1.我们的哨兵模式中,当主节点挂掉以后,此时哨兵会重新进行选举,选举出新的主节点去对外提供写服务
在选举的过程中,他redis整个集群是不提供写服务的 (因为此时我们哨兵对外提供写服务的只有Master)
2.我们单节点的redis的内存不能过大,可能8G,10G 如果过大的话,他持久化的以及数据同步的时候就会有压力
所以这个就是哨兵的弊端,基于哨兵的弊端 我们有了cluster模式
他的数据是分片的
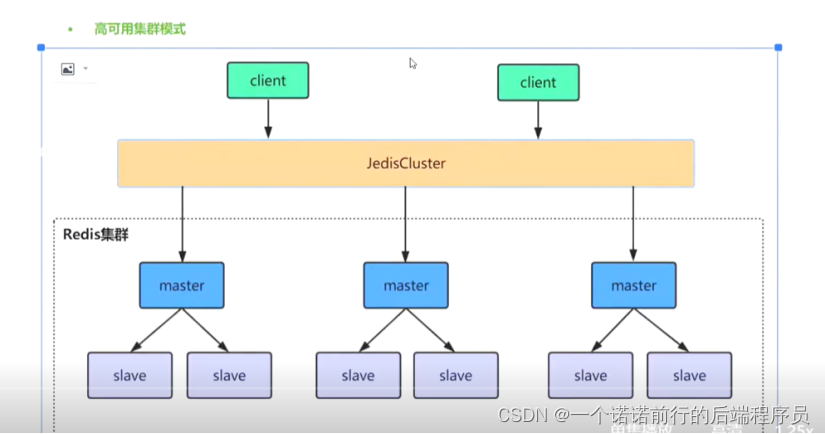
我们此时搭建这么一个redis集群,redisCluster 他的数据是进行分片存储的


不同的微服务搞一个小的redis集群 比如说用户用用户的redis集群
redis集群中至少要有3个主节点,每个主节点配置3个从节点,3主3从,6台机器
主节点会分配槽位
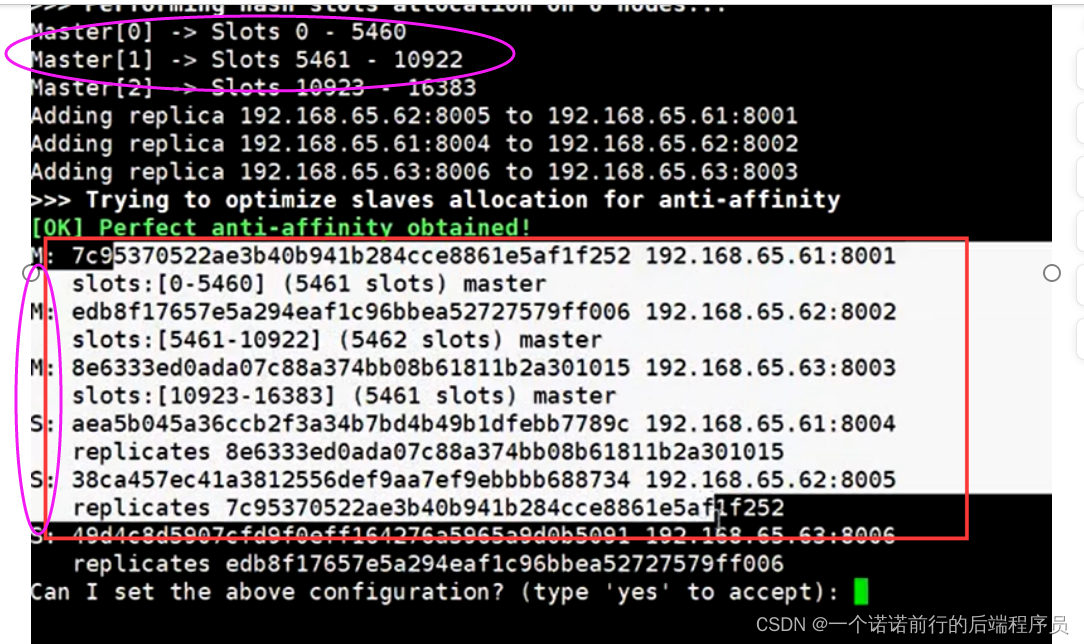

