一、前言
这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据。
update on 2016-12-28:之前忘记给BeautifulSoup的官网了,今天补上,顺便再补点BeautifulSoup的用法。
update on 2017-08-16:很多网友留言说Unsplash网站改版了,很多内容是动态加载的。所以建议动态加载的内容使用PhantomJS而不是Request库进行请求,如果使用PhantomJS请看我的下一篇博客,如果是定位html文档使用的class等名字更改的话,建议大家根据更改后的内容进行定位,学爬虫重要的是爬取数据的逻辑,逻辑掌握了网站怎么变都不重要啦。
二、运行环境
我的运行环境如下:
-
系统版本
Windows10。 -
Python版本
Python3.5,推荐使用Anaconda 这个科学计算版本,主要是因为它自带一个包管理工具,可以解决有些包安装错误的问题。去Anaconda官网,选择Python3.5版本,然后下载安装。 -
IDE
我使用的是PyCharm,是专门为Python开发的IDE。这是JetBrians的产品,点我下载。
三、模块安装
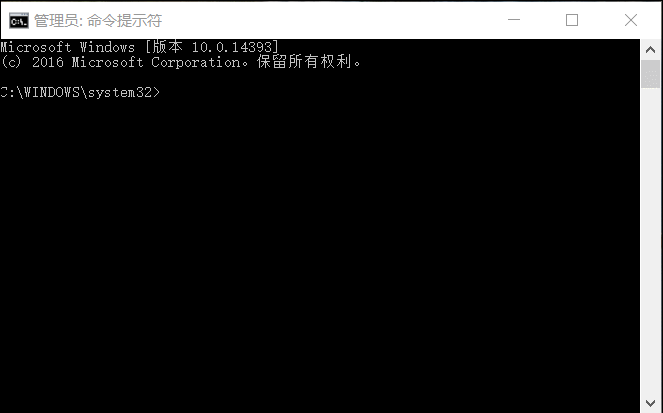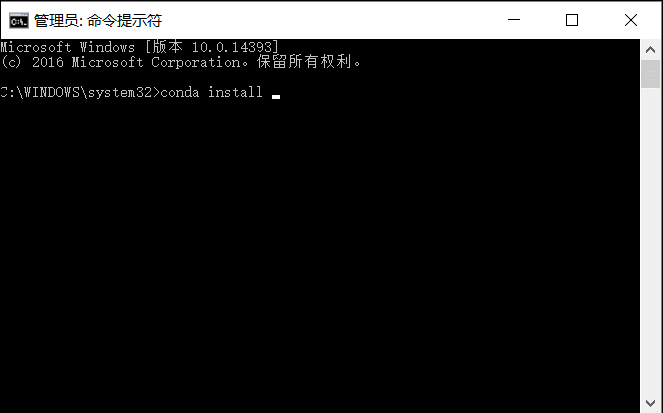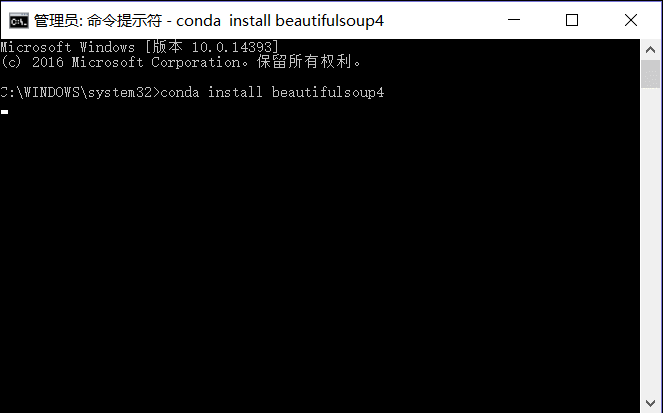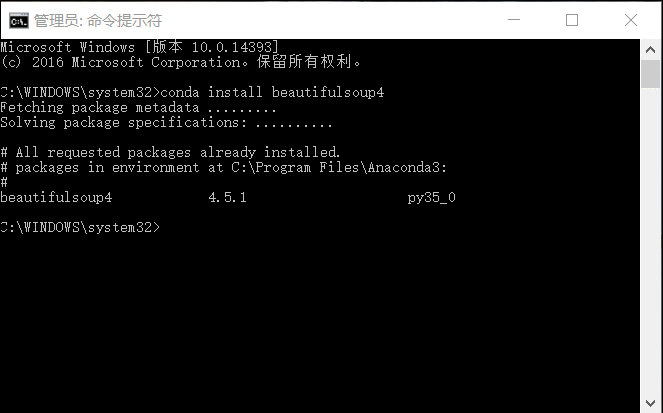
BeautifulSoup 有多个版本,我们使用BeautifulSoup4。详细使用看BeautifuSoup4官方文档。
使用管理员权限打开cmd命令窗口,在窗口中输入下面的命令即可安装:conda install beautifulsoup4
直接使用Python3.5 没有使用Anaconda版本的童鞋使用下面命令安装:pip install beautifulsoup4
然后我们安装lxml,这是一个解析器,BeautifulSoup可以使用它来解析HTML,然后提取内容。
Anaconda 使用下面命令安装lxml:conda install lxml
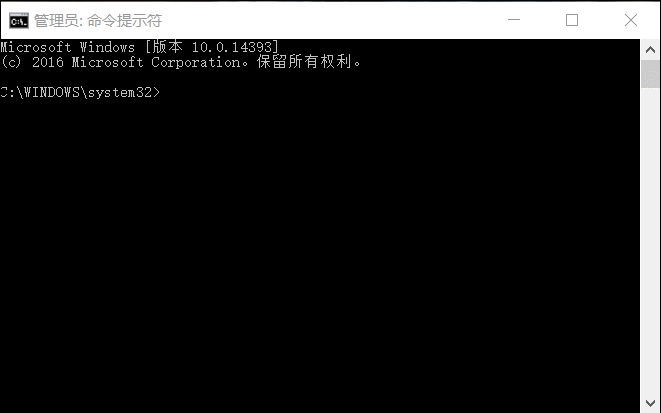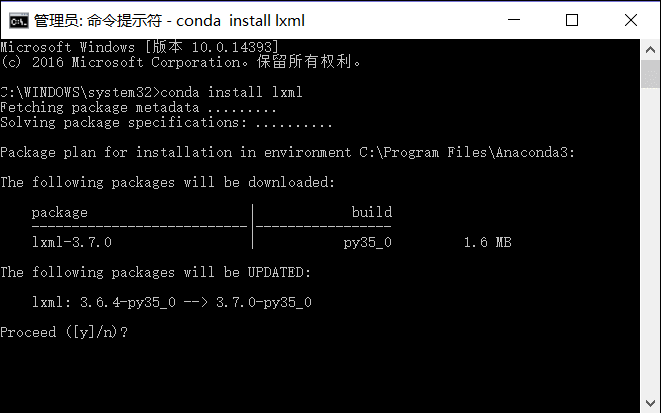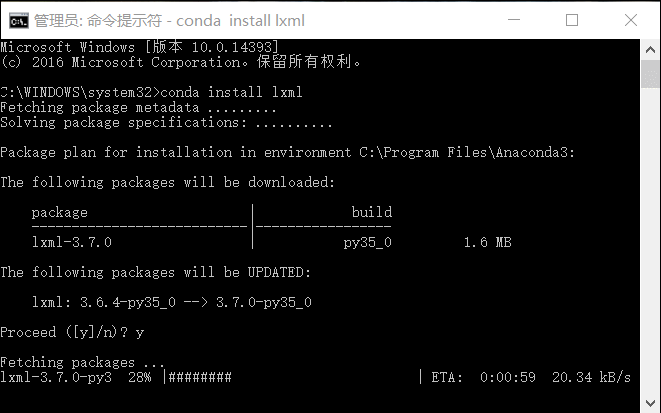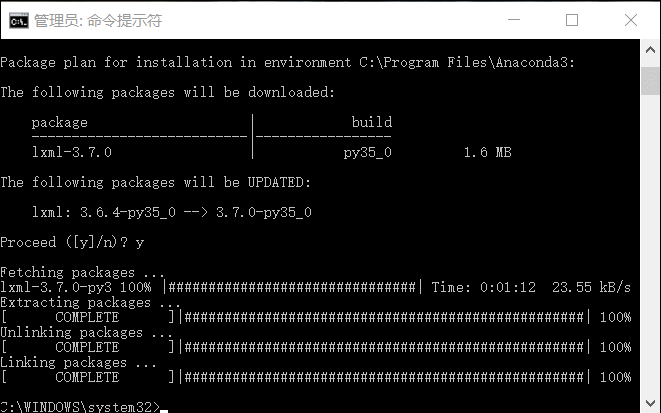
使用Python3.5 的童鞋们直接使用pip安装会报错(所以才推荐使用Anaconda版本)
如果不安装lxml,则BeautifulSoup会使用Python内置的解析器对文档进行解析。之所以使用lxml,是因为它速度快。
文档解析器对照表如下:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup,"html.parser") | 1. Python的内置标准库 2. 执行速度适 3. 中文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup,"lxml") | 1. 速度快 2. 文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup,["lxml-xml"]) BeautifulSoup(markup,"xml") | 1. 速度快 2. 唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup,"html5lib") | 1. 最好的容错性 2. 以浏览器的方式解析文档 3. 生成HTML5格式的文档 | 速度慢,不依赖外部扩展 |
