目录
进程优先级
进程饥饿
Linux当中优先级标识符
优先级的修改参数NI
进程最终优先级
修改进程的优先级
操作系统实现优先级的方法
位图
并发的概念
进程切换原理
环境变量
其他环境变量
获得环境变量的方式
getenv系统调用函数
命令行参数
本地变量
export添加环境变量
unset删除环境变量
由于我们操作系统当中的进程有很多种,但是我们的数据资源有限。所以我们的进程在运行的时候需要区分一定的顺序,这样才不会造成进程方面的干扰。所以在我们的操作系统当中引入了进程优先级的概念。
进程优先级
进程优先级是确定在操作系统当中哪一个进程先运行,哪一个数据后运行的标志。就像我们在上面所说到的那样,因为资源是有限的,但是进程有很多个,注定了进程之间存在竞争性。操作系统必须保证各个进程之间良性竞争,因此就有了进程的优先级。
进程饥饿
当我们的进程由于进程调度方面的问题,导致我们的进程长时间得不到调度,也就是该进程当中的代码长时间得不到执行,我们将这种现象叫做进程的饥饿现象。
Linux当中优先级标识符
在Linux当中我们也有表示先后运行的标识符:PRI,这个字符其实是priority优先权的缩写。我们可以通过ps指令进行查看:

我们可以通过上面的图片当中查看到我们进程优先级的值为80。对于我们的进程的优先级来说,默认值为80。我们还可以通过nice值对进程的优先级进行修改,也就是我们上面图中的NI值。
优先级的修改参数NI
我们可以通过nice值对我们进程的优先级进行修改。但是我们可以无限度的放大或者缩小一个进程的优先级吗?
假如我们无限制的放大一个进程的优先级,我们的这个进程就会一直被操作系统调度,假如该进程为一个死循环就会造成操作系统瘫痪。
假如我们无限制的缩小一个进程的优先级,我们这个进程就会一直处于调用队列的对尾,永远都不会被调用。同样会造成资源上的浪费。
因此我们的进程优先级不能被无限的放大或者缩小。为了解决这个问题,在Linux当中我们对NI值的修改进行了约束。我们要求nice值在修改的时候必须在 [ -20 , 19 ] 这个数据的范围之内变化。
进程最终优先级
一个进程最终的优先级等于进程的默认的值加上我们的nice值。进程的默认的优先级的值为80,加上我们的nice值,得到的取值的范围为:[ 60 , 99 ] 。
当一个进程的优先级的值越小该进程就会先被操作系统调用执行。
修改进程的优先级
