文章目录
- 聚类的概述
- 常见的聚类算法
- 原型聚类
- K均值聚类算法
- K均值++聚类算法
- 顺序前导聚类(Sequential leader clustering)
- 高斯混合聚类(KMM)
- 密度聚类
- DBSCAN聚类算法
- 层次聚类
- AGNES聚类算法
- 谱聚类
- 聚类的评价(轮廓系数)
- 练习题
聚类的概述
聚类的地位:聚类问题是无监督学习任务中研究最多和应用最广的问题模型。
无监督学习的主要内容:聚类、密度估计和降维。(聚类对应监督学习中的分类,密度估计对应监督学习中的回归)。
聚类的目标:把数据样本分为若干个通常不相交的簇。
聚类的作用:
- 可以作为一个单独过程来寻找数据内在的分布结构。
- 可以作为分类等其他学习任务的前驱过程。
- 帮助寻找潜在的概念或类别。
聚类的标准:聚类的好坏不存在绝对标准,完全取决于具体使用的需要。因此,聚类是机器学习中新算法出现最多最快的领域,总能找到一个新的标准使得以往的聚类算法对它无能为力。
常见的聚类算法
原型聚类
- 别称:基于原型的聚类。
- 特点:聚类的结果可以通过一组原型来进行刻画,也就是可以在每一个簇中找到这个簇的代表性样本点。
- 过程:先对原型进行初始化,然后对原型进行迭代更新求解。
- 代表算法:K均值聚类、高斯混合聚类,学习向量量化聚类。
- 评价:研究最多的聚类方法,并且有很好的概率解释,但是通常只能找出椭球形的聚类结构。
K均值聚类算法
算法流程:
- 指定需要划分的簇的个数K。
- 随机选择K个数据对象作为初始聚类中心,这些数据对象不一定是已有的样本点。
- 逐一计算其他各个数据点到这K个初始聚类中心的距离,把数据对象划分到距离它最近的那个中心所在的簇中。
- 调整新的簇的聚类中心。
- 循环执行步骤三和步骤四,观察聚类中心是否收敛(位置基本不发生变化),如果收敛或达到最大迭代次数则终止循环过程。
备注:距离的计算也可以使用曼哈顿距离、闵可夫斯基距离等(泛化的欧氏距离)。
算法优点:
- 原理比较简单,实现起来比较容易。
- 聚类效果较好且效率较高(复杂度与样本个数呈线性关系)。
- 算法的可解释性比较好。
- 算法唯一需要调整的超参数是聚类个数K。
算法缺点:
- 聚类的个数K值不好把握。
- 受初始聚类中心的选择影响较大
- 只适合分离较远不相交的类球形簇。
- 采用迭代形式,最终的结果只是局部最优。
- 算法对噪音和异常点比较敏感。
关于K值的选择:K值的选择需要综合考虑实际要求和聚类效果两个方面。
K均值++聚类算法
算法概括:K均值++算法是对K均值算法的优化,对K均值算法的初始聚类中心的构造过程进行了优化,从而避免了K均值算法容易受初始聚类中心的影响和容易受孤立点影响的缺点。
改进内容:
- 随机选择一个样本点作为初始聚类中心。
