文章目录
- 字符串、字符串字面量、切片(slice)、字符串 slice
- 01、字符串
- 02、字符串字面量
- 03、切片 (slice)
- 04、字符串 slice
- 字符串 slice注意要点
- String 与 &str 的转换
- 字符串深度剖析
- 字符串 slice 作为函数参数
- 例子001
- 例子002
- 通过将 s 参数的类型改为字符串 slice 来改进函数
- 可变引用与不可变引用同时存在
- 切片与引用的关系
- 操作 UTF-8 字符串 (操作中文字符串)
- 1、字符
- 2、字节
- 3、获取子串
字符串、字符串字面量、切片(slice)、字符串 slice
本文是对前四章内容的学习与总结
01、字符串

字符串String 由三部分组成,如图下图所示:一个指向存放字符串内容内存的指针,一个长度,和一个容量。这一组数据存储在栈上。右侧则是堆上存放内容的内存部分。
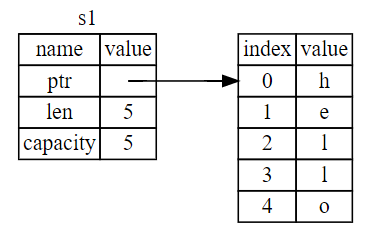
如果是中文呢,到这里,你会发觉,上面的理解是不全面的。
什么是字符串?
顾名思义,字符串是由字符组成的连续集合,Rust 中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4),这样有助于大幅降低字符串所占用的内存空间。
Rust 在语言级别,只有一种字符串类型: str,它通常是以引用类型出现 &str,也就是上文提到的字符串切片。虽然语言级别只有上述的 str 类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的即是 String 类型。
str 类型是硬编码进可执行文件,无法被修改,但是 String 则是一个可增长、可改变且具有所有权的 UTF-8 编码字符串,当 Rust 用户提到字符串时,往往指的就是 String 类型和 &str 字符串切片类型,这两个类型都是 UTF-8 编码。
除了 String 类型的字符串,Rust 的标准库还提供了其他类型的字符串,例如 OsString, OsStr, CsString 和 CsStr 等,注意到这些名字都以 String 或者 Str 结尾了吗?它们分别对应的是具有所有权和被借用的变量。
02、字符串字面量

字符串字面量就是切片。
let s = "Hello, world!";
实际上,s 的类型是 &str,因此你也可以这样声明:
let s: &str = "Hello, world!";
什么是切片,接着往下看。
03、切片 (slice)

切片并不是 Rust 独有的概念,在 Go 语言中就非常流行,它允许你引用集合中部分连续的元素序列,而不是引用整个集合。
对于字符串而言,切片就是对 String 类型中某一部分的引用,它看起来像这样:
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
hello 没有引用整个 String s,而是引用了 s 的一部分内容,通过 [0..5] 的方式来指定。
其它切片
因为切片是对集合的部分引用,因此不仅仅字符串有切片,其它集合类型也有,例如数组:
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
该数组切片的类型是 &[i32],数组切片和字符串切片的工作方式是一样的,例如持有一个引用指向原始数组的某个元素和长度。
04、字符串 slice

对于字符串而言,字符串 slice(string slice)是 String 中一部分值的引用,它看起来像这样:
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
println!("{}", hello);
println!("{}", world);
}
这类似于引用整个 String 不过带有额外的 [0..5] 部分。它不是对整个 String 的引用,而是对部分 String 的引用。
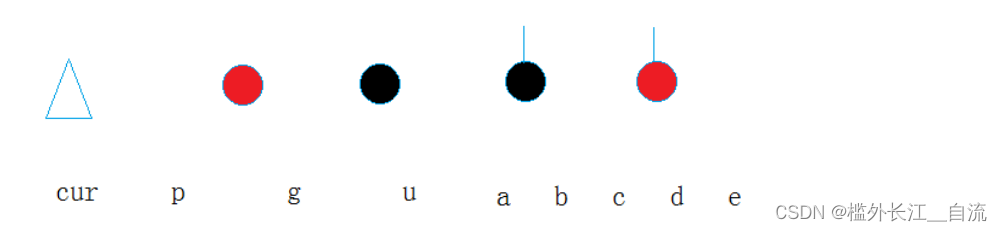
可以使用一个由中括号中的 [starting_index..ending_index] 指定的 range 创建一个 slice,其中 starting_index 是 slice 的第一个位置,ending_index 则是 slice 最后一个位置的后一个值。在其内部,slice 的数据结构存储了 slice 的开始位置和长度,长度对应于 ending_index 减去 starting_index 的值。所以对于 let world = &s[6..11]; 的情况,world 将是一个包含指向 s 索引 6 的指针和长度值 5 的 slice。
图例

