前言
扩散模型在文生图领域可谓是大显身手,效果棒棒~
每当一个idea有效之时,便会有更多相关的研究跟进尝试,今天就给大家介绍一篇将扩散模型应用到文本生成领域的工作,这也是一篇比较新的paper,其中还用到了梅西在2022世界杯表现的例子。
大家可以重点借鉴看看作者是怎么把扩散这一idea揉进到NLP的,最好看看能不能从中找到一些启发进而把扩散这一idea用到自己的领域试试~
截止笔者写这篇博客的时候,作者的代码还没有放出来,不过paper说了在不久的将来会开源出来,另外笔者之前也写过一篇关于扩散模型代码解析的文章,想实践的同学可以穿梭参考一下:
《扩散模型代码剖析》:https://zhuanlan.zhihu.com/p/591761273
本次介绍的paper: https://arxiv.org/pdf/2212.11685.pdf
扩散模型
在开始介绍方法之前,还是先简单说一下关于扩散模型的几个重要结论性公式(这里不讲复杂的推导,如果读者还不清楚扩散模型,建议先去看一下原理篇,这样的话在读本篇的结论性公式以及理解它的参数含义的时候会比较轻松一些)。
首先扩散模型的基本原理就是先加噪再去噪,而所谓的扩散模型的主要作用就是在去噪阶段预测噪声。
加噪过程:
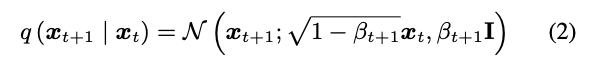
去噪过程:
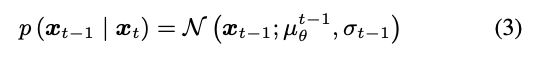
可以看到去噪过程主要就是要得到均值和方差,其中下图中红色的部分就是扩散模型,具体的作用就是预测当前t步所加的噪声:
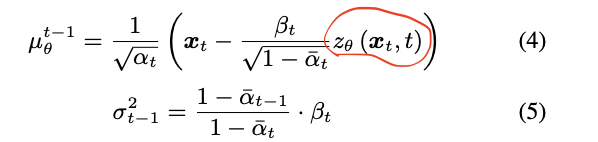
具体扩散模型训练loss就是:
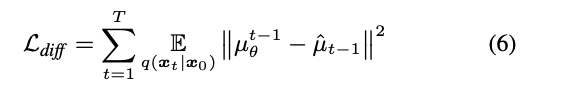
方法
(1)模型
本文主要研究的领域是文本生成NLG,其实就是个sequence-to-sequence任务,即给定一个source text,期望生成对应的target text。
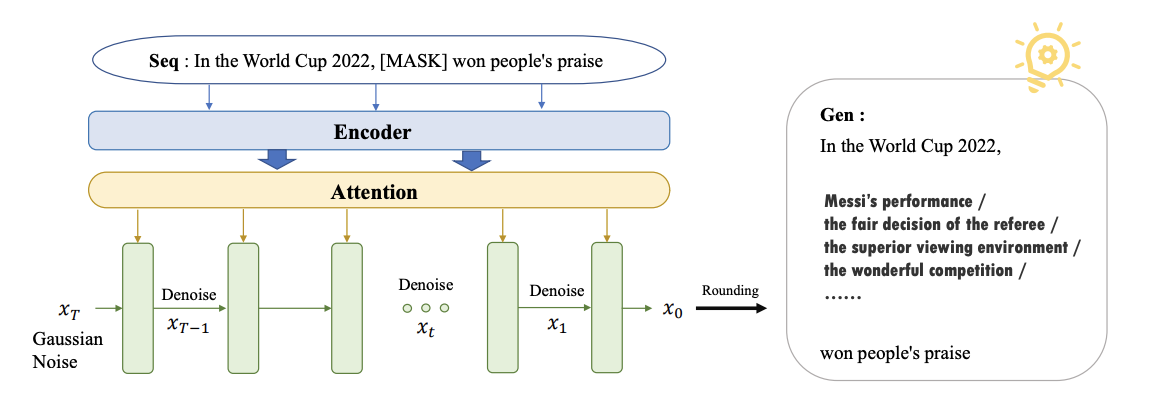
作者将所提出的框架命名为GENIE(GENeration using dIffusion modEl),框图如下:
-
Encode
encoder这里比较简单,其模型结构是一个由六层transformer组成的,主要就是负责把source text表征为一个embeding 即
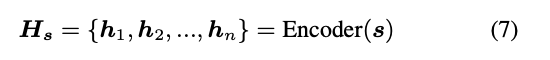
-
Text Diffusion Model
扩散模型这里(重点!!!)也是一个六层的 cross-attention,它的作用我们前面说过了就是预测当前t步所加的噪声(这也是扩散模型这一idea的核心)即 ,可以清楚的看到它的输入是 。
: 第t步
: 第t步的表征
: source text的表征
-
Inference Phase
