从零开始 Spring Cloud 15:多级缓存
多级缓存架构
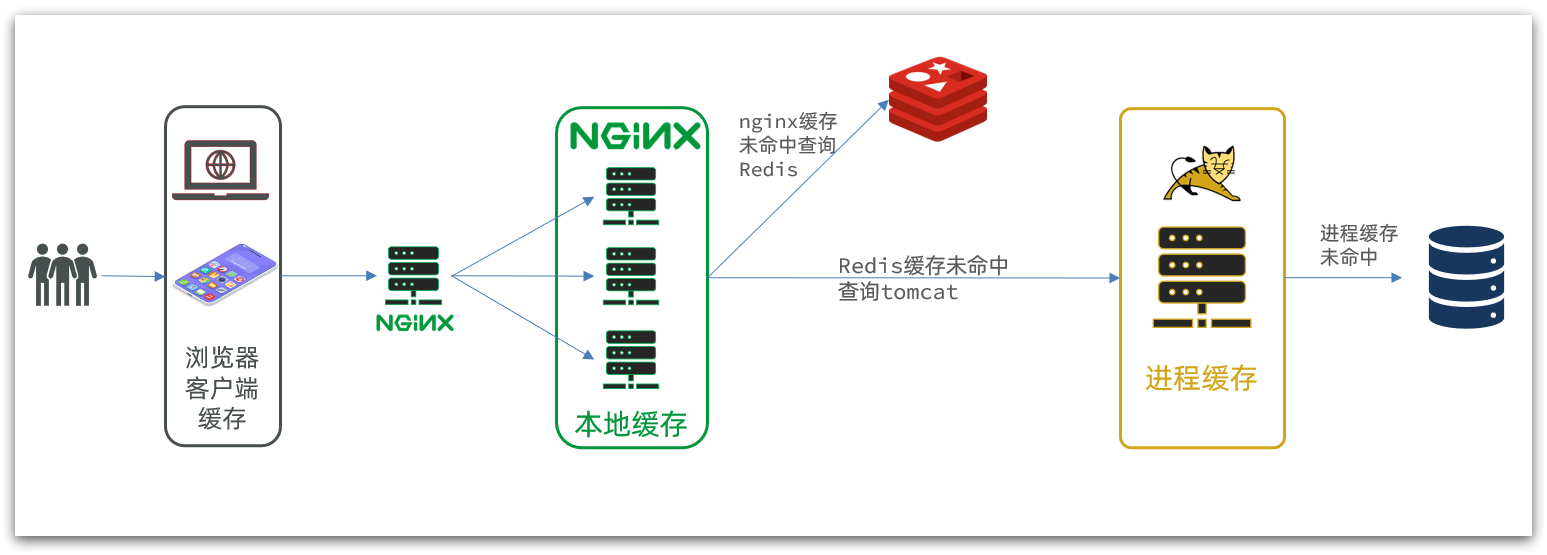
传统的缓存使用 Redis,大致架构如下:

这个架构存在一些问题:
-
请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
-
Redis缓存失效时,会对数据库产生冲击
可以使用多级缓存来解决这个问题:

具体过程为:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取 Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库
传统架构中的 Nginx 仅仅充当 Tomcat 的反向代理服务器,所以只要部署一个实例就可以了,在这个新架构中,Nginx 上同样要实现业务逻辑,以便直接从 Redis 上查询业务数据,所以为了提高可靠性, Nginx 同样需要集群部署:
当然,Tomcat 作为主要业务代码的托管方,也要集群部署:
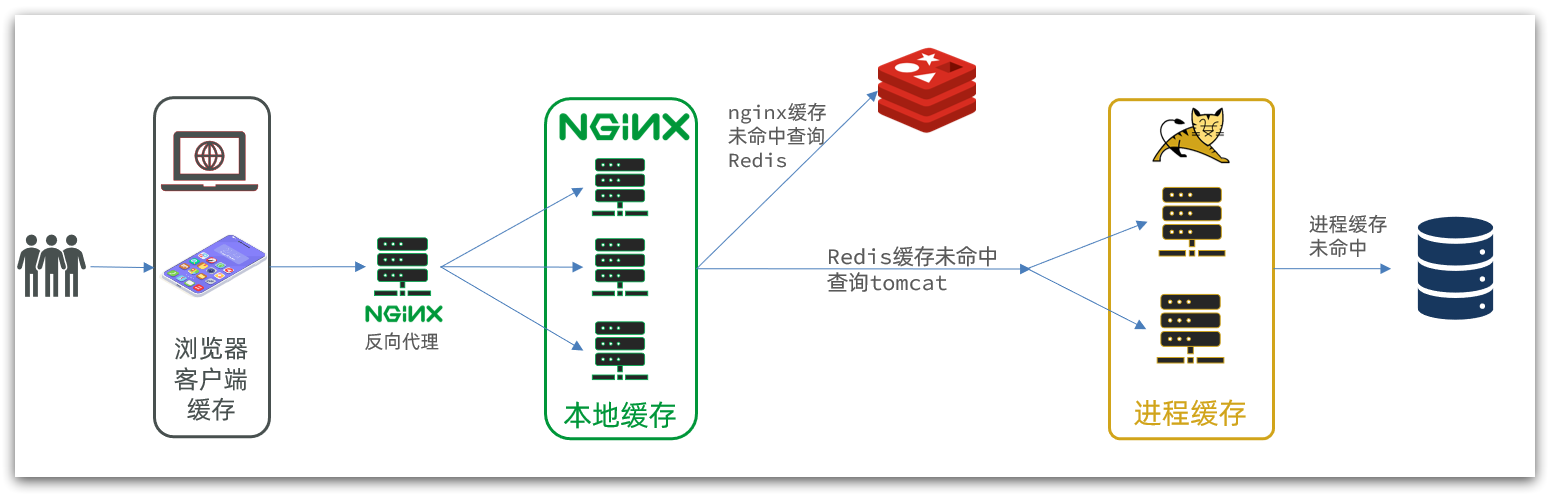
JVM 进程缓存
导入案例
在继续教程前,需要先导入示例工程,具体可以阅读案例导入说明。
Caffine
缓存可以按照存储的位置大致分为两类:
- 分布式缓存,例如Redis:
- 优点:存储容量更大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
下面我们会使用 Caffeine 作为本地缓存。
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
简单示例
示例项目中已经引入了 Caffine 的依赖:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
用 Caffine 写一个使用本地缓存的简单示例:
@Test
void simpleTest(){
Cache<String, String> cache = Caffeine.newBuilder()
.build();
String name = cache.getIfPresent("name");
if (name == null){
System.out.println("缓存未命中,写入缓存");
cache.put("name", "icexmoon");
System.out.println("从缓存读取");
name = cache.getIfPresent("name");
}
System.out.println(name);
}
Cache.getIfPresent 会在未命中缓存时返回 null,这和使用容器作为内存缓存时用法是类似的。不过 Caffine 提供更方便的 API:
@Test
void simpleTest2(){
Cache<String, String> cache = Caffeine.newBuilder()
.build();
String name = cache.get("name", key-> "icexmoon");
System.out.println(name);
}
Cache.get方法会先检查缓存中是否有,如果有就直接返回,如果没有,就使用参数列表中的 Lamda 表达式生成缓存值,写入缓存,然后再返回。整个过程和上边的示例是相同的,但写法要简洁很多。
缓存驱逐
所有的缓存机制都需要考虑缓存驱逐(过期)的问题,以防止存储空间被耗尽。
Caffine 有三种缓存驱逐策略可选:
-
基于容量:设置缓存的数量上限
// 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder() .maximumSize(1) // 设置缓存大小上限为 1 .build(); -
