🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
使用 ARIMA 模型进行异常检测
使用 ARIMA 模型
ARIMA 模型表示自回归综合移动平均线。该模型提供了一系列功能,这些功能非常强大且灵活,可以执行与时间序列预测相关的任何任务。
在机器学习中,ARIMA 模型通常是一类统计模型,它给出的输出与随机因素组合中的先前值线性相关。
在选择合适的时间序列预测模型的同时,我们需要将数据可视化,以分析趋势、季节性和周期性。当季节性是时间序列的一个非常强的特征时,我们需要考虑一个模型,例如季节性 ARIMA (SARIMA)。
ARIMA 模型通过使用分布式滞后模型工作,在该模型中,算法用于根据滞后值预测未来。在本文中,我将通过机器学习中一个非常实用的示例(异常检测)向您展示如何使用 ARIMA 模型。
使用 ARIMA 模型进行异常检测
异常检测意味着识别过程中的意外事件。这意味着检测对我们系统的威胁,这些威胁可能会在安全性和重要信息泄漏方面造成危害。
异常检测的重要性不仅限于安全性,而是用于检测任何不符合我们预期的事件。在这里,我将向您解释我们如何使用 ARIMA 模型进行异常检测。
我将使用基于主机 CPU 使用率的每分钟指标的数据。现在让我们通过导入必要的库来开始这项任务:
import pandas as pd
!pip install pyflux
import pyflux as pf
from datetime import datetime现在让我们导入数据并快速查看数据及其一些见解。你可以下载数据,我在这个任务中使用的是这里。
from google.colab import files
uploaded = files.upload()
data_train_a = pd.read_csv('cpu-train-a.csv', parse_dates=[0], infer_datetime_format=True)
data_test_a = pd.read_csv('cpu-test-a.csv', parse_dates=[0], infer_datetime_format=True)
data_train_a.head()
现在,让我们可视化这些数据以快速了解我们正在处理的内容:
import matplotlib.pyplot as plt
plt.figure(figsize=(20,8))
plt.plot(data_train_a['datetime'], data_train_a['cpu'], color='black')
plt.ylabel('CPU %')
plt.title('CPU Utilization') 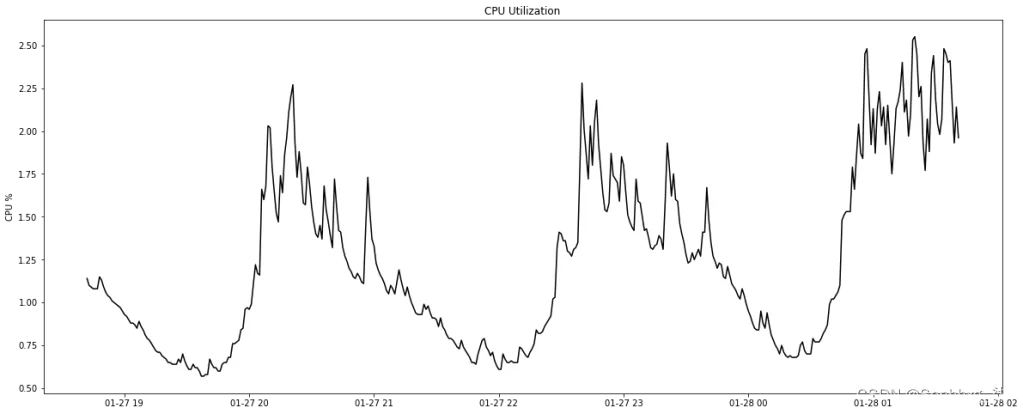
使用 ARIMA 模型
现在,让我们看看如何使用 ARIMA 模型对数据进行预测:
model_a = pf.ARIMA(data=data_train_a, ar=11, ma=11, integ=0, target='cpu')
x = model_a.fit("M-H")Acceptance rate of Metropolis-Hastings is 0.0
Acceptance rate of Metropolis-Hastings is 0.026
Acceptance rate of Metropolis-Hastings is 0.2346
Tuning complete! Now sampling.