- 计算每一个样本与当前已有的聚类中心的最短距离(也就是离当前最近的一个聚类中心的距离),这个值越大,表示被选择作为下一个聚类中心的概率越大。用轮盘法(根据概率大小进行抽选)选择下一个聚类中心。
- 重复步骤二,直到选择出K个聚类中心。
顺序前导聚类(Sequential leader clustering)
算法流程:人为设置一个距离阈值,然后逐一遍历每一个样本点并进行如下操作:
- 计算该样本点到每一个聚类中心的距离。
- 如果到最近的聚类中心的距离小于距离阈值,则将该样本点划分到这个最近聚类中心所对应的簇中,并重新计算这一个簇的聚类中心。
- 如果到最近的聚类中心的距离大于距离阈值,则将该样本点作为一个新的聚类中心并生成一个新的簇。
算法缺点:
- 算法执行顺序不同产生的结果也不同。
- 需要人工确定一个距离阈值。
高斯混合聚类(KMM)
模型原理:高斯混合聚类假设最终结果的每一个簇都服从一个高斯分布,由此得到的多个簇就构成一个整体分布模型。
算法流程:首先假设最终的簇的个数为K(这一点与K均值算法相同)。然后遍历每一个样本点进行下列操作。重复下面过程直到得到局部最优解。
- 通过计算得出该样本点属于各个高斯分布的概率,将该样本点划分到概率最大的高斯分布所对应的簇中。
- 更新这个簇的高斯分布参数。
求解方法:常用的求解方法是EM方法,EM算法可以分为E和M两个步骤。
- E步骤:在每一步迭代中。先根据当前的参数计算每一个样本点属于每一个高斯分布的概率。
- M步骤:更新高斯分布的参数。
高斯混合模型和K均值算法的相似性:
- 两者的分类都受到初始值的影响;
- 两者都可能限于局部最优解;
- 两者类别的个数都需要靠猜测。
高斯混合模型和K均值算法的不同:
- K均值算法属于硬聚类,也就是一个样本要么属于这一类要么属于另一类;
- 高斯混合模型属于软聚类,一个样本有不同的概率属于不同的类。
密度聚类
- 别称:基于密度的聚类。
- 特点:聚类结构能通过样本分布的紧密程度确定。
- 过程:从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇。
- 代表算法:DBSCAN、OPTICS、DENCLUE。
- 优点:
①可以生成任意形状的簇;
②抗噪声能力强;
③事先不需要指定簇的个数;
④类似于人类的视觉,因此直观清晰。
DBSCAN聚类算法
相关概念:
- 邻域:某一数据点在一定半径内的空间;
- 密度:某一数据点在邻域内的最小的对象点数目。
- 核心点:密度大于某一个阈值的样本点。
- 边界点:对象的密度小于阈值,但是在某个核心点的邻域中。
- 噪声点:不是核心点且不是边界点的样本点。
- 直接密度可达:如果一个样本点P在核心点Q的邻域内,则称从样本点Q出发直接可达样本的P。
算法流程:
