目录
前言:
哨兵位:
链表的概念
链表的相关操作:
链表的创建:
打印链表:
申请新节点:
链表的尾插:
!!!对于传参中二级指针的解释:
链表的头插:
链表的尾删:
链表的头删:
寻找结点:
在链表的指定位置前插入:
在链表的指定位置后插入:
删除pos位置的结点:
删除pos位置后的结点:
销毁链表:
最终结果:
SList.h文件:
SList.c文件:
test.c文件:
前言:
建议哈,等把其它内容看完后再来看前言......
链表一共有八种结构:
- 带头单向不循环/循环链表
- 带头双向不循环/循环链表
- 不带头单向不循环/循环链表
- 不带头双向不循环/循环链表

⽆头单向⾮循环链表:结构简单,⼀般不会单独⽤来存数据。更多是作为其他数据结构的⼦结构带头双向循环链表:结构最复杂,⼀般⽤在单独存储数据。实际中使⽤的链表数据结构就是它
后续使用二级指针pphead的原因:
请看下面关于尾插的调试:
//假设令plist指向第一个有效结点(在那之前先让它为空......)
SLNode* plist = NULL;
//尾插
SLPushBack(plist, 1);
SLPushBack(plist, 2);
//我们在后续使用时用的是这样的SLPushBack(&plist, 1);
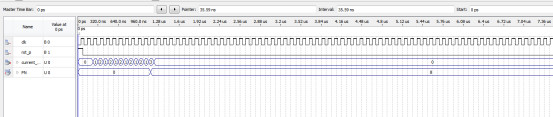
SLPrint(plist);未使用二级指针时进行第二次两次插入前plist的值情况:
我们发现此时plist的值为空?pphead为什么返回不回去呢
