随着 Linux 内核的发展和成熟,更多的用户期待着 Linux 可以运行非常大的系统来处理科学分析应用程序或者海量数据库。这些企业级的应用程序通常需要大量的内存才能好好运行。2.4 Linux 内核有识别相当大数量的内存的功能,但是 2.5 内核发生了很多改变,使其有能力以更有效的方式处理更多的内存。
反向映射
在 Linux 内存管理器中,页表保持对进程使用的内存物理页的追踪,它们将虚拟页映射到物理页。这些页中有一些可能不是长时间使用的,它们应该被交换出去。不过,在它们可以被交换出去之前,必须找到映射那个页的每一个进程,这样那些进程中相应页的页表条目才可以被更新。在 Linux 2.4 内核中,这是一项令人生畏的任务,因为为了确定某个页是否被某个进程映射,必须遍历每个进程的页表。随着在系统中运行的进程数量的增加,将这些页交换出去的工作量也会增加。
反向映射,或者说是 RMAP,就是为解决此问题而在 2.5 内核中实现的。反向映射提供了一个发现哪些进程正在使用给定的内存物理页的机制。不再是遍历每个进程的页表,内存管理器现在为每一个物理页建立了一个链表,包含了指向当前映射那个页的每一个进程的页表条目(page-table entries, PTE)的指针。这个链表叫做 PTE 链。PTE 链极大地提高了找到那些映射某个页的进程的速度,如图 1 所示。
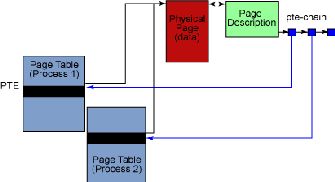
图 1. 2.6 中的反向映射
当然,没有什么是免费的:用反向映射获得性能提高也要付出代价。反向映射最重要、明显的代价是,它带来了一些内存开销。不得不用一些内存来保持对所有那些反向映射的追踪。PTE 链的每一个条目使用 4 个字节来存储指向页表条目的指针,用另外 4 个字节来存储指向链的下一个条目的指针。这些内存必须使用低端内存,而这在 32 位硬件上有点不够用。有时这可以优化到只使用一个条目而不使用链表。这种方法叫做 p页直接方法(page-direct approach)。如果只有一个到这个页的映射,那么可以用一个叫做“direct”的指针来代替链表。只有在某个页只是由一个惟一的进程映射时才可以进行这种优化。如果稍后这个页被另一个进程所映射,它将不得不再去使用 PTE 链。一个标记设置用来告诉内存管理器什么时候这种优化对一个给定的也有效。
反向映射还带来了一些其他的复杂性。当页被一个进程映射时,必须为所有那些页建立反向映射。同样,当一个进程释放对页的映射时,相应的映射也必须都删除掉。这在退出时尤其常见。所有这些操作都必须在锁定情况下进行。对那些执行很多派生和退出的应用程序来说,这可能会非常浪费并且增加很多开销。
尽管有一些折衷,但可以证明反向映射是对 Linux 内存管理器的一个颇有价值的修改。通过这一途径,查找定位映射某个页的进程这一严重瓶颈被最小化为只需要一个简单的操作。当大型应用程序向内核请求大量内存和多个进程共享内存时,反向映射帮助系统继续有效地运行和扩展。当前还有更多对反向映射的改进正在研究中,可能会出现在未来的 Linux 内核版本中。
内核资料直通车:最新Linux内核源码资料文档+视频资料![]() https://link.zhihu.com/?target=https%3A//docs.qq.com/doc/DTmFTc29xUGdNSnZ2
https://link.zhihu.com/?target=https%3A//docs.qq.com/doc/DTmFTc29xUGdNSnZ2
学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈![]() https://link.zhihu.com/?target=https%3A//ke.qq.com/course/4032547%3FflowToken%3D1040236
