salmon 帮助文档
https://salmon.readthedocs.io/en/latest/building.html#installation
github主页
https://github.com/COMBINE-lab/salmon
我最开始是直接使用conda安装的 v1.4
首先第一步是对参考转录组进行索引,命令
salmon index -t pome.fa -i transcripts_index_1 -p 16
这一步不知道为啥总是卡住
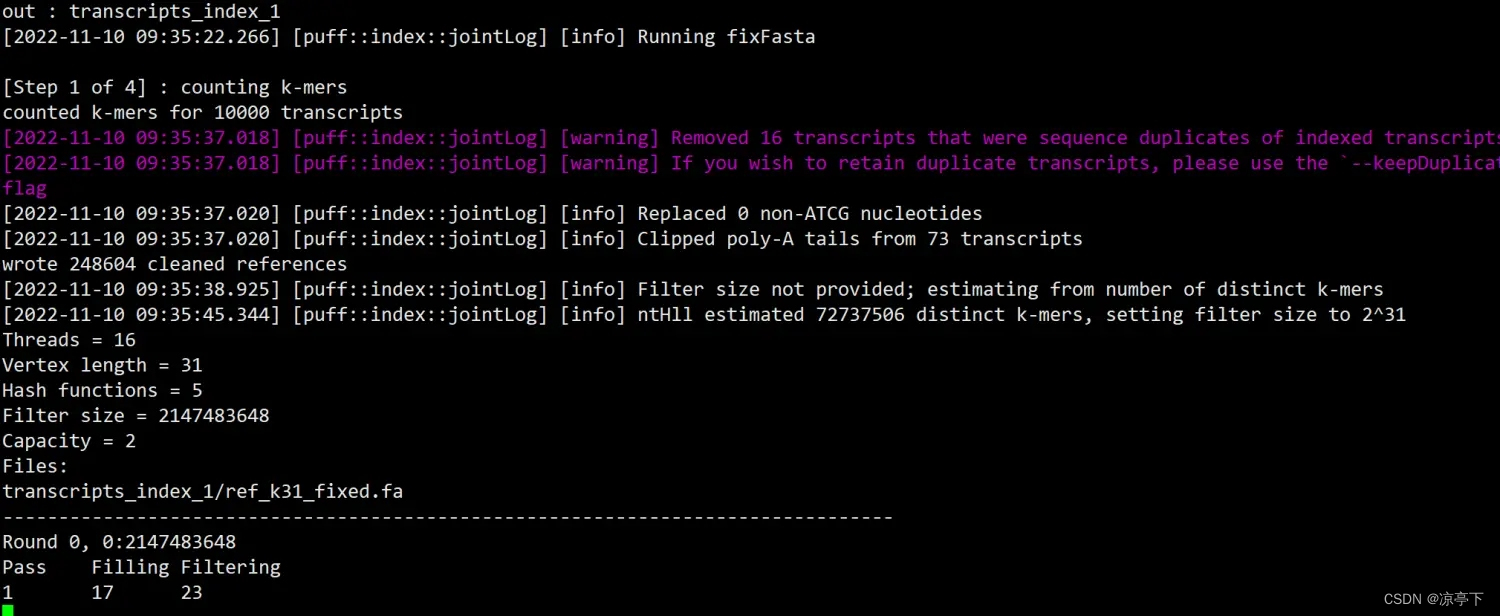 到这里就进行不下去了
到这里就进行不下去了
然后我在github上直接下载了编译好的v1.9
./salmon/bin/salmon index -t pome.fa -i transcripts_index_2
同样的会卡到这一步
但是用v1.0指定核心数却可以运行完
试了一次能够运行,试第二次的时候又卡住了 不知道为啥
这个和salmon是哪个版本关系应该不到,而且有时候可以成功,有时候就会卡住,但是卡住的时候多
已解决
请教了课题组的师兄,应该是文件存贮的原因,我用到的是计算机集群,涉及到的文件存储知识我也搞不太明白,我的大体理解是:计算集群存储的系统是两套,当启用一个计算节点的时候,这个计算节点有一个临时的文件存储系统,节点关闭自动会删除这个临时的文件存储系统,每次节点启动这个临时的存储系统路径都不一样,可以使用命令$TMPDIR来获取存储路径 参考这个链接 https://help.cropdiversity.ac.uk/data-storage.html。计算集群还有一个单独的文件存储系统,这个系统是永久的。默认的输出文件是在计算集群的单独的数据文件存储。使用salmon这个软件需要将输出文件指定到节点的临时文件存储中,运行完再将输出结果复制到计算集群的文件存储系统中
(这个理解不知道是否正确)
我运行如下命令
salmon index -t pome01.fa -i /tmp/myan_3797261/transcripts_index_05 --threads 4
就能够顺利运行,然后将结果复制到集群的存储系统中
cp -R $TMPDIR/transcripts_index_05/ ./
量化的步骤使用集群的文件存储还是节点的临时存储都是可以的