精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
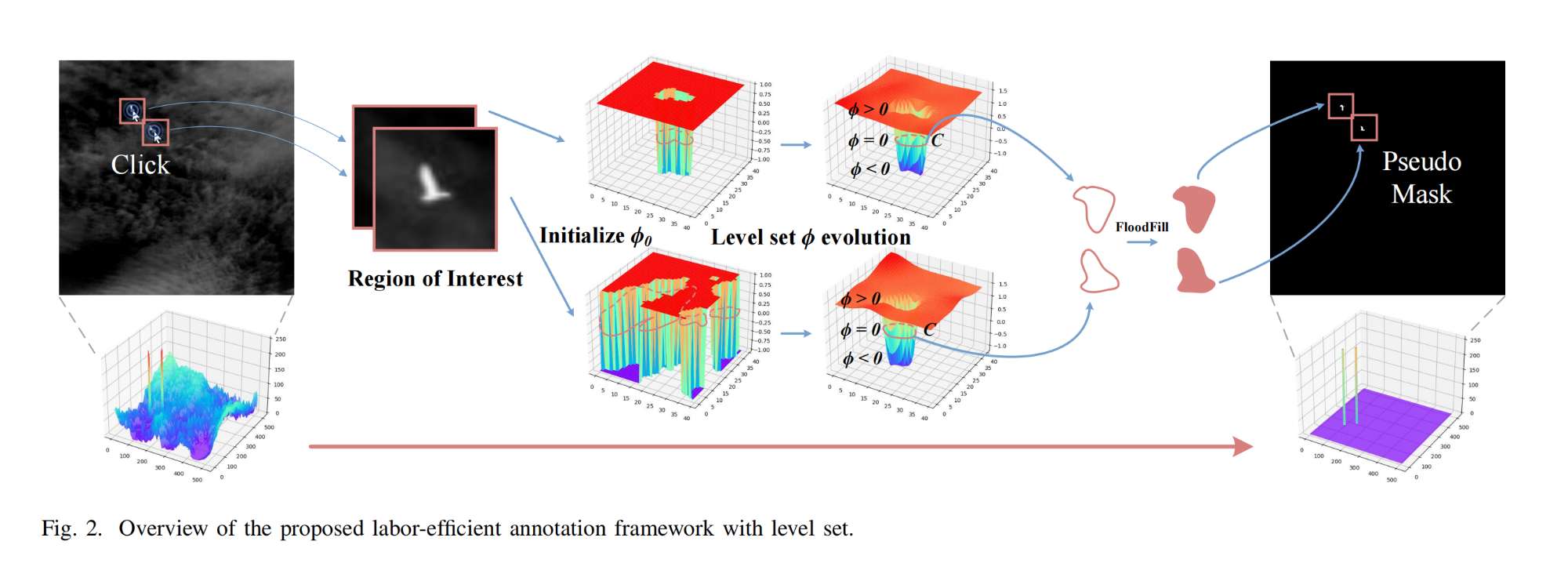
1.【目标检测】Click on Mask: A Labor-efficient Annotation Framework with Level Set for Infrared Small Target Detection
-
论文地址:https://arxiv.org//pdf/2310.12562
-
开源代码:https://github.com/Li-Haoqing/COM
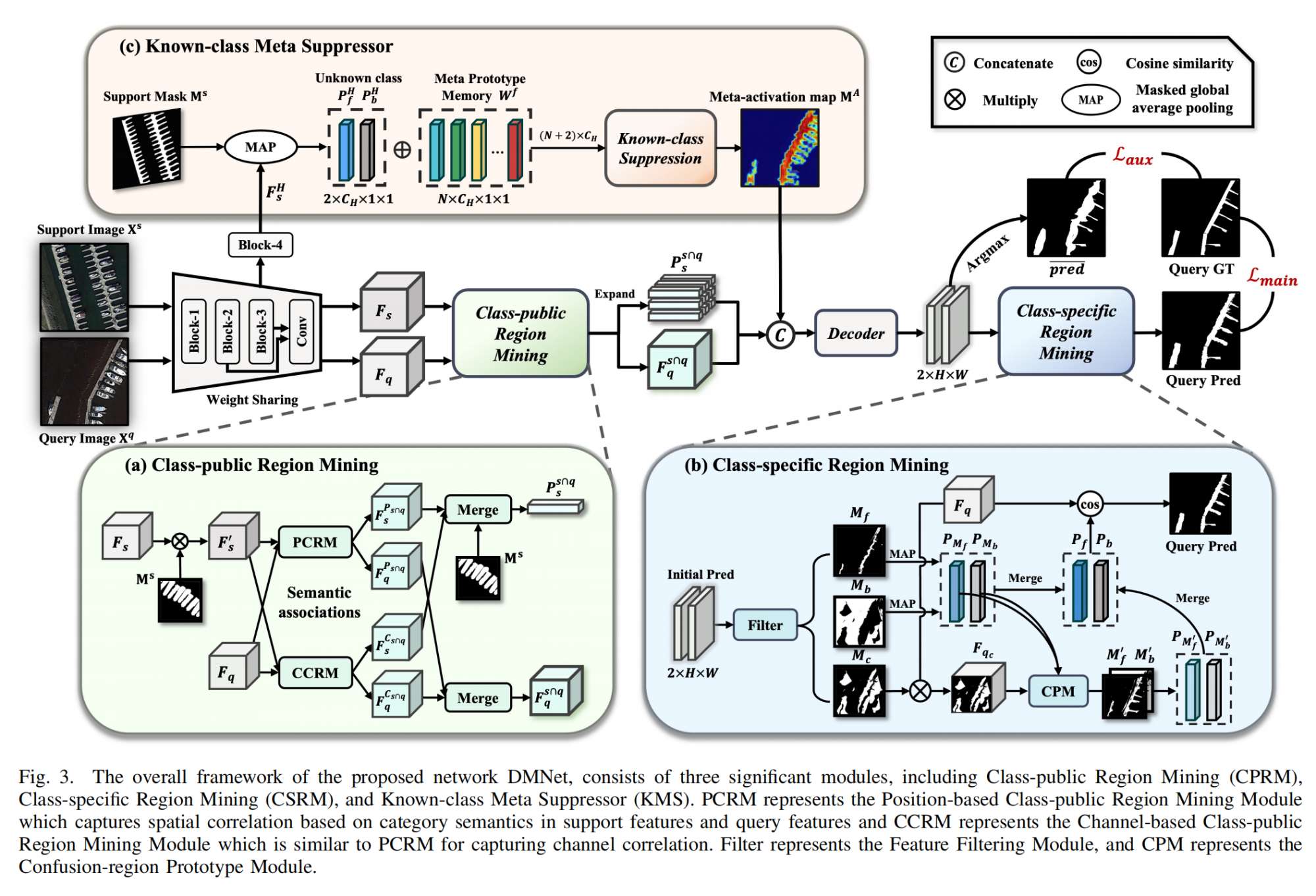