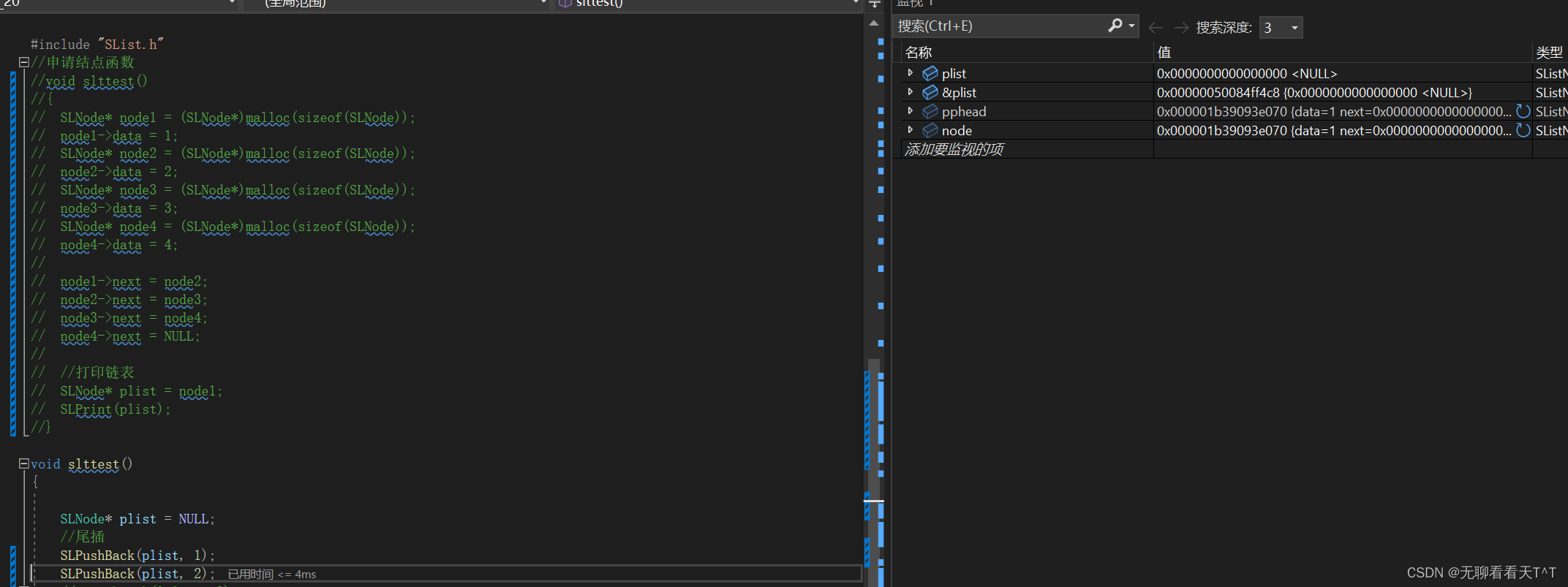
使用二级指针并完成更改后的结果:
再次插入时plist中的情况:
此时pphead两次插入时的值已经返回去了


结论: 感觉就是传值调用和传址调用的区别,第一种情况是传值调用pphead只是形参它是实参的一个拷贝对它的改变影响不了实参它所保留的值在出函数时就会被销毁(看图片你也可以发现它的地址与&plist的地址不一样),第二种情况时传址调用*pphead获得的是实参的地址:

这里你会发现二级指针pphead的地址就会与plist的地址一样了,对pphead的操作其实就是对plist的操作,这就是传址调用的妙处。
这是我在一个小时前想写的话:
我也是初学者对于这些内容也有点懵,描述的也不算清楚但是应该会有一定帮助
现在我想写的是:
ok搞定 (之前一直纠结哨兵位对是否使用二级指针的影响,现在看来好像没那个必要啊,到底使用了哨兵位后有啥好处我在这里考虑什么呢?)
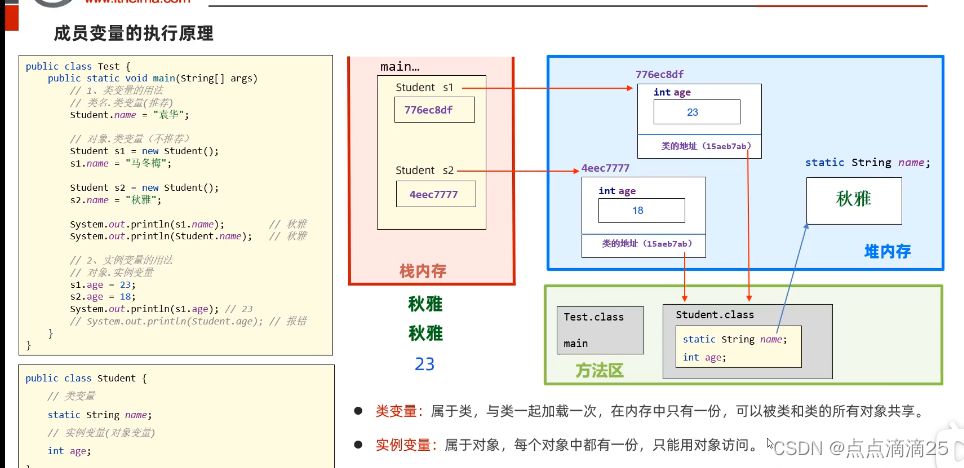
链表的具体概念
链表是线性表的一种,它就相当于一列火车:

结点 = 当前节点中保存的数据data + 保存下⼀个节点地址的指针变量next(单链表的情况)
不带头单向不循环链表的相关操作:
链表的创建:
!!需要补充的是:*pphead存储的值一直是链表的第一个有效结点的地址!!
!还有就是它是一个SLNode*类型的指针变量!
!!还有如果一个指针指向一个结点那么该指针中存放的就是该结点的地址!!
