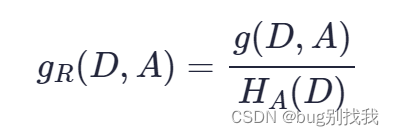一 进程概念
什么是进程呢?许多资料都说一个已经加载到内存的程序就叫进程,意思是只要代码到了内存就能跑起来了吗?接下来我就谈谈对进程概念的理解。
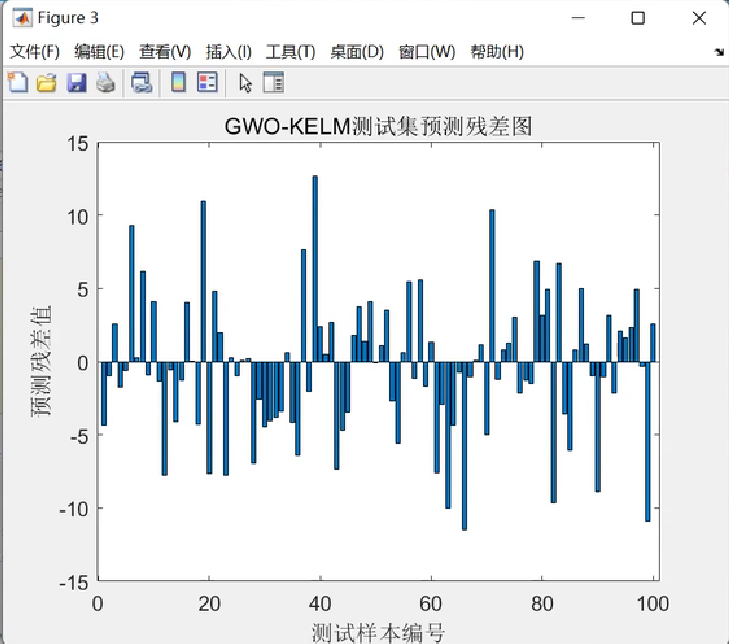
1 如何管理进程
我们可能运行多个进程,这些进程有些结束,有些要退出,都需要操作系统控制将其搬进内存或者从内存中移出去,这意味着进程都要在操作系统的管理下,不能随意进出。由我上篇博客中可知操作系统的管理工作是通过管理数据实现的,所以那管理进程就是管理数据。这个数据可不是程序的代码和数据,而是描述进程的数据,因为操作系统只要描述好进程,根本不用看代码写了什么就能管理进程。
那如何描述进程呢,首先怎么才能让不同的进程区分开来呢-属性,我们用身份证区分每个人,进程的属性之一就是-标识符,这个的作用就类似身份证用来区分进程,此外我们是可以同时运行多个进程的,例如同时在手机上看小说和听音乐,有时后台还挂着微信,QQ,这些程序的代码都要CPU去跑,但cpu只有一个,所以进程还需要一个属性,那就是优先级,还有其它的属性后提,但这些属性都要存在一起,也就是说还要生成一个PCB结构体来存属性,操作系统就可以管理这个PCB对象来达到管理的目的。
2 PCB对象的意义
仅仅是代码到了内存中,没有这个结构体,操作系统是不会对这个代码进行管理的,不管理那就不会让cpu执行代码,一个不被执行的代码你觉得还叫进程合适吗?为什么不管理呢?
我的理解就是操作系统不愿意,它可没空时刻盯着你这些没有PCB对象的程序,凭什么为了你个不合规的代码耽误我的办事效率,没创建那就从内存出去,真让操作系统管,不还是用一些变量记录一下你这个进程叫什么名字,你现在运行到哪了,明明系统可以用一个链表把所有PCB对象管理起来,你偏偏说我不想和这些普通的进程待在一起,那对于系统而言,那就要两边跑了,能是肯定能实现,只是没必要,一切进程皆平等,都在我的链表里等安排,操作系统只做最高效的事。
由此得, 所以如果仅仅是看程序在不在内存中来判断是否是进程,有点不太准确,此时进程还不算真正形成,还得在操作系统那创建个PCB对象,挂个名,和系统说要执行快点我的代码,你的代码后续才会执行。去办事你也得挂个号排队吧,总不能人站在办事大厅吧。
二 进程的属性
接下来就看看这个PCB对象内部究竟有什么,是什么信息就能让操作系统管理进程呢?