四、BeautifulSoup 库的使用
不同版本的用法差不多,几个常用的语法都一样。
首先来看BeautifulSoup的对象种类,在使用的过程中就会了解你获取到的东西接下来应该如何操作。
4.1 BeautifulSoup对象的类型
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象。所有对象可以归纳为4种类型: Tag , NavigableString , BeautifulSoup , Comment 。下面我们分别看看这四种类型都是什么东西。
4.1.1 Tag
这个就跟HTML或者XML(还能解析XML?是的,能!)中的标签是一样一样的。我们使用find()方法返回的类型就是这个(插一句:使用find-all()返回的是多个该对象的集合,是可以用for循环遍历的。)。返回标签之后,还可以对提取标签中的信息。
提取标签的名字:
tag.name
提取标签的属性:
tag['attribute']
我们用一个例子来了解这个类型:
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml') #声明BeautifulSoup对象
find = soup.find('p') #使用find方法查到第一个p标签
print("find's return type is ", type(find)) #输出返回值类型
print("find's content is", find) #输出find获取的值
print("find's Tag Name is ", find.name) #输出标签的名字
print("find's Attribute(class) is ", find['class']) #输出标签的class属性值
4.1.2 NavigableString
NavigableString就是标签中的文本内容(不包含标签)。获取方式如下:tag.string
还是以上面那个例子,加上下面这行,然后执行:print('NavigableString is:', find.string)

4.1.3 BeautifulSoup
BeautifulSoup对象表示一个文档的全部内容。支持遍历文档树和搜索文档树。
4.1.4 Comment
这个对象其实就是HTML和XML中的注释。
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
type(comment)
# <class 'bs4.element.Comment'>
有些时候,我们并不想获取HTML中的注释内容,所以用这个类型来判断是否是注释。
if type(SomeString) == bs4.element.Comment:
print('该字符是注释')
else:
print('该字符不是注释')
4.2 BeautifulSoup遍历方法
4.2.1 节点和标签名
可以使用子节点、父节点、 及标签名的方式遍历:
soup.head #查找head标签
soup.p #查找第一个p标签
#对标签的直接子节点进行循环
for child in title_tag.children:
print(child)
soup.parent #父节点
# 所有父节点
for parent in link.parents:
if parent is None:
print(parent)
else:
print(parent.name)
# 兄弟节点
sibling_soup.b.next_sibling #后面的兄弟节点
sibling_soup.c.previous_sibling #前面的兄弟节点
#所有兄弟节点
for sibling in soup.a.next_siblings:
print(repr(sibling))
for sibling in soup.find(id="link3").previous_siblings:
print(repr(sibling))
4.2.2 搜索文档树
最常用的当然是find()和find_all()啦,当然还有其他的。比如find_parent() 和 find_parents()、 find_next_sibling() 和 find_next_siblings() 、find_all_next() 和 find_next()、find_all_previous() 和 find_previous() 等等。
我们就看几个常用的,其余的如果用到就去看官方文档哦。
- find_all()
搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。返回值类型是bs4.element.ResultSet。
完整的语法:find_all( name , attrs , recursive , string , **kwargs )
这里有几个例子
soup.find_all("title")
# [<title>The Dormouse's story</title>]
#
soup.find_all("p", "title")
# [<p class="title"><b>The Dormouse's story</b></p>]
#
soup.find_all("a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
#
soup.find_all(id="link2")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
#
import re
soup.find(string=re.compile("sisters"))
# u'Once upon a time there were three little sisters; and their names were\n'
name 参数:可以查找所有名字为 name 的tag。
attr 参数:就是tag里的属性。
string 参数:搜索文档中字符串的内容。
recursive 参数: 调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点。如果只想搜索tag的直接子节点,可以使用参数 recursive=False 。
- find()
与find_all()类似,只不过只返回找到的第一个值。返回值类型是bs4.element.Tag。
完整语法:find( name , attrs , recursive , string , **kwargs )
看例子:
soup.find('title')
# <title>The Dormouse's story</title>
#
soup.find("head").find("title")
# <title>The Dormouse's story</title>
基本功已经练完,开始实战!