创建链表需要经历以下操作:
1、定义一个结构体来表示链表的结点(SList.h文件)
//定义一种链表节点的结构(实际应用中有多种,这里只演示最基本的结构)
typedef int SLDataType; //便于切换链表中存储数据的类型
struct SListNode {
SLDataType data; //存储数据
struct SListNode* next; //用来保存下一个节点地址的指针变量next
};
typedef struct SListNode SLNode; //将链表结点的结构体重命名为SLNode
//申请结点函数
void slttest()
{
SLNode* node1 = (SLNode*)malloc(sizeof(SLNode));
node1->data = 1;
SLNode* node2 = (SLNode*)malloc(sizeof(SLNode));
node2->data = 2;
SLNode* node3 = (SLNode*)malloc(sizeof(SLNode));
node3->data = 3;
SLNode* node4 = (SLNode*)malloc(sizeof(SLNode));
node4->data = 4;
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = NULL;
//打印链表
SLNode* plist = node1;
SLPrint(plist);
}
打印链表:
//用phead表示指向第一个有效结点的指针
void SLPrint(SLNode* phead)
{
//循环打印
//令pcur指针同样指向第一个有效结点的地址(把它当作phead的拷贝)
SLNode* pcur = phead;
//当pcur指向的地址不为空时继续循环
while (pcur)
{
//打印此时所指向结点中的数据
printf("%d ->", pcur->data);
//打印结束后让pcur指向下一个结点的地址
pcur = pcur->next;
}
//打印完成后,用NULL在小黑框中标识一下证明此时链表已经打印完了
printf("NULL\n");
}
申请新节点:
//申请有效结点,并在该结点中存储数据x
SLNode* SLByNode(SLDataType x)
{
//为有效结点申请一个新的空间,并用node指针存储该空间的地址(用node指向该空间)
SLNode* node = (SLNode*)malloc(sizeof(SLNode));
//该节点中存储的数据为x
node->data = x;
//将该结点的下一个结点置为空,因为我们也不知道它后面到底还要不要结点了
node->next = NULL;
//返回申请的有效结点地址(返回值为node,而node里面存储的就是有效结点所在内存空间的地址)
return node;
}链表的尾插:
//链表的尾插
void SLPushBack(SLNode** pphead, SLDataType x)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
SLNode* node = SLByNode(x);
//如果没有第一个有效结点(链表为空)那就让*pphead指向创建的有效结点的地址(让该结点作为链表的第一个有效结点)
if (*pphead == NULL)
{
*pphead = node;//(注意=的意思是赋值,而node的值就是有效结点的地址,把有效结点的地址传递给*ppead那么此时它里面存储的值就是有效结点的地址,此时它就相当于node了)
return;
}
//如果有第一个有效结点,则通过循环读取至链表的结尾
SLNode* pcur = *pphead;//(赋值原理同上)
//然后利用pcur->next遍历至链表的末尾
while (pcur->next)
{
pcur = pcur->next;//(赋值原理同上)
}
//当遍历至链表的末尾时,开始执行插入操作
pcur->next = node;//(赋值原理同上)
//还是解释一下:将有效结点的地址交给当前pcur指向结点中的next指针
}注意在理解这些操作时,一定要清楚的是”=“的作用就是赋值(感觉理解这点很重要)
链表的头插:
//链表的头插
void SLPushFront(SLNode** pphead, SLDataType x)//相当于两个互相赋值
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
SLNode* node = SLByNode(x);
//下面两条进行的其实就是简单的交接工作
//因为是头插,所以此时要将原来第一个有效结点的地址交给要头插新的有效结点的next指针
node->next = *pphead;
//然后将要插入的有效结点的地址交给*pphead(因为*pphead中存放的一定是第一个有效结点的地址,而这里我们将链表的第一个有效结点的地址变为了头插的新的有效结点的地址所以要将*pphead中存储的地址改变一下)
*pphead = node;
}链表的尾删:
//链表的尾删(链表为空的情况下不能尾删)
void SLPopBack(SLNode** pphead)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
//判断第一个有效结点是否存在(表为空不能进行尾删)
assert(*pphead);
//当有且只有一个有效结点时
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
//当不止一个有效结点时,找尾结点和尾结点的前一个结点
//这是为了防止尾删后它前一个结点的next指针变为野指针,我们要在删除尾结点后将该next指针置为空
//定义prev存放尾结点的前一个结点的地址(暂时将该指针的值置为空)
SLNode* prev = NULL;
//定义ptail为用于找尾结点的指针,先让它接收第一个有效结点的地址
SLNode* ptail = *pphead;
//当ptail->next的值为空时,证明上一次循环时ptail已经指向了尾结点
while (ptail->next != NULL)
{
//用prev将ptail最后一次循环前的值保存下来,不存储时就没法找到NULL前的一个结点(尾结点)
//此时prev保存的就是尾结点的前一个结点的地址
prev = ptail;
ptail = ptail->next;
}
//这里处理的就是野指针的情况,循环结束后ptail->text的值就为空了,将它赋值给尾结点上一个结点的next指针
prev->next = ptail->next;
//下面两步的操作的具体解释放在后面了......