Acceptance rate of Metropolis-Hastings is 0.244425
现在,让我们可视化我们的模型:
model_a.plot_fit(figsize=(20,8))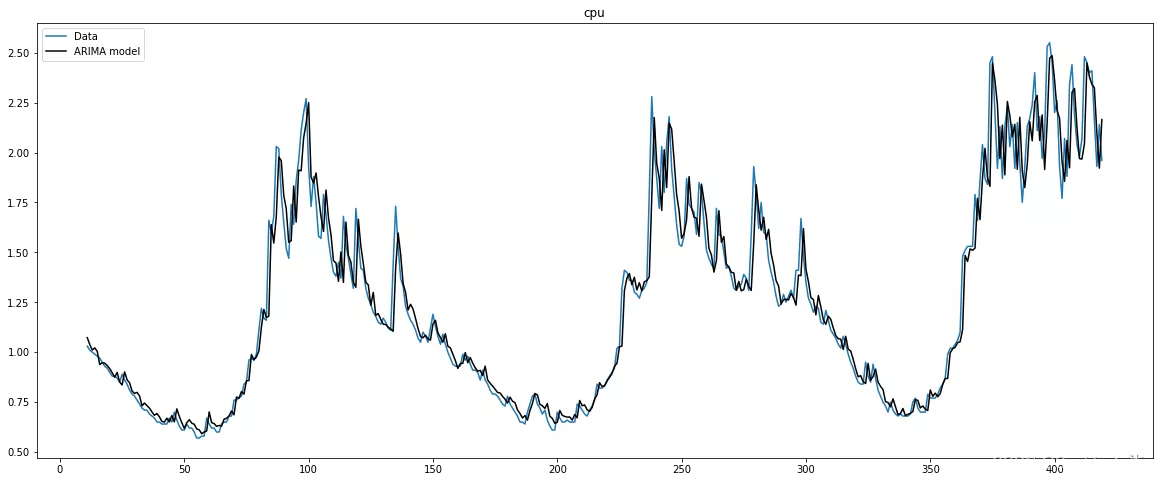
上面的输出显示了与 ARIMA 模型预测相符的 CPU 利用率随时间的变化。现在让我们执行一个示例测试来评估我们模型的性能:
model_a.plot_predict_is(h=60, figsize=(20,8))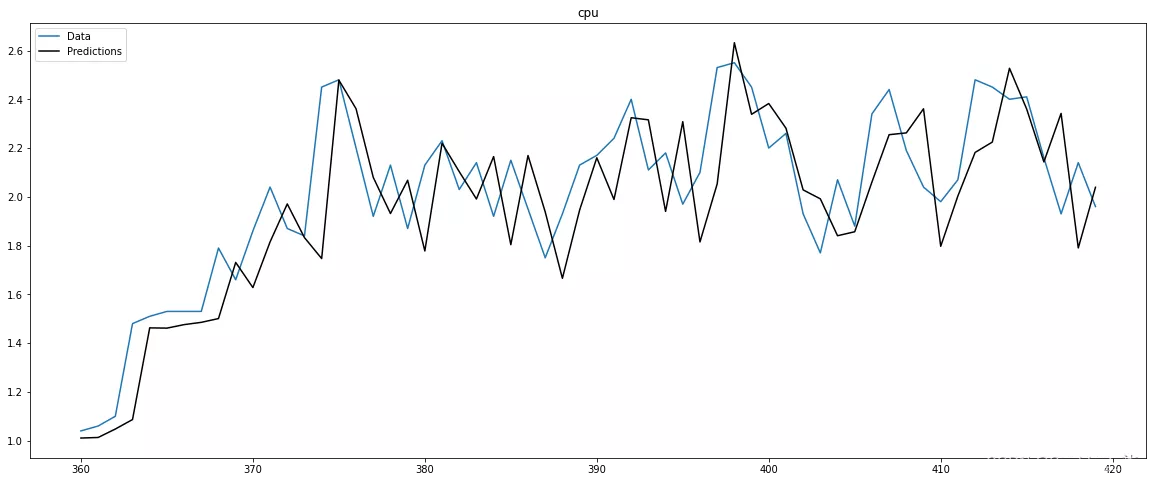
上面的输出显示了我们的 ARIMA 预测模型的样本内(训练集)。现在,我将运行实际预测,使用最近的 100 个观察到的数据点,然后是 60 个预测点:
model_a.plot_predict(h=60,past_values=100,figsize=(20,8))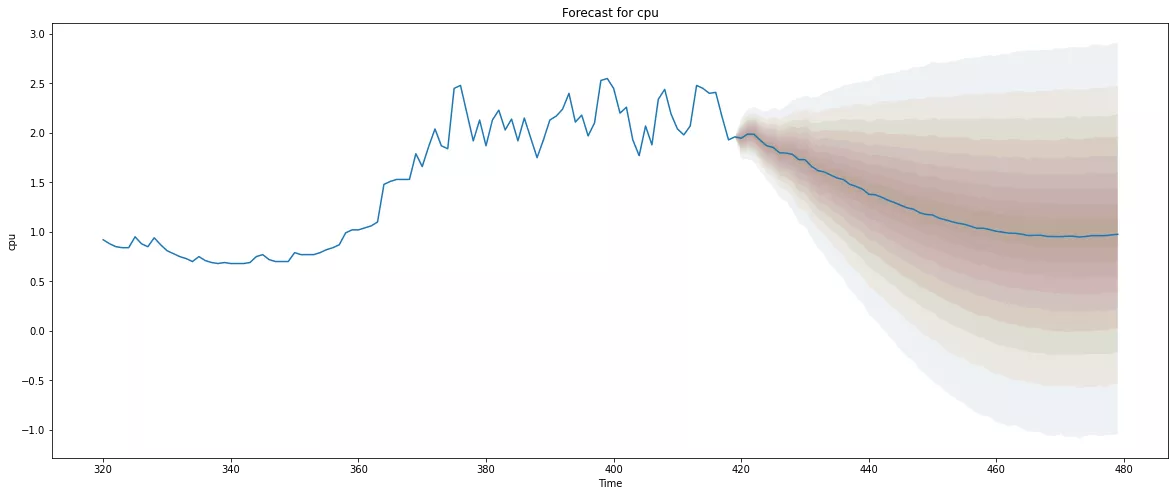
让我们对在不同时间捕获的 CPU 利用率数据集的另一部分执行相同的异常检测:
data_train_b = pd.read_csv('cpu-train-b.csv', parse_dates=[0], infer_datetime_format=True)
data_test_b = pd.read_csv('cpu-test-b.csv', parse_dates=[0], infer_datetime_format=True)
plt.figure(figsize=(20,8))