基于时间:设置缓存的有效时间
// 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder() // 设置缓存有效期为 10 秒,从最后一次写入开始计时 .expireAfterWrite(Duration.ofSeconds(10)) .build(); -
基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
实现 JVM 进程缓存
下面使用 Caffine 在示例项目中实现 JVM 进程缓存。
这里使用 Caffine 缓存商品详情和商品库存的查询结果。
首先在配置类中将缓存对象定义为 Spring Bean:
@Configuration
public class WebConfig {
/**
* 商品详情缓存
* @return
*/
@Bean
public Cache<Long, Item> itemCache() {
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10000)
.build();
}
/**
* 库存缓存
* @return
*/
@Bean
public Cache<Long, ItemStock> itemStockCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10000)
.build();
}
}
在 Controller 中使用缓存对象缓存查询结果:
@RestController
@RequestMapping("item")
public class ItemController {
// ...
@Autowired
private Cache<Long, Item> itemCache;
@Autowired
private Cache<Long, ItemStock> itemStockCache;
// ...
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id) {
return itemCache.get(id, key -> itemService.query()
.ne("status", 3).eq("id", key)
.one());
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id) {
return itemStockCache.get(id, key -> stockService.getById(key));
}
}
Lua
在 Nginx 上实现业务代码需要使用 Lua 作为编程语言,所以下面先学习 Lua。
介绍
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。官网:https://www.lua.org/
Lua经常嵌入到C语言开发的程序中,例如游戏开发、游戏插件等。
Nginx本身也是C语言开发,因此也允许基于Lua做拓展。
Hello World
首先查看虚拟机上是否已经安装了 Lua:
[icexmoon@192 tmp]$ lua -v
Lua 5.4.4 Copyright (C) 1994-2022 Lua.org, PUC-Rio
如果没有安装,用包管理器安装:
[icexmoon@192 tmp]$ sudo yum install lua
添加一个简单的 Lua 代码文件hello.lua,内容如下:
[icexmoon@192 tmp]$ cat hello.lua
print("Hello World!");
运行:
[icexmoon@192 tmp]$ lua hello.lua
Hello World!