free(ptail);
ptail = NULL;
}
}这是只有一个有效结点时尾删操作前*pphead的值 :

这是free(*pphead)后的结果:(这里地址不会变的哈只是这是两次调试的结果看data和next就行)

这是将*pphead置为空的结果:

我们可以发现free后只是将申请的内存空间释放掉了,但是*pphead中仍然保存了一个地址,那这个地址对应的内存空间已经被释放了,如果我们还要利用这个地址做一些事情,这时*pphead就是野指针了,所以此时就需要将*pphead置为空
其实对于free(*pphead)不懂的,你只需要知道它是一个SLNode*类型的指针变量就可以理解了
emm,其实看注释就够了下面的图中的文字部分可能会与注释内容有冲突,一切以注释为主,当然图中除了文字部分的内容还是可以多看一看的......

链表的头删:
//链表的头删
void SLPopPront(SLNode** pphead)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
//判断第一个有效结点是否存在(表为空不能进行尾删)
assert(*pphead);
//当有且只有一个有效结点时(具体的从这里开始便不再解释,不懂的请回去看尾删~)
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//令del指针存放第一个有效结点的地址
SLNode* del = *pphead;
//因为要环头了(第一个有效结点),此时第二个有效结点要作为第一个有效结点所以将原来第一个有效结点的next指针中存储的地址(也就是第二个有效结点的地址)交给*pphead
*pphead = (*pphead)->next;
//将del存储的原第一个有效结点的内存空间释放
free(del);
//虽然内存空间释放但是del仍然保存了一个地址如果不将del置为空那么它就是野指针
del = NULL;
}寻找结点:
//查找结点(前面的几个操作你懂了这里的代码应该就不用解释了吧)
SLNode* SLFind(SLNode** pphead, SLDataType x)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
SLNode* pcur = *pphead;
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
//该函数需要与在指定位置插入删除结合,返回的结果使用一个指针来接收,在test.c文件中的使用情况如下:
SLNode* find = SLFind(&plist,2);//查找数据为2的结点
SLInsert(&plist,find,x)//在find(数据为2)的结点前插入含有数据x的新节点在完成以下代码后需要考虑的三种情况:
1、pos是头结点
2、pos是中间结点
3、pos是最后一个结点
在链表的指定位置前插入:
//在指定位置之前插入数据
void SLInsert(SLNode** pphead, SLNode* pos, SLDataType x)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
//判断第一个有效结点是否存在(表为空不能进行尾删)
assert(*pphead);
//你得确定能找到你说的那个结点,你都找不到那你怎么在它之前插入结点啊哥们...
assert(pos);
SLNode* node = SLByNode(x);
//有且只有一个有效结点,此时在第一个有效结点前进行插入操作就相当于头插
if(pos == *pphead)
{
node->next = *pphead;
*pphead = node;
return;
}
//当不只有一个有效结点的时候,先通过循环找到指向pos前一个结点的地址(prev指向的结点)
SLNode* prev = *pphead;
//当prev->next指向pos的时候跳出循环
while (prev->next != pos)
{
prev = prev->next;
}
//此时prev指向pos位置前的一个结点(prev中存放的就是该结点的地址)
//最后,处理插入位置两边的结点与新结点三者之间的关系prve node pos
//此时下面的两个操作顺序可以交换
node->next = pos;
prev->next = node;
}
在链表的指定位置后插入:
//在指定位置之后插入数据(这里就不需要传一个二级指针了)
void SLInsertAfter(SLNode* pos, SLDataType x)
{
//你得确定能找到你说的那个结点,你找不到那你怎么在它之后插入结点啊
assert(pos);
SLNode* node = SLByNode(x);
//处理pos node pos->next三者之间的关系(看...看图......)
