这里写自定义目录标题
- LLama的一些基本结论
各个论文中给出一些观察显现,我们比摘要更简略地摘要一些文本大模型大佬地基本结论和观察到的现象
LLama的一些基本结论
由于大模型要作为服务,因而推理时间更重要。一个较小的、训练时间较长的模型最终会在推理中更便宜
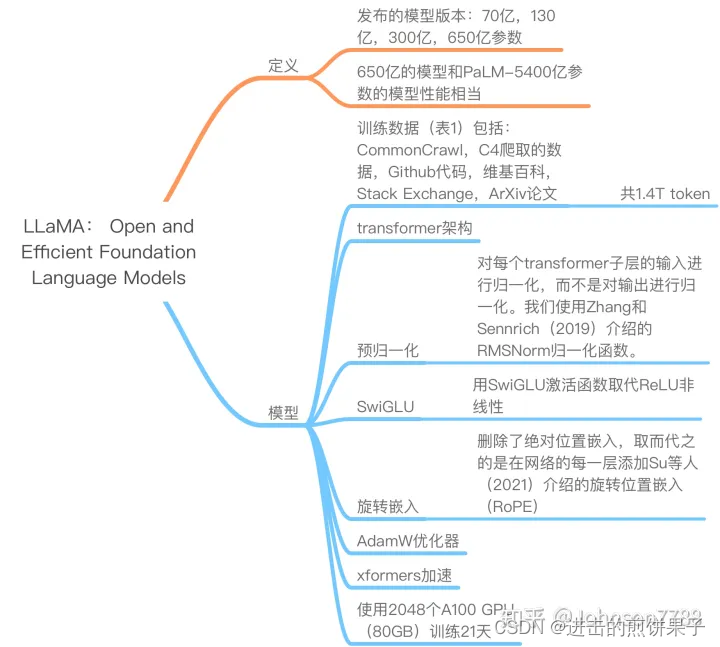
主要流程
预归一化[GPT3]:为了提高训练的稳定性,我们对每个transformer子层的输入进行归一化,而不是对输出进行归一化。我们使用Zhang和Sennrich(2019)介绍的RMSNorm归一化函数。
SwiGLU激活函数[PaLM]:我们用SwiGLU激活函数取代ReLU非线性,由Shazeer(2020)介绍,以提高性能。我们使用2/3 4d的维度,而不是PaLM中的4d。
旋转嵌入[GPTNeo]:我们删除了绝对位置嵌入,取而代之的是在网络的每一层添加Su等人(2021)介绍的旋转位置嵌入(RoPE)。我们不同模型的超参数细节见表2。
附录:
某些名词解释
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
归一化函数RMSNorm
激活函数SwiGLU
位置嵌入RoPE
优化器AdamW
评测基准
MMLU Benchmark (Multi-task Language Understanding)多任务知识理解能力,涵盖数学、计算机、人文科学。 GPT4载-shot上 86%
BIG-bench 有204个任务,语言学,常识推理、数学、生物、物理等。
65% 的任务中超过人类。
HELM Holistic Evaluation of Language Models 综合测评,16个核心场景,7类指标