Hive SQL 加载数据
之前我们加载数据是,创建一张表,将结构化文件放到hadoop对应表路径下。这样我们就将表和文件进行映射了。但是这样比较暴力,官方不推荐。
这样的操作是直接跳过了Hive
Load加载数据
语法:
load data [local] inpath ‘filepath’ [overwrite] into table tablename;
写了local就是指本地文件系统,不管你客户端在哪里,指的是hive服务所在的本地文件系统。
不写local就是指hdfs文件系统

create table test.student_local(
num int,
name string,
sex string,
age int,
dept string
)row format delimited
fields terminated by ",";
-- 加载本地文件,是复制的动作,源文件还在!
load data local inpath '/hivedata/student.txt' into table test.student_local;
-- 加载hdfs文件,这是移动文件的动作,源文件没了!
load data inpath '/student.txt' into table test.student_hdfs;
-- overwrite 关键字会将表中原有的数据清除掉
load data inpath '/student.txt' overwrite into table test.student_hdfs;
Insert插入数据
Hive官方推荐加载数据方式:
清洗数据成为结构化文件,再使用load语法加载数据到表中,这样效率更高
也可以使用insert语法把数据插入到指定的表中,最常用的配合是把查询返回的结果插入到另一张表中。
insert into test.student_local values (11,“张三”,“男”,18,“MA”);
使用insert插入数据,底层会走MR程序,找yarn申请资源,走map阶段,reduce阶段,中间还有繁琐的shuffle,最后输出结果。
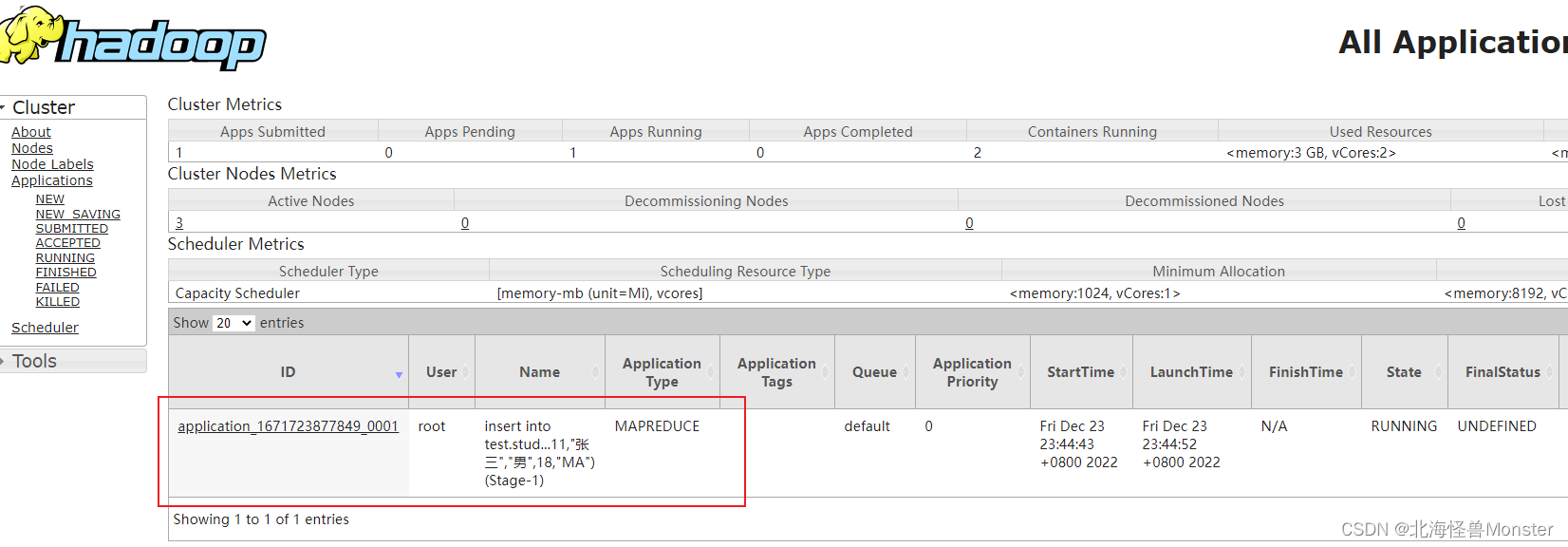