例子
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
//let slice = &s[0..2]; //he
//let slice = &s[..2]; //he
//let slice = &s[3..len]; //lo
//let slice = &s[3..]; //lo
let slice = &s[..]; //hello
println!("{}", slice);
}
字符串 slice注意要点
在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
let s = "中国人";
let a = &s[0..2];
println!("{}",a);
因为我们只取 s 字符串的前两个字节,但是本例中每个汉字占用三个字节,因此没有落在边界处,也就是连 中 字都取不完整,此时程序会直接崩溃退出,如果改成 &s[0..3],则可以正常通过编译。 因此,当你需要对字符串做切片索引操作时,需要格外小心这一点, 关于该如何操作 UTF-8 字符串,参见 操作-utf-8-字符串。
String 与 &str 的转换

在之前的代码中,已经见到好几种从 &str 类型生成 String 类型的操作:
String::from("hello,world")"hello,world".to_string()
那么如何将 String 类型转为 &str 类型呢?答案很简单,取引用即可:
fn main() {
let s = String::from("hello,world!");
say_hello(&s);
say_hello(&s[..]);
say_hello(s.as_str());
}
fn say_hello(s: &str) {
println!("{}",s);
}
实际上这种灵活用法是因为 deref 隐式强制转换,具体我们会在 Deref 特征进行详细讲解。
字符串深度剖析
那么问题来了,为啥 String 可变,而字符串字面值 str 却不可以?
就字符串字面值来说,我们在编译时就知道其内容,最终字面值文本被直接硬编码进可执行文件中,这使得字符串字面值快速且高效,这主要得益于字符串字面值的不可变性。不幸的是,我们不能为了获得这种性能,而把每一个在编译时大小未知的文本都放进内存中(你也做不到!),因为有的字符串是在程序运行得过程中动态生成的。
对于 String 类型,为了支持一个可变、可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容,这些都是在程序运行时完成的:
- 首先向操作系统请求内存来存放
String对象 - 在使用完成后,将内存释放,归还给操作系统
其中第一部分由 String::from 完成,它创建了一个全新的 String。
重点来了,到了第二部分,就是百家齐放的环节,在有垃圾回收 GC 的语言中,GC 来负责标记并清除这些不再使用的内存对象,这个过程都是自动完成,无需开发者关心,非常简单好用;但是在无 GC 的语言中,需要开发者手动去释放这些内存对象,就像创建对象需要通过编写代码来完成一样,未能正确释放对象造成的后果简直不可估量。
对于 Rust 而言,安全和性能是写到骨子里的核心特性,如果使用 GC,那么会牺牲性能;如果使用手动管理内存,那么会牺牲安全,这该怎么办?为此,Rust 的开发者想出了一个无比惊艳的办法:变量在离开作用域后,就自动释放其占用的内存:
{
let s = String::from("hello"); // 从此处起,s 是有效的
// 使用 s
} // 此作用域已结束,
// s 不再有效,内存被释放
与其它系统编程语言的 free 函数相同,Rust 也提供了一个释放内存的函数: drop,但是不同的是,其它语言要手动调用 free 来释放每一个变量占用的内存,而 Rust 则在变量离开作用域时,自动调用 drop 函数: 上面代码中,Rust 在结尾的 } 处自动调用 drop。
其实,在 C++ 中,也有这种概念: Resource Acquisition Is Initialization (RAII)。如果你使用过 RAII 模式的话应该对 Rust 的
drop函数并不陌生。
这个模式对编写 Rust 代码的方式有着深远的影响,在后面章节我们会进行更深入的介绍。
字符串 slice 作为函数参数
在说字符串 slice 作为函数参数前,我们先看几个错误的例子
例子001
fn main() {
let my_name = "Pascal";
greet(my_name);
}
fn greet(name: String) {
println!("Hello, {}!", name);
}
greet 函数接受一个字符串类型的 name 参数,然后打印到终端控制台中,非常好理解,你们猜猜,这段代码能否通过编译?
error[E0308]: mismatched types
--> src/main.rs:3:11
|
3 | greet(my_name);
| ^^^^^^^
| |
| expected struct `std::string::String`, found `&str`
| help: try using a conversion method: `my_name.to_string()`
error: aborting due to previous error
Bingo,果然报错了,编译器提示 greet 函数需要一个 String 类型的字符串,却传入了一个 &str 类型的字符串
所以可以这样修改
// 添加to_string()
let my_name = "Pascal".to_string();
// 或者
let my_name = String::from("Pascal");
例子002
fn main() {
let s1 = "hello";
let len = calculate_length(s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
输出
error[E0308]: mismatched types
--> src/main.rs:4:32
|
4 | let len = calculate_length(s1);
| ---------------- ^^ expected `&String`, found `&str`
| |
| arguments to this function are incorrect
|
= note: expected reference `&String` found reference `&str`
note: function defined here
编译器提示 calculate_length 函数需要一个 &String 类型的字符串,却传入了一个 &str 类型的字符串。
那&str怎么转&String呢?如图

