一:为什么要有包头保护
学过HTTP和HTTPS都知道,随着网络的普及,人们对于信息的保护,个人的隐私越发的重视。信息加密对于未来协议的发展肯定是越来越趋于严格。QUIC作为新生代的协议,必然要站着前辈的肩膀上发展,对于报文中信息的保护肯定比前辈更加的严格,载荷加密不谈,QUIC甚至在包头上都进行了加密。
其实翻开QUIC的发展历程,并不是QUIC诞生之初就对包头进行了加密,早期的QUIC包头是明文,其实包头就是协议的一些必要字段,并不承载用户的信息,直到QUIC的第一个发行版本RFC9000出世,将包头保护作为协议的一个特性,那为什么要对QUIC的包头进行加密呢。
1,最大限度降低被网络中间件解析
在我们的网络中,会有解析协议的中间件,比如运营商部署的DPI设备,或者企业自己部署的协议解析设备。除开运营商的国家行为,私设的DPI设备我们要尽力保护每一个保护的信息,包头保护虽然在算法上是公开的,但是如果要去解析必然要耗费大量的算力,这在一定程度上起到了保护隐私的作用。
2,最大限度降低被中间件拦截的概率
网络中可能部署有软件或者硬件,用于拦截或者解密HTTPS,最常见的就是去解析SNI字段并进行识别,来拦截一些特定的流量。包头的保护可以一定程度上降低被拦截的概率,即使有设备去做解析也要付出大量的算力代价。
3,避免网络中间件僵化而带来的不确定性