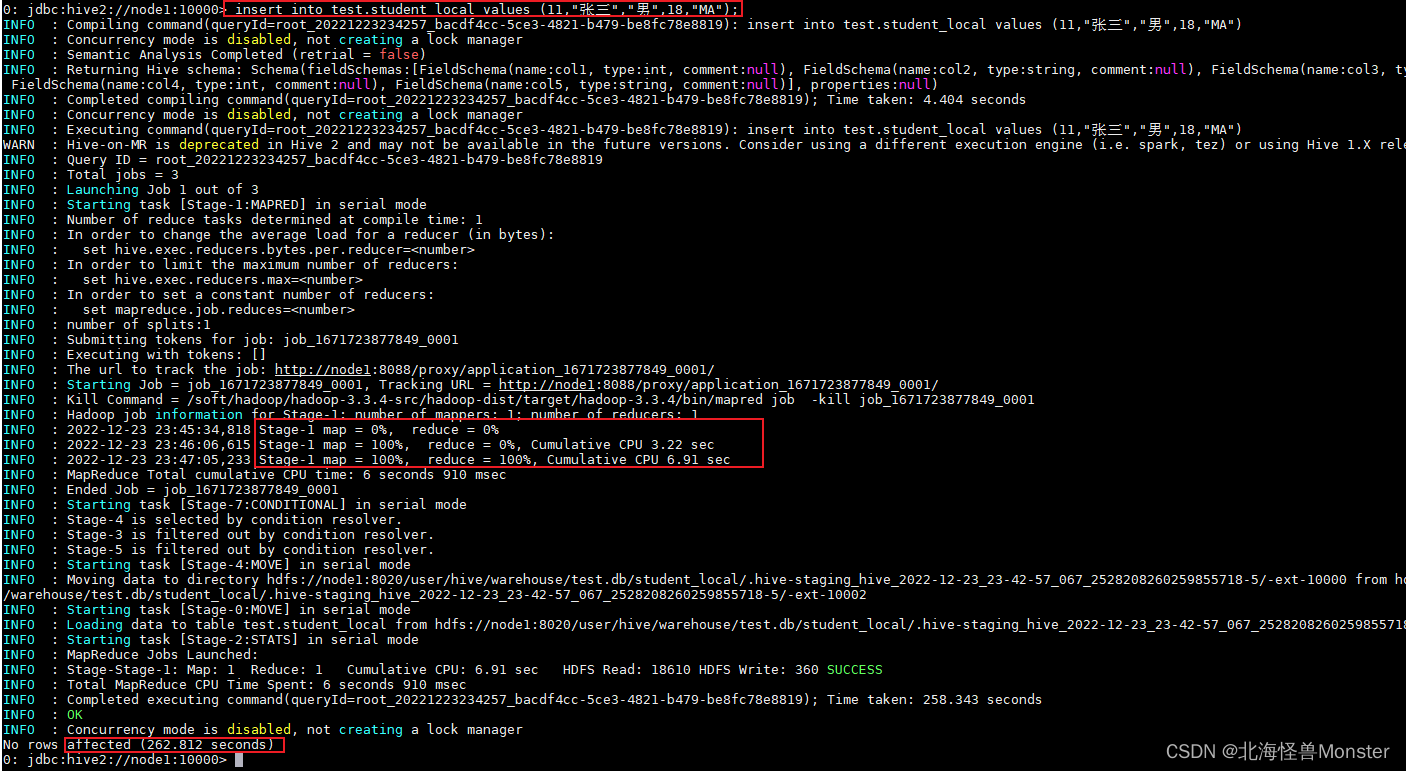
所以我们绝对不会使用insert语法插入数据。
常用的是insert+select语句
insert into 表1 select 字段1… from 表2
这个也是会执行一个MR程序。但是执行速度会比直接插入快一些,不知道为啥,视频教程没讲。
Hive SQL 查询数据
select * from 表名-- 查询所有数据
select 字段1,字段2... from 表名 -- 查询指定字段
select current_database(); -- current_database() 函数,查看当前使用的数据库
select distinct 字段1,字段2 from 表名 -- 去重查询,多个字段整体去重
-- where条件,可以使用函数,但是不能使用聚合函数
select 字段 from where 条件1 and 条件2 or 条件3 or length(字段)>10
is null
between and
in
-- 和sql差不多
--聚合操作,就是使用聚合函数
-- 聚合函数最大的特点是,不管原始数据有多少行,经过聚合操作只返回一条数据,这一条数据就是聚合函数的结果
-- 聚合函数,例如: count(不包括null值)、sum、max、min、avg
-- 使用 as 取别名,和sql一样
group by -- 分组
-- group by 语法,只会将分组后的数据的第一行数据返回,所以,你不在group by 里面的字段,需要使用聚合函数包起来
select state from 表名 group by state --这是可以的
select state,count(字段1) from 表名 group by state -- 这也是可以的
select state,字段2 from 表名 group by state -- 这是不行的
-- having 是分组之后的条件过滤,可以使用聚合函数
select * from 表名 group by 字段名 having 条件
-- order by 排序
select [distinct] 字段...