基本语法
数据类型
Lua 中的数据类型分为以下几种:

这里的类型table相当于 PHP 中的关联数组,可以用纯数字作为 KEY,也可以用字符串作为 KEY。
通过type()函数可以判断变量的类型:
[icexmoon@192 tmp]$ lua
Lua 5.4.4 Copyright (C) 1994-2022 Lua.org, PUC-Rio
> print(type('hello'))
string
> print(type(12.5))
number
> print(type({1,2,3}))
table
直接使用
lua命令可以进入一个交互式编程的界面,类似 Python。
变量声明
在 Lua 中声明变量不需要说明变量类型,这类似于 Go 或 Python 的类型推断机制,编程语言可以根据赋值操作符右侧的实际类型来给变量设置相应的类型:
-- 声明一个字符串
local str='hello'
-- 声明一个数字
local num=123
-- 字符串连接
local str2=str .. ' world'
-- 声明一个 bool 类型
local b = true
function printVar(var)
print(type(var))
print(var)
end
printVar(str)
printVar(num)
printVar(str2)
printVar(b)
这里printVar是一个自定义函数,用于打印变量内容和变量类型。Lua 与某些编程语言一样,函数声明必须放在使用函数的语句之前,否则会报语法错误。
Lua 中注释语句用--标注,而非常见的#或//。
Lua 中拼接字符串使用..。
遍历数组需要使用循环语句:
-- 声明一个数组
local arr={1,1,2,3,5}
-- 遍历数字索引的数组
for key,val in ipairs(arr) do
print(key, val)
end
-- 声明一个关联数组
local person={name='icexmoon', age=12}
-- 遍历关联数组
for key,val in pairs(person) do
print(key, val)
end
语法和 Python 类似,需要注意的是,遍历纯数字索引的数组时,使用的是ipairs,遍历字符串索引的数组时,使用的是pairs。
此外,使用字符串作为索引的数组时,声明数组时{}内部的 KEY 可以不用引号包裹,类似于 js 中声明对象的方式。
要注意的是,在 Lua 中,纯数字索引的数组下标是从 1 开始,而非 0。
函数
Lua 中函数的语法:
function 函数名( argument1, argument2..., argumentn)
-- 函数体
return 返回值
end
如果没有返回值,return语句可以省略。
示例:将数组遍历和打印封装成函数:
local function printMap(map)
for key,val in pairs(map) do
print(key, val)
end
end
local function printArr(arr)
for key,val in ipairs(arr) do
print(key, val)
end
end
-- 声明一个数组
local arr={1,1,2,3,5}
-- 遍历数字索引的数组
printArr(arr)
-- 声明一个关联数组
local person={name='icexmoon', age=12}
-- 遍历关联数组
printMap(person)
与变量声明类似,声明函数同样可以使用local关键字,这样声明的函数作用域是局部而非全局。
条件控制
Lua 的条件控制语句与 Python 或 Bash 类似:
if(布尔表达式)
then
--[ 布尔表达式为 true 时执行该语句块 --]
else
--[ 布尔表达式为 false 时执行该语句块 --]
end
示例:在遍历打印数组时判断作为参数的数组是否为 null:
local function printMap(map)
if(map == nil)
then
print('数组不能为null')
return
end
for key,val in pairs(map) do
print(key, val)
end
end
printMap(nil)
实现多级缓存
要在 Nginx 上实现业务逻辑,需要进行 Nginx 编程,这里使用基于 OpenResty 的 Lua 编程。
安装 OpenResty
penResty® 是一个基于 Nginx的高性能 Web 平台,用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。具备下列特点:
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库
官方网站: https://openresty.org/cn/
先在 Linux 上安装 OpenResty 及其相关组件,具体过程可以阅读这篇文章。
Nginx 编程
下面用一个简单示例说明如何实现基于 OpenResty 和 Lua 的 Nginx 编程。
首先需要在 OpenResty 的 Nginx 配置文件中添加相关模块的引用:
http {
# ...
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
}
部署在本地 Nginx 的静态资源文件item.html的访问路径是:http://localhost/item.html?id=10001。
其获取商品详细信息的接口调用是 http://localhost/api/item/10001,现在我们要在 Linux 上的 OpenResty 中用 Lua 编程的方式响应这个接口调用。
首先修改本地 Nginx 中的反向代理的集群信息,服务器地址改为 Linux 主机上的 OpenResty 的地址:
upstream nginx-cluster{
server 192.168.0.88:8081;
}
在 OpenResty 的 Nginx 配置文件中添加一个路径规则:
http {
# ...
server {
listen 8081;
server_name localhost;
location /api/item {
# 默认的响应类型
default_type application/json;
# 响应结果由lua/item.lua文件来决定
content_by_lua_file lua/item.lua;
}
}
}
在 OpenResty 的 Nginx 目录中创建配置文件中指定的 Lua 文件:
[root@192 conf]# cd ..
[root@192 nginx]# pwd
/usr/local/openresty/nginx
[root@192 nginx]# mkdir lua
[root@192 nginx]# vim ./lua/item.lua
其内容为:
ngx.say('{"id":10001,"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
内容很简单,就是直接输出一个 json 格式的字符串到响应报文,以模拟接口响应。
重启 OpenResty 中的 Nginx;
nginx -s reload
现在再访问本地 Nginx 的商品详情页就能看到/api/item/xxx的接口调用已经可以正常被反向代理到 OpenResty,并返回响应结果。
获取请求参数
用 Lua 获取请求参数的方式如下:

在当前示例中,OpenResty 接收的请求路径是 http://192.168.0.88:8081/api/item/10001,所以需要用在 Nginx 配置文件中对路径规则使用正则表达式的方式来让 Lua 脚本获取路径中的路径参数。
修改 OpenResty 的 Nginx 配置:
