目录
一、全方位了解字体渲染的全过程
1.加载顺序
2.实践操作:浏览器中调试字体渲染
3.总结:
二、字体文件的检查和数据查看
1.字体文件的操作软件
2.映射关系的建立
3.实践操作:翻找样式和真实内容
4.总结:
三、字体文件转换并实现网页内容还原
1.字体文件的转换
2.替换网页内容
3.实践操作:字体映射的解密和爬取
四、完美还原上百页的数据内容
1.字体文件的转换
2.替换网页内容
3.实践操作:爬虫实战,还原数据内容
4.总结:
一、全方位了解字体渲染的全过程
1.加载顺序
(1)载入字体内容或文件
(2)@font-face定义
(3)css中进行字体引用
2.实践操作:浏览器中调试字体渲染
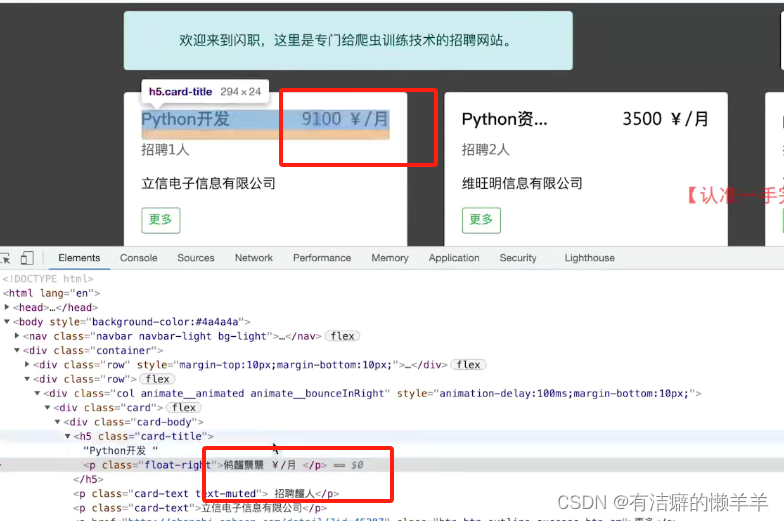
3.总结:
(1)字体渲染:网页看到的数据和调试工具中的数据不一致。
(2)字体内容可以是文件形式,或者是base64内容格式。
(3)将加密内容进行手动替换操作。
二、字体文件的检查和数据查看
1.字体文件的操作软件
windows平台:FontCreator
macOS平台:IconFronPreview
Linux平台:FontForge
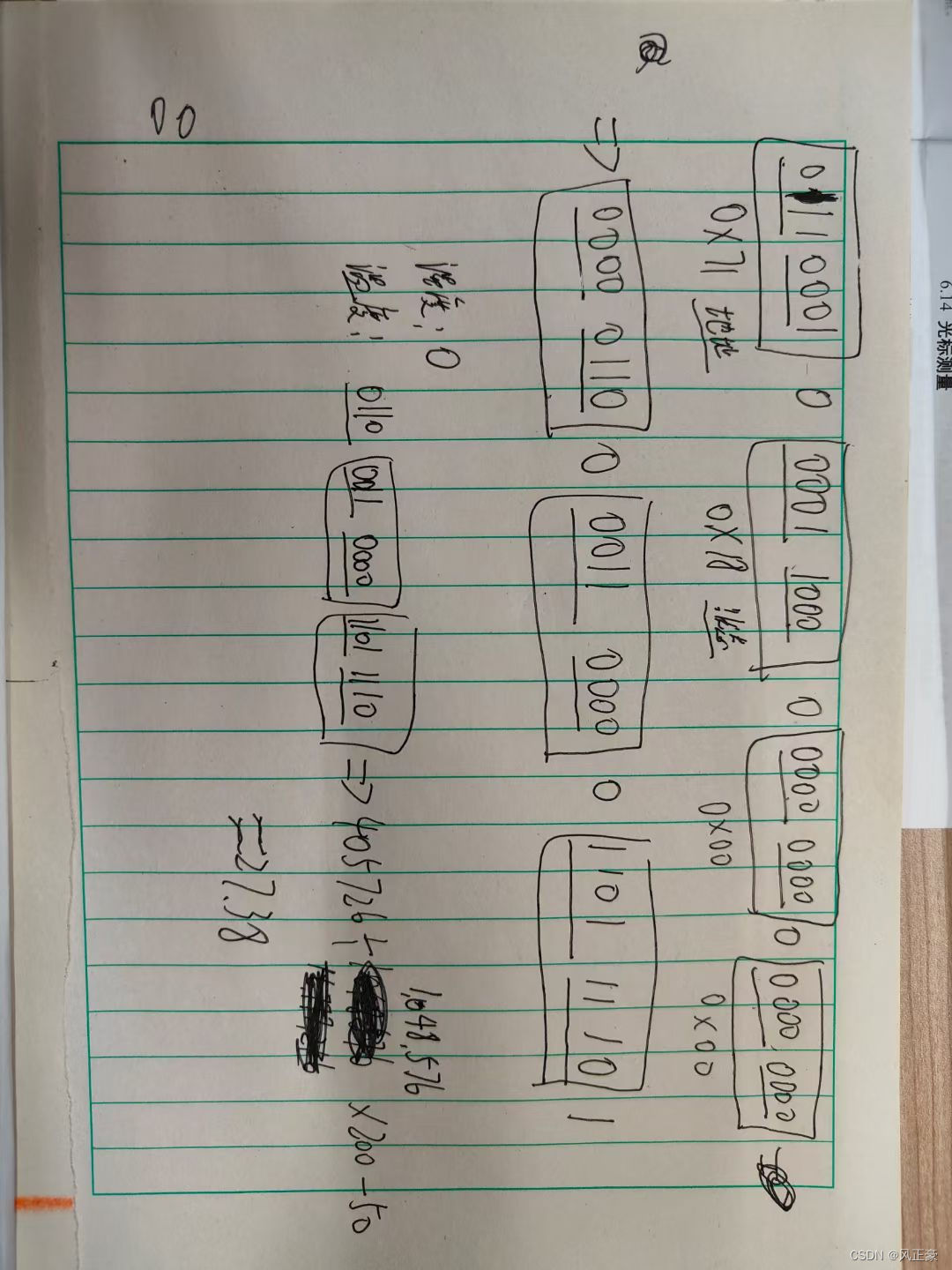
2.映射关系的建立
查看字体文件的内容,找出数字样式和真实内容
查看网页内容,找出网页的数字样式和真实内容
3.实践操作:翻找样式和真实内容
4.总结:
(1)一定要找出真实内容和数字样式的对应关系,非必需百分百找出
(2)浏览器调试工具看到的不一定是对的,可能是默认字体渲染
三、字体文件转换并实现网页内容还原
1.字体文件的转换
(1)python安装fontTools库
(2)使用fontTools读取TTF格式字体文件
(3)将内容保存成xml格式
(4)从xml格式中读取映射关系
2.替换网页内容
(1)请求网页内容
(2)循环映射关系,批量替换掉网页内容中的加密字体
(3)解析替换数据后的网页数据内容
(4)请求并分析接口数据的内容
(5)将日志保存到文件
3.实践操作:字体映射的解密和爬取
# 麣龒龤龒龒
# 10400
import requests
from fontTools.ttLib import TTFont # pip install fontTools
from lxml import etree
fonturl = 'http://shanzhi.spbeen.com/static/fonts/szec.ttf'
fontresponse = requests.get(fonturl)
print(fontresponse)
with open('font.ttf','wb') as file:
file.write(fontresponse.content)
font = TTFont("font.ttf")
# font.saveXML("font.xml")
result_dict = {}
for k,v in font['cmap'].getBestCmap().items():
# hex()函数是将十进制转成16进制
k = hex(k).replace('0x','&#x')+';'
v = int(v[8:10])-1
result_dict[k]=str(v)
print(result_dict)
url = 'http://shanzhi.spbeen.com/search/?word='
response = requests.get(url)
html = response.text
