一、SPI协议简介
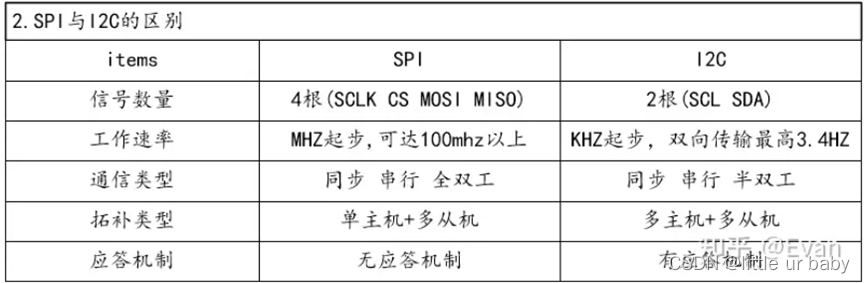
SPI = Serial Peripheral Interface,是串行外围设备接口,是一种高速,全双工,同步的通信总线。常规只占用四根线,节约了芯片管脚,PCB的布局省空间。现在越来越多的芯片集成了这种通信协议,常见的有EEPROM、FLASH、AD转换器等。
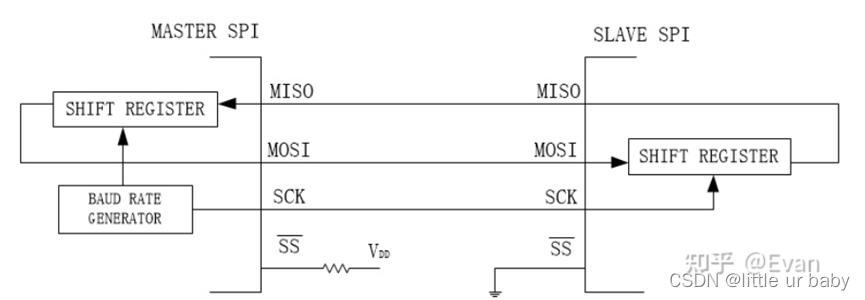
二、遵循SPI协议控制DAC:tlv5618
1.时序分析
从tlv5618芯片的数据手册中可找到其时序特性:
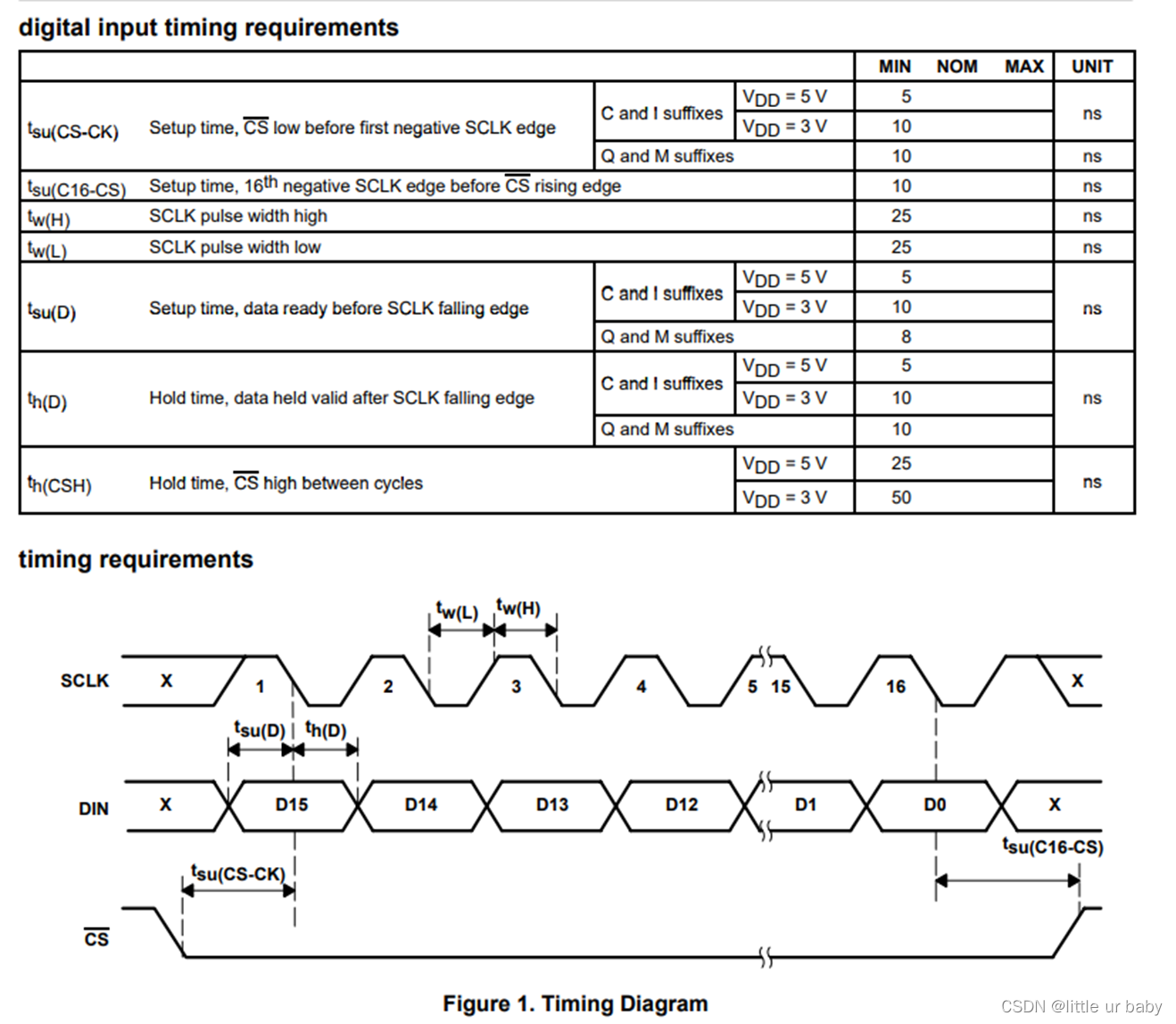
没有Miso线时序,所以只需要设计三根线即可,因为此dac不需要主机发数据。由tsu(D)与th(D)均基于sclk的时钟下降沿描述,可以确定adc在时钟下降沿读取din数据,所以我们在sclk时钟上升沿改变数据即可。向由tw(不小于50ns)确定sclk时钟频率为20MHz;根据DIN时序可知在SCLK上升沿DIN改变,在SCLK下降沿读取DIN;tsu(D)建立时间,不小于10ns;th(D)保持时间,不小于10ns;故直接用20MHz时钟设计DIN长度即可满足;tsu用于限制CS的起止点,tsu(csh)应不小于50ns,tsu(cs-cl)应不小于10ns,tsu(c16-cs)应不小于10ns,在仿真时检验并调整使CS满足tsu即可。
2.模块框图
根据时序图可知,用线性序列机即可(LSM)实现。定义的信号如下:

3.代码实现
//采用线性序列机(LSM)来实现
module dac_driver(
input fpga_clk ,
input rst_n ,
input dac_pulse ,
input [15:0]dac_data ,
output reg cs_n ,//low level valid
output reg sclk ,
output reg mosi ,
output reg dac_sig ,
output reg dac_done
);
//供电电压不同,参数最小值不同,这里按照兼容VDD = 5V 和 VDD = 3V 的参数设计
// tsu(cs-ck) : 20ns //
// tsu(c16-cs): 20ns //
// th(D): 10ns //
// th(csh):50ns //
// sclk : 20Mhz //
//
// D15 - D12 : 设置位 根据手册来设置 //