如果我们想要修改一个进程的优先级,我们可以通过top指令修改一个进程的优先级。测试示例如下:
先通过ps -al | head -1 && ps -al | grep proc指令进行查看最终进程的优先级:

之后输入top指令,通过修改nice值,进行修改进程的优先级:
1.当我们输入top指令之后进入此界面就可以进行我们优先级的修改了。

2.输入r,进行输入想要修改的进程的标识符

如果不输入pid的话就会对我们的21864号进程进行修改进程的优先级。
3.输入我们需要修改的进程PID之后,再输入我们修改的nice值即可
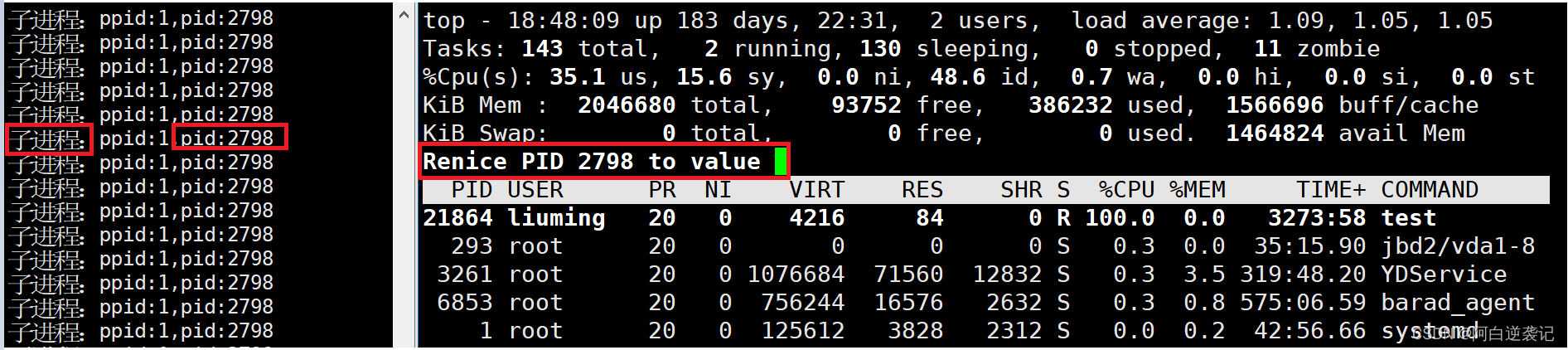
4.再次对我们进程的优先级进行查看(输入q可以退出优先级修改界面)

我们会发现,再修改完毕之后再通过PRI(before)+NI就得到了我们现在进程的优先级60。
操作系统实现优先级的方法
既然知道了进程优先级的使用方法,那么我们再来学习一下操作系统实现优先级的方法。
由于我们的进程优先级的区间在 [ 60 , 99 ] 一共有40个数据值。每一个优先级都可以代表很多进程。我们将优先级相同的进程组成一个链表进行管理。 因此我们可以通过四十个链表的首节点的指针进行对于对四十个优先级的值的进程进行管理。
结合我们之前学习的知识:我们运行的进程在资源都准备完毕的时候会将我们的PCB结构体加载到运行队列当中。我们的运行队列当中就规定了这一类的资源的判断方式:

我们可以发现Linux实现运行队列的方式是实现一个指针数组,每一个指针管理着一个链表,该链表就是我们对应的需要运行的程序。
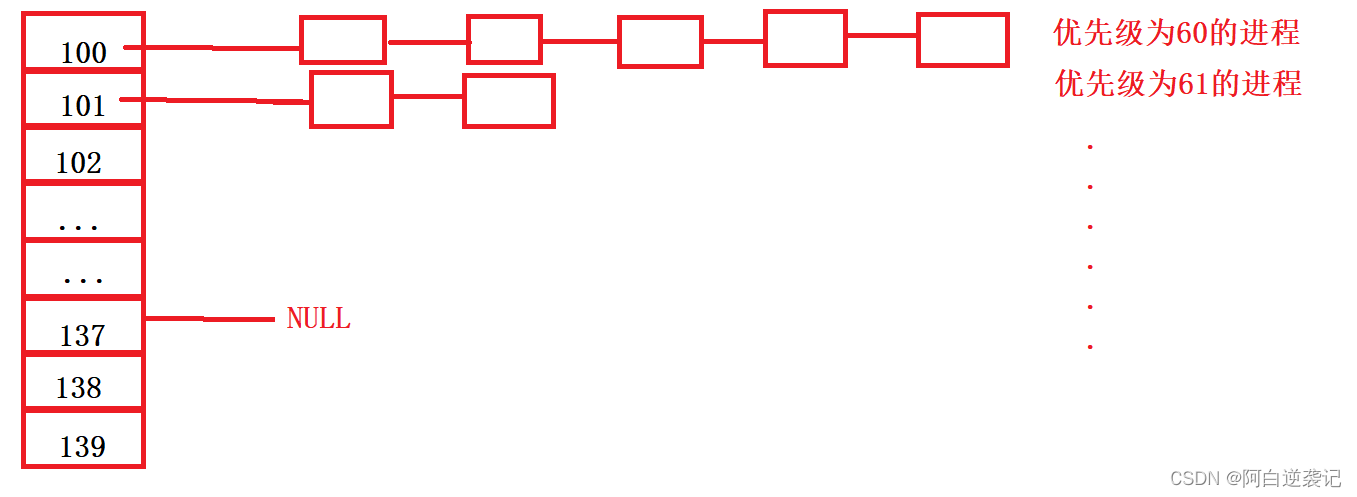
如果对应的优先级没有相应的进程那么我们相应位置所对应的指针就设置为空。
所以我们先要查看并实行特定优先级的进程就可以通过遍历一个指针数组实现。在Linux内核当中将优先级调度算法优化成为了O(1)。
位图
为了方便我们判断相应优先级是否存在相应的进行需要被执行,所以我们还可以通过位图的方式方便我们的管理。
所谓的位图就是使用二进制位表达相对应的内容。例如我们就可以使用二进制位只存在0和1的特点,进行表示某一个优先级链表当中是否存在需要执行的进程。例如:1表示该优先级存在需要执行的进程,0表示该优先级不存在需要执行的进程。这样我们就可以仅仅通过一个整形变量就可以检查我们40个空间是否存在数据了。
并发的概念
