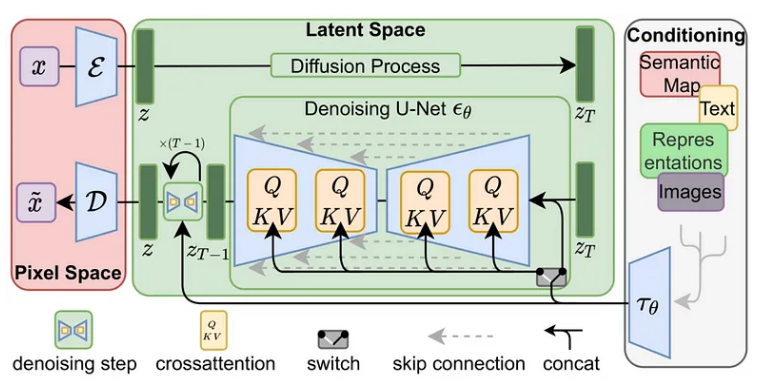
论文
Meta-analysis of the impacts of global change factors on soil microbial diversity and functionality
https://www.nature.com/articles/s41467-020-16881-7#Sec15
论文里提供了数据和代码,很好的学习素材
这篇论文是公众号的一位读者留言,说这篇论文提供了数据和代码,但是代码比较长,看起来比较吃力。我看了论文中提供的代码,大体上能够看懂,争取抽时间把论文中提供的代码都复现一下。因为论文中的图都对应着提供了作图数据,我们想复现论文中的图。关于用原始数据分析的部分后续有时间在单独介绍。
论文中提供的代码链接
https://static-content.springer.com/esm/art%3A10.1038%2Fs41467-020-16881-7/MediaObjects/41467_2020_16881_MOESM8_ESM.txt
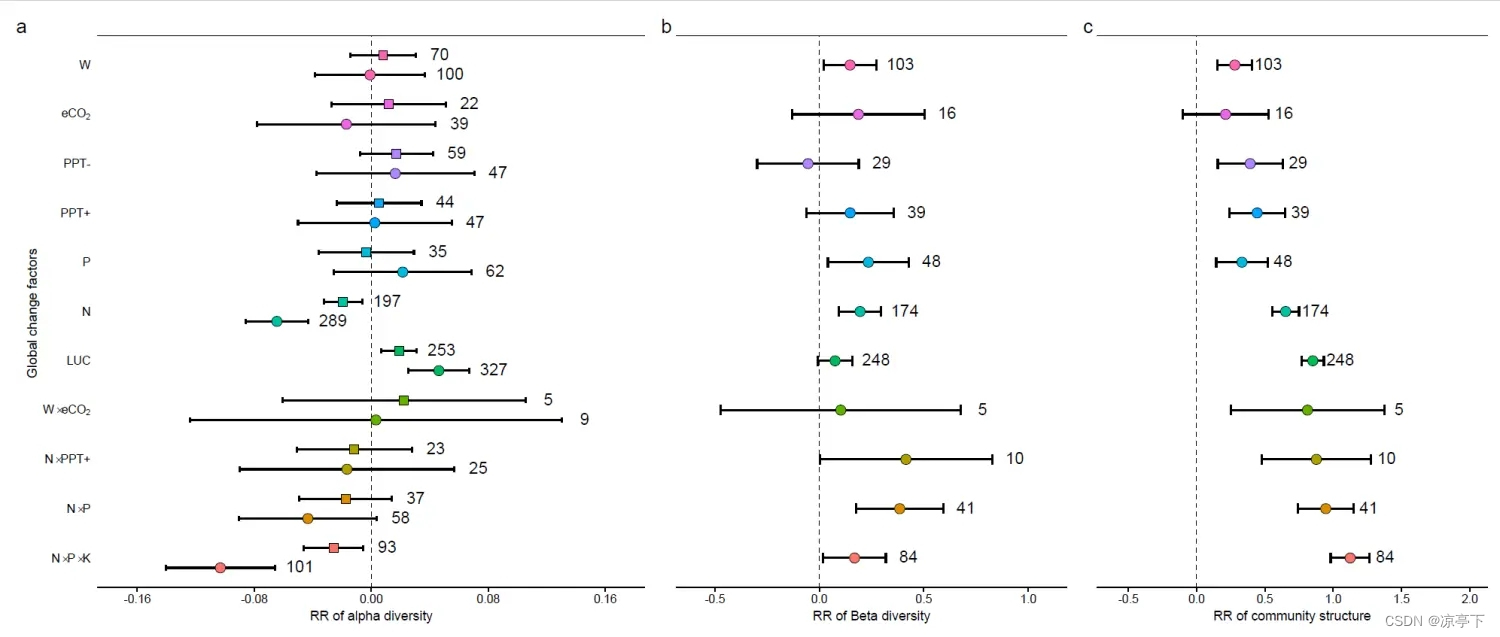
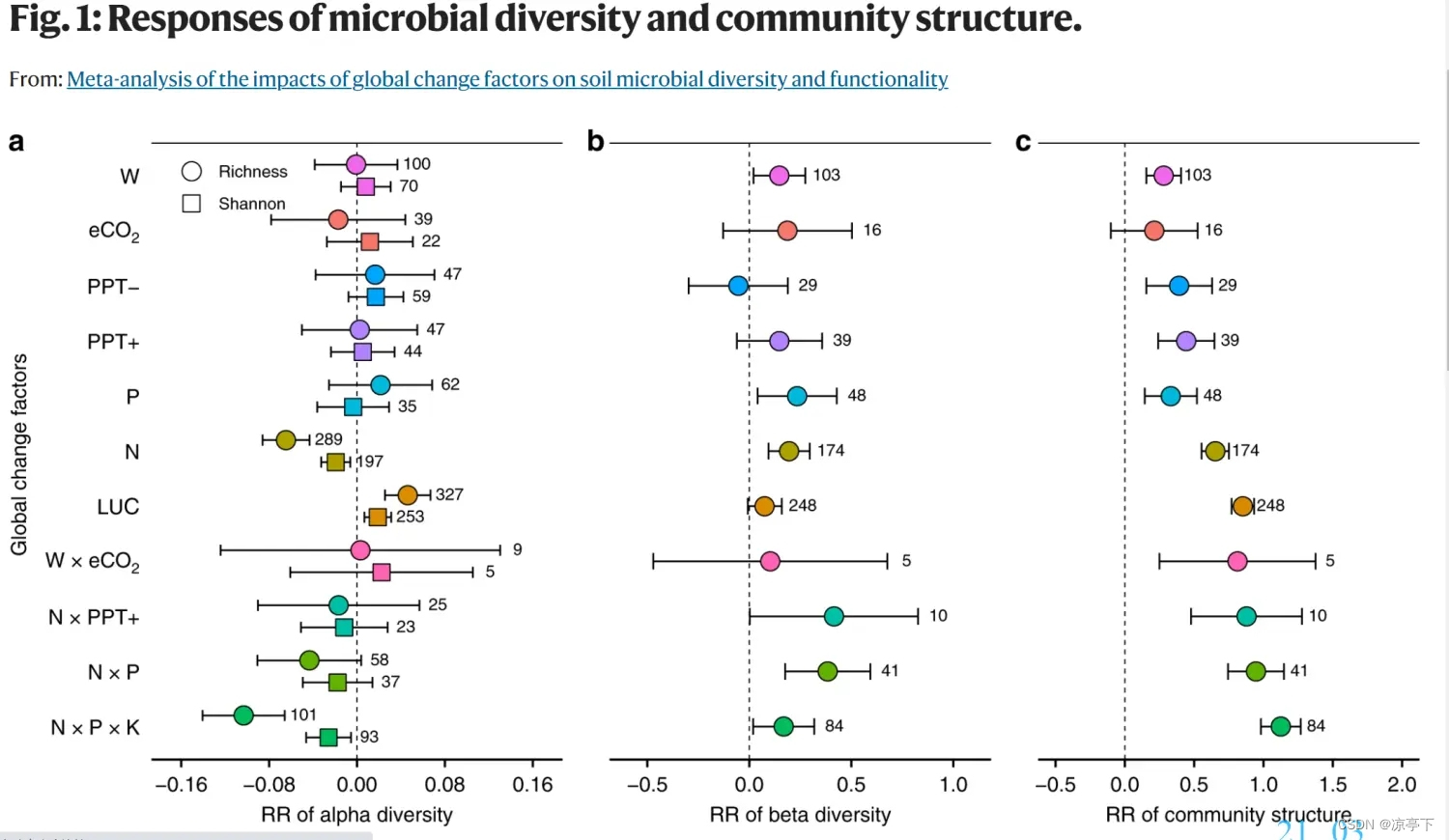
今天的推文我们复现论文中的figure1
论文中提供的作图数据如下,excel存储
加载需要用到的R包
library(readxl)
library(tidyverse)
library(latex2exp)
library(ggplot2)
读取数据
metaresult<-read_excel("data/20221129/41467_2020_16881_MOESM9_ESM.xlsx",
sheet = 'Fig1')
colnames(metaresult)
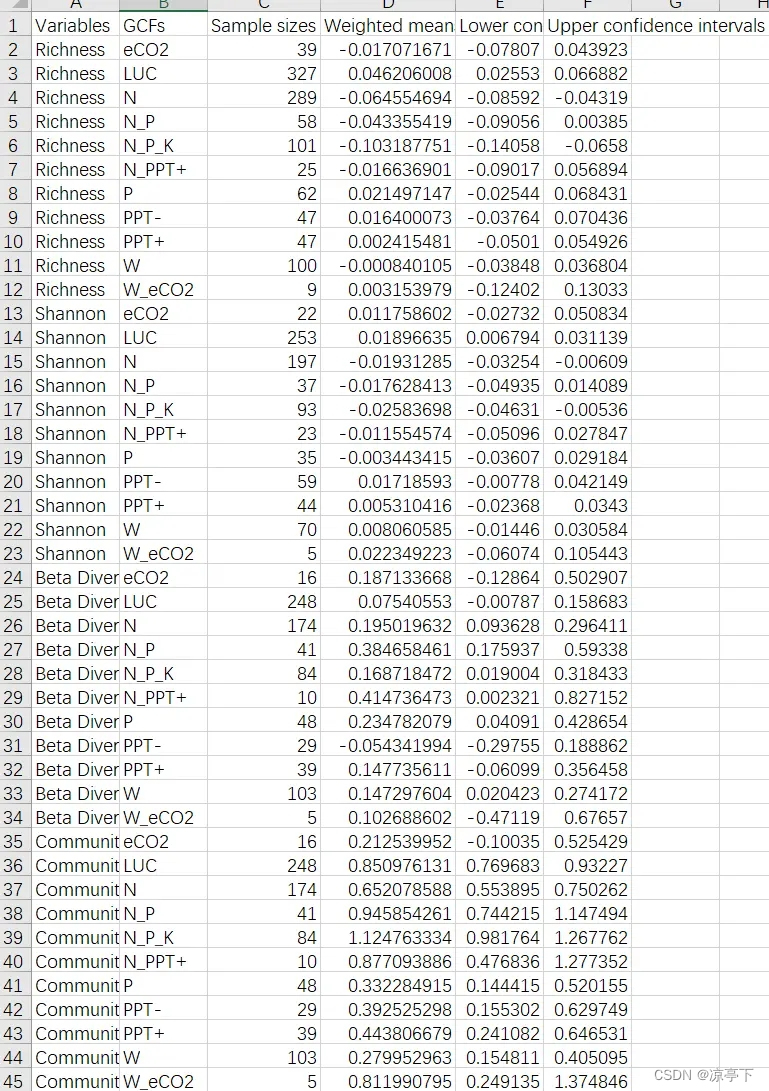
首先是第一个小图a
论文中的代码是用RR作为Y轴,GCFs作为X轴,然后再通过coord_flip()函数整体旋转;论文中关于字体上小标是用expression函数实现的,这里我们使用latex2exp这个R包
代码我们参考论文中的代码,但是不完全按照他的写
数据整理和作图代码
data1<-metaresult %>%
filter(Variables=="Richness"|Variables=="Shannon")
data1$GCFs
data1<-data1 %>%