// D11 - D0 : 数据位 需要转化的电压值 //
wire clk_40m ;
pll pll_inst(
.inclk0(fpga_clk),
.c0(clk_40m)
);
//detect dac_pulse
reg dac_pulse_reg ;
always@(posedge fpga_clk or negedge rst_n)
if(!rst_n)
dac_pulse_reg <= 0 ;
else
dac_pulse_reg <= dac_pulse ;
//dac_sig
always@(posedge fpga_clk or negedge rst_n)
if(!rst_n)
dac_sig <= 0 ;
else if( (dac_pulse_reg == 0) & ( dac_pulse == 1) )
dac_sig <= 1 ;
else if( dac_done )
dac_sig <= 0 ;
// dac_cnt : 0 - 15
reg [5:0]dac_cnt ;
always@(posedge clk_40m or negedge rst_n)
if(!rst_n)
begin
dac_cnt <= 0 ;
end
else if(dac_sig)
begin
dac_cnt <= dac_cnt + 1 ;
if(dac_cnt == 34 )
dac_cnt <= 0 ;
end
else
dac_cnt <= 0 ;
//dac_done:
always@(posedge clk_40m or negedge rst_n)
if(!rst_n)
dac_done <= 0 ;
else if( dac_cnt == 34 )
dac_done <= 1 ;
else if( dac_done )
dac_done <= 0 ;
// cs_n
always@(posedge clk_40m or negedge rst_n)
if(!rst_n)
cs_n <= 1 ;
else if(dac_sig)
begin
if(dac_cnt < 32 )
cs_n <= 0 ;
else
cs_n <= 1 ;
end
// sclk
always@(posedge clk_40m or negedge rst_n)
if(!rst_n)
sclk <= 0 ;
else if(dac_sig)
begin
sclk <= !sclk ;
end
else
sclk <= 0 ;
//mosi
