原文链接:
https://aclanthology.org/2023.acl-short.123.pdf
ACL 2023
介绍
问题
基于span来解决嵌套ner任务的范式,大多都是先对span进行枚举,然后对每个span进行分类,实际就是得到一个分数矩阵,矩阵中每个元素表示一个span(比如矩阵中的n行m列,对应着span(token_n, token_m))。作者认为这种方法忽略了span与sapn之间的空间信息。
IDEA
在矩阵中,每个span与其周围的span在原句中都是比较接近的,存在一定的空间语义信息。因此作者提出使用CNN来对span之间的空间信息进行建模。
方法
整体来说,首先对span进行枚举,然后通过Biaffine decoder得到一个三维的特征矩阵,在此基础上使用CNN来进行卷积,在span与span之间进行交互,丰富span的表征,最后对其进行分类。整体结构如下图所示:

Span-based Representation
使用一个预训练模型(比如BERT)来得到输入句子的word embedding,对于分词后的token,使用max-pooling来得到这个word的词嵌入:
![]()
然后使用一个多头的Biaffine decoder来得到每个span的分数矩阵R:

CNN on Feature Matrix
使用CNN来对span与其周围的span之间的交互进行建模,
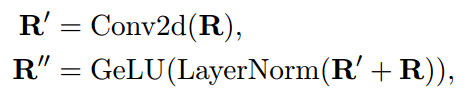
这里由于句子中的token数量不同,导致分数矩阵R的大小会不同,为了进行批量计算,在矩阵中使用0来进行padding。
Output
使用一个mlp来得到相应的预测对数:
![]()
模型的损失函数是一个分类二值交叉熵:
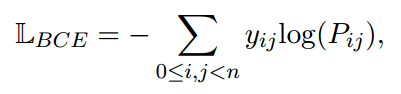
实验
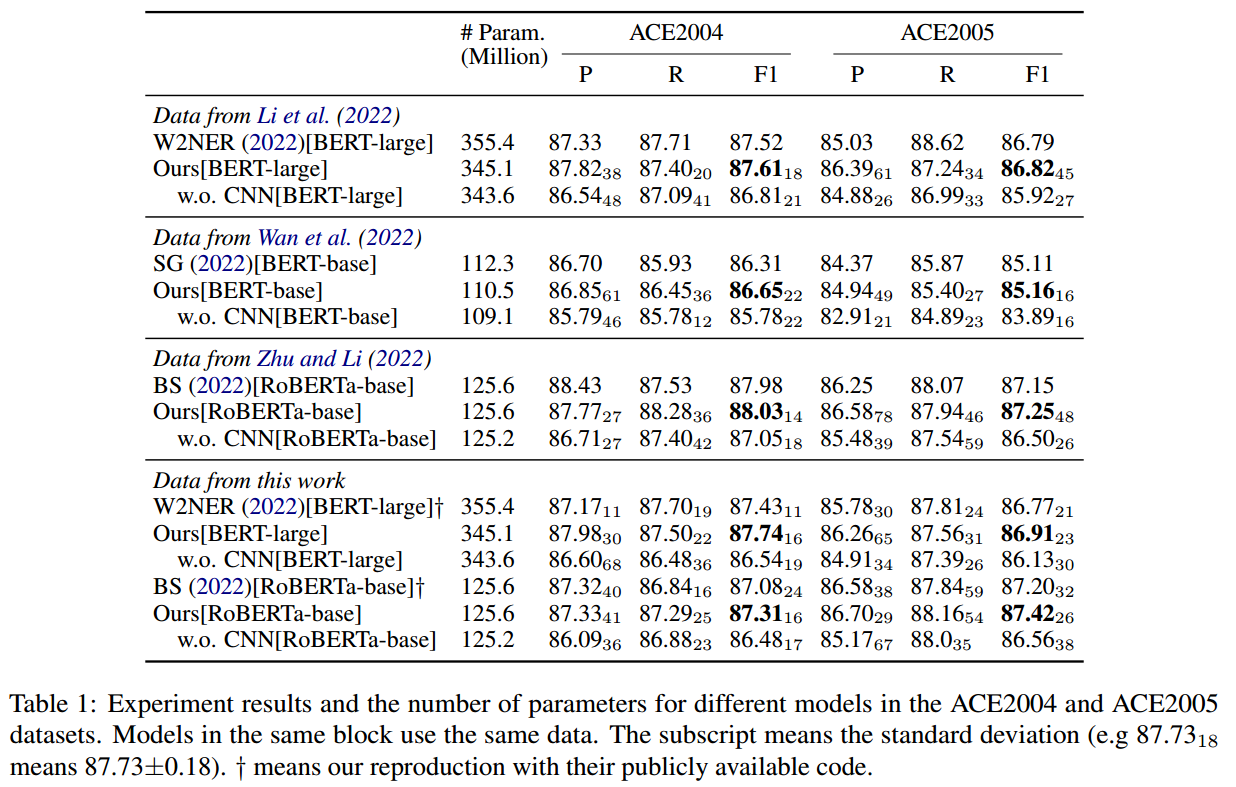
在ACE2004和ACE2005这两个数据集上进行实验,结果如下所示:
在genia数据集上进行了实验(预训练模型使用BioBERT-base),结果如下图所示:

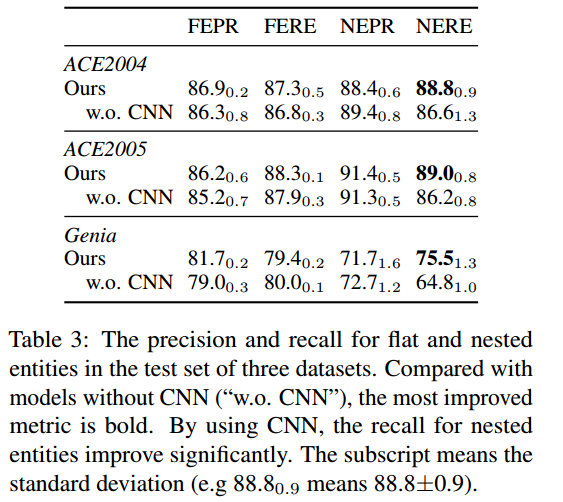
为了研究为什么CNN有利于嵌套ner任务,作者将实体分为两类:嵌套实体(nest ner)和非嵌套实体(flat ner)。作者设计了 4 个指标 NEPR(flat entity precision)、NERE(flat entity recall)、FEPR(nested entity precision) 和 FERE(nested entity recall):
结论
论文想法很简单,使用了卷积来对不同的span进行交互,使其能够学习到周围span的信息,但是其实从实验结果来看,加了CNN的效果并没有很大的提升。但将卷积利用到NER任务中,也浅算一个创新点吧,或许可以考虑不止在span与span之间进行卷积。