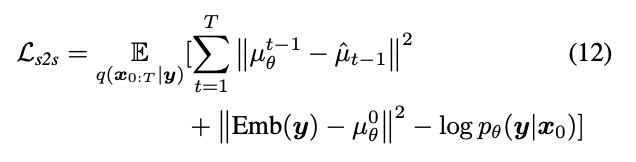OpenCV Python SVM 学习
【目标】
- 直观理解 SVM
【理论】
线性可分
下图有两种类型的数据,红色和蓝色。在kNN中,对于一个测试数据,我们用来测量它与所有训练样本的距离,并取距离最小的一个。测量所有的距离需要大量的时间,存储所有的训练样本需要大量的内存。但是考虑到图像中给出的数据,我们需要那么多吗?

考虑另一个想法。我们找到一条直线, f ( x ) = a x 1 + b x 2 + c f(x)=ax_1+bx_2+c f(x)=ax1+bx2+c,它将两个数据分为两个区域。当我们得到一个新的test_data X X X时,只需将它代入 f ( X ) f(X) f(X)。如果 f ( X ) > 0 f(X)>0 f(X)>0,它属于蓝色组,否则它属于红色组。我们可以称这条线为决策边界。这是非常简单、高效和节省内存的。这种可以用一条直线(或高维的超平面)分为两部分的数据称为线性可分数据。
所以在上图中,你可以看到有可能会有很多这样的线,我们到底选哪一个呢?直观地说,这条线应该离所有点越远越好。为什么?因为输入的数据中可能会有噪声。该数据不应影响分类精度。所以选择一条最远的线可以增强对噪音的免疫力。所以SVM所做的是找到一条与训练样本距离最小的直线(或超平面)。请看下图中穿过中心的粗体线。