always@(posedge clk_40m or negedge rst_n)
if(!rst_n)
mosi <= 0 ;
else if(dac_sig)
begin
case(dac_cnt)
0 : mosi <= dac_data[15] ;
2 : mosi <= dac_data[14] ;
4 : mosi <= dac_data[13] ;
6 : mosi <= dac_data[12] ;
8 : mosi <= dac_data[11] ;
10 : mosi <= dac_data[10] ;
12 : mosi <= dac_data[9] ;
14 : mosi <= dac_data[8] ;
16 : mosi <= dac_data[7] ;
18 : mosi <= dac_data[6] ;
20 : mosi <= dac_data[5] ;
22 : mosi <= dac_data[4] ;
24 : mosi <= dac_data[3] ;
26 : mosi <= dac_data[2] ;
28 : mosi <= dac_data[1] ;
30 : mosi <= dac_data[0] ;
32 : mosi <= 0 ;
default:;
endcase
end
else
mosi <= 0 ;
endmodule`timescale 1ns/1ns
module dac_driver_tb();
reg fpga_clk ;
reg rst_n ;
reg dac_pulse ;
reg [15:0]dac_data ;
wire cs_n ;
wire sclk ;
wire mosi ;
wire dac_done ;
dac_driver dac_driver_inst(
.fpga_clk(fpga_clk) ,
.rst_n(rst_n) ,
.dac_pulse(dac_pulse) ,
.dac_data(dac_data) ,
.cs_n(cs_n) ,//low level valid
.sclk(sclk) ,
.mosi(mosi) ,
.dac_done(dac_done)
);
initial fpga_clk = 0 ;
always #10 fpga_clk = ! fpga_clk ;
initial
begin
rst_n = 0 ;
dac_pulse = 0 ;
dac_data = 0 ;
#100 ;
rst_n = 1 ;
#100 ;
dac_data = 16'h5a5a ;