location ~ /api/item/(\d+){
# ...
}
修改用于生成接口响应信息的 Lua 脚本/lua/item.lua:
local id = ngx.var[1]
ngx.say('{"id":'..id..',"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
现在接口返回的响应信息中的id是从请求路径中的路径参数获取,不再是纯粹的假数据。
这点可以通过请求 http://192.168.0.88:8081/api/item/10003 进行验证。
查询 Tomcat
要在 Nginx 上编写的主要业务逻辑是查询 Redis,如果 Redis 缺少相应的缓存信息就通过查询具体业务服务器的 Tomcat 来获取结果并缓存到 Redis。
在学习如何用 Lua 在 OpenResty 上查询 Redis 前,我们先看在不使用 Redis 缓存的情况下,如何用 Lua 通过查询 Tomcat 获取结果。
发送 HTTP 请求
Lua 可以通过以下 API 发送一个 HTTP 请求:
local resp = ngx.location.capture("/path",{
method = ngx.HTTP_GET, -- 请求方式
args = {a=1,b=2}, -- get方式传参数
})
返回的响应内容包括:
- resp.status:响应状态码
- resp.header:响应头,是一个table
- resp.body:响应体,就是响应数据
需要注意的是,这里作为请求路径的/path不包括 IP 和端口,所以只是对所在 Nginx(OpenResty)的本地请求。所以要让这个请求转发到运行在本地电脑上的 Tomcat(SpringBoot 应用),就需要配置反向代理,比如:
location /path {
# 这里是windows电脑的ip和Java服务端口,需要确保windows防火墙处于关闭状态
proxy_pass http://192.168.150.1:8081;
}
封装工具函数
因为会频繁使用 Lua 进行 HTTP 调用,所以这里可以将调用 HTTP 请求的代码封装成一个工具函数,放在/usr/local/openresty/lualib/common.lua 这个 Lua 脚本文件中。
内容如下:
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if resp == nil then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http请求查询失败, path: ", path , ", args: ", args)
ngx.exit(404)
return nil
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http
}
return _M
这个工具将read_http函数封装到_M这个table类型的变量中,并且返回,这类似于导出。
使用的时候,可以利用require('common')来导入该函数库,这里的 common 是函数库的文件名。
前面已经在 OpenResty 的 Nginx 配置文件中通过
lua_package_path "/usr/local/openresty/lualib/?.lua;;";加载了lualib下的 Lua 脚本,所以可以直接使用。
现在使用封装好的工具函数实现对商品详情的查询:
-- 导入 common 函数
local common = require('common')
local read_http = common.read_http
local id = ngx.var[1]
-- 查询商品详情
local itemJson = read_http('/item/'..id, nil)
ngx.say(itemJson)
修改 OpenResty 的 Nginx 配置,将 /item 路径的请求反向代理到 Tomcat:
location /item {
proxy_pass http://192.168.0.46:8081;
}
这里的
192.168.0.46是运行 SpringBoot 应用的宿主机所在的局域网 IP。
重启 OpenResty:
nginx -s reload
请求 OpenReasty 的接口 http://192.168.0.88:8081/api/item/10003 ,就能看到返回的商品详情:
{
"id": 10003,
"name": "韩版牛仔裤",
"title": "唐狮新品牛仔裤女学生韩版宽松裤子 A款/中牛仔蓝(无绒款) 26",
"price": 84600,
"image": "https://m.360buyimg.com/mobilecms/s720x720_jfs/t26989/116/124520860/644643/173643ea/5b860864N6bfd95db.jpg!q70.jpg.webp",
"category": "牛仔裤",
"brand": "唐狮",
"spec": "{\"颜色\": \"蓝色\", \"尺码\": \"26\"}",
"status": 1,
"createTime": "2019-04-30T16:00:00.000+00:00",
"updateTime": "2019-04-30T16:00:00.000+00:00",
"stock": null,
"sold": null
}
现在商品详情信息不再是假数据,而是通过 SpringBoot 应用的 Tomcat 查询到的结果。
CJSON
上边返回的数据中库存和销量信息是 null,这是因为库存相关信息在这个示例项目中需要通过一个额外接口查询获取,在这里可以用 Lua 脚本分别查询两个接口,并对结果进行拼接来实现在一个 OpenResty 接口中提供所有的商品信息。
因为 SpringBoot(Tomcat) 接口返回的信息是 JSON 格式的字符串,要进行拼接就需要对 JSON 字符串解析。这里用到的解析 JSON 字符串的 Lua 函数库是 cjson,其官网是:
https://github.com/openresty/lua-cjson/
OpenResty 已经默认包含了这个函数库:
[root@192 nginx]# ll /usr/local/openresty/lualib/
总用量 72
-rwxr-xr-x. 1 root root 37480 7月 18 12:40 cjson.so
.so 是 C 编写的函数库,Lua 可以直接使用 C 编写的函数库。
所以我们只需要直接使用:
-- 导入 common 函数
local common = require('common')
-- 导入 cjson 函数库
local cjson = require('cjson')
local read_http = common.read_http
local id = ngx.var[1]
-- 查询商品详情
local itemJson = read_http('/item/'..id, nil)
local item = cjson.decode(itemJson)
-- 查询商品库存
local stockJson = read_http('/item/stock/'..id, nil)
local stock = cjson.decode(stockJson)
-- 拼接结果
item.stock = stock.stock
item.sold = stock.sold
ngx.say(cjson.encode(item))
其中cjson.decode用于解析 JSON 字符串为 table 类型的变量,cjson.encode用于将 table 类型的变量编码成 JSON 字符串。
现在再请求接口,就能看到库存和销量信息。
Tomcat 集群的负载均衡
通常我们的 Tomcat 是集群部署:

所以需要在 OpenResty 中配置负载均衡:
http {
# ...
upstream tomcat-cluster {
server 192.168.0.46:8081;
server 192.168.0.46:8082;
}
server {
# ...
location /item {
proxy_pass http://tomcat-cluster;
