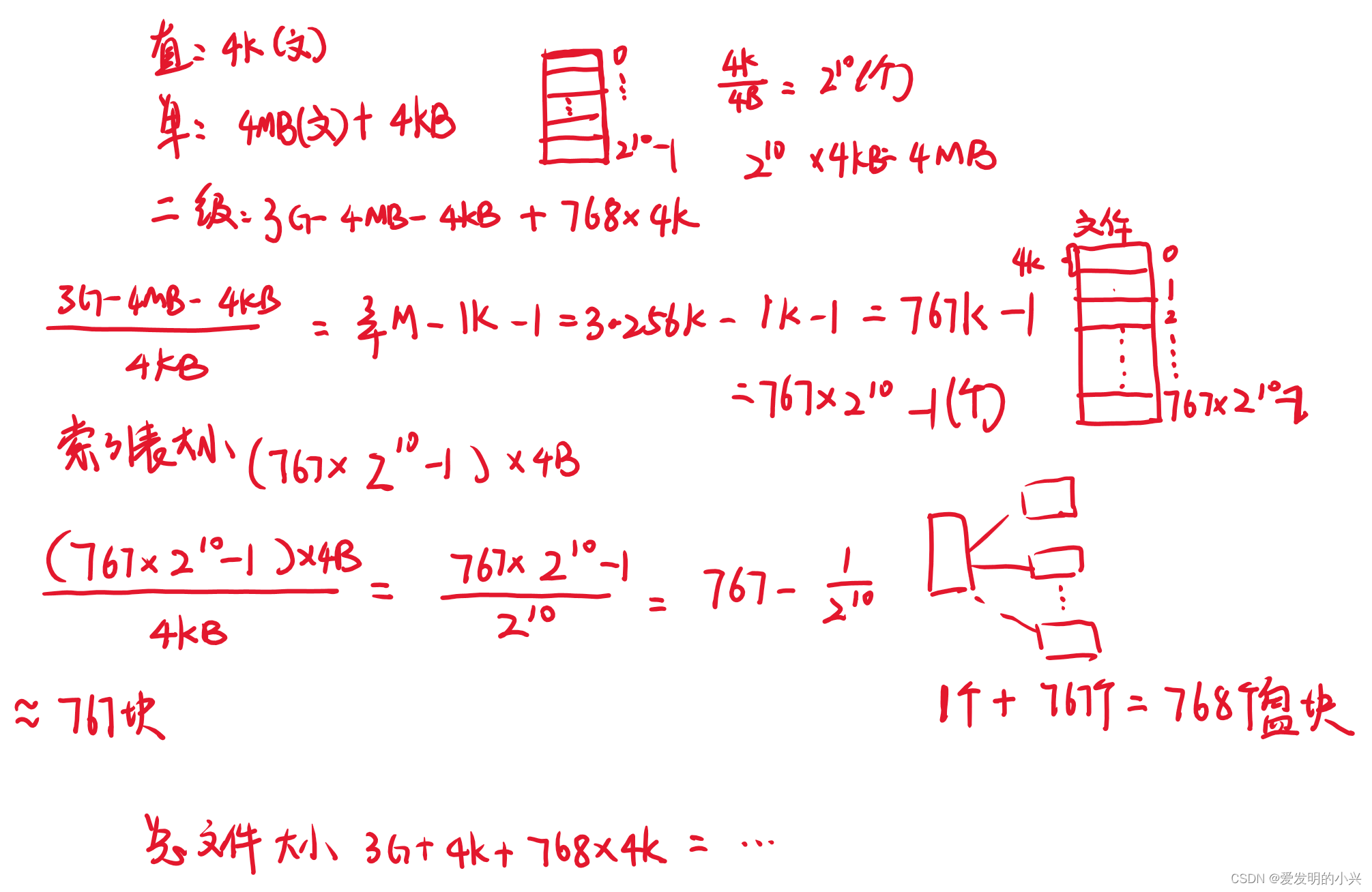1 Encoder模块
1.1 Encoder模块的结构和作用
- 经典的Transformer结构中的Encoder模块包含6个Encoder Block.
- 每个Encoder Block包含一个多头自注意力层,和一个前馈全连接层.
1.2 Encoder Block
- 在Transformer架构中,6个一模一样的Encoder Block层层堆叠在一起,共同组成完整的Encoder,因此剖析一个Block就可以对整个Encoder的内部结构有清晰的认识.