一个进程在执行的时候可以分为并行和并发两种状态。所谓的并行就是我们多个进程在多个CPU上面运行,其实就是共同执行。
而我们的并发的就是有多个进程在一个CPU当中依次执行。在一段时间之内我们的程序均可以被执行,我们将这种方式叫做并发。
CPU只有一个为什么可以有多个程序共同执行呢?我们需要知道的是:进程的并发需要从两个方面进行观察。在很短的时间段里面一个CPU当中运行的只能有一个进程。但是在较长的一段时间内由于进程是经过快速切换的,一个进程运行完一个时间段之后就会切换下一个进程继续执行。又由于计算机切换进程的速度很快,所以表现出来的形式就是有多个进程共同在CPU上面执行。
进程切换原理
想要知道一个进程的在CPU上面的切换的原理,我们就需要想到两个问题:
1.进程切换之后执行出来的数据怎么办?
2.如何知道进程当中的代码执行到哪一行了呢?
Q:函数的返回值是怎么被外部拿到的呢?
A:当我们的函数在执行完之后,如果有需要会有一个返回值。但是我们的这个返回值是如何返回给我们main函数当中的变量的呢?
当我们在返回一个数据的时候,我们会先将这个返回值的数据写入到寄存器当中,再回到我们的main函数当中,之后再将寄存器当中的数据写入到指定的变量当中。这就是函数返回值写入的原理。
Q:我们是如何知道程序运行到哪一行的呢?
A:在我们的程序运行的时候会产生一个指针,这个指针指向我们需要执行的下一行代码。我们可以通过这个指针找到我们需要运行的代码。我们讲个指针成为程序计数器,也就是我们常说的PC指针。
在我们计算机当中有很多的寄存器供我们使用,比如通用的寄存器:eax,ebx,ecx 栈帧esp,eip,ebp 状态寄存器:status。这些寄存器当中存储着我们进程执行过程中产生的所有数据对应的值。我们将存储到寄存器当中的数据成为进程的上下文数据。
当我们的进程想要进行切换的时候,为了方便我们的进程之后可以顺利的执行,我们需要将处理的数据拿走,也就是将我们寄存器当中的上下文数据拿走。等到我们的进程再次加载进入CPU上面的时候,再将我们相应的数据加载进入相应的寄存器当中,最终通过PC指针得到下一行代码的运行位置。
因此我们的进程在被切换的时候最主要进行的操作为:1.保存上下文数据 2.恢复上下文数据 这样就实现了我们的进程切换。
环境变量
在Linux当中一切指令都是一个可执行程序文件,我们所编写的程序也是这样的。但是为什么我们编写的程序在执行的时候需要加上 ./ 但是我们执行的命令却不需要呢?