#100 ;
dac_pulse = 1 ;
#40 ;
dac_pulse = 0 ;
#100;
wait(dac_done);
#3000 ;
dac_data = 16'ha5a5 ;
#100 ;
dac_pulse = 1 ;
#40 ;
dac_pulse = 0 ;
#100;
wait(dac_done);
#3000 ;
$stop;
end
endmodule4.仿真验证
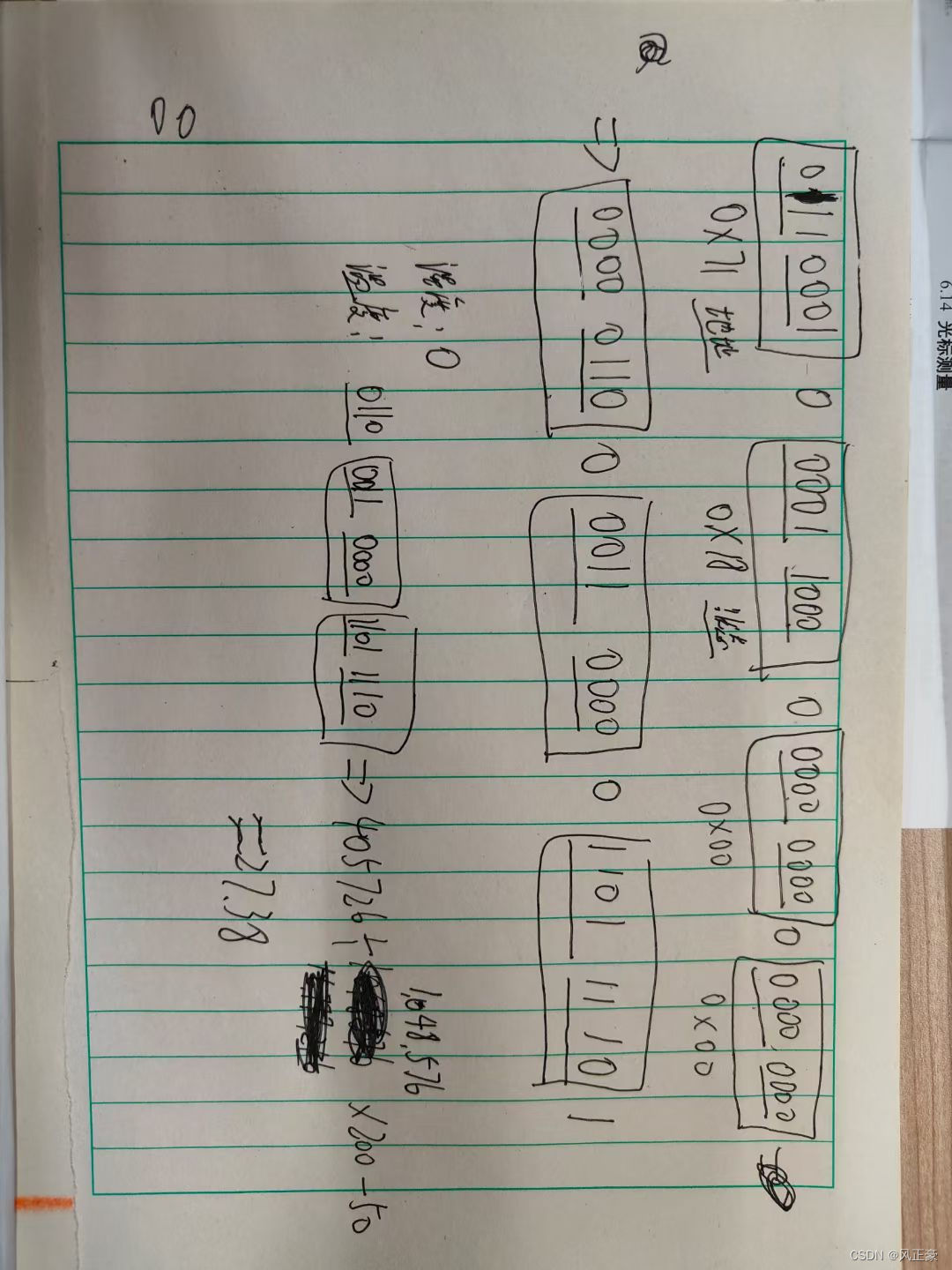
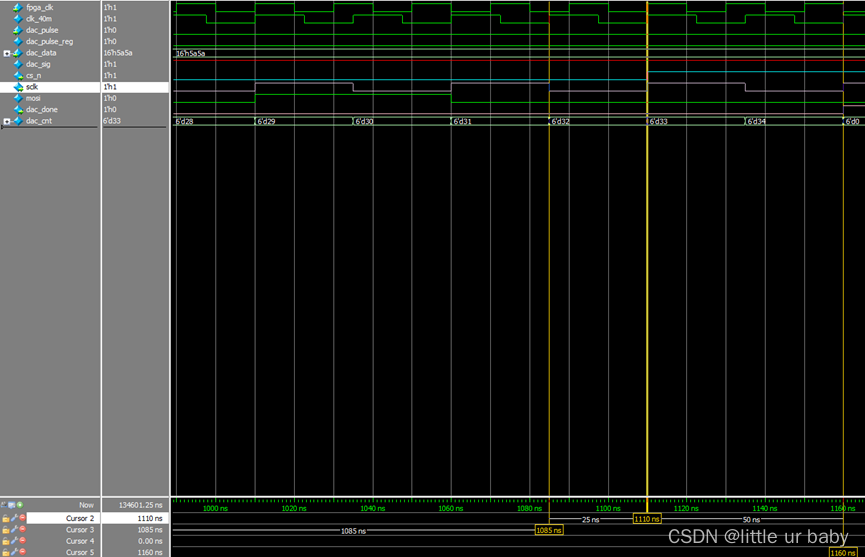 由图可知,tsu为25ns,大于tsu(c16-cs)(10ns),th(csh)为50ns,不小于50ns,满足要求。
由图可知,tsu为25ns,大于tsu(c16-cs)(10ns),th(csh)为50ns,不小于50ns,满足要求。
三、遵循SPI协议控制ADC:ADC128S022
1.时序分析
ADC128S022的spi接口时序图如下:
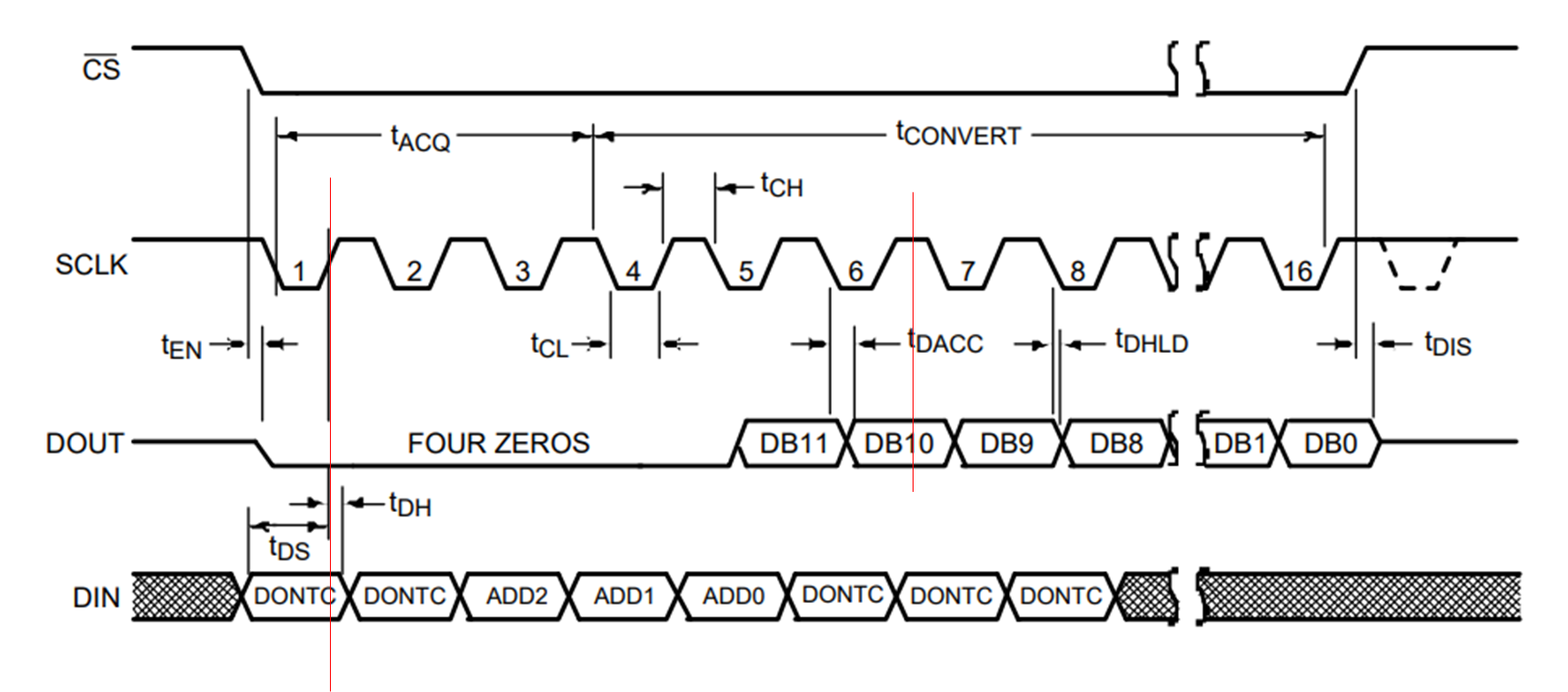

根据时序图及对应参数数值作以下分析:
1.fSCLK = 3.2 MHz to 8 MHz ,这里我们选取fsclk = 4Mhz进行设计,可以满足要求。
2.mosi:通过sds和tdh来判断,它是基于sclk的上升沿描述的,所以从机大概率是在时钟上升沿读取数据,因而可以选择在sclk的下降沿改变数据,从而到上升沿时数据已经保持稳定。
3.miso:根据tdacc和tdhld以及时序图判断,它基于下降沿描述的,即从机在下降沿改变数据,故主机在上升沿进行读取。(读和写的变化沿大部分都是一致的)
根据时序图分析画出如下波形:

2.模块框图
本模块通过一个adc_en脉冲开启一次adc转换读取;adc_channel用于选择八个ad通道中的一个;每次转换完成发出一个adc_done脉冲,并输出转换完成的数据adc_data;

3.代码实现
//****************************//
//fsclk要求:3.2MHz - 8MHz 取:4MHz //
//
module adc_driver(
input fpga_clk ,
input rst_n ,
input [2:0]adc_channel ,
input adc_en ,
//SPI
input miso ,
output reg mosi ,
output reg cs_n ,