node->next = pos->next;
pos->next = pos;
}
//使用案例:
//SLNode* find = SLFind(&plist,1);
//SLInsertAfter(find,100);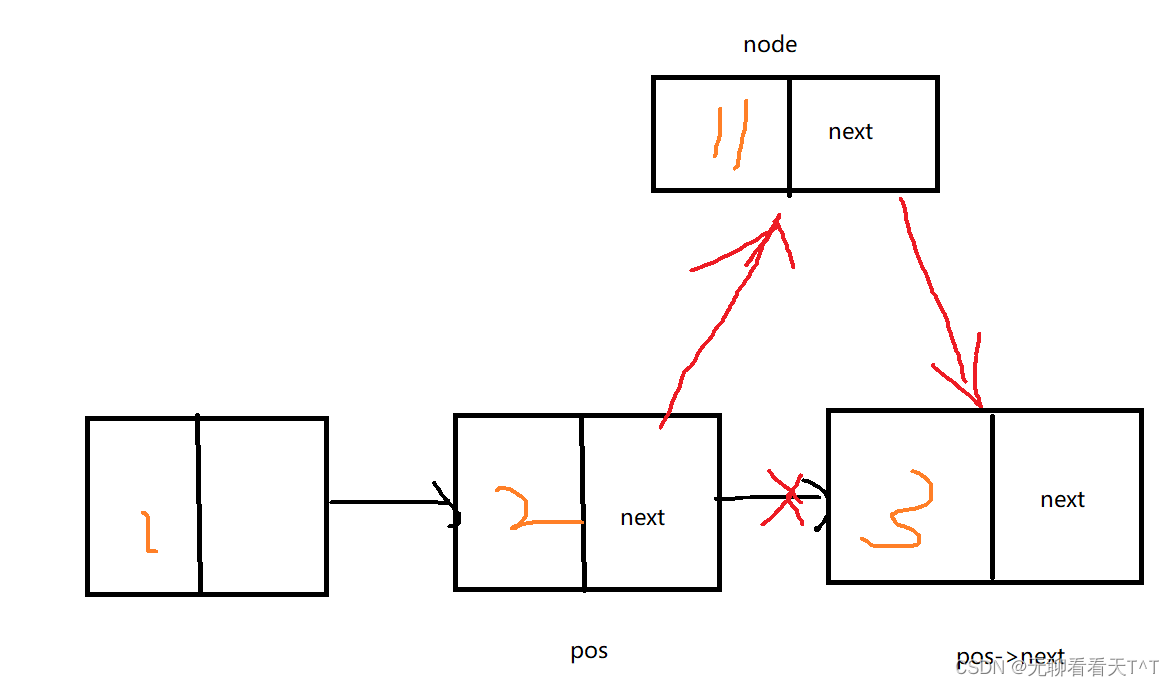
虽然看着跟前面在指定位置之前插入的图看起来差不多,但是在指定位置后插入省去了用循环寻找pos的上一个结点的步骤更好理解
删除pos位置的结点:
//删除pos结点
void SLErase(SLNode** pphead, SLNode* pos)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
//判断第一个有效结点是否存在(表为空不能进行尾删)
assert(*pphead);
//还是那句话:你得确定能找到你说的那个结点,你都找不到那你怎么在它之前插入结点啊哥们.....
assert(pos);
//当pos为第一个有效结点时
if (pos == *pphead)
{
//第一个有效结点要换人了,换人前先把遗嘱交代了哈(传地址)
*pphead = (*pphead)->next;
free(pos);
return;
}
//当pos不为第一个有效结点时
//先找到pos的前一个结点,然后(后续内容与之前的操作类似)
SLNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//先完成pos两边结点的交接工作,然后再释放pos结点
prev->next = pos->next;
free(pos);
pos = NULL;
}
删除pos位置后的结点:
//删除pos结点之后的数据
void SLEraseAfter(SLNode* pos)
{
//除了pos不为空以外,还需要pos->next不为空,因为pos刚好是最后一个结点你总不能删除一个NULL
assert(pos && pos->next);
SLNode* del = pos->next;
pos->next = del->next;
free(del);
del=NULL;
}

销毁链表:
//销毁链表
void SLDestroy(SLNode** pphead)
{
assert(pphead);
SLNode* pcur = *pphead;
//循环删除
while (pcur)
{
SLNode* next = pcur->next;
free(pcur);
pcur = next;
}
//此时链表所有的有效结点的内存空间已经释放了,*pphead再保存着已经释放的内存空间的地址是不是不太合适?(野指针)
*pphead = NULL;
}最终结果:
SList.h文件:
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
//定义链表节点的结构
typedef int SLDataType;
struct SListNode { //定义一个表示链表节点的结构体
SLDataType data; //链表中用于存储数据的成员(某个节点的数据)
struct SListNode* next; //用来保存下一个节点地址的指针变量next
};
typedef struct SListNode SLNode; //将指向下一个节点的指针类型重命名为SLNode
//创建几个结点组成的链表,并打印链表
void SLPrint(SLNode* phead);
//链表的尾插
void SLPushBack(SLNode** phead, SLDataType x);
//链表的头插
void SLPushFront(SLNode** phead, SLDataType x);
//链表的尾删
void SLPopBack(SLNode** pphead);
//链表的头删
void SLPopPront(SLNode** pphead);
//找结点
SLNode* SLFind(SLNode** pphead,SLDataType x);
//链表的在指定位置之前插入
void SLInsert(SLNode** phead, SLNode* pos,SLDataType x);
//链表的指定位置删除
void SLInsertAfter(SLNode* pos, SLDataType x);
//删除pos位置的结点
void SLErase(SLNode** pphead, SLNode* pos);
//删除pos后的结点
void SLEraseAfter(SLNode* pos);
//销毁链表
void SLDestroy(SLNode** pphead);SList.c文件:
#include "SList.h"
//用phead表示指向第一个有效结点的指针
void SLPrint(SLNode* phead)
{
//循环打印
