2022年圣诞节到来啦,很高兴这次我们又能一起度过~
这次分享关于一个对某大型政务网站的优化咨询的案例,发生在今年的下半年,已过去一段时间,并取得了良好的成果!*
项目背景
某大型政务网站准备上线,需要应对总共500w左右的流量,首两日预计承受一百万左右的流量。
需求特点:
- 一些静态文章
- 一些静态资源
- 需要播放多个50-100mb左右的视频文件
- 纯供应商开发的网址
- 未使用任何cms框架,目前所有资源和请求都是从项目中直接获取
说是要优化,其实不用想,就是假设各种缓存。
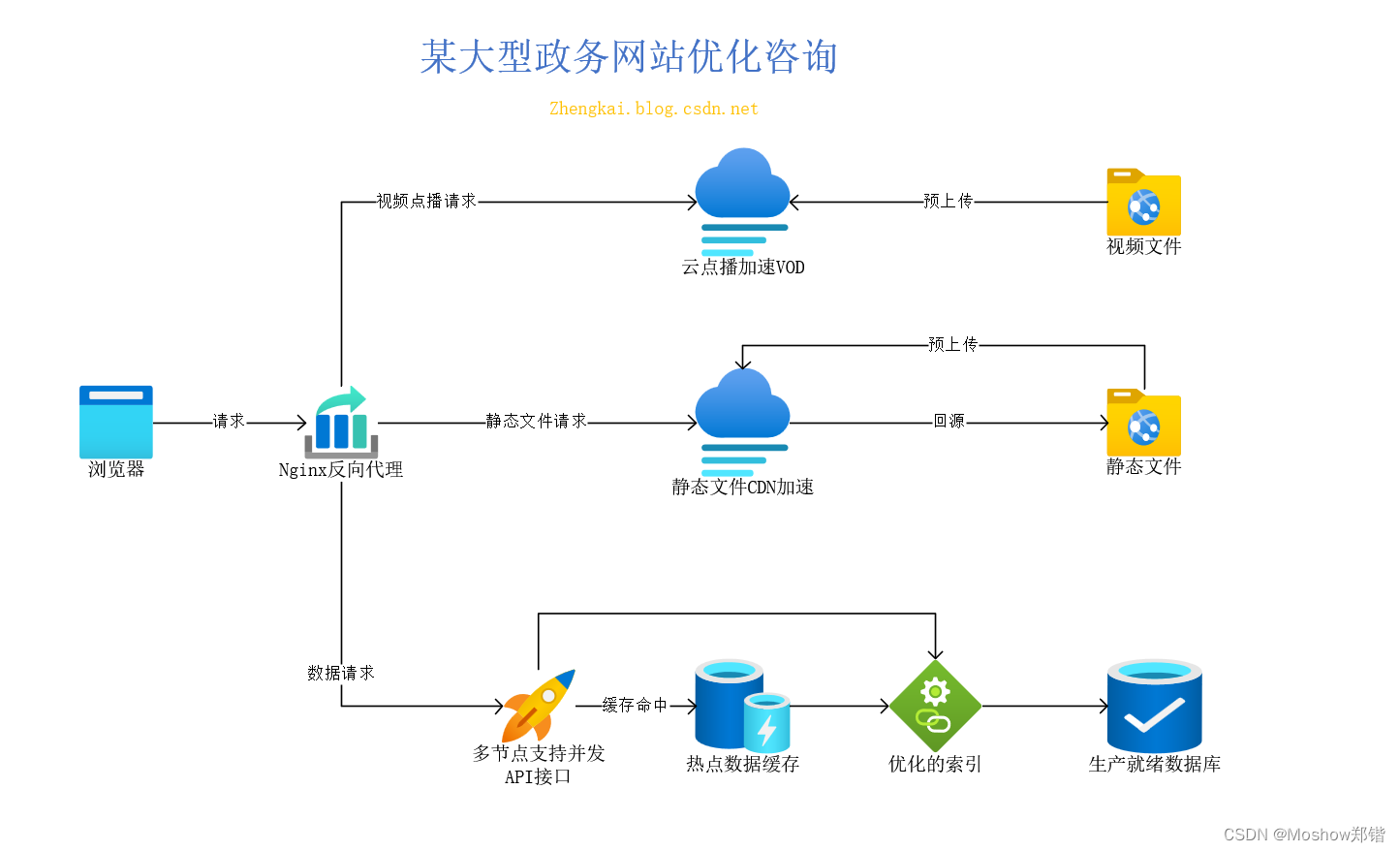
缓存设计
在这个场景中,我设计了三重缓存,
视频点播缓存,这个之前是要合并在CDN的,但是由于有更优的VOD方案,也就是上传视频之后,其他的交给VOD搞定,在文章中用js调用他们的视频播放器,如果简单又美妙的方式,谁不爱。静态文件缓存,想js/css/img等资源文件,本质都是可以通过cdn缓存,这样减少服务器的压力,可以更多的去处理需要处理的请求。数据缓存,一个是API需要改造支持多节点和多并发,然后就是针对热点数据进行缓存,对于非热点的动态数据则进行数据库查询,并建立合理的索引机制,网址大面积需要文本索引,所以全文索引很重要, 虽然没能改造为ElasticSearch,但是全文索引很加分。- nginx反向代理开启
GZIP压缩,压缩网站,减少流量,加快访问。
技术详解
一、NGINX代理与Gzip
NGINX是很强大的反向代理,使用的时候,可以进行项目分发, 例如有多个后端则设置多ip轮训即可。
然后开启GZIP压缩。
GZIP是网站压缩加速的一种技术,对于开启后可以加快我们网站的打开速度,原理是经过服务器压缩,客户端浏览器快速解压的原理,可以大大减少了网站的流量
Gzip配置参数
gzip on; #是否开启gzip模块 on表示开启 off表示关闭
gzip_buffers 4 16k; #设置压缩所需要的缓冲区大小