output reg sclk ,
output reg adc_done,
output reg adc_state ,
output reg [11:0]adc_data
);
wire clk_8m ;
pll pll_inst(
.inclk0(fpga_clk),
.c0(clk_8m)
);
reg adc_en_reg ;
always@(posedge fpga_clk or negedge rst_n)
if(!rst_n)
adc_en_reg <= 0 ;
else
adc_en_reg <= adc_en ;
always@(posedge fpga_clk or negedge rst_n)
if(!rst_n)
adc_state <= 0 ;
else if(adc_en == 1 & adc_en_reg == 0)
adc_state <= 1 ;
else if(adc_done)
adc_state <= 0 ;
reg [6:0]adc_cnt ;
always@(posedge clk_8m or negedge rst_n)
if(!rst_n)
adc_cnt <= 0 ;
else if ( adc_state == 1 )
adc_cnt <= adc_cnt + 1 ;
else if(adc_done)
adc_cnt <= 0 ;
//cs_n
always@(posedge fpga_clk or negedge rst_n)
if(!rst_n)
cs_n <= 1 ;
else if( adc_en )
cs_n <= 0 ;
else if( adc_done )
cs_n <= 1 ;
//sclk
always@(posedge clk_8m or negedge rst_n)
if(!rst_n)
sclk <= 1 ;
else if(adc_state)
sclk <= ~sclk ;
else
sclk <= 1 ;
//mosi miso
reg [11:0]adc_data_reg ;
always@(posedge clk_8m or negedge rst_n)
if(!rst_n)
begin
mosi <= 0 ;
adc_done <= 0 ;
adc_data <= 0 ;
adc_data_reg <= 0 ;
end
else if (adc_state)
begin
case(adc_cnt)
4 : mosi <= adc_channel[2] ;
6 : mosi <= adc_channel[1] ;