mutate(GCFs=factor(GCFs,
levels = c("N_P_K","N_P","N_PPT+",
"W_eCO2","LUC","N","P",
"PPT+","PPT-","eCO2","W"))
)
data1 %>% colnames()
ggplot(data = data1,
aes(x=`Weighted means of RR`,
y=`GCFs`,
shape=Variables))+
geom_vline(xintercept=0,linetype = "dashed",size=0.2)+
geom_errorbarh(aes(xmin=`Lower confidence intervals`,
xmax=`Upper confidence intervals`),
position=position_dodge(0.8),
height=0.2)+
geom_point(position=position_dodge(0.8),
size=3, stroke = 0.3,
aes(fill=GCFs),
show.legend = FALSE)+
geom_text(aes(y =`GCFs` , x = `Upper confidence intervals`+0.015,
label = `Sample sizes`),
position = position_dodge(width = 0.8),
vjust = 0.4, hjust=0.4, size = 4,
check_overlap = FALSE)+
geom_segment(y = 11.6, x = -Inf,
yend = 11.6, xend = Inf,
colour = "black",size=0.4)+
scale_shape_manual(values=c("Richness"=21,"Shannon"=22))+
scale_x_continuous(limits=c(-0.17,0.17),
breaks = c(-0.16,-0.08,0,0.08,0.16))+
scale_y_discrete(breaks=c("N_P_K","N_P","N_PPT+",
"W_eCO2","LUC","N","P",
"PPT+","PPT-","eCO2","W"),
labels=c(TeX(r"($N \times P \times K$)"),
TeX(r"($N \times P$)"),
TeX(r"($N \times PPT$+)"),