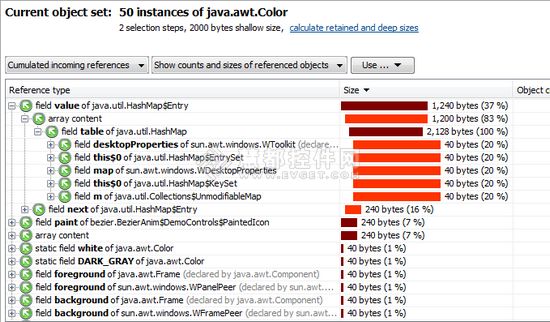
一共分配16384个槽位,此时是基于CRC16算法定位数据,我们可以用cluster Info 来查看redis集群的信息 目前来看 他的cluster_size 长度是3
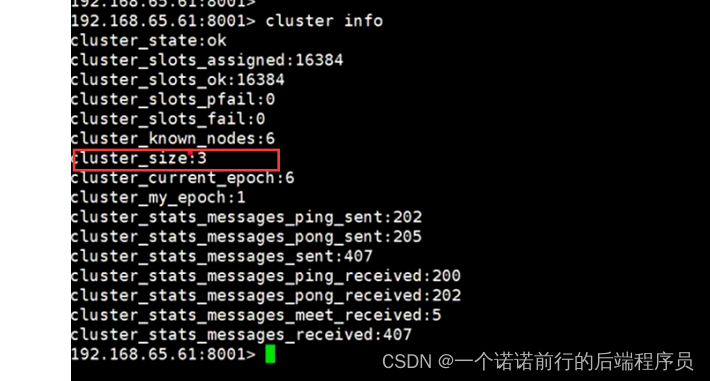
集群关键信息 clusterNodes 这个是集群的6台信息

主从架构我们集群的信息 他会写进配置文件中

集群搭建好了,他会根据你的key计算 用crc16算法来计算 看这个key会在那个节点上
分片定位算法
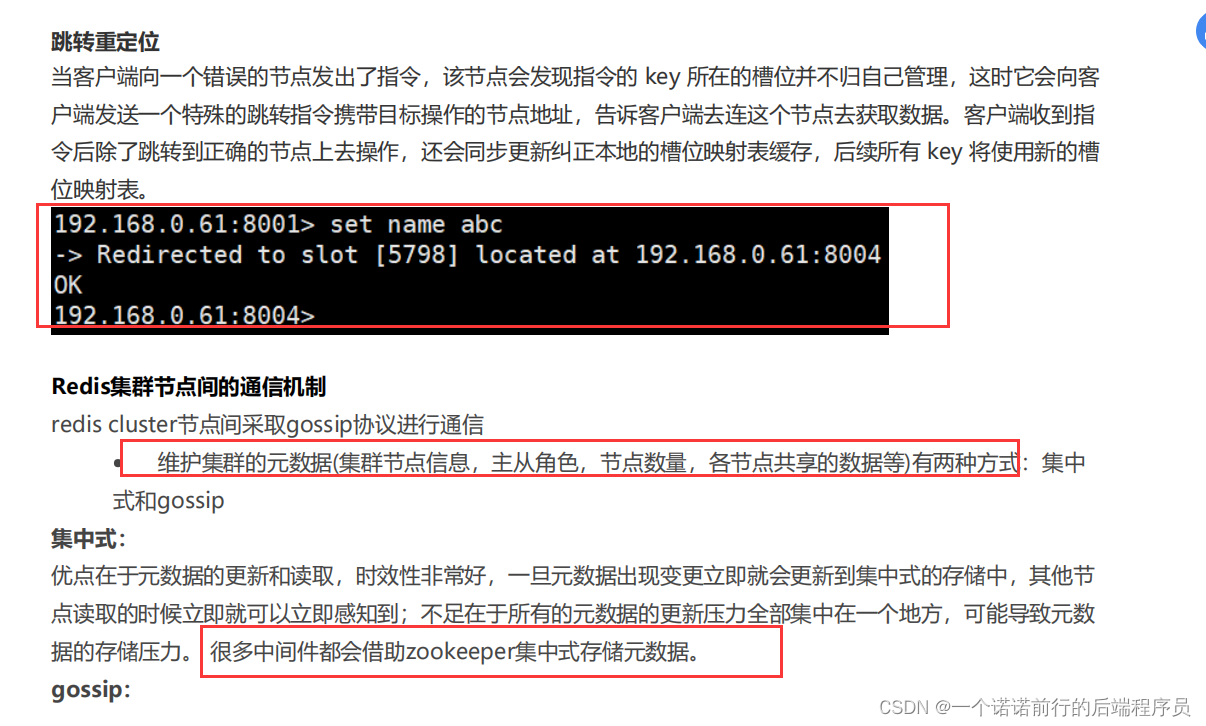
元数据信息 比如说我新加一个机器 或者说主节点挂了 在redis中这些信息是通过goosp告诉其他节点的
对于元数据的维护 我们还可以通过zk来进行管理 比如说dubbo kafka之列的
他吧元数据信息维护在zk中,把我们的客户端信息注册在zk中
只要存储元数据的地方发生变化 所有客户端都能够访问到最新的
goosp点对点 慢慢通知的这种情况 通知是要花费时间的
如果你的集群节点搞的太多 内网集群变动的话 内部心跳通知什么的 会很耗时
现在都是微服务架构,一个为微服务或者几个微服务公用一个redis集群,每个redis集群可能就几个主节点 每个主节点配置呢么1到2个从节点。他不会搞太多机器,因为集群的变动的话,redis内部是通过goosp协议点对点的通知的, 他会很耗时
redis 默认是一个Ap架构 更多的是保证你的可用性
Zk保证是绝对的一致性
redis的集群选举分析原理 当master挂掉以后,会进行多个slave进行选举,选举就会有过半机制

集群脑裂问题的解决方案 (过半机制)