gzip_comp_level 6; #压缩级别1-9,数字越大压缩的越好,也越占用CPU时间
gzip_min_length 100k; #设置允许压缩的最小字节
gzip_http_version 1.1; #设置压缩http协议的版本,默认是1.1
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript; #设置压缩的文件类型
gzip_vary on; #加上http头信息Vary: Accept-Encoding给后端代理服务器识别是否启用 gzip 压缩
编辑配置文件
[root@linux /]# vim /usr/local/nginx/conf.d/www.conf
server {
listen 80;
server_name www.zhengkai.com;
root html/bk;
index index.php index.html;
access_log /usr/local/nginx/logs/www.log ;
include /usr/local/nginx/php/www.conf;
include /usr/local/nginx/wjt/typecho.conf;
gzip on;
gzip_buffers 4 16k;
gzip_comp_level 6;
gzip_vary on;
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript;
}
重载配置文件
/usr/local/nginx/sbin/nginx -s reload
检测Gzip是否开启
[root@linux /]#
curl -I -H"Accept-Encoding: gzip, deflate" "https://www.zhengkai.com"
网页GZIP压缩检测
https://tool.chinaz.com/gzips/
二、VOD视频点播
https://cloud.tencent.com/product/vod
云点播(Video on Demand,VOD)为用户提供云端一体化音视频点播服务平台。用户可以通过本地上传/URL 拉取/API 上传/Web SDK/短视频 SDK/直播录制等多种上传方式将视频上传至云端,并对云端视频进行普通转码、极速高清、多码率转码、截图、视频加密、添加水印、识别等处理,处理完成的视频文件可通过腾讯云遍布全球的 CDN 节点完成加速分发。此外,结合云点播的超级播放器的多终端能力,提供完整可靠的数据质量和监控平台,同时云点播用户还可使用腾讯内容公众平台,小程序进行发布和推广,多分发路径使信息更易触达。
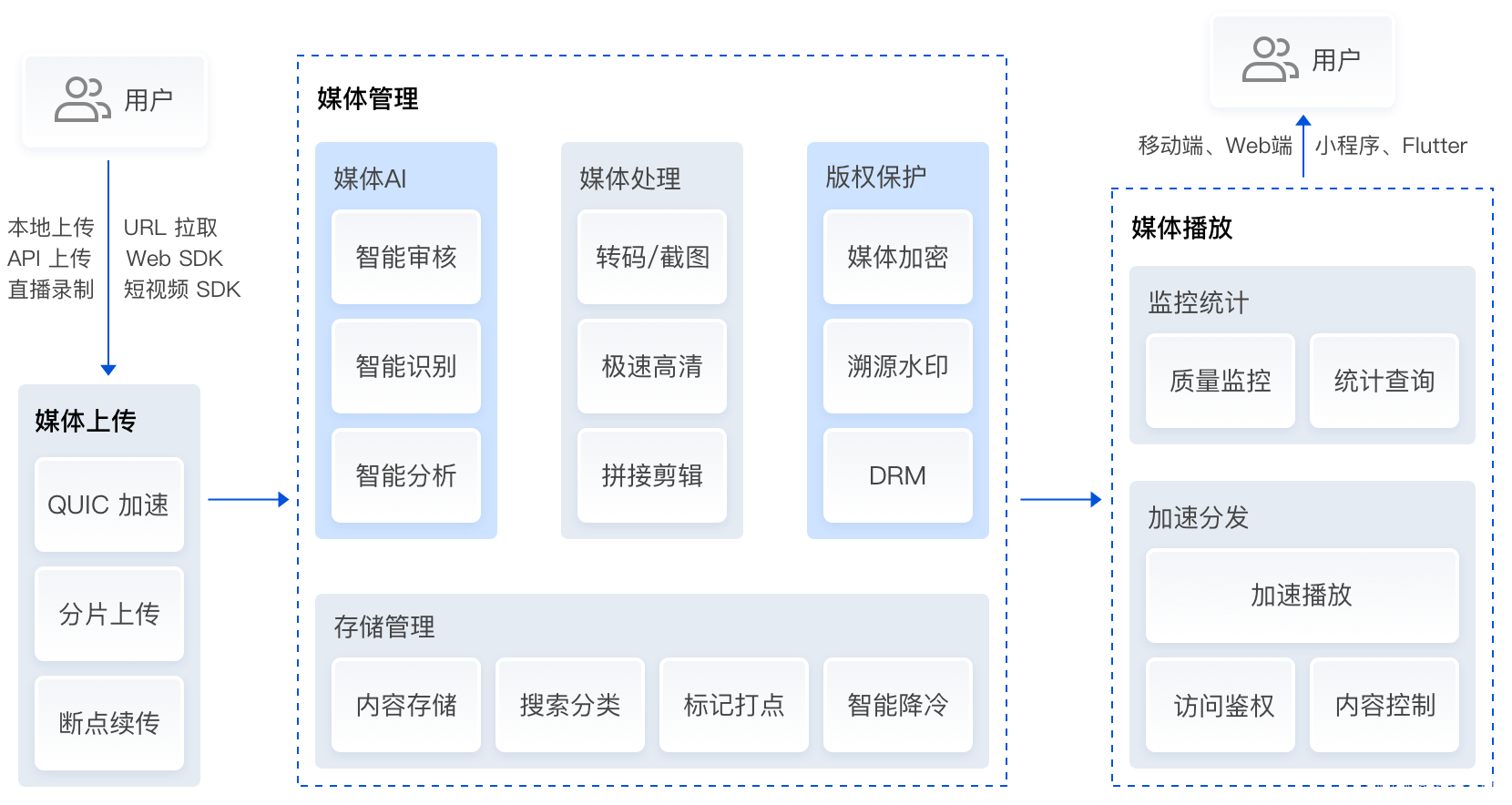

其实很多VOD平台都有类似的功能,工具需要选择即可。
对应的demo文档可以在https://cloud.tencent.com/document/product/266/58693 这找到
三、CDN静态内容分发
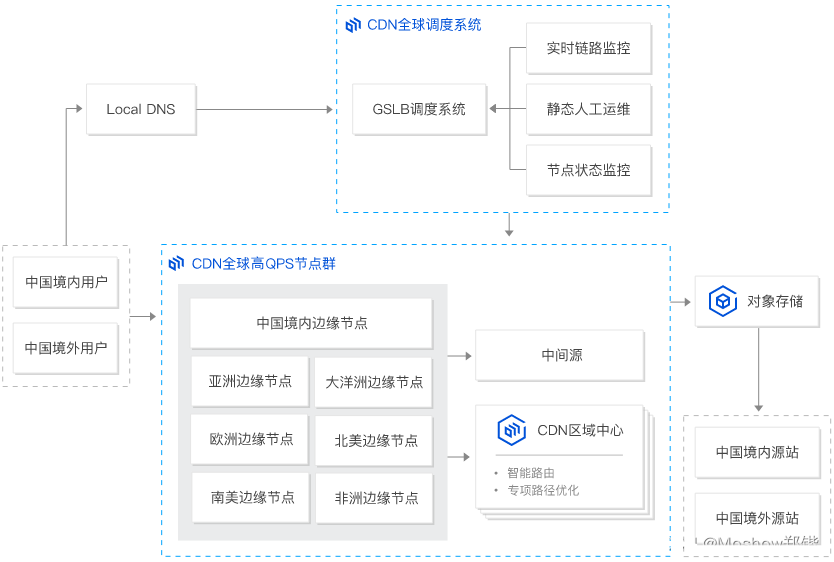
内容分发网络(Content Delivery Network)是建立并覆盖在承载网之上,由分布在不同区域的边缘节点服务器群组成的分布式网络。 CDN分担源站压力,避免网络拥塞,确保在不同区域、不同场景下加速网站内容的分发,提高资源访问速度。
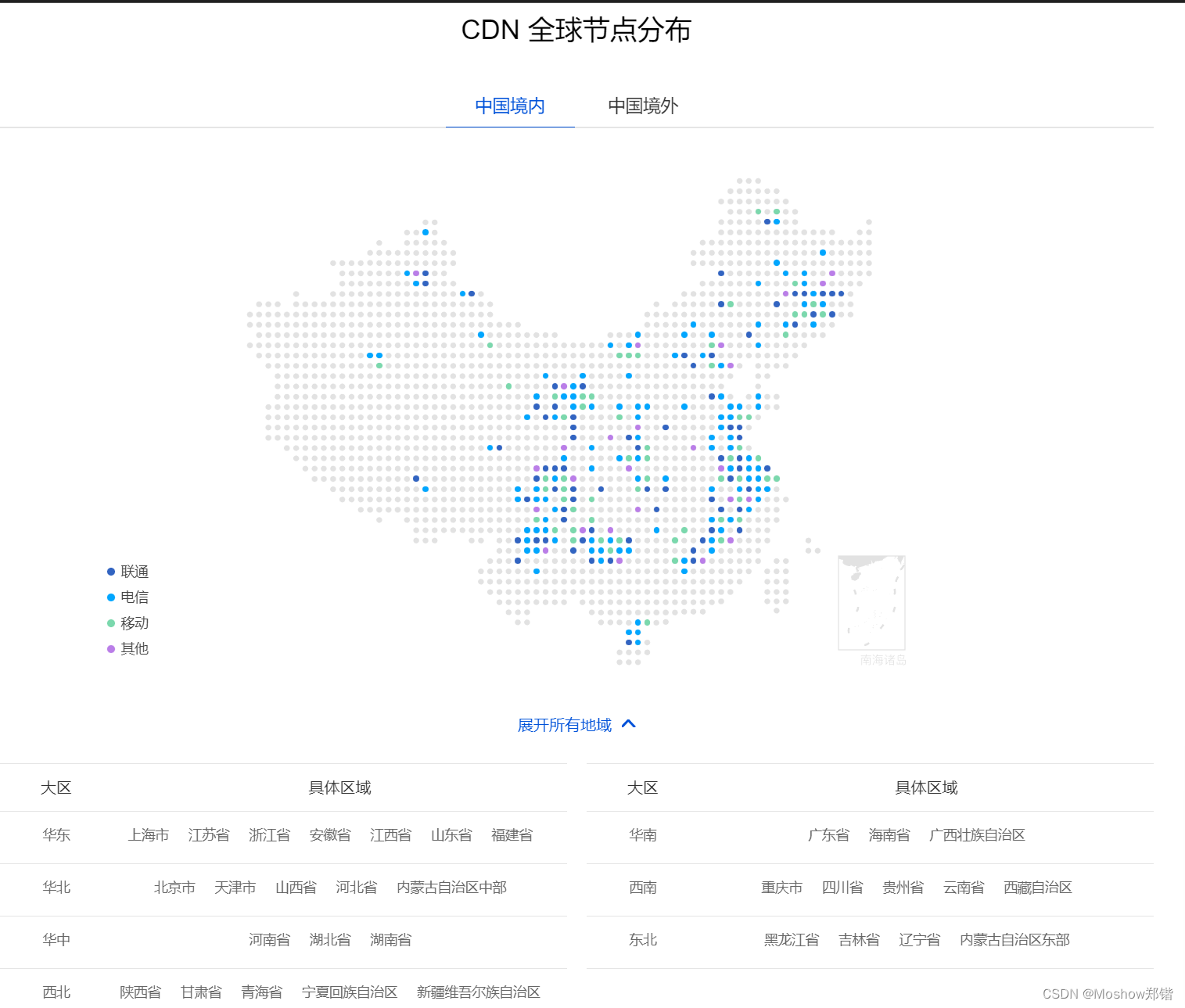
CDN比较烦的就是需要绑定cdn域名,需要拥有域名控制权。
可以在代码里面设置一个开关,针对dev环境使用本地静态资源,针对prod环境使用cdn静态资源。目录结构保持不变即可。
支持js/css/img/png等静态资源文件,甚至一些静态html页面也能放上面,在大访问量的时候可以为网站分流超多的请求。
四、热点数据缓存