TeX(r"($W \times eCO_2$)"),
"LUC","N","P","PPT+","PPT-",
TeX(r"($eCO_2$)"),
"W"))+
labs(x = "Global change factors ", y = "RR of alpha diversity",colour = 'black')+
theme(legend.title = element_blank(),
legend.position=c(0.2,0.94),
legend.key = element_rect(fill = "white",size = 2),
legend.key.width = unit(0.5,"lines"),
legend.key.height= unit(0.8,"lines"),
legend.background = element_blank(),
legend.text=element_text(size=6),
panel.background = element_rect(fill = 'white', colour = 'white'),
axis.title=element_text(size=9),
axis.text.y = element_text(colour = 'black', size = 8),
axis.text.x = element_text(colour = 'black', size = 8),
axis.line = element_line(colour = 'black',size=0.4),
axis.line.y = element_blank(),
axis.ticks = element_line(colour = 'black',size=0.4),
axis.ticks.y = element_blank())
输出结果
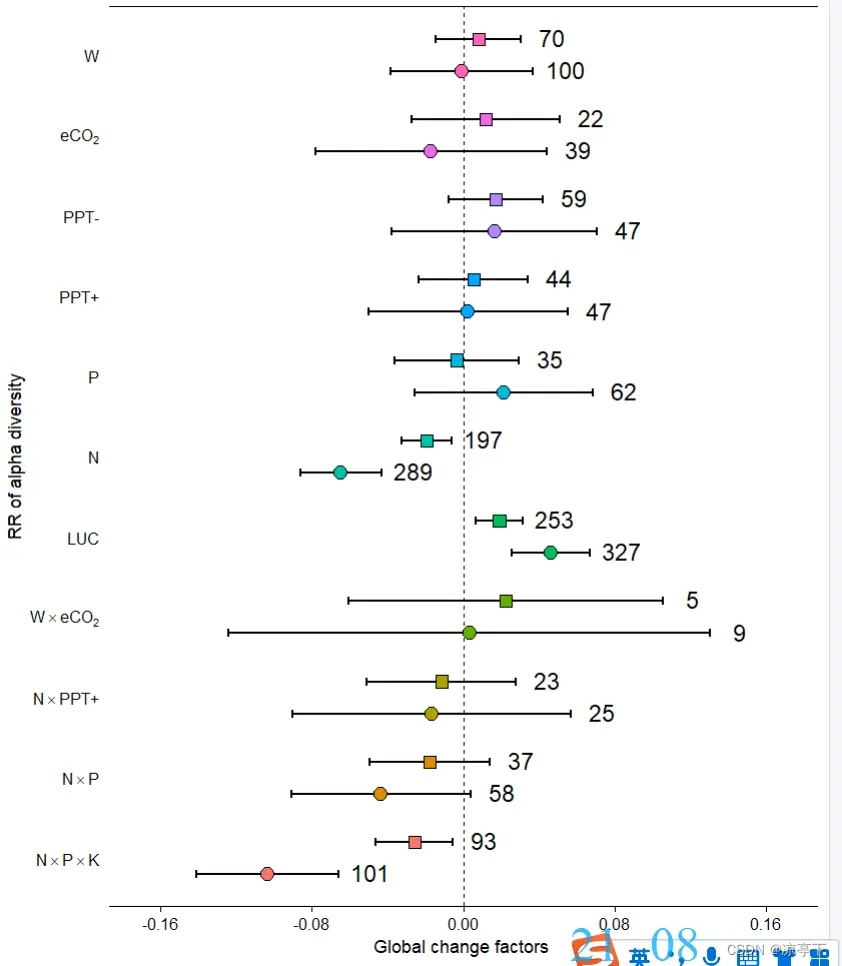
小图b
data2<-metaresult %>%
filter(Variables=="Beta Diversity")
data2$GCFs
data2<-data2 %>%
mutate(GCFs=factor(GCFs,
levels = c("N_P_K","N_P","N_PPT+",
"W_eCO2","LUC","N","P",
"PPT+","PPT-","eCO2","W"))
)
data2 %>% colnames()
ggplot(data = data2,