//令pcur指针同样指向第一个有效结点的地址(把它当作phead的拷贝)
SLNode* pcur = phead;
//当pcur指向的地址不为空时继续循环
while (pcur)
{
//打印此时所指向结点中的数据
printf("%d ->", pcur->data);
//打印结束后让pcur指向下一个结点的地址
pcur = pcur->next;
}
//打印完成后,用NULL在小黑框中标识一下证明此时链表已经打印完了
printf("NULL\n");
}
//申请有效结点,并在该结点中存储数据x
SLNode* SLByNode(SLDataType x)
{
//为有效结点申请一个新的空间,并用node指针存储该空间的地址(用node指向该空间)
SLNode* node = (SLNode*)malloc(sizeof(SLNode));
//该节点中存储的数据为x
node->data = x;
//将该结点的下一个结点置为空,因为我们也不知道它后面到底还要不要结点了
node->next = NULL;
//返回申请的有效结点地址(返回值为node,而node里面存储的就是有效结点所在内存空间的地址)
return node;
}
//链表的尾插
void SLPushBack(SLNode** pphead, SLDataType x)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
SLNode* node = SLByNode(x);
//如果没有第一个有效结点(链表为空)那就让*pphead指向创建的有效结点的地址(让该结点作为链表的第一个有效结点)
if (*pphead == NULL)
{
*pphead = node;//(注意=的意思是赋值,而node的值就是有效结点的地址,把有效结点的地址传递给*ppead那么此时它里面存储的值就是有效结点的地址,此时它就相当于node了)
return;
}
//如果有第一个有效结点,则通过循环读取至链表的结尾
SLNode* pcur = *pphead;//(赋值原理同上)
//然后利用pcur->next遍历至链表的末尾
while (pcur->next)
{
pcur = pcur->next;//(赋值原理同上)
}
//当遍历至链表的末尾时,开始执行插入操作
pcur->next = node;//(赋值原理同上)
//还是解释一下:将有效结点的地址交给当前pcur指向结点中的next指针
}
//链表的头插
void SLPushFront(SLNode** pphead, SLDataType x)//相当于两个互相赋值
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
SLNode* node = SLByNode(x);
//下面两条进行的其实就是简单的交接工作
//因为是头插,所以此时要将原来第一个有效结点的地址交给要头插新的有效结点的next指针
node->next = *pphead;
//然后将要插入的有效结点的地址交给*pphead(因为*pphead中存放的一定是第一个有效结点的地址,而这里我们将链表的第一个有效结点的地址变为了头插的新的有效结点的地址所以要将*pphead中存储的地址改变一下)
*pphead = node;
}
//链表的尾删(链表为空的情况下不能尾删)
void SLPopBack(SLNode** pphead)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
//判断第一个有效结点是否存在(表为空不能进行尾删)
assert(*pphead);
//当有且只有一个有效结点时
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
//当不止一个有效结点时,找尾结点和尾结点的前一个结点
//这是为了防止尾删后它前一个结点的next指针变为野指针,我们要在删除尾结点后将该next指针置为空
//定义prev存放尾结点的前一个结点的地址(暂时将该指针的值置为空)
SLNode* prev = NULL;
//定义ptail为用于找尾结点的指针,先让它接收第一个有效结点的地址
SLNode* ptail = *pphead;
//当ptail->next的值为空时,证明上一次循环时ptail已经指向了尾结点
while (ptail->next != NULL)
{
//用prev将ptail最后一次循环前的值保存下来,不存储时就没法找到NULL前的一个结点(尾结点)
//此时prev保存的就是尾结点的前一个结点的地址
prev = ptail;
ptail = ptail->next;
}
//这里处理的就是野指针的情况,循环结束后ptail->text的值就为空了,将它赋值给尾结点上一个结点的next指针
prev->next = ptail->next;
//下面两步的操作的具体解释放在后面了......