2.【图像分割】Not Just Learning from Others but Relying on Yourself: A New Perspective on Few-Shot Segmentation in Remote Sensing
-
论文地址:https://arxiv.org//pdf/2310.12452
-
开源代码(即将开源):https://github.com/HanboBizl/DMNet/
3.【语义分割】Minimalist and High-Performance Semantic Segmentation with Plain Vision Transformers
-
论文地址:https://arxiv.org//pdf/2310.12755
-
开源代码(即将开源):https://github.com/ydhongHIT/PlainSeg
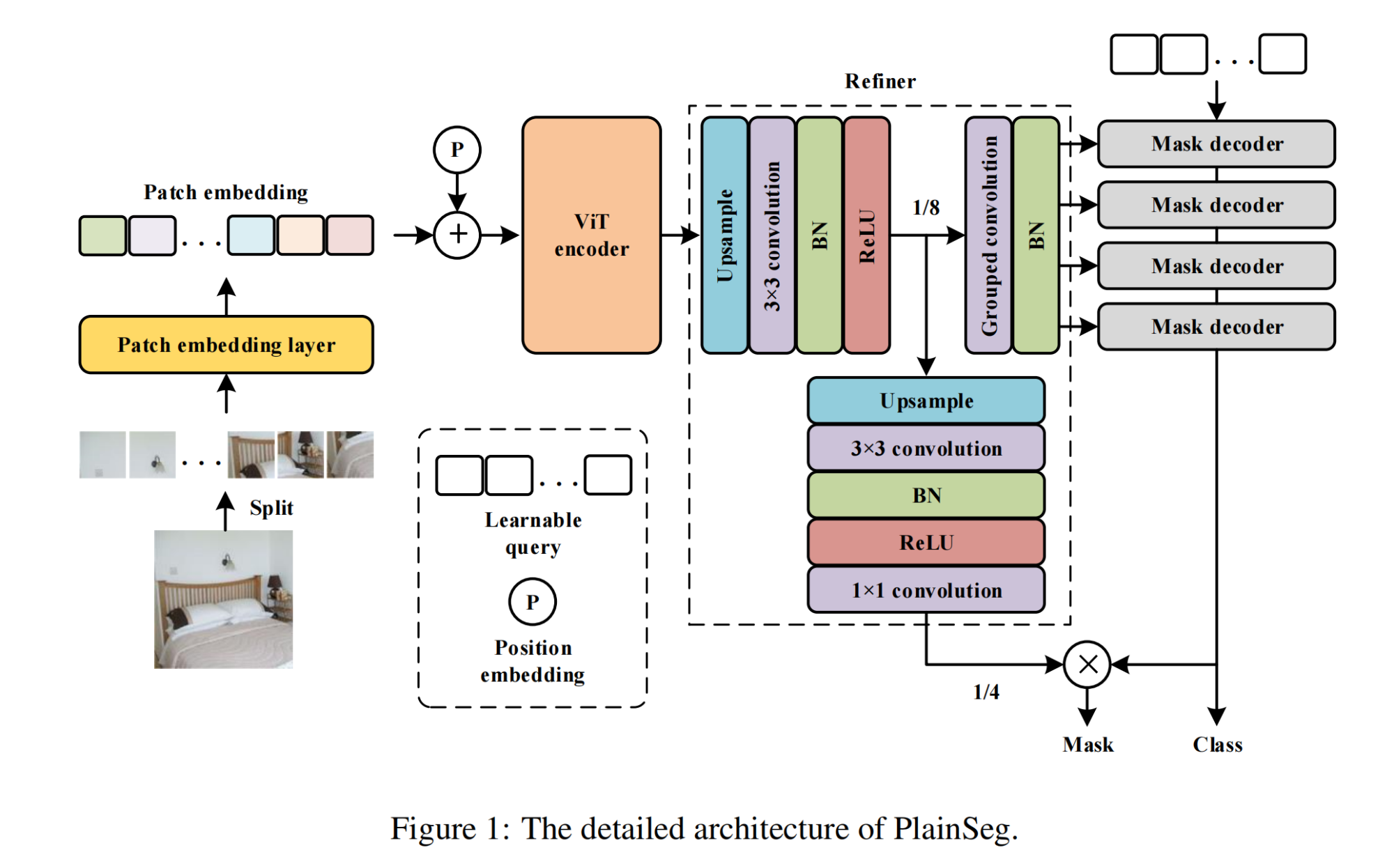
