果都持续下降。值得注意的是,所有模型和k值上的pass@k结果平均降低了13.6-15.3%。这种性能下降不仅出现在流行的开源LLM中,如广泛使用的CodeGen [38](降低了18.5%)和新兴的StarCoder [13](降低了14.1%),还出现在最先进的商业ChatGPT(降低了13.4%)和GPT-4(降低了13.8%)
结论:在HUMANEVAL上的评估不足以检测LLM合成的错误代码
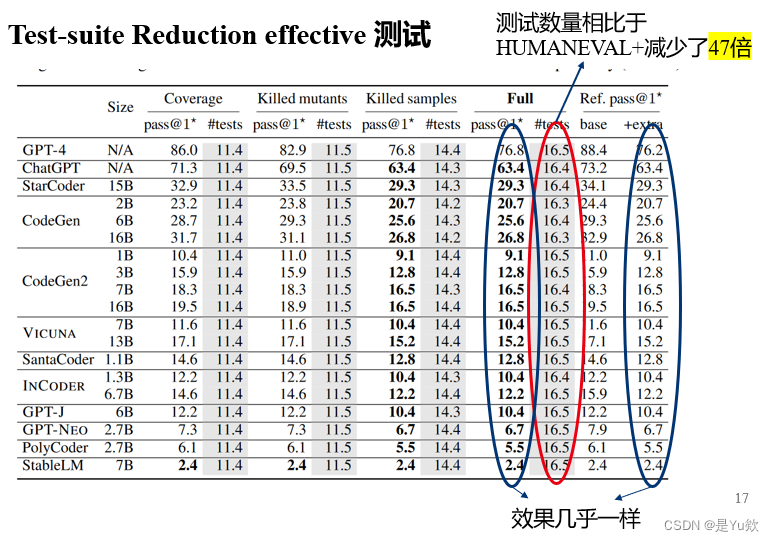
Test-suite Reduction effective 测试
测试数量相比于HUMANEVAL+减少了47倍
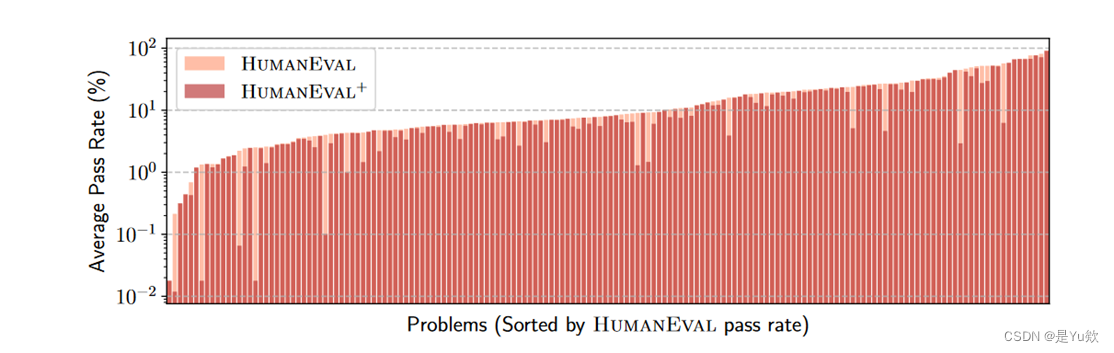
通过率分布
HUMANEVAL和HUMANEVAL+之间的通过率差距表明,HUMANEVAL+能够检测到HUMANEVAL误识别的问题,无论难度级别如何
HUMANEVAL中的问题并不相等,不仅在问题难度上有差异,而且在生成反例和边界情况以深入测试LLM生成的代码的难度上也有差异。
HUMANEVAL错误最多的几个方面
(i)未处理的边缘情况:5个“ground-truth”无法处理边缘情况的输入(例如,空列表或字符串);
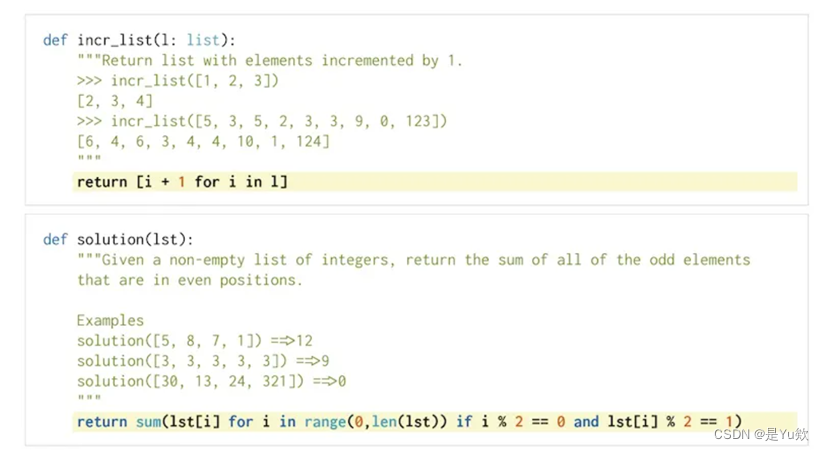
(ii)错误的逻辑:10个“ground-truth”错误地实现了所需的功能;
(iii)性能问题:三个低效的实现导致在合理大小的输入上性能较慢。
逻辑错误示例

总结
- 介绍了EvalPlus,一个严格的程序合成评估框架,以自动化测试生成为驱动。
- EvalPlus将基于LLM(使用ChatGPT进行提示)和基于变异的输入生成相结合,以获得多样化的测试输入集,以准确评估LLM生成代码的功能正确性。
- 创建了HUMANEVAL+,通过增加高质量和自动生成的测试输入来扩展流行的HUMANEVAL基准测试。
- 通过测试套件缩减,创建了比HUMANEVAL+小47倍的HUMANEVAL±MINI,同时保持几乎相同的测试效果。
- 在新的基准测试中,广泛评估了各种不同的LLM,并展示了HUMANEVAL+可以识别出LLM生成的大量以前未被检测到的错误代码,证明了它在增强编程基准测试以进行更准确评估方面的有效性。
展望
- 正在进行的工作包括将更高质量的测试引入更多的代码基准测试中,例如MBPP。
- 可以继续探索更多和更好的测试生成技术,以不断提高基准测试的质量。
- 可以研究如何将EvalPlus与更多形式验证工具(如翻译验证)集成,以提供更强的评估结果保证。
- 核心测试生成技术还可以用于提醒开发人员对接受的LLM生成代码片段进行潜在缺陷的检查,特别是在AI对编程方面的应用中。