网络中间件为了识别某些网络协议的流量,需要部分或者全部实施这些网络协议,比如要识别TLS,最简单的就是使用某个版本TLS开源库解析数据包,根据包头的某些固定字段判断是否TLS包。随着时间的推移,网络协议在更新,但是网络中间件由于各种原因可能无法更新,之前那些检测网络协议的策略相当于固化在中间件上了,无法识别新的网络协议,可能会导致新网络协议的包被错误的处理甚至丢弃,阻碍新协议的推进,这个就是中间件僵化。
典型的一个例子是在2017年2月,Chrome和Firefox都开始为其客户提供TLS 1.3。结果发现很多用户TLS 1.3失败了,TLS 1.2工作正常。最后定位到的原因是TLS 1.3协议中的ChangeCipherSpec,session_id和压缩字段就都被删除,而这几个字段可能被网络中间件认为是TLS一些基本特征,如果删除它们就会导致连接失败。2017年11月在新加坡举行的IETF会议上,TLS 1.3提出了一个新的改变来解决这个问题,即重新引入了被删除的协议中的很多部分,比如,session_id,ChangeCipherSpec和一个空的压缩字段,这就使得TLS1.3看起来像TLS1.2一样。
解决僵化最好的方法是加密,尽可能对报文所有字段加密,使得网络中间件无法或者需要很大代价理解或者识别协议,这样可以减少甚至是避免网络中间件实施干扰,同时也增加了通信的安全性。QUIC的payload都是加密的,如果想GQUIC那样,包头都是明文,那么就会存在网络中间件协议僵化问题,所以QUIC设计了包头保护。
二:QUIC包头加密的字段分析
QUIC包头保护并不是对所有的字段进行解密,因为一开始就把所有的信息进行加密,对端进行解密都不知道从何下手,所以还是需要暴露一些必要的字段方便对方进行解密。