aes(x=`Weighted means of RR`,
y=`GCFs`))+
geom_vline(xintercept=0,linetype = "dashed",size=0.2)+
geom_errorbarh(aes(xmin=`Lower confidence intervals`,
xmax=`Upper confidence intervals`),
height=0.2)+
geom_point(size=3, stroke = 0.3,
shape=21,
aes(fill=GCFs),
show.legend = FALSE)+
geom_text(aes(y =`GCFs` , x = `Upper confidence intervals`+0.1,
label = `Sample sizes`),
#position = position_dodge(width = 0.8),
vjust = 0.4, hjust=0.4, size = 4,
check_overlap = FALSE)+
geom_segment(y = 11.6, x = -Inf,
yend = 11.6, xend = Inf,
colour = "black",size=0.4)+
scale_x_continuous(limits=c(-0.6,1.1),breaks = c(-0.5,0,0.5,1))+
scale_y_discrete(breaks=c("N_P_K","N_P","N_PPT+",
"W_eCO2","LUC","N","P",
"PPT+","PPT-","eCO2","W"),
labels=c(TeX(r"($N \times P \times K$)"),
TeX(r"($N \times P$)"),
TeX(r"($N \times PPT$+)"),
TeX(r"($W \times eCO_2$)"),
"LUC","N","P","PPT+","PPT-",
TeX(r"($eCO_2$)"),
"W"))+
labs(y = "Global change factors ",
x = "RR of alpha diversity",
colour = 'black')+
theme(legend.title = element_blank(),
legend.position=c(0.2,0.9),
legend.key = element_rect(fill = "white",size = 2),