8 : begin mosi <= adc_channel[0] ; end
9 : adc_data_reg[11] <= miso ;
11 : adc_data_reg[10] <= miso ;
13 : adc_data_reg[9] <= miso ;
15 : adc_data_reg[8] <= miso ;
17 : adc_data_reg[7] <= miso ;
19 : adc_data_reg[6] <= miso ;
21 : adc_data_reg[5] <= miso ;
23 : adc_data_reg[4] <= miso ;
25 : adc_data_reg[3] <= miso ;
27 : adc_data_reg[2] <= miso ;
29 : adc_data_reg[1] <= miso ;
31 : adc_data_reg[0] <= miso ;
32 : begin adc_done <= 1 ; adc_data <= adc_data_reg ; end
default : ;
endcase
end
else
begin
adc_done <= 0 ;
adc_data_reg <= 0 ;
mosi <= 0 ;
end
endmodule`timescale 1ns/1ns
/*注意,由于使用联合仿真的时候,modelsim的默认目录是当前Quartus工
程下的simulation目录下的modelsim文件夹,所以,需要在执行仿真前手
动将sin_12bit.txt文件拷贝到simulation/modelsim下。修改了
sin_12bit.txt内容后也请记得重新覆盖modelsim下的sin_12bit.txt文件
*/
`define sin_data_file "./sin_12bit.txt"
module adc128s022_tb;
reg Clk;
reg Rst_n;
reg [2:0]Channel;
wire [11:0]Data;
reg En_Conv;
wire Conv_Done;
wire ADC_State;
wire [7:0]DIV_PARAM;
wire ADC_SCLK;
wire ADC_CS_N;
reg ADC_DOUT;
wire ADC_DIN;
assign DIV_PARAM = 13;
reg[11:0] memory[4095:0];//测试波形数据存储空间
reg[11:0] address;//存储器地址