1.3 多头自注意力层(self-attention)
首先来看self-attention的计算规则图
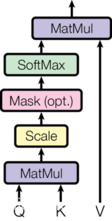
- 上述attention可以被描述为将query和key-value键值对的一组集合映射到输出,输出被计算为values的加权和,其中分配给每个value的权重由query与对应key的相似性函数计算得来。这种attention的形式被称为Scaled Dot-Product Attention,对应的数学公式形式如下:
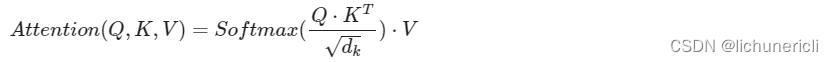
- 所谓的多头self-attention层,则是先将Q,K,V经过参数矩阵进行映射,再做self-attention,最后将结果拼接起来送入一个全连接层即可。
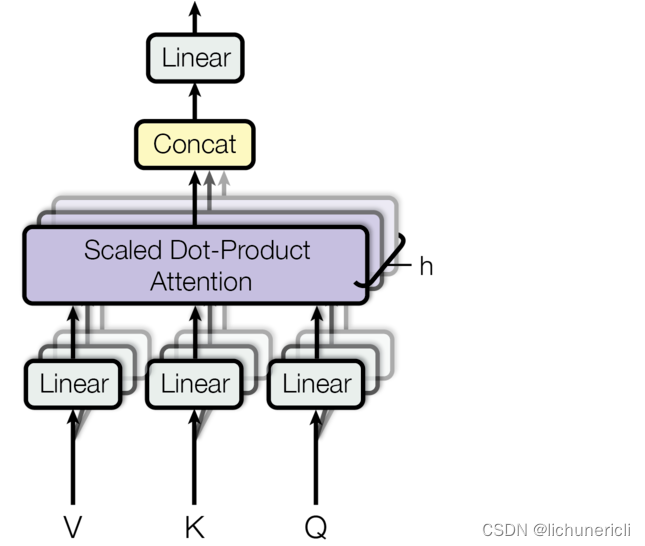
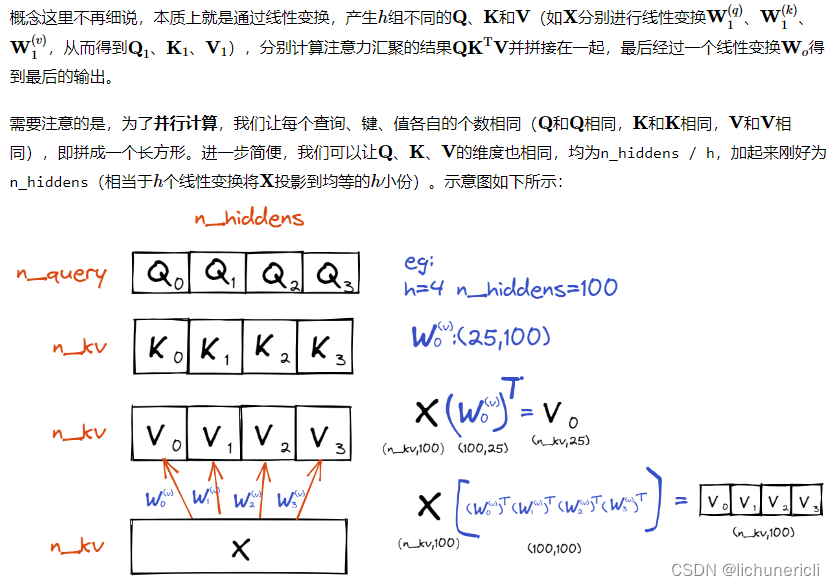
-
前馈全连接层模块
- 前馈全连接层模块, 由两个线性变换组成, 中间有一个Relu激活函数, 对应的数学公式形式如下:

- 前馈全连接层模块, 由两个线性变换组成, 中间有一个Relu激活函数, 对应的数学公式形式如下:
注意: 原版论文中的前馈全连接层,输入和输出的维度均为d_model = 512,层内的连接维度d_ff = 2048,均采用4倍的大小关系。
前馈全连接层的作用:单纯的多头注意力机制并不足以提取到理想的特征,因此增加全连接层来提升网络的能力。
1.4 Decoder模块
- Decoder模块的结构和作用:
- 经典的Transformer结构中的Decoder模块包含6个Decoder Block.
- 每个Decoder Block包含三个子层.
- 一个多头self-attention层
- 一个Encoder-Decoder attention层
- 一个前馈全连接层
- Decoder Block中的多头self-attention层
- Decoder中的多头self-attention层与Encoder模块一致, 但需要注意的是Decoder模块的多头self-attention需要做look-ahead-mask, 因为在预测的时候"不能看见未来的信息", 所以要将当前的token和之后的token全部mask.