在训练好了模型之后,预测阶段就很简单了。开始先随机从高斯分布中抽取一个样本点即 ,然后使用训练好的模型去预测每一步的噪声,最后利用公式(4)(5)一步步去噪,直到得到 即可。
-
Training Phase
这里来看一下具体的训练过程。
假设当前的target sequence为y即:
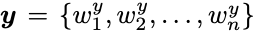
首先就是将y这一序列token进行embedding化生成初始值,更具体的就是扩散模型中 的即
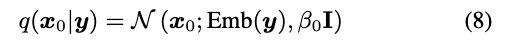
有了 ,根据扩散模型的公式,我们便可以得到任意一步t的状态值:
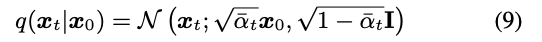
同时我们可以通过扩散模型预测噪声得到相应的均值和方差(其实就是上面讲的公式4和公式5)
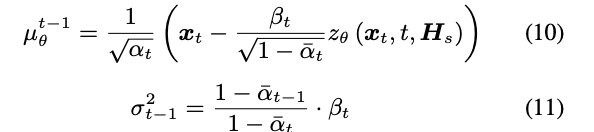
最后参考扩散模型的loss便可以得到我们要训练的loss:
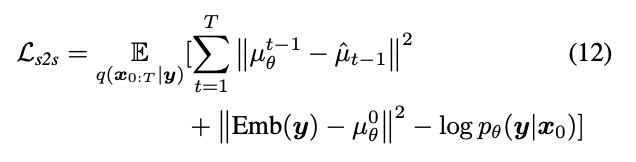
-
小结
这里涉及的公式较多,看不懂的小伙伴可以先看原理篇,然后再回头看这里就一目了然啦。可以看到基本上就是原封不动的把扩散模型那一套拿过来。
(2)预训练
作者也强调了说,扩散模型的在NLP生成领域潜力是具体的,因为它生成的多样性很强,只不过现在的效果以及训练速度等方面还有一些限制。于是作者也参考了之前大模型的惯用做法:先预训练一把!
具体做法就是从一篇doc里面随机MASK掉一些段落 即用[MASK]标识符代替,以此来作为encoder的输入即可以得到 ,同时 就可以作为target text即 ,进而依据公式(9)就可以得到 ,有了 便有了扩散模型的输入,最后便可以预测噪声,得到均值方差进行训练啦。
碎碎念
想用扩散模型的前提是要想清楚你最终想要的输出是什么也即 ,同时控制生成的变量是什么也即 。一旦确定好了或者说你当前研究的领域能够抽象成这样一个问题,那就可以直接把扩散模型这一套拿过来试试啦。具体的逻辑就是:先表征出 (咋表征无所谓,用啥模型自己决定就行),有了 后就可以得到任意一步的状态 ,进而就可以拿到 ,而这就是扩散模型的输入,那么进而就可以预测噪声,预测出噪声就可以得到均值和方差,有了均值和方差就可以依据公式(3)一步步去噪直到得到 。
需要注意的是在训练阶段 的获得是需要 ,而在预测阶段,我们不可能知道 (因为我们的目的就是希望生产一个好的 ),那 或者说去噪的最原始状态 获得其实就是随机从高斯分布中采一个样本点就行,这也是为啥能生成多种多样符合结果的原因。当然了指导生成的变量 在训练和预测阶段逻辑上基本上是一样的。
本篇是将扩散模型应用到了NLG领域,具体到source text的是 、target text是 。那如何将扩散模型应用到理解类NLU内容呢?大家可以多尝试哦~
本文由 mdnice 多平台发布