这个时候就需要介绍我们环境变量当中的一个内容 PATH 。如果大家对于计算机比较了解的话,那么肯定在Windows当中肯定对环境变量进行过配置。
当我们在PATH环境变量当中配置好目录地址的时候,我们就可以通过查找遍历PATH当中的目录进行直接执行相应的操作。不在需要我们一级一级输入我们文件的所在的位置。
在Linux当中也是同样的原理。我们编写的一个程序在运行的时候由于PATH路径当中没有相应的路径,所以我们就需要手动指出该程序所处电脑当中的位置。也即是 ./程序名。前面的 ./ 代表的是文件的路径。同样的由于我们执行的命令所处代码的位置已经在PATH路径当中进行过配置,所以我们不需要指定特定命令文件所处的位置。我们可以进行测试:
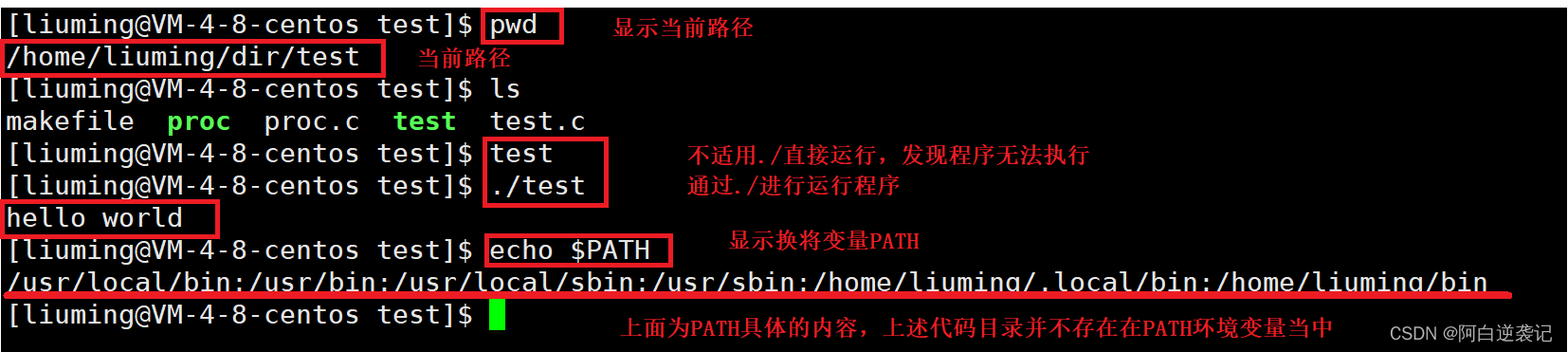
我们可以手动进行环境变量的配置:

其中我们的PATH目录当中每一个路径都以 :进行分隔,所以我们在添加新的PATH路径的时候,可以直接使用:进行添加新的路径。
需要注意的是:我们在修改PATH路径的时候必须加上我们之前的PATH路径,否则我们修改的路径就会被我们添加的路径所替代。在添加之后就可以直接运行我们的程序了。

如果我们不小心将系统当中原本的环境变量覆盖,不需要着急,我们只需要退出系统重新登陆即可。每一次登录我们的环境变量都会重置,并变成我们最初的状态。
其他环境变量