- 通过检查数据集中的每一个点的邻域在搜索簇,如果某一个样本点为核心点,则以该样本点开始创建一个簇。经过这一步后,原始的多个样本点被分别划分到多个簇中,而一些噪声点则被忽略。
- 迭代地判断各个簇是否足够邻近使得相邻的两个簇可以进行合并。经过这一步后靠得较近的簇都被合并。
层次聚类
- 特点:能够产生不同粒度的聚类结果。
- 过程:在不同层次对数据集进行划分,从而形成树形的聚类结构。
- 代表算法:AGNES(自底向上)、DIANA(自顶向下)。
AGNES聚类算法
算法流程:
- 最初将每个对象作为一个簇,然后这些簇根据某些准则被进一步合并,每次合并两个簇。
- 两个簇间的相似度由这两个不同簇中距离最近的两个数据点之间的距离确定。当任意两个簇最近距离超过用户所给定的阈值时聚类过程终止。
- 聚类的合并过程重复迭代进行,直到所有的对象都满足簇数据。
谱聚类
算法原理:基于图论的聚类方法,将无向带权图划分为两个或两个以上的最优子图,使得子图内尽量相似,而子图之间的距离尽量越远越好,从而实现聚类的目的。
算法优点:
- 只需要待聚类点之间的相似度矩阵作为前提条件。
- 对于数据集的要求较低。
聚类的评价(轮廓系数)
轮廓系数的作用:轮廓系数是用于评价聚类结果好坏的指标,可以用于聚类模型的调参过程。
- 样本的簇内不相似度:样本到同一个簇中其他样本点的平均距离。
- 样本的簇间不相似度:计算样本点到其他某一个簇的所有样本点的平均距离,对其他每一个簇进行一次计算,计算结果中的最小值即为样本的簇间不相似度。
样本的轮廓系数:假设样本i的簇内不相似度为ai,簇间不相似度为bi,则样本i的轮廓系数计算公式如下:
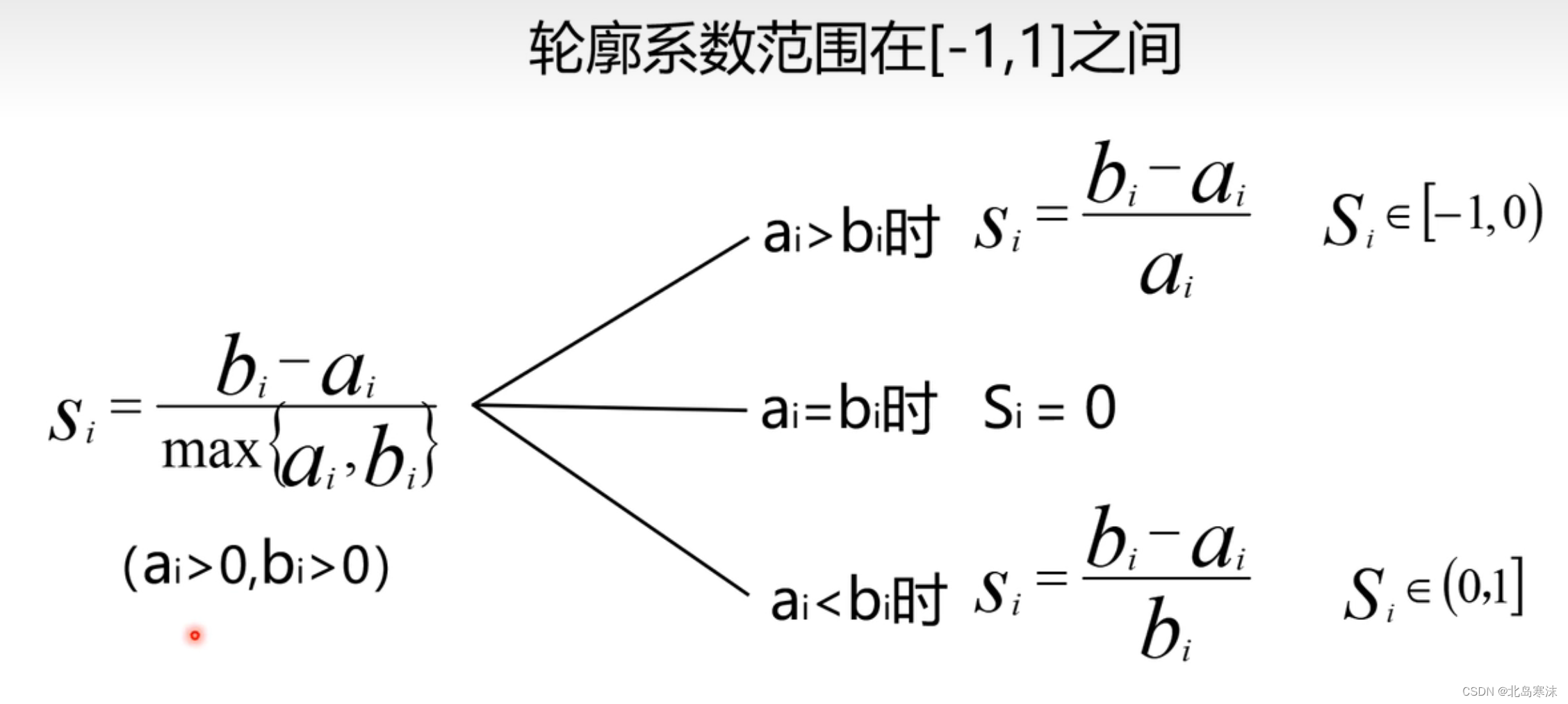
- 轮廓系数越接近1,表示聚类结果越好。
- 轮廓系数小于1,表示当前样本点聚类不合理。
聚类结果的轮廓系数:聚类结果的轮廓系数即每一个样本点的轮廓系数的平均值。
基于轮廓系数的调参过程:可以绘制参数变化时轮廓系数的变化曲线,曲线最大值所对应的参数即为最优参数。
注意事项:轮廓系数最大值所对应的参数可能并非实际上问题的参数。
练习题
1.对于Silhouette图表述正确的是(C)。
A.每个点的取值范围为[0,1]
B.每个点的取值越接近0越好
C.可以体现出簇的紧凑性
D.对于离群点,取值可能超过1
解析:本题考察轮廓系数的相关内容。每一个样本点的轮廓系数取值范围都是[-1,1],因此A错误;每个点的轮廓系数越接近1,说明聚类效果越好,因此B错误;所有点的轮廓系数不可能大于1,因此D错误。综上所述,只有C正确,这是因为轮廓系数越大,簇的紧凑性越高。
2.由于K均值聚类是一个迭代过程,我们需要设置其迭代终止条件。下面哪句话正确描述了K均值聚类的迭代终止条件 (A)。
A.已经达到了迭代次数上限或者前后两次迭代中聚类质心基本保持不变