for k,v in result_dict.items():
html = html.replace(k,v)
# print(html)
htmlobj = etree.HTML(html)
divcard = htmlobj.xpath('.//div[@class="content"]/div')
for dc in divcard:
td = {}
td['标题'] = dc.xpath('./div/h5/a/text()')
td['薪资'] = dc.xpath('./div/h5/small/text()')
print(td)四、完美还原上百页的数据内容
1.字体文件的转换
2.替换网页内容
3.实践操作:爬虫实战,还原数据内容
import requests
from fontTools.ttLib import TTFont
from lxml import etree
from time import sleep
import logging
logging.basicConfig(level=logging.DEBUG,filename='debug.log',filename='a',format='%(asctime)s-%(levelname)s-[%(filename)s:%(lineno)d]-%(message)s')
font = TTFont("font.ttf")
result_dict = {}
for k,v in font['cmap'].getBestCmap().items():
# hex()函数是将十进制转成16进制
k = hex(k).replace('0x','&#x')+';'
v = int(v[8:10])-1
result_dict[k]=str(v)
def replace_html(html:str):
for k,v in result_dict.items():
html = html.replace(k,v)
return html
url = 'http://shanzhi.spbeen.com/search/?word=%E5%B5%8C%E5%85%A5%E5%BC%8F&page={}&_=1631261605624'
for i in range(1,10000):
turl = url.format(i)
response = requests.get(turl)
html = replace_html(reponse.text)
htmlobj = etree.HTML(html)
divcard = htmlobj.xpath('.//div[contains(@class, "animate__animated")]')
total_num += len(divcard)
print("当前页面是第{}页,总计有{}条数据,当前页数据如下:".format(i,len(divcard),total_num))
for dc in divcard:
td = {}
td['标题'] = dc.xpath('./div/h5/a/text()')
td['薪资'] = dc.xpath('./div/h5/small/text()')
print(' ',td)
if len(divcard) < 10:
break
else:
pass
sleep(0.1)
4.总结:
(1)提取出具体的原数据和对应数字,进行网页内容的替换
(2)注意原数据的完整格式,确保替换后的数据没有多余符号
(3)找数据接口和具体参数,循环请求接口拿数据