所以可以这样修改
let s1 = "hello".to_string();
let len = calculate_length(&s1);
通过将 s 参数的类型改为字符串 slice 来改进函数
当我们把函数calculate_length 中的&String修改为&str,对 String 值和 &str 值就可以使用相同的函数了。
fn main() {
// 支持 String
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
// 支持 &str
let s2 = "hello";
let len = calculate_length(s2);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: &str) -> usize {
s.len()
}
如果有一个字符串 slice,可以直接传递它。
如果有一个 String,则可以传递整个 String 的 slice 或对 String 的引用。
下面的写法都是可以的
// 支持 &str
let s2 = "hello";
let len = calculate_length(&s2[0..len]);
let len = calculate_length(&s2[1..3]);
let len = calculate_length(&s2[3..]);
let len = calculate_length(&s2[..]);
let len = calculate_length(s2);
println!("The length of '{}' is {}.", s2, len);
如果你不小心写成let len = calculate_length(&s2);,测试发现,也是可以的。但不建议这么写。因为字符串字面量类型就是&str。
可变引用与不可变引用同时存在
可变引用与不可变引用同时存在,就会报错。为什么?
我们不能在拥有不可变引用的同时拥有可变引用。使用者可不希望不可变引用的值在他们的眼皮底下突然被改变了!然而,多个不可变引用是可以的,因为没有哪个只能读取数据的人有能力影响其他人读取到的数据。
示例代码
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}
回忆一下借用规则,当拥有某值的不可变引用时,就不能再获取一个可变引用。因为 clear 需要清空 String,它尝试获取一个可变引用。在调用 clear 之后的 println! 使用了 word 中的引用,所以这个不可变的引用在此时必须仍然有效。Rust 不允许 clear 中的可变引用和 word 中的不可变引用同时存在,因此编译失败。Rust 不仅使得我们的 API 简单易用,也在编译时就消除了一整类的错误!
借用规则总结如下:
1、同一时刻,你只能拥有要么一个可变引用, 要么任意多个不可变引用
2、不过可变引用有一个很大的限制:在同一时间,只能有一个对某一特定数据的可变引用。尝试创建两个可变引用的代码将会失败
3、引用必须总是有效的
切片与引用的关系
下面是一个简单的示例代码,展示了如何在Rust中使用切片和引用的关系:
fn main() {
// 创建一个整数数组
let numbers = [1, 2, 3, 4, 5];
// 创建一个指向数组的切片
let slice = &numbers[..3];
// 输出切片的值
println!("{:?}", slice); // Output: [1, 2, 3]
// 创建一个指向切片的引用
let reference = &slice[1];
// 输出引用的值
println!("{}", reference); // Output: 2
}
输出
[1, 2, 3]
2
在这个示例中,我们首先创建了一个整数数组numbers。然后,我们使用&numbers[..3]创建了一个指向数组前三个元素的切片。接下来,我们使用&slice[1]创建了一个指向切片中第二个元素的引用。最后,我们通过引用输出了该元素的值。
总结起来,Rust中的切片和引用是密切相关的。切片是对数组或向量的部分引用的连续片段,而引用则是创建和操作切片的手段。使用切片和引用可以更高效地处理和操作数据,同时避免不必要的复制和移动操作。

操作 UTF-8 字符串 (操作中文字符串)
前文提到了几种使用 UTF-8 字符串的方式,下面来一一说明。
1、字符
如果你想要以 Unicode 字符的方式遍历字符串,最好的办法是使用 chars 方法,例如:
fn main() {
for c in "西红柿".chars() {
println!("{}", c);
}
}
输出如下
西
红
柿
2、字节
这种方式是返回字符串的底层字节数组表现形式:
fn main() {
for b in "西红柿".bytes() {
println!("{}", b);
}
}
输出如下:
228
184
173
229
155
189
228
186
186
3、获取子串
想要准确的从 UTF-8 字符串中获取子串是较为复杂的事情,例如想要从 holla西红柿नमस्ते 这种变长的字符串中取出某一个子串,使用标准库你是做不到的。 你需要在 crates.io 上搜索 utf8 来寻找想要的功能。
可以考虑尝试下这个库:utf8_slice。