legend.key.width = unit(0.5,"lines"),
legend.key.height= unit(0.8,"lines"),
legend.background = element_blank(),
legend.text=element_text(size=6),
panel.background = element_rect(fill = 'white', colour = 'white'),
axis.title=element_text(size=9),
axis.text.y = element_text(colour = 'black', size = 8),
axis.text.x = element_text(colour = 'black', size = 8),
axis.line = element_line(colour = 'black',size=0.4),
axis.line.y = element_blank(),
axis.ticks = element_line(colour = 'black',size=0.4),
axis.ticks.y = element_blank())
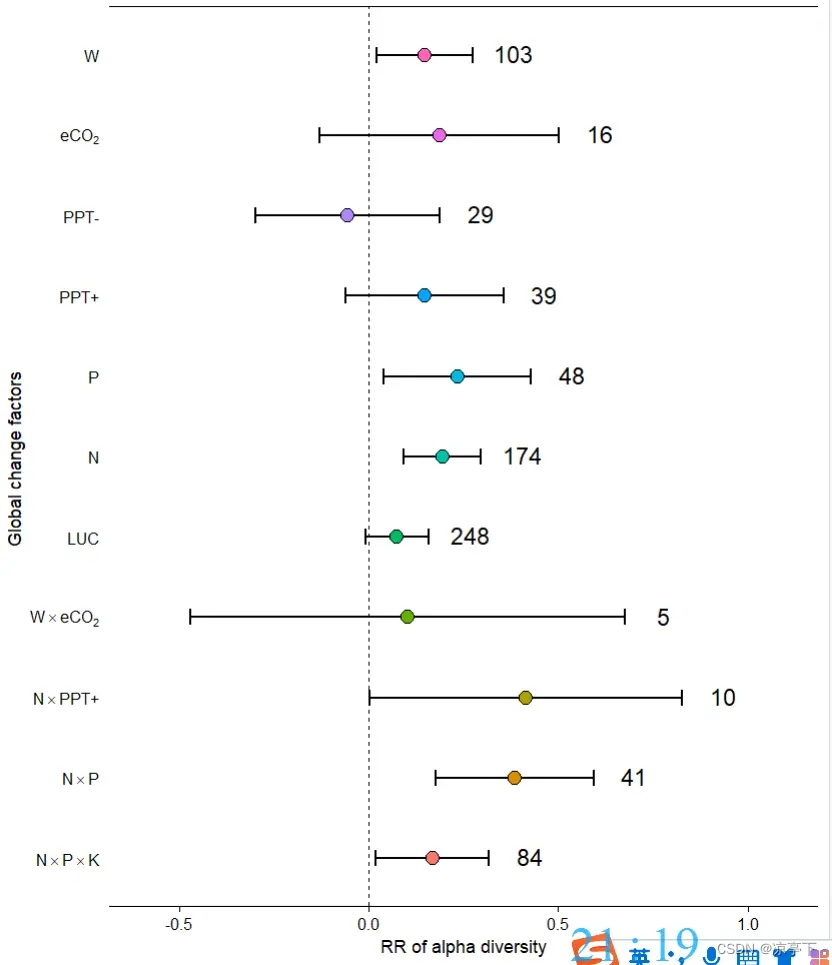
小图c
data3<-metaresult %>%
filter(Variables=="Community structure")
data3$GCFs
data3<-data3 %>%
mutate(GCFs=factor(GCFs,
levels = c("N_P_K","N_P","N_PPT+",
"W_eCO2","LUC","N","P",
"PPT+","PPT-","eCO2","W"))
)
data3 %>% colnames()
ggplot(data = data3,
aes(x=`Weighted means of RR`,
y=`GCFs`))+
geom_vline(xintercept=0,linetype = "dashed",size=0.2)+
geom_errorbarh(aes(xmin=`Lower confidence intervals`,
xmax=`Upper confidence intervals`),
height=0.2)+
geom_point(size=3, stroke = 0.3,
shape=21,
aes(fill=GCFs),
show.legend = FALSE)+