}
# ...
}
}
现在的系统架构如下:

虽然8081和8082的 Tomcat 的商品信息查询接口都有本地缓存,但因为 Nginx 的负载均衡默认规则是轮询,所以即使是对同一个商品的两次连续查询,也会出现先查询 8081,生成本地缓存,再查询 8082,同样生成本地缓存的现象。
这就需要改变 Nginx 的负载均衡策略实现优化,具体实现很简单:
upstream tomcat-cluster {
hash $request_uri;
server 192.168.0.46:8081;
server 192.168.0.46:8082;
}
这里的hash $request_uri;,将负载均衡规则修改为对请求的路径进行 hash,将 hash 值取余后对应到 Tomcat 集群的一个具体服务器上,对于固定的请求路径,其映射结果必然是固定的,所以就不会存在轮询规则时重复生成本地缓存的问题。
这种映射策略和 Redis 分片集群时将 KEY 映射到插槽(slot)的策略是类似的。
Redis 缓存预热
Redis缓存会面临冷启动问题:
冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。
在我们这个示例中,将会简单的将所有商品和库存信息提前缓存到 Redis 中作为预热。
首先准备一个 Redis,这里我使用 LInux 中使用 Docker 运行的 Redis。
具体的安装和运行可以参考Docker 官方文档。
在项目中添加 Redis 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
添加 Redis 连接信息到配置文件:
spring:
redis:
host: 192.168.0.88
编写一个配置类实现应用初始化后对 Redis 缓存进行预热:
@Configuration
public class InitConfig {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private ItemService itemService;
@Autowired
private IItemStockService itemStockService;
@Bean
CommandLineRunner commandLineRunner() {
return args -> {
ObjectMapper objectMapper = new ObjectMapper();
// 获取所有的商品信息
List<Item> items = itemService.list();
for (Item item : items) {
// 将商品信息写入 Redis 缓存
stringRedisTemplate.opsForValue().set("item:id:" + item.getId(), objectMapper.writeValueAsString(item));
}
// 获取所有库存信息
List<ItemStock> stocks = itemStockService.list();
for (ItemStock itemStock : stocks) {
// 将库存信息写入 Redis 缓存
stringRedisTemplate.opsForValue().set("item:stock:id:" + itemStock.getId(), objectMapper.writeValueAsString(itemStock));
}
};
}
}
- 这里使用 CommandLineRunner 编写需要在 SpringBoot 应用初始化后执行的代码,相关内容可以阅读这篇文章。
ObjectMapper是 Spring 自带的 JSON 处理包 Jackson 用于编码和解码 JSON 的类。
重启应用后就能用 Redis 客户端查看到 Redis 中生成的缓存信息:

这里将库存信息和商品信息分别缓存而不是整合后缓存,有一个好处是对于库存这种会频繁改变的信息,改变后会触发库存缓存刷新,但不影响商品基本信息的缓存。
查询 Redis 缓存
要使用 Lua 查询 Redis 缓存,使用的是 OpenResty 提供的 redis 模块:
[root@192 openresty]# pwd
/usr/local/openresty
[root@192 openresty]# ll lualib/resty | grep redis
-rw-r--r--. 1 root root 15841 7月 18 12:40 redis.lua
该模块位于/lualib/resty/redis.lua。
在/lualib/common.lua中添加 Redis 连接的代码:
-- 引入 Redis 模块
local redis = require('resty.redis')
-- 初始化连接客户端
local redisClient = redis:new()
redisClient:set_timeouts(1000, 1000, 1000)
这里的redis:new()是创建一个对象,redisClient:set_timeouts是调用对象的方法。在这个里这个方法的用途是设置客户端连接超时的等待时间。
添加一个关闭 Redis 连接的工具函数:
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
,这里并不会真的关闭连接,而是创建一个连接池,将连接放入连接池进行管理,以进行连接复用。
添加查询 Redis 的工具函数:
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = redisClient:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
close_redis(redisClient)
return nil
end
--得到的数据为空处理
if resp == ngx.null then
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
close_redis(redisClient)
return nil
end
close_redis(redisClient)
return resp
end
将读取 Redis 缓存的方法导出:
-- 将方法导出
local _M = {
read_http = read_http,
read_redis = read_redis
}
现在利用工具函数read_redis实现先从 Redis 读取数据的业务逻辑:
-- 导入 common 函数
local common = require('common')
-- 导入 cjson 函数库
local cjson = require('cjson')
local read_http = common.read_http
local read_redis = common.read_redis
-- 先尝试从 Redis 中读取数据,如果没有,再从 Tomcat 中读取
local function read_data(key, path, params)
local value = read_redis('127.0.0.1', 6379, key)
if value ~= nil then
-- 从缓存中获取到数据,直接返回
return value
end
-- 没有从缓存中查询到数据,从 Tomcat 获取
ngx.log(ngx.ERR, '没有从 Redis 缓存中查询到数据,尝试从 Tomcat 获取数据')
value = read_http(path, params)
return value
end
local id = ngx.var[1]
-- 查询商品详情
local itemJson = read_data('item:id:'..id, '/item/'..id, nil)
local item = cjson.decode(itemJson)
-- 查询商品库存
local stockJson = read_data('item:stock:id:'..id, '/item/stock/'..id, nil)
local stock = cjson.decode(stockJson)
-- 拼接结果
item.stock = stock.stock
item.sold = stock.sold
ngx.say(cjson.encode(item))
注意,Lua 中表示“不等于”的逻辑运算符是
~=,而非常见的!=。
重启 Nginx:
nginx -s reload
现在即使关闭 SpringBoot 应用,依然可以通过 OpenResty 的接口获取返回的数据,因为这里 OpenResty 可以从 Redis 直接获取缓存数据并返回。
Nginx 本地缓存
可以在 OpenResty 查询 Redis 缓存之前,再增加 OpenResty 的本地缓存,用于进一步提高性能。
API
OpenResty为Nginx提供了shard dict的功能,可以在nginx的多个worker之间共享数据,实现缓存功能。
1)开启共享字典,在nginx.conf的http下添加配置:
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
2)操作共享字典:
-- 获取本地缓存对象
local item_cache = ngx.shared.item_cache
-- 存储, 指定key、value、过期时间,单位s,默认为0代表永不过期
item_cache:set('key', 'value', 1000)
-- 读取
local val = item_cache:get('key')
实现本地缓存
修改 OpenResty 的配置文件,增加共享字典:
http {
lua_shared_dict item_cache 150m;