from 表名
where 条件
group by 字段
having 条件
order by 字段 -- 默认升序ASC,降序DESC,可以多个字段,先根据字段1排序,相同之后,再根据字段2排序
limit 开始行,行数 -- limit 2,3 从第二行开始,取三条数据,行数从0开始计算。 limit 3,从0开始,取3条数据
-- 再查询过程中执行顺序
-- from > where > group by(含聚合) > having > select > order
-- 聚合函数要比having子句优先执行
-- where子句再查询过程中执行优先级别优先于聚合语句
Hive SQL Join关联查询
表连接和SQL一样
内连接 inner join
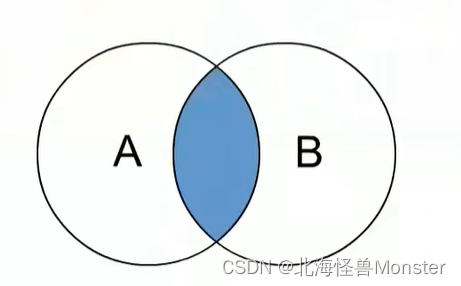
外连接 left join , right join
左外连接
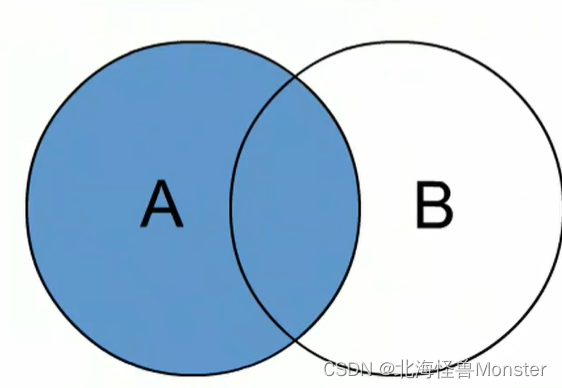
使用on 连接关系,笛卡尔积消除
Hive SQL中的函数使用
使用 show functions 查看当下可用的所有函数
通过 describe function extended 函数名 来出查看函数的使用方式
函数分类:内置函数,用户定义函数UDF
内置函数可分为:数值型函数,日期类型函数,字符串类型函数,集合函数,条件函数
用户定义函数根据输入输出的行数可分为3类:UDF,UDAF,UDTF
UDF,普通函数,一进一出
UDAF:聚合函数,多进一出
UDTF:表生成函数,一进多出
常用的内置函数
官方文档: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
--------------------String Functions 字符串函数 -------------------------
select length("qwe"); -- 查看长度
select reverse("qwe"); -- 反转
select concat("qwe","asd"); -- 连接两个字符串 输出:qweasd
select concat_ws('.','www',array('qwe','asd')); -- 参数1:分隔符,参数2:可以是字符串,参数3:可以是符合类型字符串
-- 输出结果为 www.qwe.asd
select substr('qweasd',-2); -- 字符串截取,为负数,则从后往前截取,最后一位为-1,输出为:sd
select substr('qweasd',2,2); -- 索引从1开始 输出为:we
select split('qwe asd',' '); -- 按照指定分割符进行分割,返回为数组,索引从0开始
-------------------- Date Functions 日期函数 -------------------------
-- 获取当前日期
select current_date();
-- 获取当前UNIX时间戳函数,精确到秒
select unix_timestamp();
-- 日期转时间戳
select unix_timestamp("2022-12-09 14:20:09");
-- 指定格式日期转时间戳
select unix_timestamp("20221102 13:03:12","yyyyMMdd HH:mm:ss");
-- 时间戳转日期
select from_unixtime(0,'yyyy-MM-dd HH:mm:ss')
-- 日期比较函数 日期格式要求:yyyy-MM-dd HH:mm:ss or yyyy-MM-dd
-- 返回相差天数,不用考虑闰年问题,月份问题
select datediff('2012-12-09','2012-10-09')
-- 日期增加函数
select date_add('2012-10-20',10);
-- 日期减少函数
select date_sub('2012-02-09',10);
-------------------- 数学函数 --------------------
-- 取整函数,四舍五入,返回double类型 3
select round(3.1415926)
-- 指定精度 四舍五入,返回double类型 3.1416
select round(3.1415926,4)
-- 取随机数,返回0~1范围内的随机数
select rand();
-- 指定种子取随机数,每次随机数都是固定的一个数,传入的种子不一样随机数也不一样
select rand(3)
-------------------- 条件函数 --------------------
select * from 表名 limit 3;
-------------------- 条件判断 --------------------
-- 为true 取第一个,为false或者null 取第二个
select if(sex='男','M','W') from 表名
-- 将case值进行 when后面的值匹配,符合就输出then后面的值,后面可以跟许多个 when 值 then 值
select case 字段 when 50 then 'tom' when 100 then 'mary' else 'tim' end from 表名 ;
-------------------- 空值转换 --------------------
-- 字段如果不为bull则返回本身的值,如果为空则返回后面指定的值
select nvl(字段,'test')