在Linux当中PATH只是我们众多环境变量当中的其中一个,其中还包括很多其他的环境变量,例如:HOME,USER,SHELL等等。我们可以通过env命令进行查看Linux当中所有的环境变量。如下图:
我们可以通过echo指令进行查看特定的环境变量: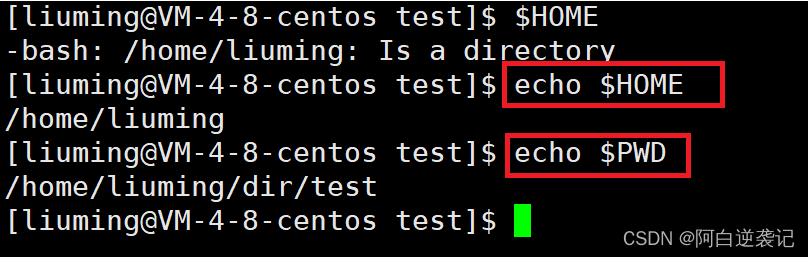
实质上我们在执行特定的命令的时候就是调用环境变量实现的,例如我们之前经常使用的pwd命令,其实就是执行的echo $PATH命令。测试如下:
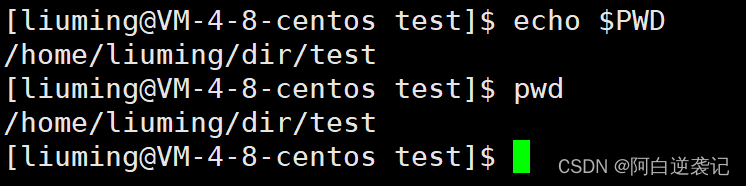
同样的当我们登上Linux系统的时候会默认进入/home/liuming目录,这个原因就是我们的操作系统在进入的时候直接执行了我们的echo $HOME命令。
获得环境变量的方式
getenv系统调用函数
获得环境变量有很多种方式。上面直接执行env命令就是获得环境变量的方式之一。我们还可以通过系统调用接口进行查看特定的环境变量。测试代码如下:
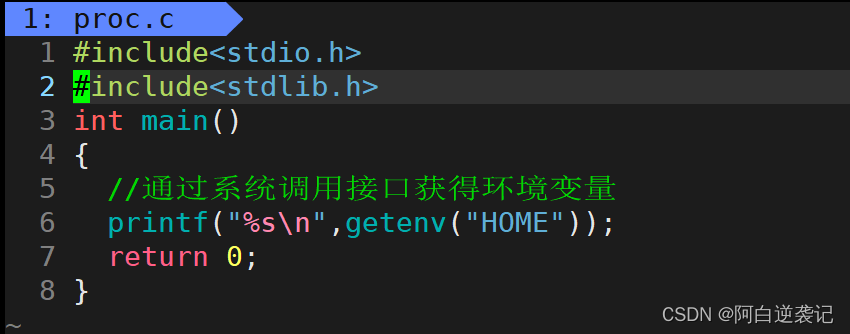
我们直接调用getenv函数就可以获得特定的环境变量的值,其中getenv的参数为我们想要查看的环境变量的名称。
运行结果如下:
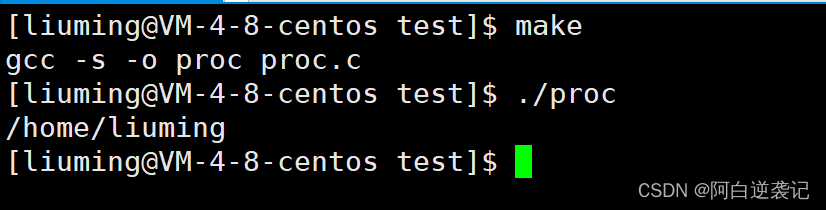
命令行参数