标识符:描述本进程的唯一标识符,用来区别其他的进程
状态:任务状态,如休眠,执行,暂停。
优先级:相对于其他的进程的优先级。
程序计数器:程序中即将被执行的下一条指令的地址。
内存指针:包括程序代码和进程相关数据的指针,还有其他的进程共享的内存块的指针
上下文数据:进程执行时处理器的寄存器中的数据
I/O状态信息:包括显示I/O请求,分配给进程的I/O设备和进程使用的文件列表
记账信息:可能包括处理器的时间总和,使用的时钟总和,时间限制
其他信息
1标识符,大家都是进程,有时候某个进程很紧急要处理,我都找不到这个进程。
2 状态参数,这也很好理解,有时候这个暂停这个进程,去执行其它进程的代码,就先把这个进程设为暂停或休眠,过会唤醒继续执行,为了唤醒后知道从哪继续执行,也就有了程序计数器,cpu执行一条指令是非常快的,所以一定是需要快速知道下一条指令地址在哪的,所以程序计数器一般是在cpu内的寄存器,所以这个地址也是属于上下文数据的一种,上下文数据的作用要在进程状态后提,这个属性都是在一个结构体内,结构体内又不放代码,所以就得有个指针链接代码,也就有了内存指针,这其实也就意味着在操作系统那排队等执行的其实是这个结构体,排到你了,就通过这个指针去找代码,后面说进程状态会更好理解,等待是怎样的,也就更好理解为什么是PCB去排队比代码排队好。
记账信息是为了公平分配cpu,就是不让一个进程长时间地占用cpu资源,诶,不对啊,我手机一直开着软件看视频,那不就是让这个软件的代码一直在被cpu处理吗,实际上有个概念叫并发,也就是说cpu会让一个进程执行了十几毫秒后,切换下一个进程执行它的代码,而在一秒内,所有进程都跑了起来,这称之为并发,我们几乎感觉不到当前进程有停止的过程,还有其它的属性都要后面结合场景解释,现在先放下不谈。
再分享一条指令,ps ajx打印进程信息,对于我们后面观察子进程创建有用处
三 创建子进程
1 获取进程的pid
先前说进程的属性之一是标识符,这个标识符其实是pid,而linux提供一些函数——getpid可以获取到当前进程的标识符,getppid可以获取父进程的pid,接下来就用linux下的vim来编写代码,尝试一下获取pid和ppid。我们先前说一个程序运行,操作系统会帮忙创建PCB对象,最终形成一个进程,那我们的test就是个可执行程序,如果./让它运行,那不就也会形成一个进程,所以我们下面看到打印出对于进程的pid是9797,那父进程是谁,我这个程序运行起来了怎么突然多了个爹。
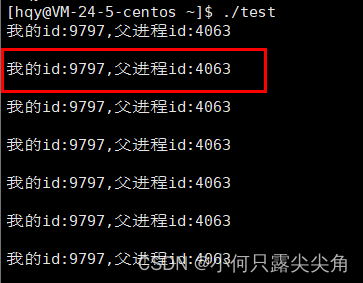
打印一下,看看这个父进程是谁,噢,原来是bash命令行,所以我们就可以大致猜测一下,bash此时创建了一个子进程(如何创建fork会提及),至于为什么要这么做呢,我觉得有一种解释很符合我这个菜鸟阶段理解,那就是进程,程序都不是绝对安全运行的,如果bash去执行你的代码,你代码出问题了,出现异常终止了,这个进程就被干掉了,那不是直接把bash也整崩溃了,那后续怎么接受你的其它命令,重启?这不太合理吧,所以bash和执行代码分离在不同的进程对效率是非常有意义的。

当我们的可执行程序运行起来了,我们想要看看代码在跑的时候是不是形成了一个进程,所以我们去另一个显示窗口打印的进程信息,因为此时bash进程挂起了,在执行子进程的代码,没办法接受指令,可以通过Xhell的复制会话或者复制渠道都可以再建立一个输入指令的窗口,这样就可以让test一边跑,我们这同时看进程信息了。
