自然语言处理---Transformer机制详解之Multi head Attention详解
1 采用Multi-head Attention的原因
- 原始论文中提到进行Multi-head Attention的原因是将模型分为多个头, 可以形成多个子空间, 让模型去关注不同方面的信息, 最后再将各个方面的信息综合起来得到更好的效果.
- 多个头进行attention计算最后再综合起来, 类似于CNN中采用多个卷积核的作用, 不同的卷积核提取不同的特征, 关注不同的部分, 最后再进行融合.
- 直观上讲, 多头注意力有助于神经网络捕捉到更丰富的特征信息.
2 Multi-head Attention的计算方式
- Multi-head Attention和单一head的Attention唯一的区别就在于, 其对特征张量的最后一个维度进行了分割, 一般是对词嵌入的embedding_dim=512进行切割成head=8, 这样每一个head的嵌入维度就是512/8=64, 后续的Attention计算公式完全一致, 只不过是在64这个维度上进行一系列的矩阵运算而已.
- 在head=8个头上分别进行注意力规则的运算后, 简单采用拼接concat的方式对结果张量进行融合就得到了Multi-head Attention的计算结果.
- Multi-Head Attention是利用多个查询,来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分,然后再进行拼接。
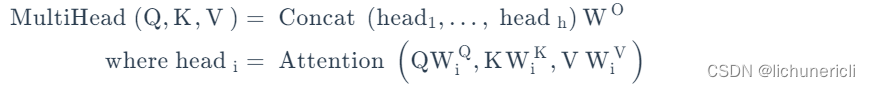

3 Multi-Head Attention的作用
- 多头注意力的机制进一步细化了注意力层,通过以下两种方式提高了注意力层的性能:
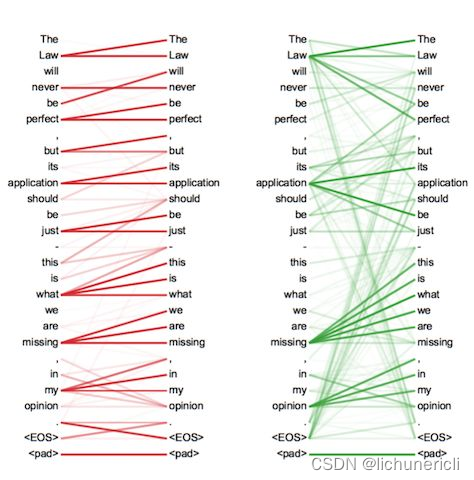
- 扩展了模型专注于不同位置的能力。当多头注意力模型和自注意力机制集合的时候,比如翻译“动物没有过马路,因为它太累了”这样的句子的时候,想知道“它”指的是哪个词,如果能分析出来代表动物,就很有用。
- 为注意力层提供了多个“表示子空间”。对于多头注意力,不仅有一个而且还有多组Query/Key/Value权重矩阵,这些权重矩阵集合中的每一个都是随机初始化的。然后,在训练之后,每组用于将输入Embedding投影到不同的表示子空间中。多个head学习到的Attention侧重点可能略有不同,这样给了模型更大的容量。
4 小结
- Transformer架构采用Multi-head Attention的原因.
- 将模型划分为多个头, 分别进行Attention计算, 可以形成多个子空间, 让模型去关注不同方面的信息特征, 更好的提升模型的效果.
- 多头注意力有助于神经网络捕捉到更丰富的特征信息.
- Multi-head Attention的计算方式.
- 对特征张量的最后一个维度进行了分割, 一般是对词嵌入的维度embedding_dim进行切割, 切割后的计算规则和单一head完全一致.
- 在不同的head上应用了注意力计算规则后, 得到的结果张量直接采用拼接concat的方式进行融合, 就得到了Multi-head Attention的结果张量.
- Multi-Head Attention的作用
- 扩展了模型专注于不同位置的能力
- 为注意力层提供了多个“表示子空间”
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1122788.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!