给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
- 例如,如果
words = ["ab","cd","ef"], 那么"abcdef","abefcd","cdabef","cdefab","efabcd", 和"efcdab"都是串联子串。"acdbef"不是串联子串,因为他不是任何words排列的连接。
返回所有串联子串在 s 中的开始索引。你可以以 任意顺序 返回答案。
示例 1:
输入:s = "barfoothefoobarman", words = ["foo","bar"] 输出:[0,9] 解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。 子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。 子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。 输出顺序无关紧要。返回 [9,0] 也是可以的。
示例 2:
输入:s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
输出:[]
解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。
s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。
所以我们返回一个空数组。
示例 3:
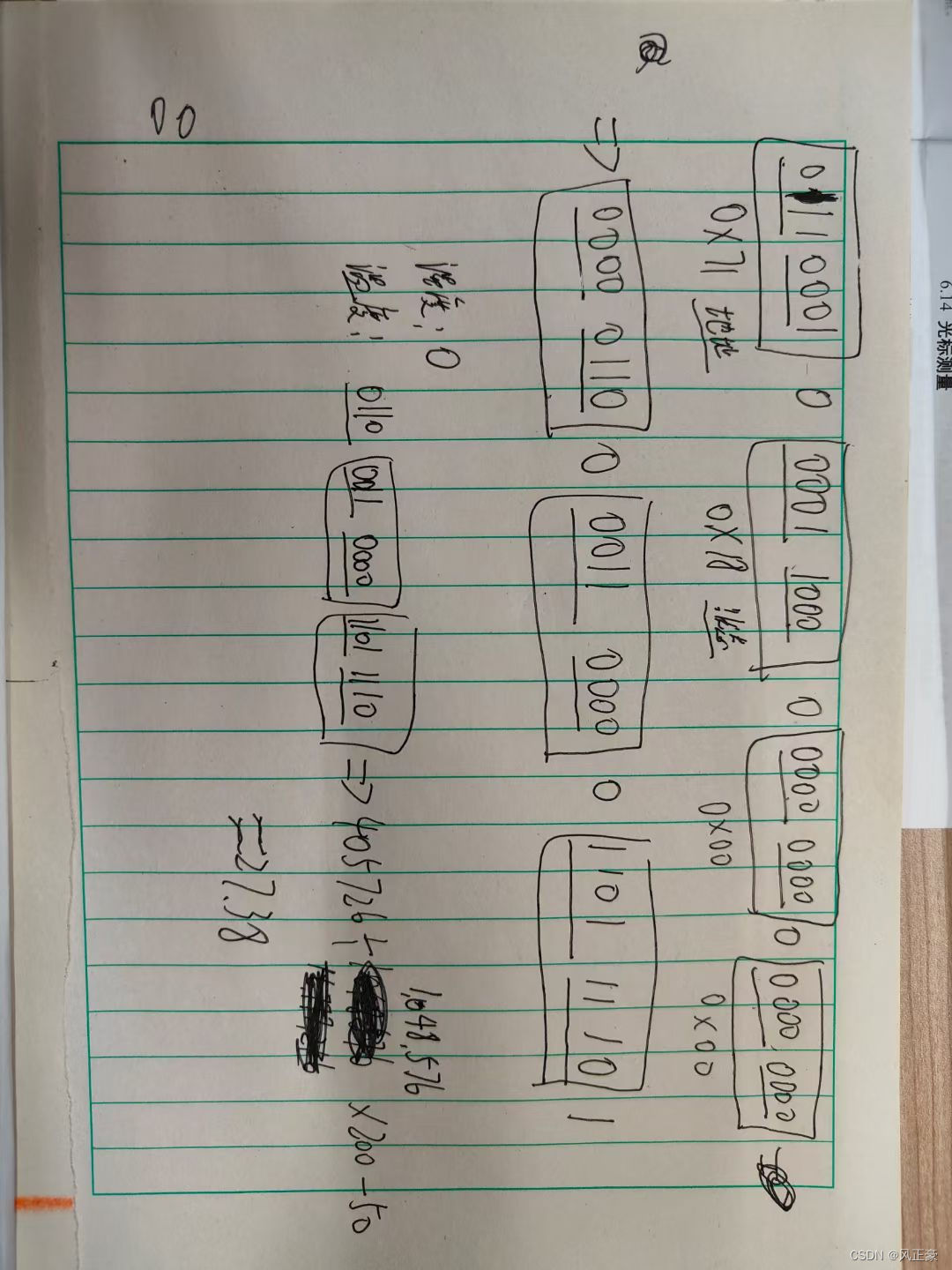
输入:s = "barfoofoobarthefoobarman", words = ["bar","foo","the"] 输出:[6,9,12] 解释:因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。 子串 "foobarthe" 开始位置是 6。它是 words 中以 ["foo","bar","the"] 顺序排列的连接。 子串 "barthefoo" 开始位置是 9。它是 words 中以 ["bar","the","foo"] 顺序排列的连接。 子串 "thefoobar" 开始位置是 12。它是 words 中以 ["the","foo","bar"] 顺序排列的连接。 (1)情况一,子串完全匹配
(2)情况二,遇到了不匹配的单词,直接将 left 移动到该单词的后边