4.【OCR】DocXChain: A Powerful Open-Source Toolchain for Document Parsing and Beyond
-
论文地址:https://arxiv.org//pdf/2310.12430
-
开源代码:https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/Applications/DocXChain

5.【点云分割】2D-3D Interlaced Transformer for Point Cloud Segmentation with Scene-Level Supervision
-
论文地址:https://arxiv.org//pdf/2310.12817
-
工程主页:MIT
-
开源代码:https://github.com/jimmy15923/mit
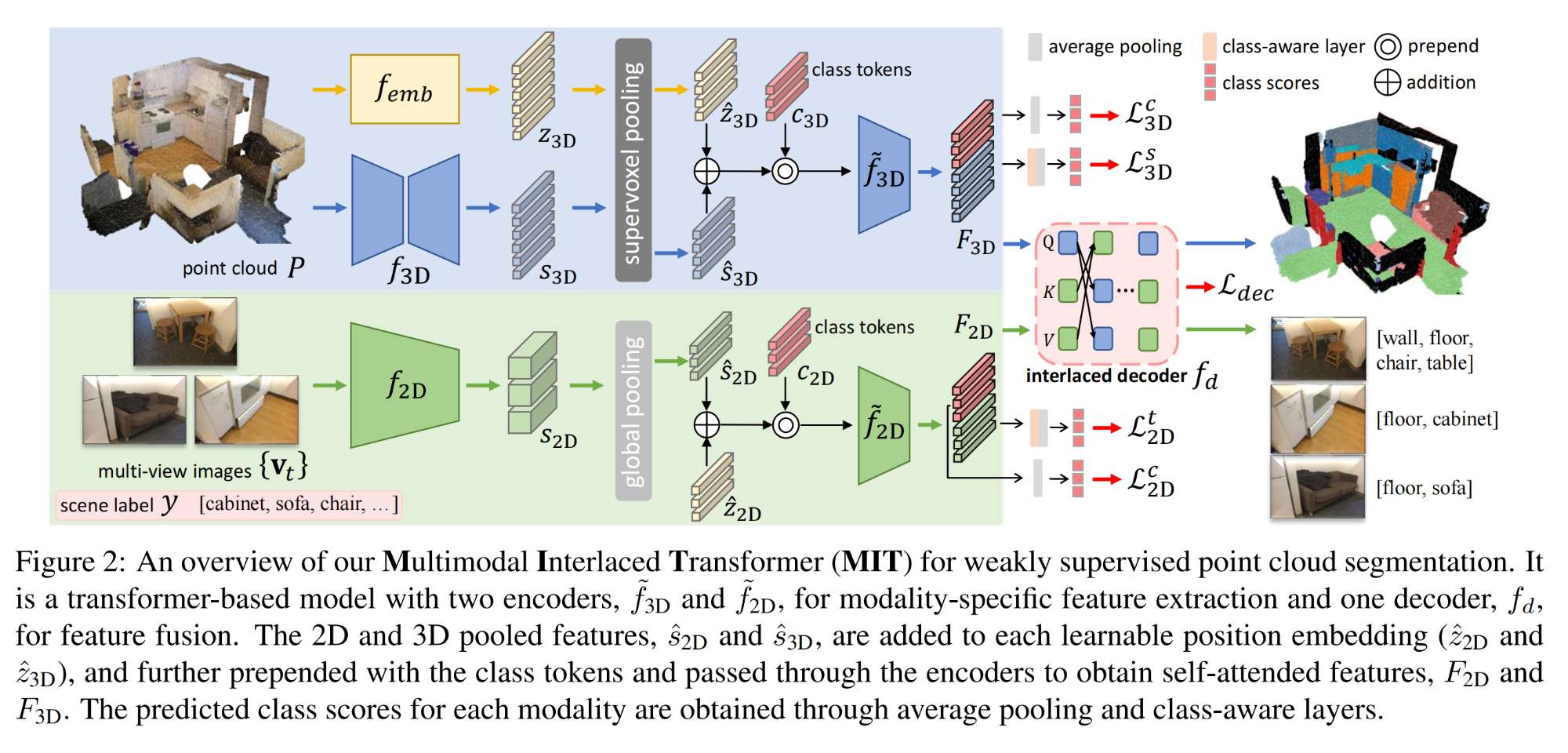
6.【医学图像分割】DA-TransUNet: Integrating Spatial and Channel Dual Attention with Transformer U-Net for Medical Image Segmentation
-
论文地址:https://arxiv.org//pdf/2310.12570
-
开源代码:https://github.com/SUN-1024/DA-TransUnet
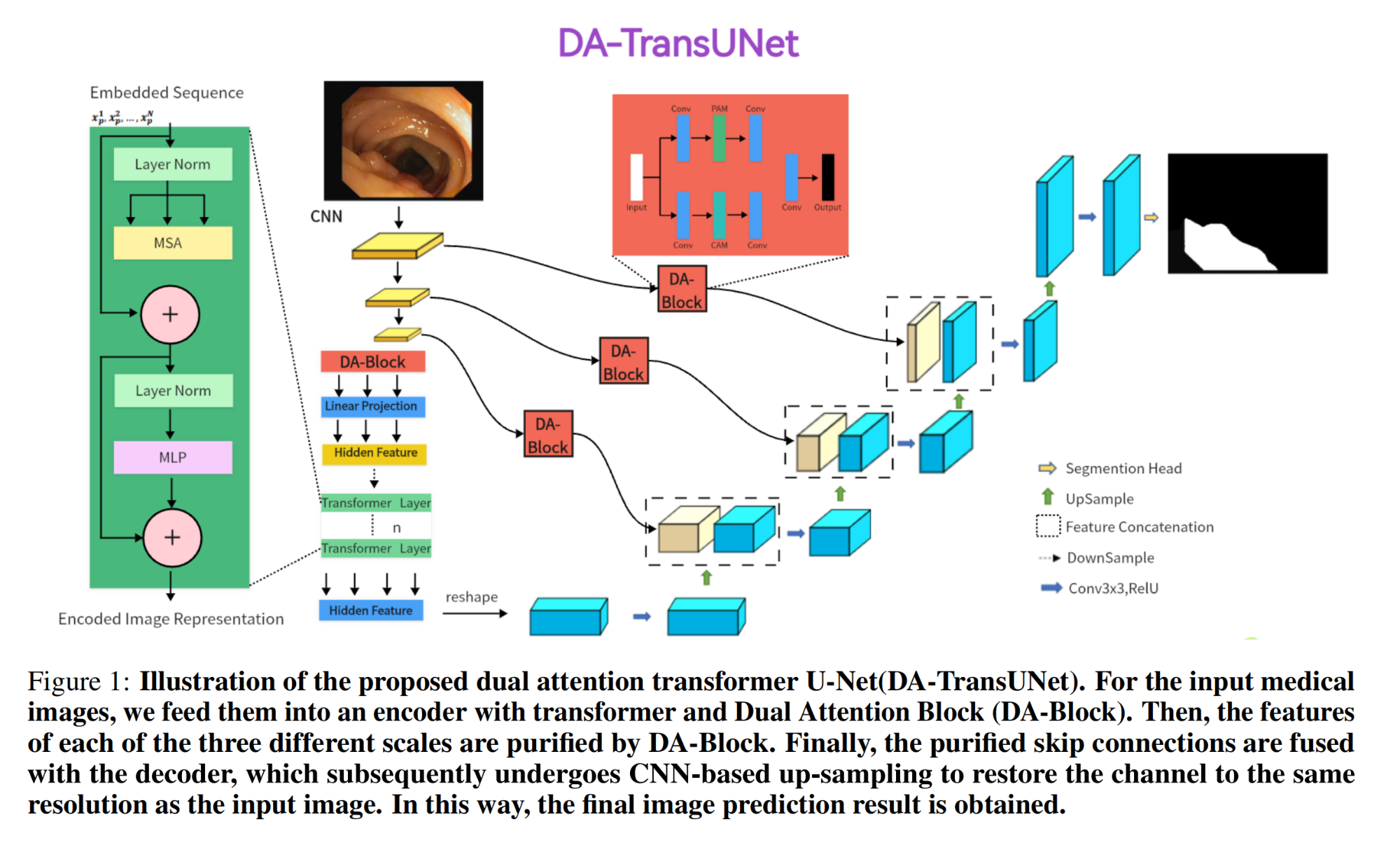
7.【多模态】Frozen Transformers in Language Models Are Effective Visual Encoder Layers
