大家好,我是微学AI,今天给大家介绍一下大模型的实践应用3-大模型的基础架构Transformer模型,掌握Transformer就掌握了大模型的灵魂骨架。Transformer是一种基于自注意力机制的深度学习模型,由Vaswani等人在2017年的论文《Attention is All You Need》中提出。它最初被设计用来处理序列到序列(seq2seq)任务,如机器翻译,但现在已经广泛应用于各种NLP任务。下面我们将详细介绍其网络结构。
一、Transformer的结构介绍
我们需要理解Transformer模型的整体架构。这个模型由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器读取输入序列,并生成一个连续的表示;解码器则利用这个表示生成输出序列。
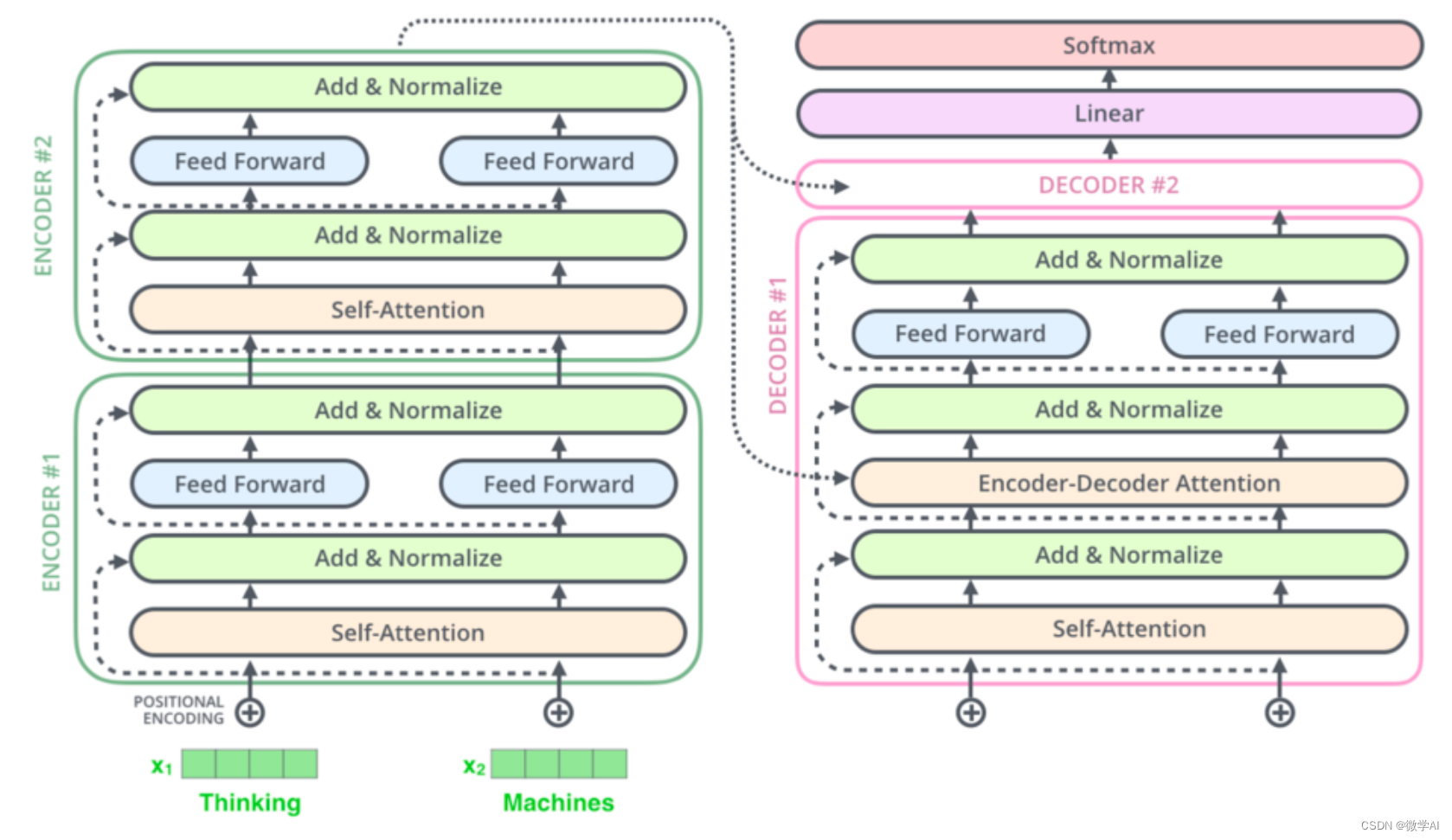
1.数据输入层:
输入数据通常是一段文本或者句子,比如“我喜欢看书”。为了让计算机能理解这段文本,我们需要把每个单词转换成计算机能理解的形式。这就涉及到了下一个环节——词嵌入。
2.词嵌入:
在词嵌入阶段,每个单词会被映射到一个高维空间中的向量。例如,“我”可能被映射为[0.1, 0.3, …, 0.5],“喜欢”可能被映射为[0.2, 0.4, …, 0.6]。这样做的目标是使得语义相近的单词在高维空间中位置接近。词嵌入是将离散的词语映射到连续的向量空间。假设我们有一个大小为