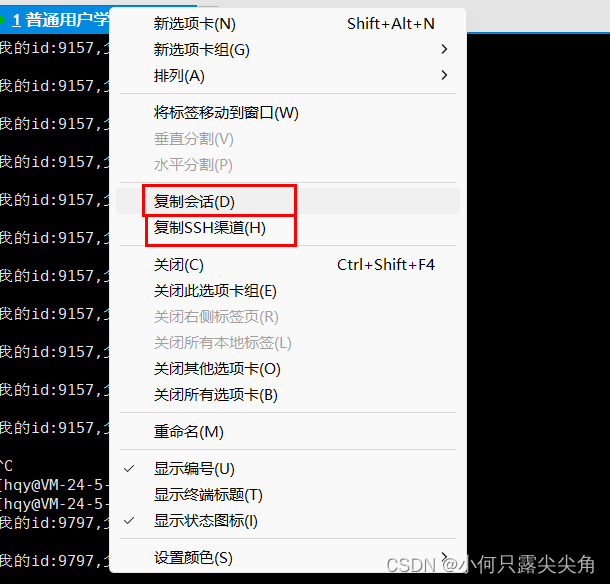
循环打印进程信息,while(空格) :; do+执行的指令, 指令之间一般用;隔开,|这个是管道文件,ps ajx把所有进程信息放到管道文件,然后传给head指令使用,这里是想把进程信息的那个表格头显示出来,语法特殊,所以指令之间没加&&或者; ,grep test是在给的信息中查找 test关键字,查找出来的信息也会把自己带上,这个可能是设计的结果,用grep -v grep就可以去除这个显示,最后加个done,就可以循环显示进程信息了。
[hqy@VM-24-5-centos ~]$ while :;do ps ajx | head -1 && ps ajx |
grep test; sleep 1; done

然后就是来认识认识fork这个函数。
2 初识fork
先来段代码,一步步揭示fork的作用。
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
printf("begin\n");
fork();
printf("我是进程\n");
return 0;
}
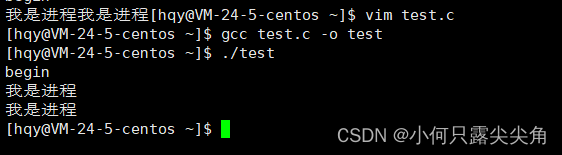
诶,奇怪,为什么有三个printf,都说fork创建子进程,那子进程干了什么呢?难道是执行我父进程的代码吗?好像是如此,可是我自己不就能做了,怎么还要个子进程一起做同样的事呢?别急,我们先看看man手册中的fork,直接在bash命令行输入man fork即可查询,如果没找到那就要切换为root账号去下载,下载指令为 yun install -y man-pages,再用man手册查找就可以出如下图。
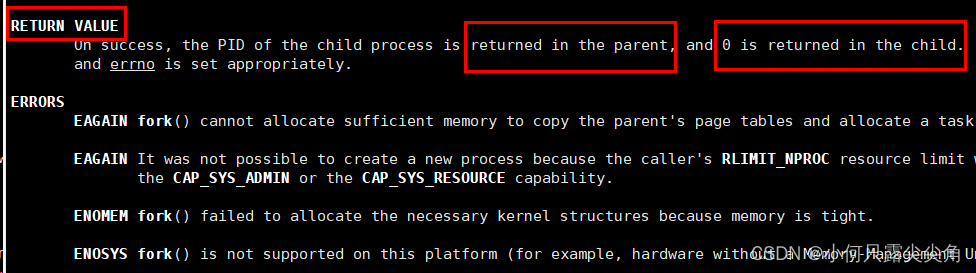
诶好像有两个返回值,那我们设计如下代码看看是不是真有两个返回值。
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
printf("begin\n");
int ret = fork();
if(ret == 0)
printf("我是子进程\n");
else
printf("我是父进程\n");
return 0;
}
完蛋,if和else都进去了。要说清楚为什么得分成好几个问题,但首先要知道一点的是,bash创建子进程去执行test这个可执行程序的代码,然后这个子进程2又调用fork去创建子进程3,此时就有三个进程了,我要说的就是这个子进程3是新来的,请问它的代码哪里来? 我们刚出生也是什么都没有,但是父母会给我们提供物资,所以子进程其实是和父进程共享执行fork之后的代码和数据,别钻牛角尖问为什么不把之前的代码也执行了,让子进程执行fork后的代码其实对于使用者的意义,就是可以控制子进程的执行流从哪开始。
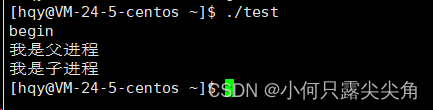
噢,子进程是能用父进程的代码,这样就为它能执行printf奠定了基础,可是还有很多问题啊?我一个个列举出来,1 fork函数为什么要返回两个值? 2 而且为什么是0和子进程的pid这两个不同的值?3 一个函数如何返回两个值,如何return两次? 4 一个变量ret如何接受两个返回值?