plt.plot(data_train_b['datetime'], data_train_b['cpu'], color='black')
plt.ylabel('CPU %')
plt.title('CPU Utilization')
现在,让我们将这些数据拟合到模型上:
model_b = pf.ARIMA(data=data_train_b, ar=11, ma=11, integ=0, target='cpu')
x = model_b.fit("M-H")Acceptance rate of Metropolis-Hastings is 0.0
Acceptance rate of Metropolis-Hastings is 0.016
Acceptance rate of Metropolis-Hastings is 0.1344
Acceptance rate of Metropolis-Hastings is 0.21025
Acceptance rate of Metropolis-Hastings is 0.23585
Tuning complete! Now sampling.
Acceptance rate of Metropolis-Hastings is 0.34395
model_b.plot_predict(h=60,past_values=100,figsize=(20,8))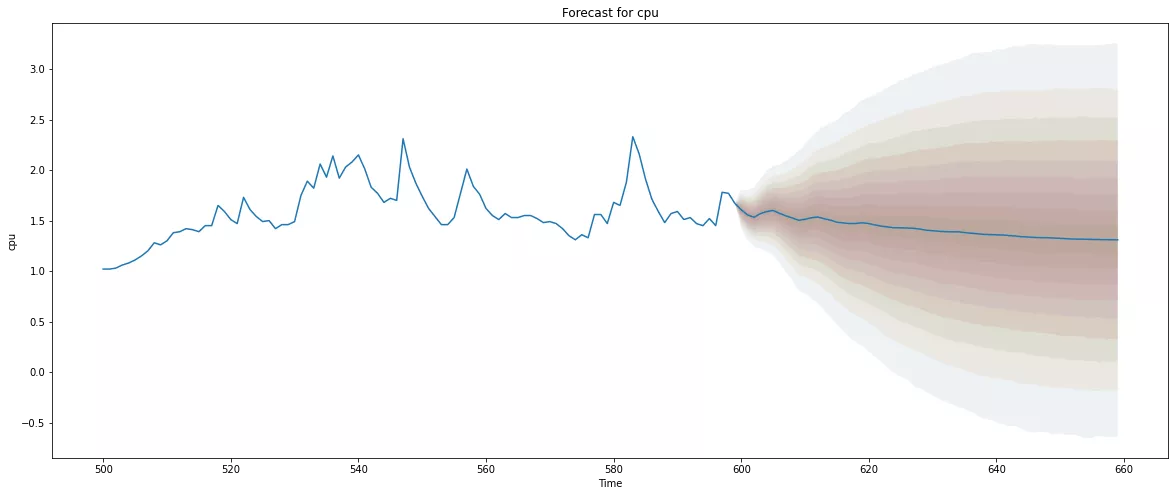
我们可以将训练期后短时间内发生的异常可视化,因为观察值落在低置信区间内,因此它会引发异常警报。
我希望您喜欢这篇关于使用 ARIMA 模型进行异常检测的文章。