geom_text(aes(y =`GCFs` , x = `Upper confidence intervals`+0.1,
label = `Sample sizes`),
#position = position_dodge(width = 0.8),
vjust = 0.4, hjust=0.4, size = 4,
check_overlap = FALSE)+
geom_segment(y = 11.6, x = -Inf,
yend = 11.6, xend = Inf,
colour = "black",size=0.4)+
scale_x_continuous(limits=c(-0.6,2.0),breaks = c(-0.5,0,0.5,1,1.5,2.0))+
scale_y_discrete(breaks=c("N_P_K","N_P","N_PPT+",
"W_eCO2","LUC","N","P",
"PPT+","PPT-","eCO2","W"),
labels=c(TeX(r"($N \times P \times K$)"),
TeX(r"($N \times P$)"),
TeX(r"($N \times PPT$+)"),
TeX(r"($W \times eCO_2$)"),
"LUC","N","P","PPT+","PPT-",
TeX(r"($eCO_2$)"),
"W"))+
labs(y = "Global change factors ",
x = "RR of community structure",
colour = 'black')+
theme(legend.title = element_blank(),
legend.position=c(0.2,0.9),
legend.key = element_rect(fill = "white",size = 2),
legend.key.width = unit(0.5,"lines"),
legend.key.height= unit(0.8,"lines"),
legend.background = element_blank(),
legend.text=element_text(size=6),
panel.background = element_rect(fill = 'white', colour = 'white'),
axis.title=element_text(size=9),