-
论文地址:https://arxiv.org//pdf/2310.12973
-
开源代码:https://github.com/ziqipang/LM4VisualEncoding

8.【多模态】CLAIR: Evaluating Image Captions with Large Language Models
-
论文地址:https://arxiv.org//pdf/2310.12971
-
工程主页:CLAIR: Evaluating Image Captions with Large Language Models
-
开源代码:https://github.com/davidmchan/clair

9.【人体运动生成】HumanTOMATO: Text-aligned Whole-body Motion Generation
-
论文地址:https://arxiv.org//pdf/2310.12978
-
工程主页:HumanTOMATO: Text-aligned Whole-body Motion Generation
-
开源代码(即将开源):https://github.com/IDEA-Research/HumanTOMATO
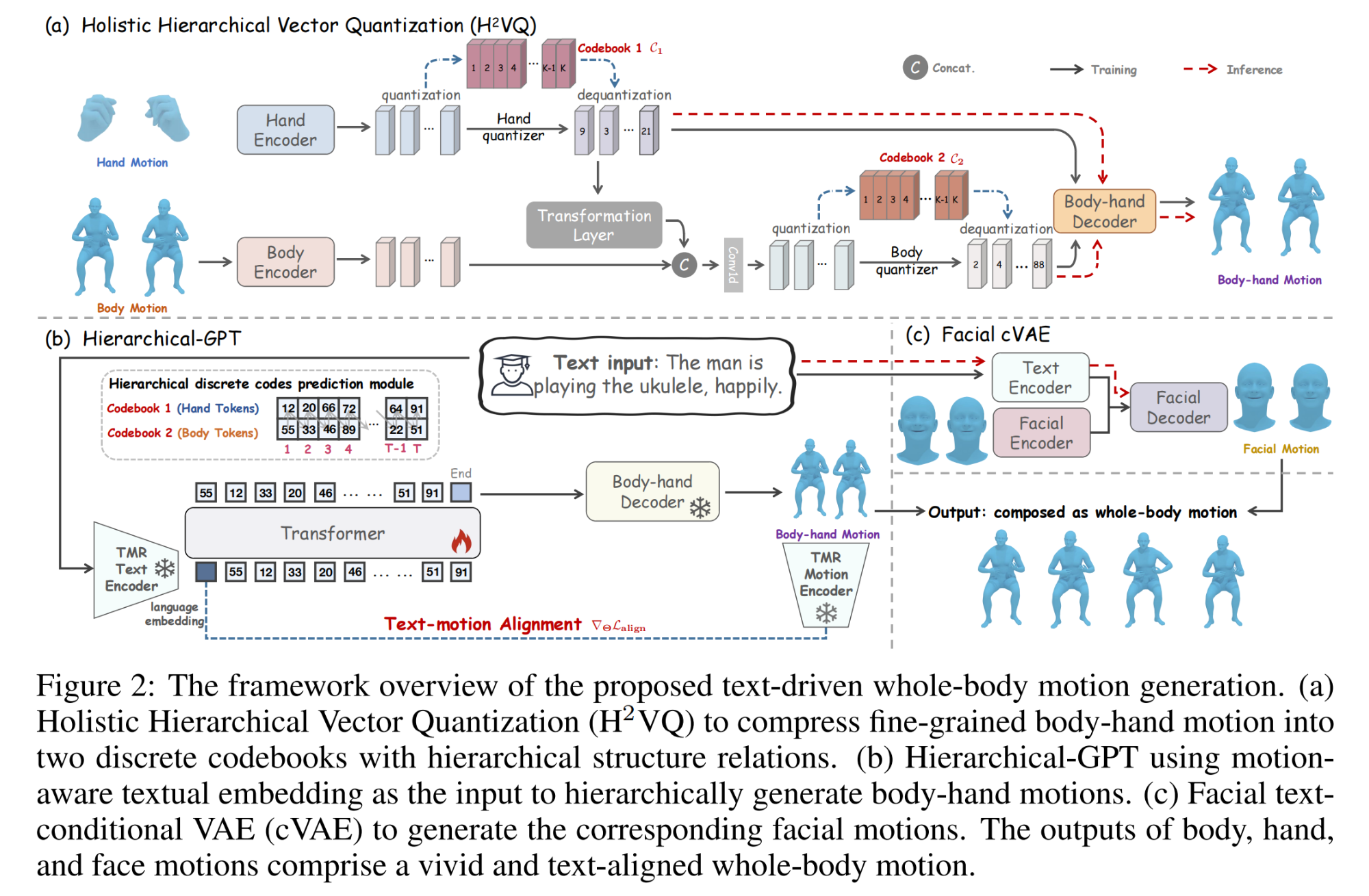
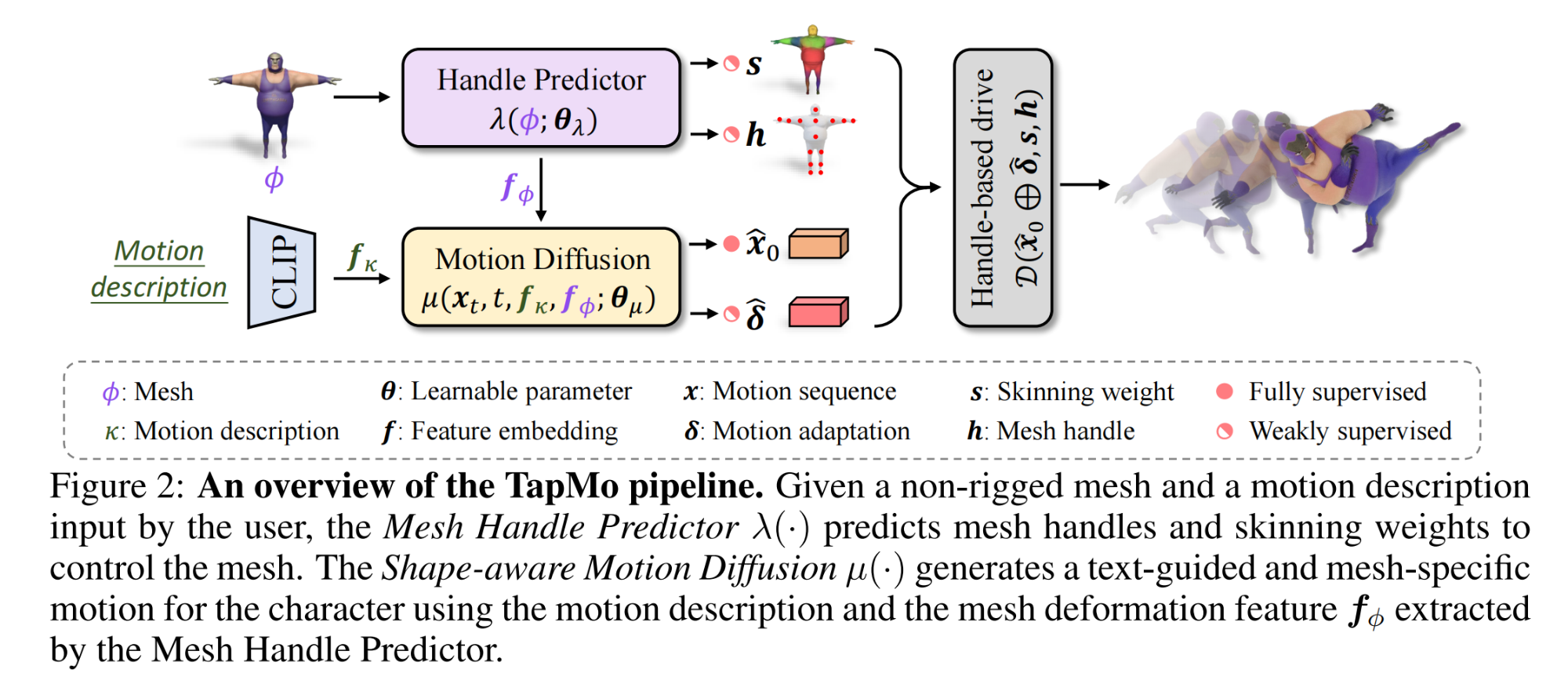
10.【人体运动生成】TapMo: Shape-aware Motion Generation of Skeleton-free Characters
-
论文地址:https://arxiv.org//pdf/2310.12678
-
工程主页:TapMo