free(ptail);
ptail = NULL;
}
}
//链表的头删
void SLPopPront(SLNode** pphead)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
//判断第一个有效结点是否存在(表为空不能进行尾删)
assert(*pphead);
//当有且只有一个有效结点时(具体的从这里开始便不再解释,不懂的请回去看尾删~)
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//令del指针存放第一个有效结点的地址
SLNode* del = *pphead;
//因为要环头了(第一个有效结点),此时第二个有效结点要作为第一个有效结点所以将原来第一个有效结点的next指针中存储的地址(也就是第二个有效结点的地址)交给*pphead
*pphead = (*pphead)->next;
//将del存储的原第一个有效结点的内存空间释放
free(del);
//虽然内存空间释放但是del仍然保存了一个地址如果不将del置为空那么它就是野指针
del = NULL;
}
//查找结点
SLNode* SLFind(SLNode** pphead, SLDataType x)
{
//判断传入的头结点plist是否为空
assert(pphead);
SLNode* pcur = *pphead;
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
//该函数需要与在指定位置插入删除结合,返回的结果使用一个指针来接收,在test.c文件中的使用情况如下:
//SLNode* find = SLFind(&plist, 2);//查找数据为2的结点
//SLInsert(&plist, find, x)//在find(数据为2)的结点前插入含有数据x的新节点
//在指定位置之前插入数据
void SLInsert(SLNode** pphead, SLNode* pos, SLDataType x)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
//判断第一个有效结点是否存在(表为空不能进行尾删)
assert(*pphead);
//你得确定能找到你说的那个结点,你都找不到那你怎么在它之前插入结点啊哥们...
assert(pos);
SLNode* node = SLByNode(x);
//有且只有一个有效结点,此时在第一个有效结点前进行插入操作就相当于头插
if(pos == *pphead)
{
node->next = *pphead;
*pphead = node;
return;
}
//当不只有一个有效结点的时候,先通过循环找到指向pos前一个结点的地址(prev指向的结点)
SLNode* prev = *pphead;
//当prev->next指向pos的时候跳出循环
while (prev->next != pos)
{
prev = prev->next;
}
//此时prev指向pos位置前的一个结点(prev中存放的就是该结点的地址)
//最后,处理插入位置两边的结点与新结点三者之间的关系prve node pos
//此时下面的两个操作顺序可以交换
node->next = pos;
prev->next = node;
}
//在指定位置之后插入数据(这里就不需要传一个二级指针了)
void SLInsertAfter(SLNode* pos, SLDataType x)
{
//你得确定能找到你说的那个结点,你找不到那你怎么在它之后插入结点啊
assert(pos);
SLNode* node = SLByNode(x);
//处理pos node pos->next三者之间的关系(看...看图......)
node->next = pos->next;
pos->next = pos;
}
//使用案例:
//SLNode* find = SLFind(&plist,1);
//SLInsertAfter(find,100);
//使用案例:
//SLNode* find = SLFind(&plist,1);
//SLInsertAfter(find,100);
//删除pos结点
void SLErase(SLNode** pphead, SLNode* pos)
{
//想要进行链表的插入和删除操作就必须使用一个二级指针pphead
assert(pphead);
//判断第一个有效结点是否存在(表为空不能进行尾删)
assert(*pphead);
//还是那句话:你得确定能找到你说的那个结点,你都找不到那你怎么在它之前插入结点啊哥们.....