axis.text.y = element_text(colour = 'black', size = 8),
axis.text.x = element_text(colour = 'black', size = 8),
axis.line = element_line(colour = 'black',size=0.4),
axis.line.y = element_blank(),
axis.ticks = element_line(colour = 'black',size=0.4),
axis.ticks.y = element_blank())
图b和图c是一样的
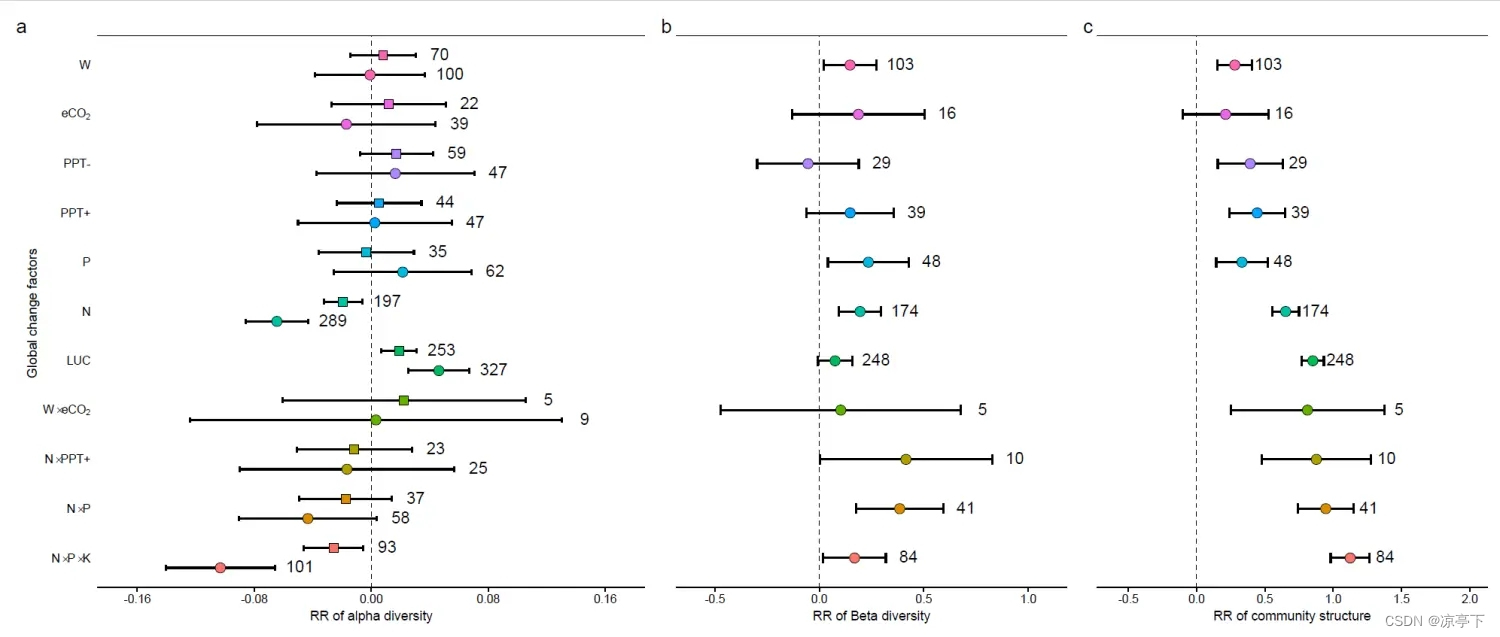
最后是拼图
论文中提供的拼图代码是用ggpubr这个R包做的
ggpubr::ggarrange(p1, p2, p3,
widths = c(7, 5, 5),
ncol = 3, nrow = 1,
labels = c("a", "b", "c"),
font.label=list(size=12),
hjust = 0, vjust = 1)
我自己更习惯使用patchwork这个R包
library(patchwork)
p1+
p2+theme(axis.text.y = element_blank(),
axis.title.y = element_blank())+
p3+theme(axis.text.y = element_blank(),
axis.title.y = element_blank())+
plot_annotation(tag_levels = "a")+
plot_layout(widths = c(7, 5, 5))
最终结果
示例数据和代码可以自己到论文中下载,如果需要我推文中的代码和数据可以给公众号推文点赞,点击在看,最后留言获取
查rma()函数找到了这个链接
http://www.simonqueenborough.info/R/specialist/meta-analysis#:~:text=The%20function%20rma()%20(random,compute%20effect%20sizes%20before%20modelling.&text=Random%20effect%20model%20can%20be,%2D%2D%2DFixed%20effect%20model%20cannot.
http://www.simonqueenborough.info/R/intro/index.html