https://link.zhihu.com/?target=https%3A//ke.qq.com/course/4032547%3FflowToken%3D1040236
大内存页
典型地,内存管理器在 x86 系统上处理的内存页为 4 KB。实际的页大小是与体系结构相关的。对大部分用户来说,内存管理器以这样大小的页来管理内存是最有效的。不过,有一些应用程序要使用特别多的内存。大型数据库就是其中一个常见的例子。由于每个页都要由每个进程映射,必须创建页表条目来将虚拟地址映射到物理地址。如果您的一个进程要使用 4KB 的页来映射 1 GB 内存,这将用到 262,144 个页表条目来保持对那些页的追踪。如果每个页表条目消耗 8 个字节,那些每映射 1 GB 内存需要 2 MB 的开销。这本身就已经是非常可观的开销了,不过,如果有多个进程共享那些内存时,问题会变得更严重。在这种情况下,每个映射到同一块 1 GB 内存的进程将为页表条目付出自己 2 MB 的代价。如果有足够多的进程,内存在开销上的浪费可能会超过应用程序请求使用的内存数量。
解决这一问题的一个方法是使用更大的页。大部分新的处理器都支持至少一个小的和一个大的内存页大小。在 x86 上,大内存页的大小是 4 MB,或者,在物理地址扩展(PAE)打开的系统上是 2 MB。假定在前面的中使用页大小为 4 MB 的大内存页,同样 1 GB 内存只用 256 个页表条目就可以映射,而不需要 262,144 个。这样开销从 2 MB 变为 2,048 个字节。
大内存页的使用还可以通过减少 变换索引缓冲(translaTIon lookaside buffer, TLB)的失败次数来提高性能。TLB 是一种页表的高速缓存,让那些在表中列出的页可以更快地进行虚拟地址到物理地址的转换。大内存页可以用更少的实际页来提供更多的内存,相当于较小的页大小,使用的大内存页越多,就有越多的内存可以通过 TLB 引用。
在高端内存中存储页表条目
在 32 位机器上页表通常只可以存储在低端内存中。低端内存只限于物理内存的前 896 MB,同时还要满足内核其余的大部分要求。在应用程序使用了大量进程并映射了大量内存的情况下,低端内存可能很快就不够用了。
现在,在 2.6 内核中有一个配置选项叫做 Highmem PTE,让页表条目可以存放在高端内存中,释放出更多的低端内存区域给那些必须放在这里的其他内核数据结构。作为代价,使用这些页表条目的进程会稍微慢一些。不过,对于那些在大量进程在运行的系统来说,将页表存储到高端内存中可以在低端内存区域挤出更多的内存。
稳定性
更好的稳定性是 2.6 内存管理器的另一个重要改进。当 2.4 内核发布时,用户几乎马上就开始遇到内存管理相关的稳定性问题。从内存管理对整个系统的影响来看,稳定性是至关重要的。问题大部分已经解决,但是解决方案必须从根本上推翻原来的内存管理器并重写一个简单的多的管理器来取代它。这为 Linux 的发行者改进自己特定发行版本的 Linux 的内存管理器留下了很大的空间。不过,那些改进的另一方面是,在 2.4 中的内存管理部件由于使用的发行版本不同而很不相同。为避免再发生这样的事情,内存管理成为 2.6 中内核开发的最细致的一部分。从很低端的桌面系统到大型的、企业级的、多处理器的系统,新的内存管理代码已经在它们上面都已经进行了测试和优化。
结束语
Linux 2.6 内核中内存管理的改进远远不只本文中提到的这些特性。很多变化是细微的,却相当重要。这些变化一起促生了 2.6 内核中的内存管理器,它的设计目标是更高的性能、效率和稳定性。有一些变化,比如 Highmem PTE 和大内存页,目的是减少内存管理带来的开销。其他变化,比如反向映射,提高了某些关键领域的性能。之所以选择这些特别的例子,是因为它们举例说明了 Linux 2.6 内核得到了怎样的调整和增强,以便更好地处理企业级的硬件和应用程序。