# ...
}
修改脚本 item.lua:
-- 导入共享字典
local item_cache = ngx.shared.item_cache
-- 导入 common 函数
local common = require('common')
-- 导入 cjson 函数库
local cjson = require('cjson')
local read_http = common.read_http
local read_redis = common.read_redis
-- 先尝试从 Redis 中读取数据,如果没有,再从 Tomcat 中读取
local function read_data(key, expire, path, params)
-- 先尝试从共享字典中查询结果
local value = item_cache:get(key)
if value ~= nil then
-- 从共享字典中查询到数据,直接返回
return value
end
-- 没有从共享字典中查询到数据,从 Redis 缓存中获取
ngx.log(ngx.ERR, '没有从共享字典中查询到数据,尝试从 Redis 获取数据, key:', key)
value = read_redis('127.0.0.1', 6379, key)
if value ~= nil then
-- 从缓存中获取到数据,直接返回
-- 缓存到共享字典
item_cache:set(key, value, expire)
return value
end
-- 没有从缓存中查询到数据,从 Tomcat 获取
ngx.log(ngx.ERR, '没有从 Redis 缓存中查询到数据,尝试从 Tomcat 获取数据, key:', key)
value = read_http(path, params)
-- 如果结果不为 null, 缓存到共享字典
if value ~= nil then
item_cache:set(key, value, expire)
end
return value
end
local id = ngx.var[1]
-- 查询商品详情
local itemJson = read_data('item:id:'..id, 1800, '/item/'..id, nil)
local item = cjson.decode(itemJson)
-- 查询商品库存
local stockJson = read_data('item:stock:id:'..id, 60, '/item/stock/'..id, nil)
local stock = cjson.decode(stockJson)
-- 拼接结果
item.stock = stock.stock
item.sold = stock.sold
ngx.say(cjson.encode(item))
对于商品信息和库存信息,共享字典中的缓存数据时间不同,前者为半小时,后者为1分钟。
缓存同步
同步策略
缓存数据同步的常见方式有三种:
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
**异步通知:**修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
而异步通知实现又可以基于MQ或者Canal来实现:
1)基于MQ的异步通知:

解读:
- 商品服务完成对数据的修改后,只需要发送一条消息到MQ中。
- 缓存服务监听MQ消息,然后完成对缓存的更新
依然有少量的代码侵入。
2)基于Canal的通知
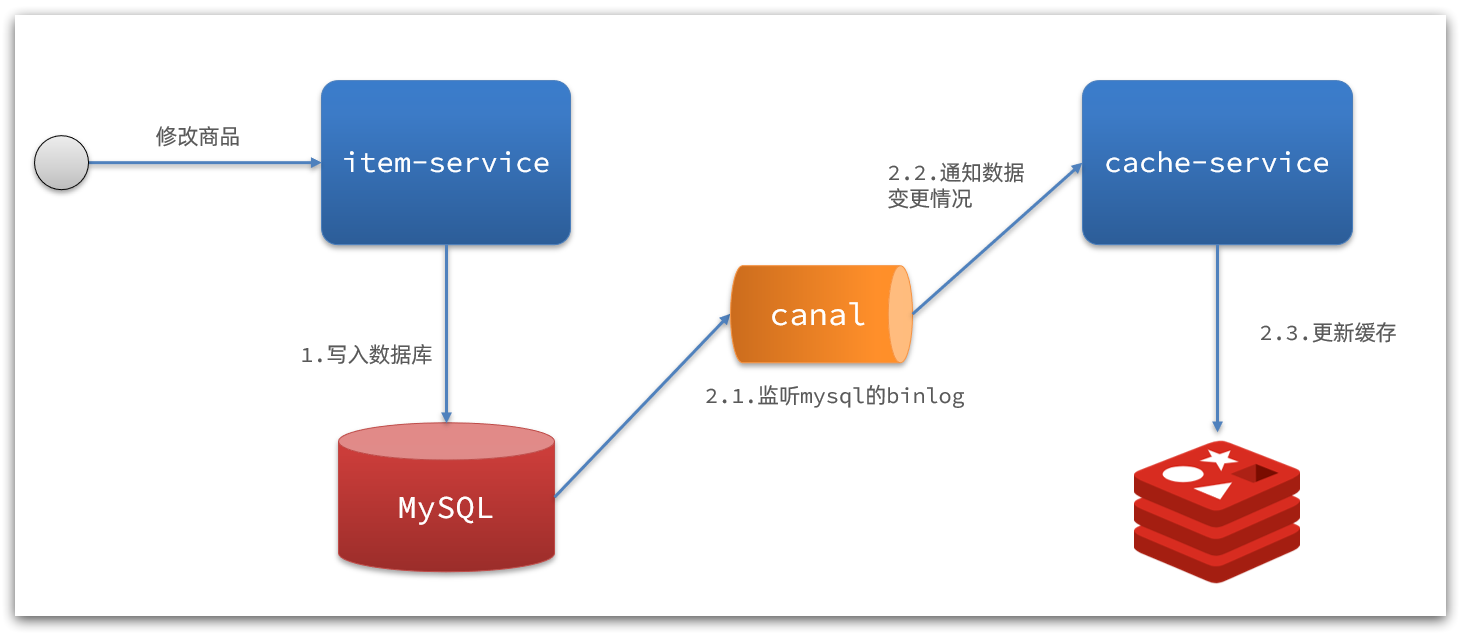
解读:
- 商品服务完成商品修改后,业务直接结束,没有任何代码侵入
- Canal监听MySQL变化,当发现变化后,立即通知缓存服务
- 缓存服务接收到canal通知,更新缓存
代码零侵入
安装 Canal
Canal [kə’næl],译意为水道/管道/沟渠,canal是阿里巴巴旗下的一款开源项目,基于Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。GitHub的地址:https://github.com/alibaba/canal
Canal是基于mysql的主从同步来实现的,MySQL主从同步的原理如下:

- 1)MySQL master 将数据变更写入二进制日志( binary log),其中记录的数据叫做binary log events
- 2)MySQL slave 将 master 的 binary log events拷贝到它的中继日志(relay log)
- 3)MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
而Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。再把得到的变化信息通知给Canal的客户端,进而完成对其它数据库的同步。

具体的安装过程可以参考这篇文章。
监听 Canal
在 SpringBoot 项目中使用 Canal 客户端监听 Canal服务端,以实现在商品相关表数据变更时对缓存数据进行更新。
架构图如下:
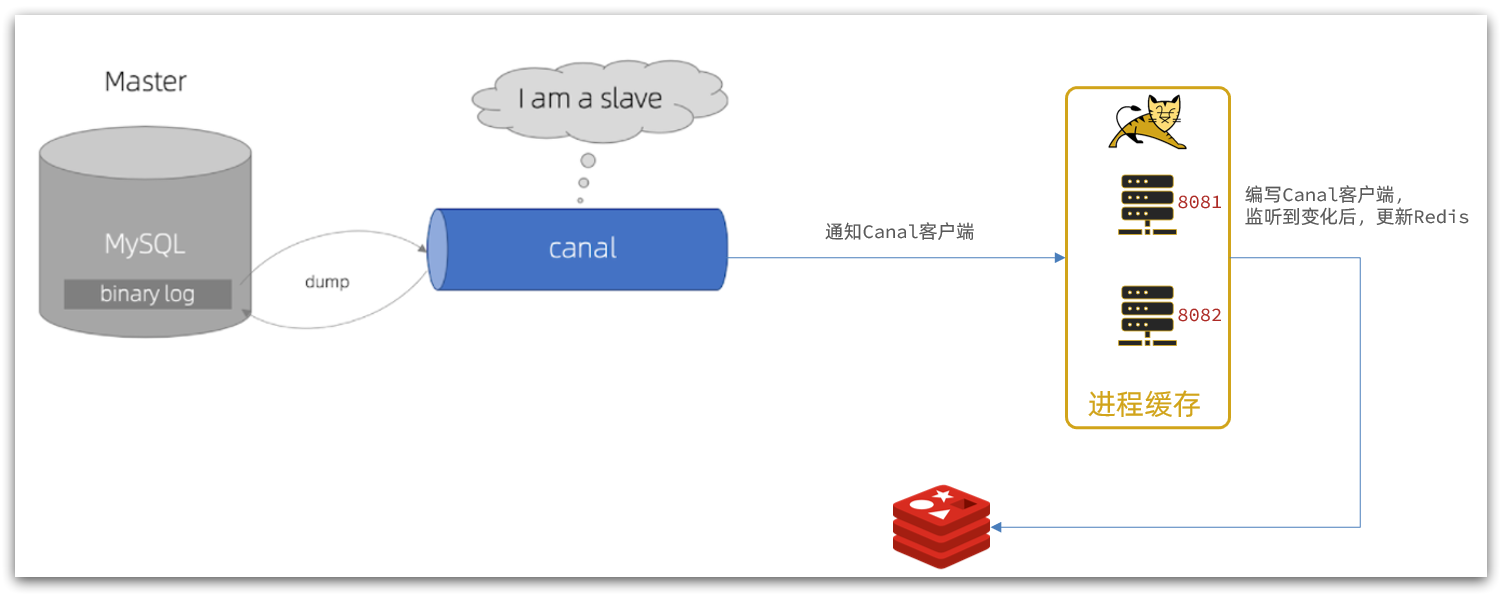
添加依赖
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>
这里添加的依赖并非 Canal 官方的客户端依赖,而是一个第三方依赖,比官方依赖更易使用。
添加配置
canal:
destination: heima # canal的集群名字,要与安装canal时设置的名称一致
server: 192.168.0.88:11111 # canal 服务端地址
添加监听
@CanalTable("tb_item")
@Component
public class ItemHandler implements EntryHandler<Item> {
@Override
public void insert(Item item) {
EntryHandler.super.insert(item);
}
@Override
public void update(Item before, Item after) {
EntryHandler.super.update(before, after);
}
@Override
public void delete(Item item) {
EntryHandler.super.delete(item);
}
}
@CanalTable注解说明了要监听的是哪个表数据的变化,EntryHandler是一个泛型接口,其泛型参数是监听表对应的实体类。EntryHandler接口有三个方法,分别对应表数据的新增、更新和删除。
MyBatis 依赖一些注解来组装实体类,Canal 同样也需要依赖一些注解组装实体类。所以这里需要给实体类添加 Canal 需要的注解:
@Data
@TableName("tb_item")
public class Item {
@Id
@TableId(type = IdType.AUTO)
private Long id;//商品id
private String name;//商品名称
private String title;//商品标题