为了找到这个决策边界,你需要训练数据。你都需要吗?不。只需要那些靠近相反类别的数据就足够了。在我们的图像中,它们是一个蓝色圆和两个红色方块。我们可以称它们为支持向量,穿过它们的直线称为支持平面。它们足以找到我们的决策边界。我们不需要担心所有的数据。它有助于减少数据。
结果是,找到了最能代表数据的前两个超平面。例如,蓝色数据用 w T x + b 0 > 1 w^Tx+b_0>1 wTx+b0>1表示,红色数据用 w T x + b 0 < − 1 w^Tx+b_0<−1 wTx+b0<−1表示,其中 w w w为权重向量 ( w = [ w 1 , w 2 , … , w n ] ) (w=[w_1,w_2,…,w_n]) (w=[w1,w2,…,wn]), x x x为特征向量 ( x = [ x 1 , x 2 , … , x n ] ) (x=[x_1,x_2,…,x_n]) (x=[x1,x2,…,xn])。 b 0 b_0 b0是偏置。权重向量决定决策边界的方向,偏置点决定决策边界的位置。现在决策边界被定义在这些超平面的中间,因此表示为 w T x + b 0 = 0 w^Tx+b_0=0 wTx+b0=0。支持向量到决策边界的最小距离为, d i s t a n c e s u p p o r t v e c t o r s = 1 ∣ ∣ w ∣ ∣ distance_{supportvectors}= \frac{1}{||w||} distancesupportvectors=∣∣w∣∣1。边距是这个距离的两倍。我们需要最大化这个边距(类别的边距,Margin)。即,我们需要最小化一个新函数 L ( w , b 0 ) L(w,b_0) L(w,b0),具有一些约束条件,可以表示为:
min L ( w , b 0 ) = 1 2 ∣ ∣ w ∣ ∣ subject to t i ( w T x + b 0 ) ≥ 1 ∀ i \min \, L(w,b_0)= \frac{1}{2}||w|| \, \text{subject to } \, t_i (w^Tx+b_0)≥1 \quad \forall i minL(w,b0)=21∣∣w∣∣subject to ti(wTx+b0)≥1∀i
其中:
t
i
t_i
ti是类别标签,$t_i \in [-1, 1] $
线性不可分
假设有一些数据不能用一条直线将他们分成两部分。假如:-3,3 属于类别X, -1,1属于类别O,很明显,他们不能线性可分,但是也有一些方法可以解决这些问题,我们可以通过方程
f
(
x
)
=
x
2
f(x)=x^2
f(x)=x2将数据映射,这样,9 分为X和 1 分为 O,就变成可分的了。
我们可以将一维数据转换为二维数据。我们可以用
f
(
x
)
=
(
x
,
x
2
)
f(x)=(x,x^2)
f(x)=(x,x2)函数来映射这个数据。然后X变成(-3,9)和(3,9),而O变成(-1,1)和(1,1)。这也是线性可分的。简而言之,低维空间中的非线性可分数据在高维空间中变为线性可分的可能性更大。
一般来说,可以将d维空间中的点映射到某个D维空间(D>d)来检验线性可分性的可能性。有一种思想可以通过在低维输入(特征)空间中进行计算来帮助计算高维(核)空间中的点积。我们可以用下面的例子来说明。
假设在二维空间里有两个点 p = ( p 1 , p 2 ) p=(p_1,p_2) p=(p1,p2) 和 q = ( q 1 , q 2 ) q=(q_1,q_2) q=(q1,q2),设 ϕ \phi ϕ 为 映射函数,将二维数据映射到三维空间里,则有:
ϕ ( p ) = ( p 1 2 , p 2 2 , 2 p 1 p 2 ) \phi (p)=(p_1^2, p_2^2,\sqrt{2}p_1p_2) ϕ(p)=(p12,p22,2p1p2)
ϕ ( q ) = ( q 1 2 , q 2 2 , 2 q 1 q 2 ) \phi (q)=(q_1^2, q_2^2,\sqrt{2}q_1q_2) ϕ(q)=(q12,q22,2q1q2)
我们定义一个核函数 K ( p , q ) K(p,q) K(p,q)可以计算两点的点积。
K ( p , q ) = ϕ ( p ) ⋅ ϕ ( q ) = ϕ ( p ) T ϕ ( q ) = ( p 1 2 , p 2 2 , 2 p 1 p 2 ) ⋅ ( q 1 2 , q 2 2 , 2 q 1 q 2 ) = p 1 2 q 1 2 + p 2 2 q 2 2 + 2 p 1 q 1 p 2 q 2 = ( p 1 q 1 + p 2 q 2 ) 2 K(p,q)=\phi(p) \cdot \phi(q) = \phi(p)^T \phi(q) \\ =(p_1^2, p_2^2,\sqrt{2}p_1p_2) \cdot (q_1^2, q_2^2,\sqrt{2}q_1q_2) \\ = p_1^2q_1^2+p_2^2q_2^2+2p_1q_1p_2q_2 \\ = (p_1q_1+p_2q_2)^2 K(p,q)=ϕ(p)⋅ϕ(q)=ϕ(p)Tϕ(q)=(p12,p22,2p1p2)⋅(q12,q22,2q1q2)=p12q12+p22q22+2p1q1p2q2=(p1q1+p2q2)2
ϕ ( p ) ⋅ ϕ ( q ) = ( p ⋅ q ) 2 \phi(p) \cdot \phi(q) = (p \cdot q)^2 ϕ(p)⋅ϕ(q)=(p⋅q)2
这意味着,三维空间中的点积可以用二维空间中的平方点积来实现。这可以应用到高维空间。所以我们可以用低维来计算高维特征。一旦我们把它们映射出来,我们就得到了一个高维空间。
除了这些概念之外,还有错误分类的问题。因此,仅仅找到具有最大Margin的决策边界是不够的。我们还需要考虑分类错误的问题。有时,可能会找到一个边际较小,但错误分类较少的决策边界。无论如何,我们需要修改我们的模型,使其能够找到最大边际的决策边界,但错误分类较少。最小化准则修改为:
min ∣ ∣ w ∣ ∣ 2 + C ( distance of misclassified samples to their correct regions ) \min ||w||^2+C(\text{distance of misclassified samples to their correct regions}) min∣∣w∣∣2+C(distance of misclassified samples to their correct regions)
下图显示了这个概念。为每个训练数据样本定义一个新的参数 ξ i ξ_i ξi 。它是对应的训练样本到正确决策区域的距离。对于那些没有被错误分类的,它们落在相应的支撑平面上,所以它们的距离为零。

所以新的优化问题是:
min L ( w , b 0 ) = ∣ ∣ w ∣ ∣ 2 + C ∑ i ξ i subject to y i ( w T x i + b 0 ) ≥ 1 − ξ i a n d ξ i > 0 ∀ i \min \,L(w,b_0)=||w||^2+C\sum_i \xi_i \, \text{subject to} \, y_i(w^Tx_i+b_0)≥ 1-\xi_i \, and \: \xi_i>0 \, \forall i minL(w,b0)=∣∣w∣∣2+Ci∑ξisubject toyi(wTxi+b0)≥1−ξiandξi>0∀i
参数 C C C应该如何选择?很明显,这个问题的答案取决于训练数据的分布方式。虽然没有普遍的答案,但考虑以下规则是有用的:
- 较大的 C C C值给出的解错误分类错误较小,但边际较小。考虑到在这种情况下,错误分类的代价是昂贵的。由于优化的目的是使参数最小,因此不允许出现很少的误分类错误。
-
C
C
C值越小,解的余量越大,分类误差越大。在这种情况下,最小化没有考虑那么多的和项,所以它更专注于找到一个有大
Margin的超平面。
【参考】
- OpenCV: Understanding SVM
- NPTEL notes on Statistical Pattern Recognition, Chapters 25-29.