(3)情况三,遇到了符合的单词,但是次数超了

class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> res;
if (s.size() == 0 || words.size() == 0) {
return res;
}
int wordsNum = words.size();//words的个数
int wordLen = words[0].size();//word的长度
int width = wordsNum*wordLen;
if(s.size()<width) return res;// 长度不符合预期
// 将单词数组构建成哈希表
unordered_map<string,int> words_map;
// unordered_map<string,int> tmp_map;
string word="";
for (string str : words) {
words_map[str]+=1;
}
// 只遍历 0 ~ wordLen 即可,因为滑动窗口都是按照 wordLen 的倍数进行滑动的
for(int i=0;i<wordLen;i++) {
unordered_map<string,int> tmp_map;
// 滑动窗口
int left=i,right=i,count=0;
while(right + wordLen <= s.length()) {
string word = s.substr(right,wordLen);
// cout<<"word : " << word<<endl;
right += wordLen;
if(words_map.find(word)!=words_map.end()) {
int num = tmp_map[word]+1;
// 有效单词数+1
tmp_map[word]+=1;
count++;
// 出现情况三,遇到了符合的单词,但是次数超了
if(words_map[word] < num) {
// 一直移除单词,知道次数符合
while(words_map[word] < tmp_map[word]) {
string deleteWord = s.substr(left,wordLen);// 要移除的单词
tmp_map[deleteWord]--;// 更新tmp_map
left+=wordLen;// 同时移动左指针
count--;// count数目-1
}
}
} else {
// 出现情况二,遇到了不匹配的单词,直接将 left 移动到该单词的后边
tmp_map.clear();// 清空tmp_map
count=0;// 清空count
left=right;
if(left+width>s.size()) break;
}
if(count == wordsNum) {
res.push_back(left);
// 出现情况一,子串完全匹配,我们将上一个子串的第一个单词从tmp中移除,窗口后移wordLen
string firstWord = s.substr(left,wordLen);
tmp_map[firstWord]--;
count--;
left += wordLen;
}
}
}
return res;
}
};改进一下:
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> res;
if (s.size() == 0 || words.size() == 0) {
return res;
}
int wordsNum = words.size();//words的个数
int wordLen = words[0].size();//word的长度
int width = wordsNum*wordLen;
if(s.size()<width) return res;// 长度不符合预期
// 将单词数组构建成哈希表
unordered_map<string,int> words_map;
// unordered_map<string,int> tmp_map;
string word="";
for (string str : words) {
words_map[str]+=1;
}
if(wordLen==1 && words_map.size()==1) {
char c=words[0][0];
for(int i=0;i<=s.size()-width;i++) {
if(s[i]==c)
res.push_back(i);
}
return res;
}
// 只遍历 0 ~ wordLen 即可,因为滑动窗口都是按照 wordLen 的倍数进行滑动的
for(int i=0;i<wordLen;i++) {
unordered_map<string,int> tmp_map;
// 滑动窗口
int left=i,right=i,count=0;
while(right + wordLen <= s.length()) {
string word = s.substr(right,wordLen);
// cout<<"word : " << word<<endl;
right += wordLen;
if(words_map.find(word)!=words_map.end()) {
int num = tmp_map[word]+1;
// 有效单词数+1
tmp_map[word]+=1;
count++;
// 出现情况三,遇到了符合的单词,但是次数超了
if(words_map[word] < num) {
// 一直移除单词,知道次数符合
while(words_map[word] < tmp_map[word]) {
string deleteWord = s.substr(left,wordLen);// 要移除的单词
tmp_map[deleteWord]--;// 更新tmp_map
left+=wordLen;// 同时移动左指针
count--;// count数目-1
}
}
} else {
// 出现情况二,遇到了不匹配的单词,直接将 left 移动到该单词的后边
tmp_map.clear();// 清空tmp_map
count=0;// 清空count
left=right;
if(words_map.find(s.substr(right,wordLen))==words_map.end()) {
right+=wordLen;
left=right;
}
if(left+width>s.size()) break;
}
if(count == wordsNum) {
res.push_back(left);
// 出现情况一,子串完全匹配,我们将上一个子串的第一个单词从tmp中移除,窗口后移wordLen
string firstWord = s.substr(left,wordLen);
tmp_map[firstWord]--;
count--;
left += wordLen;
}
}
}
return res;
}
};参考文章:30. 串联所有单词的子串 - 力扣(LeetCode)![]() https://leetcode.cn/problems/substring-with-concatenation-of-all-words/solutions/9092/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by-w-6/?envType=study-plan-v2&envId=top-interview-150
https://leetcode.cn/problems/substring-with-concatenation-of-all-words/solutions/9092/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by-w-6/?envType=study-plan-v2&envId=top-interview-150



![[尚硅谷React笔记]——第5章 React 路由](https://img-blog.csdnimg.cn/dc3b54d6f48d4ed1aa31eb66454cd7a5.png)