-
代码即将开源
11.【三维重建】Enhancing High-Resolution 3D Generation through Pixel-wise Gradient Clipping
-
论文地址:https://arxiv.org//pdf/2310.12474
-
开源代码:https://github.com/fudan-zvg/PGC-3D

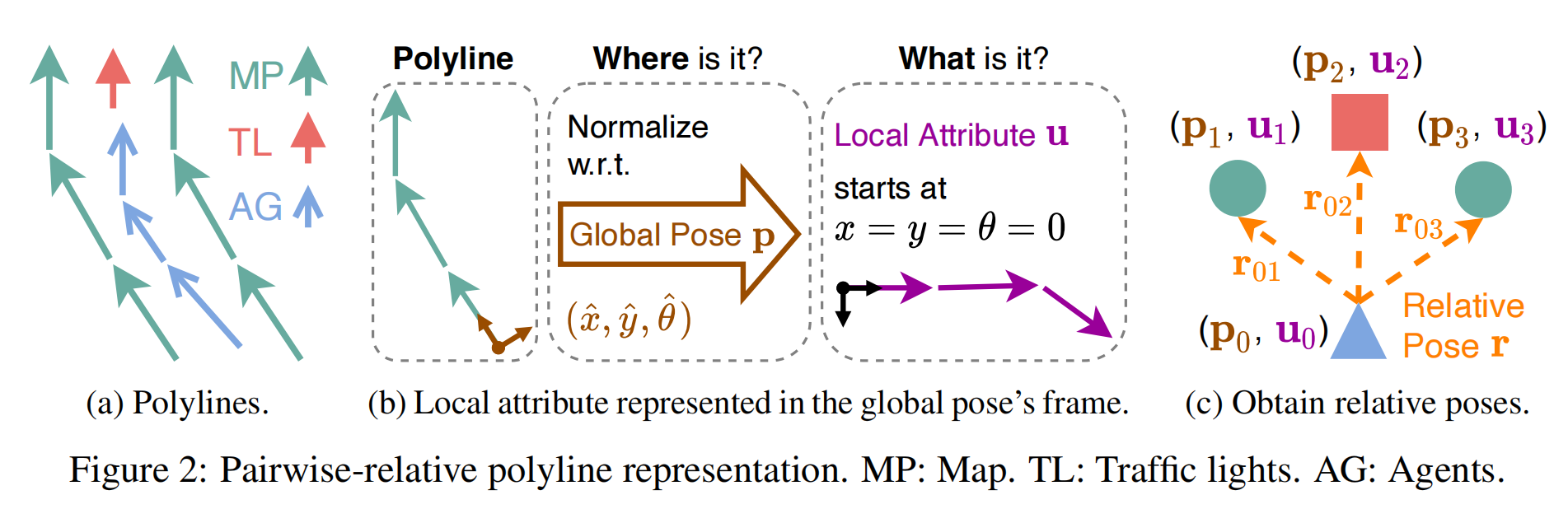
12.【运动预测】Real-Time Motion Prediction via Heterogeneous Polyline Transformer with Relative Pose Encoding
-
论文地址:https://arxiv.org//pdf/2310.12970
-
开源代码(即将开源):https://github.com/zhejz/HPTR
论文已打包,点击进入—>下载界面
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.10.19
CV计算机视觉每日开源代码Paper with code速览-2023.10.18
CV计算机视觉每日开源代码Paper with code速览-2023.10.17
CV计算机视觉每日开源代码Paper with code速览-2023.10.16
使用目标之间的先验关系提升目标检测器性能
港科大提出适用于夜间场景语义分割的无监督域自适应新方法
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
EViT:借鉴鹰眼视觉结构,南开大学等提出ViT新骨干架构,在多个任务上涨点
如何优雅地读取网络的中间特征?