缓存数据库 Redis ,丰富的数据结构能帮助您完成不同类型的业务场景开发。支持主从热备,提供自动容灾切换、数据备份、故障迁移、实例监控、在线扩容、数据回档等全套的数据库服务。
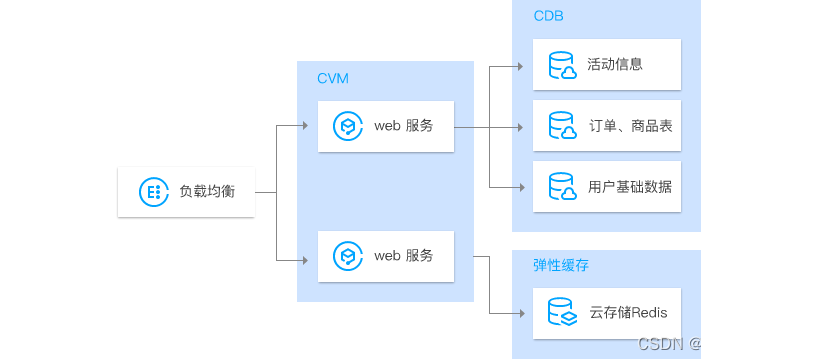 可以针对热点数据,例如电商中对订单/商品/分类数据做缓存,例如CMS网站中对分类/文章做缓存,达到加速的目的,那么访问文章的时候,根据id优先从缓存中加载,某些固定的滚动文章列表,也可以缓存起来(例如可搜索列表但是没有带搜索条件,只有翻页条件,则所有翻页的文章列数据都可以缓存起来,起到无条件默认加速,一旦有条件再进行动态查询。),首页绝大部分数据都可以缓存,这样打开首页的速度就会变得非常快。
可以针对热点数据,例如电商中对订单/商品/分类数据做缓存,例如CMS网站中对分类/文章做缓存,达到加速的目的,那么访问文章的时候,根据id优先从缓存中加载,某些固定的滚动文章列表,也可以缓存起来(例如可搜索列表但是没有带搜索条件,只有翻页条件,则所有翻页的文章列数据都可以缓存起来,起到无条件默认加速,一旦有条件再进行动态查询。),首页绝大部分数据都可以缓存,这样打开首页的速度就会变得非常快。
缓存更新方面,一旦有文章编辑行为,则刷新对应的文章缓存和列表缓存。但是要注意缓存击穿和缓存雪崩的情况,合理的设置缓存即可。也可以设置定时器,在后半夜对所有缓存进行刷新。
by zhengkai.blog.csdn.net
五、全文索引优化
有ElasticSearch当然好,全文索引强大,但是没有也不用怕,在针对商品详情和文章详情这种情况,做个合理的全文索引优化就可以了,
全文索引(Full-Text Search)是将存储于数据库中的整本书或整篇文章中的任意信息查找出来的技术。它可以根据需要获得全文中有关章、节、段、句、词等信息,也可以进行各种统计和分析。
在早期的 MySQL 中,InnoDB 并不支持全文检索技术,从 MySQL 5.6 开始,InnoDB 开始支持全文检索。
在已创建的表上创建全文索引语法如下:
CREATE FULLTEXT INDEX full_index_name ON table_name(col_name);
MATCH(col1,col2,...) AGAINST(expr[search_modifier])
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}
全文搜索使用 MATCH() AGAINST()语法进行:
- MATCH() 采用逗号分隔的列表,命名要搜索的列。
- AGAINST()接收一个要搜索的字符串,以及一个要执行的搜索类型的可选修饰符。
全文检索分为三种类型:自然语言搜索、布尔搜索、查询扩展搜索,我们默认采用Natural Language自然语言搜索将搜索字符串解释为自然人类语言中的短语。
SELECT
count(*) AS count
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( 'MySQL' );
上述语句,查询 title,body 列中包含 ‘MySQL’ 关键字的行数量。上述语句还可以这样写:
SELECT
count(IF(MATCH ( title, body )
against ( 'MySQL' ), 1, NULL )) AS count
FROM
`fts_articles`;
上述两种语句虽然得到的结果是一样的,但从内部运行来看,第二句SQL的执行速度更快些,因为第一句SQL(基于where索引查询的方式)还需要进行相关性的排序统计,而第二种方式是不需要的。
还可以通过SQL语句查询相关性:
SELECT
*,
MATCH ( title, body ) against ( 'MySQL' ) AS Relevance
FROM
fts_articles;
相关性的计算依据以下四个条件:
- word 是否在文档中出现
- word 在文档中出现的次数
- word 在索引列中的数量
- 多少个文档包含该 word