private Long price;//价格(分)
private String image;//商品图片
private String category;//分类名称
private String brand;//品牌名称
private String spec;//规格
private Integer status;//商品状态 1-正常,2-下架
@Column(name = "create_time")
private Date createTime;//创建时间
@Column(name = "update_time")
private Date updateTime;//更新时间
@Transient
@TableField(exist = false)
private Integer stock;
@Transient
@TableField(exist = false)
private Integer sold;
}
这里用@id标记作为主键的字段,用@Transient标记不存在于表中的字段。
这两个注解都是 Spring 的注解,属于
org.springframework.data.annotation包。
如果类属性与表字段名不一致,比如上边的createTime和updateTime,还需要用@Column标明属性对应的表字段名称。
这里的
@Column注解属于 Java 注解,位于javax.persistence包。
现在可以实现监听类中具体的缓存更新逻辑:
@CanalTable("tb_item")
@Component
public class ItemHandler implements EntryHandler<Item> {
@Autowired
private RedisHandler redisHandler;
@Autowired
private Cache<Long, Item> itemCache;
@Override
public void insert(Item item) {
// 写入本地 JVM 缓存
itemCache.put(item.getId(), item);
// 写入 Redis 缓存
redisHandler.saveItem2Redis(item);
}
@Override
public void update(Item before, Item after) {
// 写入本地 JVM 缓存
itemCache.put(after.getId(), after);
// 写入 Redis 缓存
redisHandler.saveItem2Redis(after);
}
@Override
public void delete(Item item) {
// 从本地 JVM 缓存删除
itemCache.invalidate(item.getId());
// 从 Redis 缓存删除
redisHandler.deleteItemFromRedis(item.getId());
}
}
重启 SpringBoot 应用后,可以直接修改 MySQL 中的表数据(比如商品表的价格字段)以观察 Redis 中的缓存数据是否发生变化。
总结
示例项目最终的架构图为:
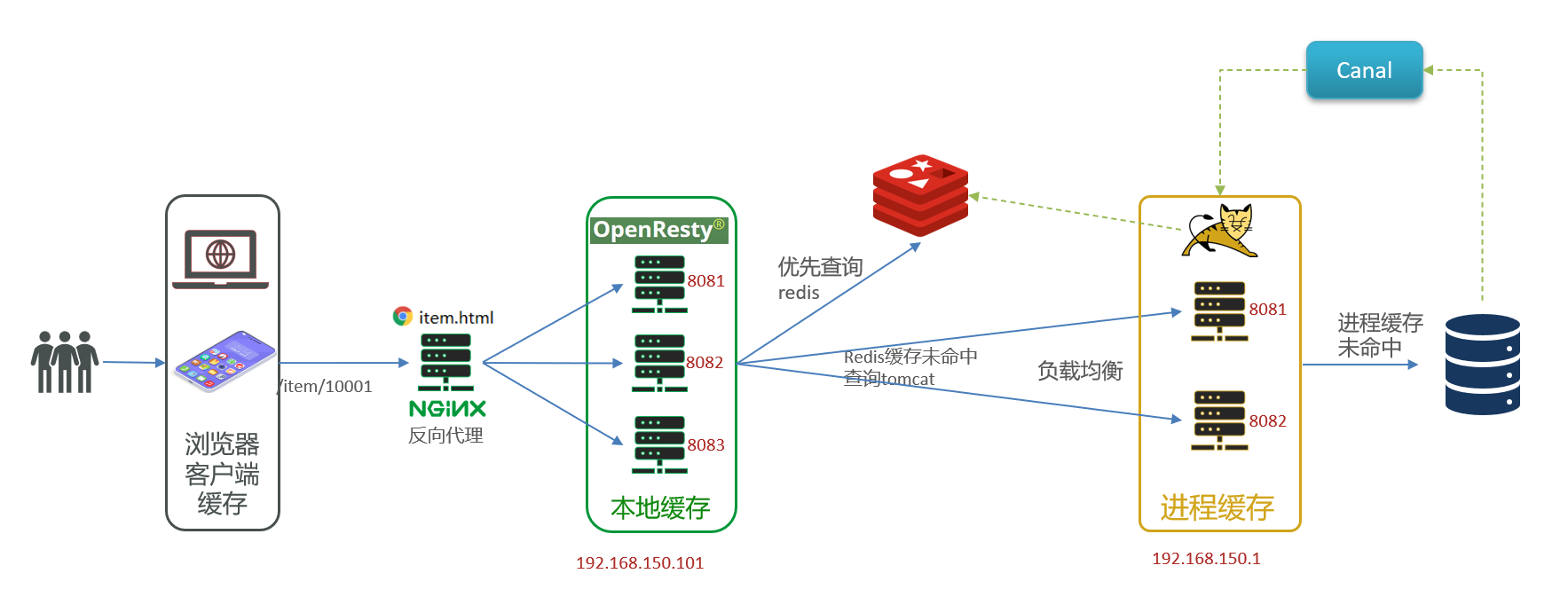
使用了 OpenResty 本地缓存、Redis 缓存、Tomcat 的 JVM 缓存多级缓存数据,同时用 Canal 对 Redis 缓存和 JVM 本地缓存进行数据同步。
OpenResty 的本地缓存采取简单的过期方式进行数据同步。
本文的完整示例代码可以从这里获取。
参考资料
- Lua 5.3 参考手册 (runoob.com)