adc_driver adc_driver_inst(
.fpga_clk(Clk) ,
.rst_n(Rst_n) ,
.adc_channel(Channel) ,
.adc_en(En_Conv) ,
//SPI
.miso(ADC_DOUT) ,
.mosi(ADC_DIN) ,
.cs_n(ADC_CS_N) ,
.sclk(ADC_SCLK) ,
.adc_done(Conv_Done),
.adc_state(ADC_State) ,
.adc_data(Data)
);
initial Clk = 1'b1;
always #10 Clk = ~Clk;
//将原始波形数据从文件读取到定义的存储器中
initial $readmemh(`sin_data_file,memory);//读取原始波形数据读到memory中
integer i;
initial begin
Rst_n = 0;
Channel = 0;
En_Conv = 0;
ADC_DOUT = 0;
address = 0;
#101;
Rst_n = 1;
#100;
Channel = 5;
for(i=0;i<3;i=i+1)begin
for(address=0;address<4095;address=address+1)begin
En_Conv = 1;
#20;
En_Conv = 0;
gene_DOUT(memory[address]); //依次将存储器中存储的波形读出,按照ADC的转换结果输出方式送到DOUT信号线上
@(posedge Conv_Done); //等待转换完成信号
#200;
end
end
#20000;
$stop;
end
//将并行数据按照ADC的数据输出格式,送到DOUT信号线上,供控制模块采集读取
task gene_DOUT;
input [15:0]vdata;
reg [4:0]cnt;
begin
cnt = 0;
wait(!ADC_CS_N);
while(cnt<16)begin
@(negedge ADC_SCLK) ADC_DOUT = vdata[15-cnt];
cnt = cnt + 1'b1;
end
end
endtask
endmodule
4.仿真验证

仿真结果满足时序要求,可行。








![[尚硅谷React笔记]——第5章 React 路由](https://img-blog.csdnimg.cn/dc3b54d6f48d4ed1aa31eb66454cd7a5.png)