assert(pos);
//当pos为第一个有效结点时
if (pos == *pphead)
{
//第一个有效结点要换人了,换人前先把遗嘱交代了哈(传地址)
*pphead = (*pphead)->next;
free(pos);
return;
}
//当pos不为第一个有效结点时
//先找到pos的前一个结点,然后(后续内容与之前的操作类似)
SLNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//先完成pos两边结点的交接工作,然后再释放pos结点
prev->next = pos->next;
free(pos);
pos = NULL;
}
//删除pos结点之后的数据
void SLEraseAfter(SLNode* pos)
{
//除了pos不为空以外,还需要pos->next不为空,因为pos刚好是最后一个结点你总不能删除一个NULL
assert(pos && pos->next);
SLNode* del = pos->next;
pos->next = del->next;
free(del);
del=NULL;
}
//销毁链表
void SLDestroy(SLNode** pphead)
{
assert(pphead);
SLNode* pcur = *pphead;
//循环删除
while (pcur)
{
SLNode* next = pcur->next;
free(pcur);
pcur = next;
}
//此时链表所有的有效结点的内存空间已经释放了,*pphead再保存着已经释放的内存空间的地址是不是不太合适?(野指针)
*pphead = NULL;
}test.c文件:
#include "SList.h"
//申请结点函数
//void slttest()
//{
// //使用malloc函数动态分配,创建链表的头节点,它不包含任何数据,知识用来指向链表的第一个实际节点
// SLNode* node1 = (SLNode*)malloc(sizeof(SLNode));
// //head
// node1->data = 1;
// SLNode* node2 = (SLNode*)malloc(sizeof(SLNode));
// node2->data = 2;
// SLNode* node3 = (SLNode*)malloc(sizeof(SLNode));
// node3->data = 3;
// SLNode* node4 = (SLNode*)malloc(sizeof(SLNode));
// node4->data = 4;
//
// //实现四个节点的链接
// //初始化头节点的next指针为node2指针变量
// node1->next = node2;
// node2->next = node3;
// node3->next = node4;
// node4->next = NULL;
//
// //打印链表
// SLNode* plist = node1; //定义一个SLNode*类型的指针变量plist,他也叫头指针,我们用它指向链表的头节点
//
// //注意头节点和头指针的概念是不同的:
// /*在链表的上下文中,通常将链表的第一个节点称为头节点(Head Node),但是头节点和头指针(Head Pointer)是不同的概念。
// 头节点是链表中的第一个实际节点,它包含数据和指向下一个节点的指针。头节点是链表的起始点,它可以存储实际的数据,也可以只是一个占位符节点,不存储实际的数据。
// 头指针是指向链表的头节点的指针。它是一个指针变量,存储着头节点的地址。通过头指针,我们可以访问链表中的每个节点,或者进行其他链表操作。
// 因此,头节点是链表中的一个节点,而头指针是指向头节点的指针。它们是不同的概念,但在某些情况下,人们可能会将它们混用或将它们视为相同的概念,因为头节点通常通过头指针来访问。*/
//
// SLNPrint(plist);
//}
void slttest()
{
SLNode* plist = NULL;
//尾插
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);//1->2->3->4->NULL
SLPrint(plist);
头插
//SLPushFront(&plist, 1);
//SLPushFront(&plist, 2);
//SLPushFront(&plist, 3);
//SLPushFront(&plist, 4);//4->3->2->1->NULL
//SLPrint(plist);
//尾删
SLPopBack(&plist);
SLPopBack(&plist);
SLPopBack(&plist);
头删
//SLPopPront(&plist);
//SLPopPront(&plist);
//SLPopPront(&plist);
//SLPopPront(&plist);
//SLPopPront(&plist);
//SLPopPront(&plist);
指定位置插入
//SLNode* find = SLFind(&plist, 4);
//SLInsert(&plist, find,11);//1->11->2->3->4->NULL
在指定位置之后插入数据
//SLInsertAfter(find, 100);
删除pos位置的节点
//SLErase(&plist, find);//1->2->3->NULL
删除pos之后的节点
//SLEraseAfter(find);
//
//销毁链表
//SLDestory(&plist);
//检验是否成功销毁
SLPrint(plist);
}
int main()
{
slttest();
return 0;
}
注意事项:
1、判断条件的等号都是==
2、冒号是否写了
3、函数或者指针变量的名字是否书写正确
4、最后的test.c文件实验时可能会存在一些多删之类的问题(函数写多了)请自行检查~
看完这个对指针的理解和使用又深了一层......
~over~
![解决使用WebTestClient访问接口报[185c31bb] 500 Server Error for HTTP GET “/**“](https://img-blog.csdnimg.cn/3dac1dcd794f4a03aafb03d6ef634b6a.png#pic_center)