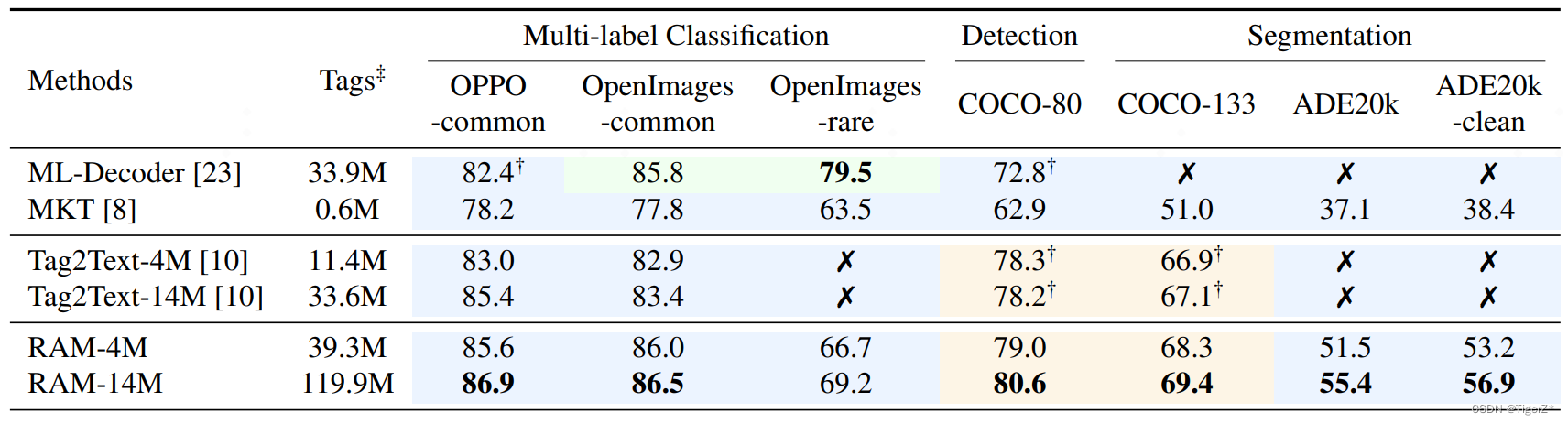
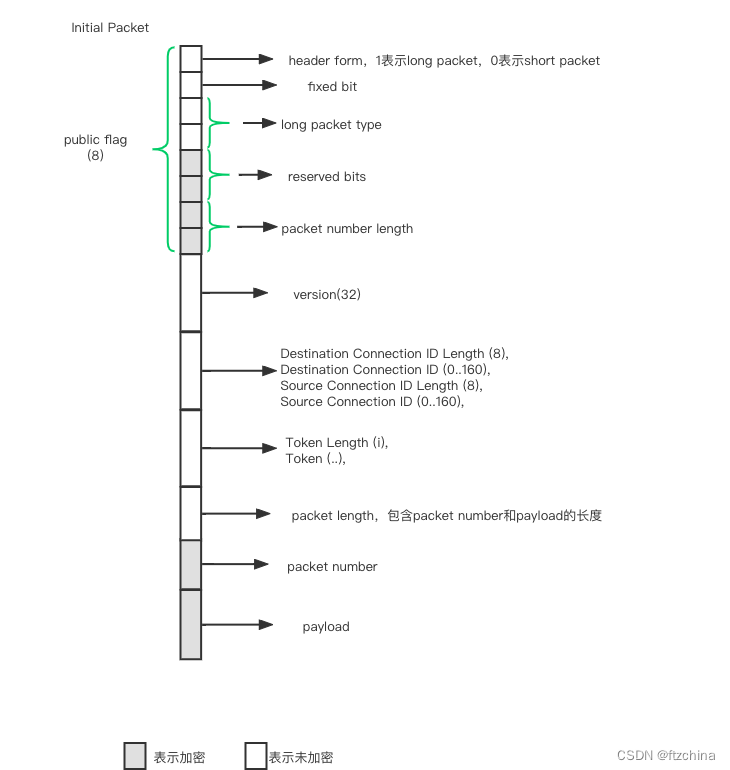
我们先来看看RFC9001中对于initial包的包头保护字段的描述
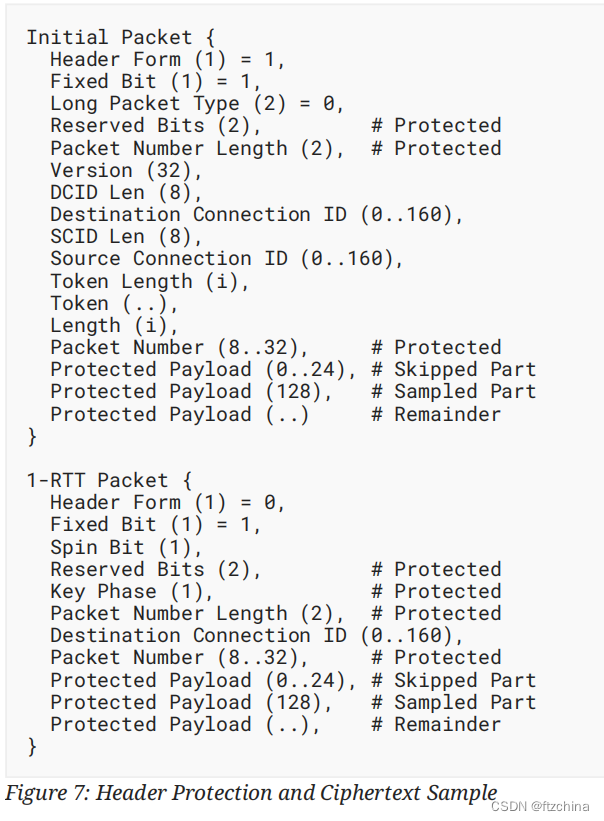
QUIC包头的字段如下:
- header form:指示是长包头还是短包头,header form加密了,就不能确定是哪个类型,故该字段不进行加密保护。
- Fixed Bit:这个bit默认1,保护没有意义。
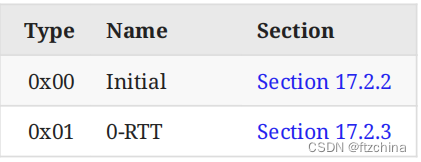
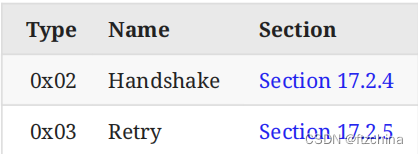
- Long Packet Type:包括以下4种,Packet Type如下
- Version:包头有些字段是版本无关的,比如header form、源和目的CID长度及其长度、长包头的version,其他字段不同版本可能会不相同。所以包头的解析依赖Version字段
- CID,CID是变长的,包头保护依赖sample,sample的位置不是固定的
- Token,Initial Packet这个字段是空。Retry包或者NEW_TOKNE帧有这个字段,本身是经过加密的
三:包头加解密算法
一张图总结一下QUIC的Initail packet包头保护加密的过程
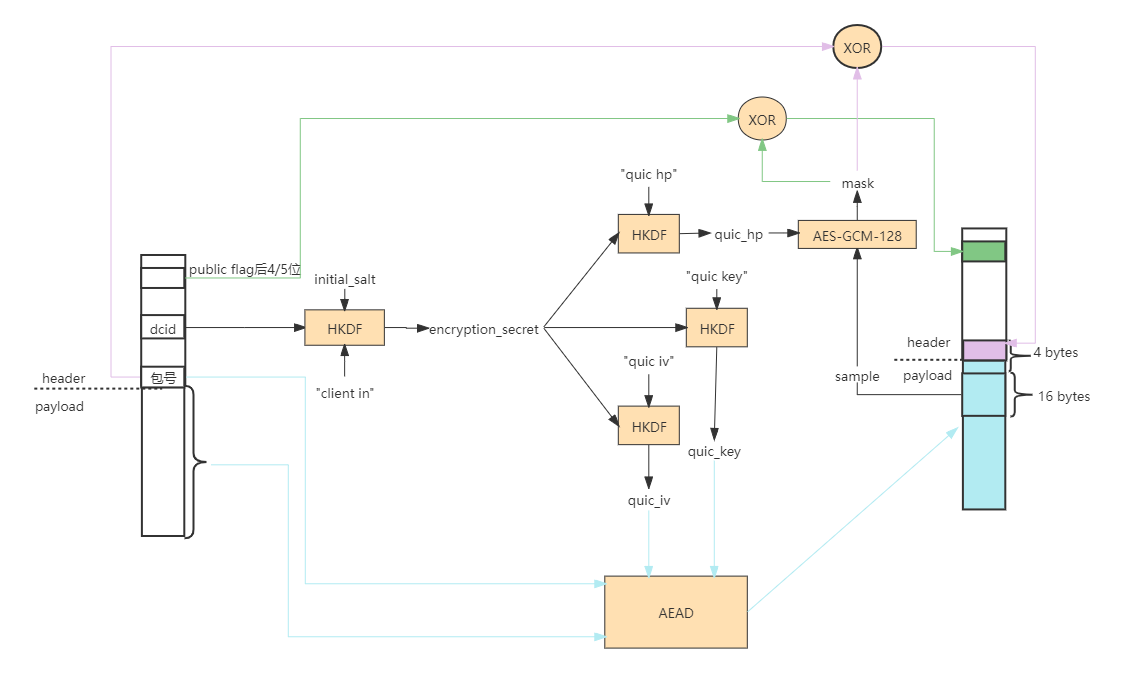
待完善。。。。