- Decoder Block中的Encoder-Decoder attention层
- 这一层区别于自注意力机制的Q = K = V, 此处矩阵Q来源于Decoder端经过上一个Decoder Block的输出, 而矩阵K, V则来源于Encoder端的输出, 造成了Q != K = V的情况.
- 这样设计是为了让Decoder端的token能够给予Encoder端对应的token更多的关注.
- Decoder Block中的前馈全连接层
- 此处的前馈全连接层和Encoder模块中的完全一样.
- Decoder Block中有2个注意力层的作用
- 多头self-attention层是为了拟合Decoder端自身的信息
- Encoder-Decoder attention层是为了整合Encoder和Decoder的信息
1.5 Add & Norm模块
- Add & Norm模块接在每一个Encoder Block和Decoder Block中的每一个子层的后面. 具体来说Add表示残差连接, Norm表示LayerNorm.
- 对于每一个Encoder Block, 里面的两个子层后面都有Add & Norm.
- 对于每一个Decoder Block, 里面的三个子层后面都有Add & Norm.
- 具体的数学表达形式为: LayerNorm(x + Sublayer(x)), 其中Sublayer(x)为子层的输出.
- Add残差连接的作用: 和其他神经网络模型中的残差连接作用一致, 都是为了将信息传递的更深, 增强模型的拟合能力. 试验表明残差连接的确增强了模型的表现.
- Norm的作用: 随着网络层数的额增加, 通过多层的计算后参数可能会出现过大, 过小, 方差变大等现象, 这会导致学习过程出现异常, 模型的收敛非常慢. 因此对每一层计算后的数值进行规范化可以提升模型的表现.
1.6 位置编码器Positional Encoding
-
Transformer中直接采用正弦函数和余弦函数来编码位置信息, 如下图所示:
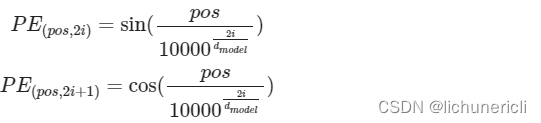
-
需要注意: 三角函数应用在此处的一个重要的优点, 因为对于任意的PE(pos+k), 都可以表示为PE(pos)的线性函数, 大大方便计算. 而且周期性函数不受序列长度的限制, 也可以增强模型的泛化能力.
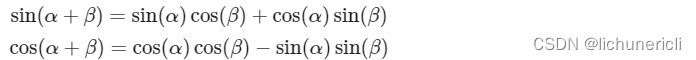
2 小结
-
Encoder模块
- 经典的Transformer架构中的Encoder模块包含6个Encoder Block.
- 每个Encoder Block包含两个子模块, 分别是多头自注意力层, 和前馈全连接层.
- 多头自注意力层采用的是一种Scaled Dot-Product Attention的计算方式, 实验结果表明, Mul ti-head可以在更细致的层面上提取不同head的特征, 比单一head提取特征的效果更佳.
- 前馈全连接层是由两个全连接层组成, 线性变换中间增添一个Relu激活函数, 具体的维度采用4倍关系, 即多头自注意力的d_model=512, 则层内的变换维度d_ff=2048.
-
Decoder模块
- 经典的Transformer架构中的Decoder模块包含6个Decoder Block.
- 每个Decoder Block包含3个子模块, 分别是多头自注意力层, Encoder-Decoder Attention层, 和前馈全连接层.
- 多头自注意力层采用和Encoder模块一样的Scaled Dot-Product Attention的计算方式, 最大的 区别在于需要添加look-ahead-mask, 即遮掩"未来的信息".
- Encoder-Decoder Attention层和上一层多头自注意力层最主要的区别在于Q != K = V, 矩阵Q来源于上一层Decoder Block的输出, 同时K, V来源于Encoder端的输出.
- 前馈全连接层和Encoder中完全一样.
-
Add & Norm模块
- Add & Norm模块接在每一个Encoder Block和Decoder Block中的每一个子层的后面.
- 对于每一个Encoder Block, 里面的两个子层后面都有Add & Norm.
- 对于每一个Decoder Block, 里面的三个子层后面都有Add & Norm.
- Add表示残差连接, 作用是为了将信息无损耗的传递的更深, 来增强模型的拟合能力.
- Norm表示LayerNorm, 层级别的数值标准化操作, 作用是防止参数过大过小导致的学习过程异常, 模型收敛特别慢的问题.
-
位置编码器Positional Encoding
- Transformer中采用三角函数来计算位置编码.
- 因为三角函数是周期性函数, 不受序列长度的限制, 而且这种计算方式可以对序列中不同位置的编码的重要程度同等看待.