B.已经形成了K个聚类集合,或者每个待聚类样本分别归属唯一一个聚类集合
c.已经形成了K个聚类集合,或者已经达到了迭代次数上限
D.已经达到了迭代次数上限,或者每个待聚类样本分别归属唯一一个聚类集合
解析:本题考察K均值聚类算法的终止条件。K均值算法往往需要设置最大迭代次数参数(非超参数),当达到最大迭代次数时即停止迭代;当相邻两次迭代中聚类中心(质心)的位置基本不变也是迭代的终止条件。由此可以判断A选项正确。
由于K均值算法从算法开始到结束中间任意时刻簇的个数都是K个,因此不能通过簇的个数判断算法是否终止;每一个样本点都归属于一个簇也不能作为终止条件。
3.我们可以从最小化每个类簇的方差这一视角来解释K均值聚类的结果,下面对这一视角描述不正确的是©。
A.最终聚类结果中每个聚类集合中所包含数据呈现出来差异性最小
B.每个样本数据分别归属于与其距离最近的聚类质心所在聚类集合
C.每个簇类的质心累加起来最小
D.每个族类的方差累加起来最小
解析:本题考察聚类结果的评价。每个簇的质心累加相当于坐标点的累加,没有实际意义,因此不能作为最终的评价指标。
4.K-Means算法中的初始中心点(D)。
A.可随意设置
B.必须在每个簇的真实中心点的附近
C.必须足够分散
D.直接影响算法的收敛结果
解析:本题考察K均值算法初始聚类中心的设置。初始中心点不能随意设置,因为初始中心点的选择直接影响算法的收敛结果,由此可以判断A选项错误,D选项正确。由于每个簇的真实中心点未知,因此B选项实际上是无法做到的;必须足够分散并非K均值算法设置初始聚类中心的要求。
5.关于K-Means算法的表述正确的是(C)。
A.对数据分布没有特殊的要求
B.能较好处理噪点和离群点
C.对初始中心点较为敏感
D.计算复杂度较高
解析:本题考察K均值聚类算法的优点和缺点。K均值算法要求数据点呈现椭球形分布,而对于数据呈现条形或其他复杂分布的情况聚类结果不好,因此A错误;K均值算法容易受到噪音点和离群点的干扰,因此B错误;K均值算法对指定的初始聚类中心敏感,初始聚类中心的选择直接影响聚类结果,因此C正确;K均值算法的计算复杂度较低,因此D错误。
6.在Sequential Leader算法中(D)。
A.需对数据集进行多次遍历
B.无法人为控制最终聚类的个数
C.需要事先生成初始中心点
D.聚类结果可能受数据访问顺序影响
解析:本题考察顺序前导聚类算法。顺序前导聚类算法只需要对数据集进行一次遍历即可完成聚类过程,是最简单的聚类算法,因此A选项错误;该算法中使用者可以通过指定距离阈值从而间接控制最终聚类的个数,因此B选项错误;该算法不需要事先生成或指定初始聚类中心,因此C选项错误。顺序前导算法的聚类结果可能受到数据访问顺序的影响,不同的遍历次序可能导致不同的聚类结果,因此D选项正确。