先大致说说问题4吧,父子进程共享数据这个点没错,但是如果要修改,就会发生写时拷贝,什么?你说为什么不一开始就拷贝一份,我们拿嘴说的容易,计算机可就累死了,有没有可能这些数据只有小部分是会被修改的,大部分都是不变的,那这个时候内存不就存在重复的数据了吗,浪费可耻! 所以我们现在就认为ret的值在父子进程中是不一样的。(这里留个伏笔,如果去打印ret的地址,会惊讶地发现是一样的,这里至少我要再往后三四篇博客才会解释)
此时我们就知道为什么会既会进入if语句,又会进入else语句,也就可以顺便解释解释问题3了。
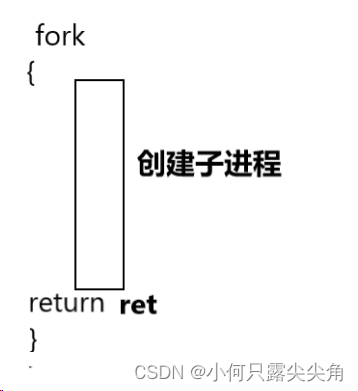
如图,fork函数肯定是会创建子进程的,如何创建,俺也不会,我能了解到fork内部已经尽力了,由上述得,创建子进程后,子进程就开始共享父进程的代码,也就是说子进程不仅共享fork后面的代码,还共享了一部分fork函数内部的代码,而return之前子进程绝对创建好了,那return 这句代码,子进程也要执行,所以为什么能返回两次(问题3),就是因为return被父子进程各执行了一次。而且bash是如何创建子进程的呢,内部肯定就是封装了fork。
因为fork函数当初设计的作用就是为了能弄出一个进程,然后去帮自己干活,让自己去做其它的事,分别执行不同的代码那就要实现一个方法能区分父子进程,才能分配任务,可是如何区分,让使用者自己写方法吗,我敢说应该是可以实现的。设计者想那不如在fork函数内就写一个方法区分父子进程,父子进程对ret变量进行写时拷贝,也就让父子进程执行return ret的时候返回不同的值,使用者根据返回值就可以做区分了。所以说与其问为什么要有两个返回值,本质是问为什么要有返回值,就是为了能让使用者通过返回值区分父子进程,而且只要有返回值,就一定会被返回两次,所以为什么要有两个返回值的问题等价于为什么要有返回值。
既然父子进程接收的返回值不同,那为什么要给父进程返回子进程pid呢,这个可能是父进程可能会有多个子进程,为了今后可以让父进程能够区分子进程,这个pid是必需的,怎么用,还不知道....,给子进程的返回值就随意了,没什么可深究的,只要和父进程接收的返回值不同就可以了。这就能让父子进程去执行不同的代码,未来就可以实现分工合作,这就是为什么要返回两个不同的值的原因。最后我要说一个不太重要的点,就是bash是创建子进程去执行代码的,如果在子进程2中又创建了子进程3,此时会有三个进程,执行顺序一般是bash创建子进程2后挂起,等待子进程2执行完代码,而子进程2又创建了子进程3,这个时候2,3进程的顺序是由调度器决定的,如果2执行完了,这个时候bash和子进程3的执行顺序也是不确定的,所以下图偶尔会出现bash命令行的显示和子进程3的显示错乱。(下图为正常)