第二种方式就是使用命令行参数进行查看系统当中的环境变量。对main函数比较熟悉的都会知道,我们的main函数其实是存在参数的。先来认识一下main函数的参数:
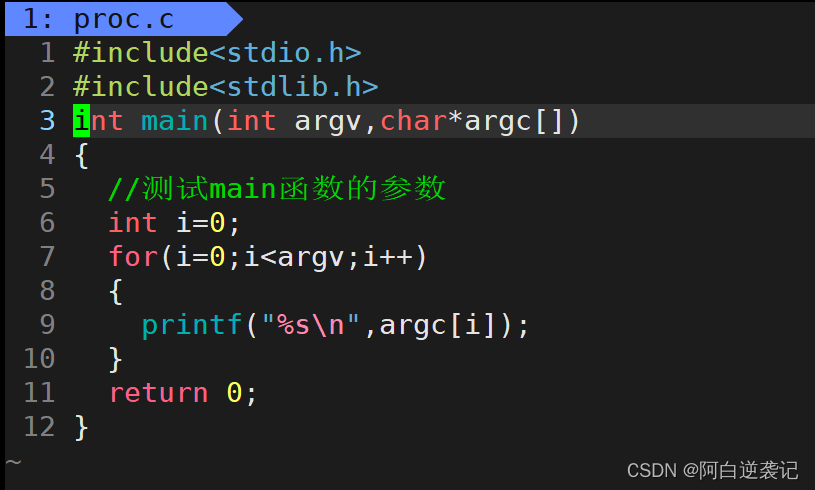
我们先认识前两个参数。我们会发现在main函数当中会有一个int类型的数据,有一个指针数组。其中argv整数代表的就是我们在命令行当中一共输入的参数的个数,后面的指针存储的就是我们在命令行当中输入的参数字符串。我们可以通过打印的方式进行测试:

我们还可以通过遍历向量表的形式进行打印参数。所谓的向量表实质上就是我们的argc指针数组,在操作系统当中存储着我们指针数组当中相关的数据,并在我们指针数组的末尾添加一个空指针,我们可以通过查看元素是否等于空指针判断参数是否打印完毕。测试代码如下:
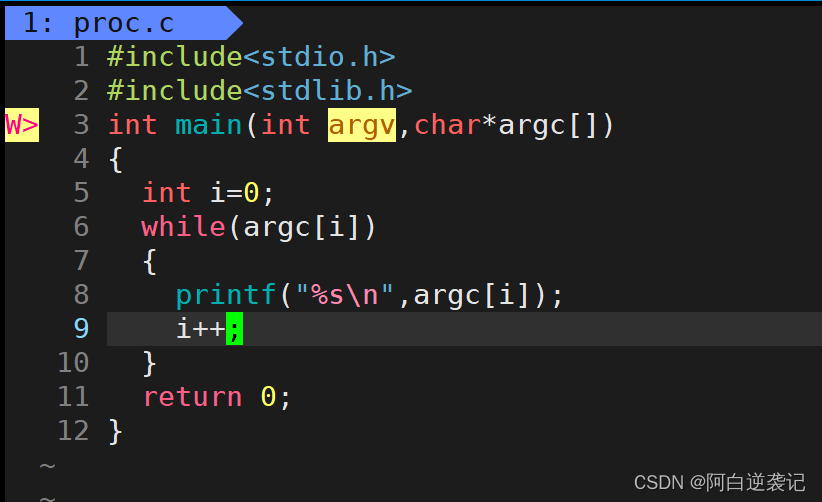
执行效果如下:
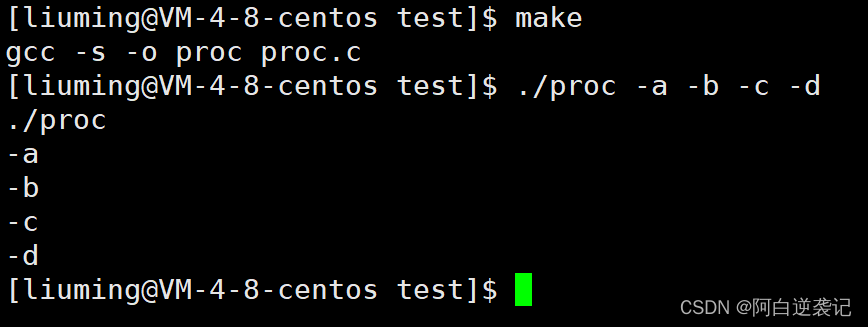
程序和我们的预期结果相同。
但是我们main函数里面一共有三个参数,其中的第三个参数同样是一个指针数组,其中保存的就是我们正在学习的环境变量,使用方法同样可以通过while循环进行,最后查找到末尾的NULL结束。测试代码如下:
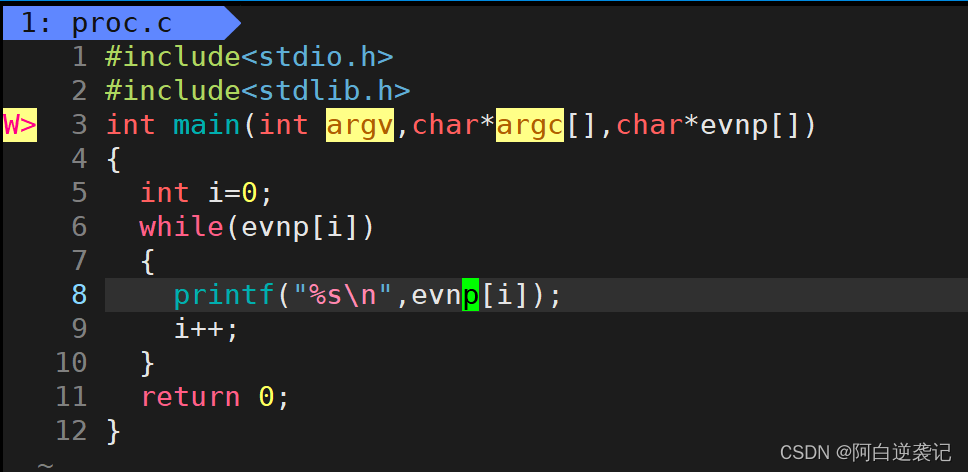
运行效果如下:
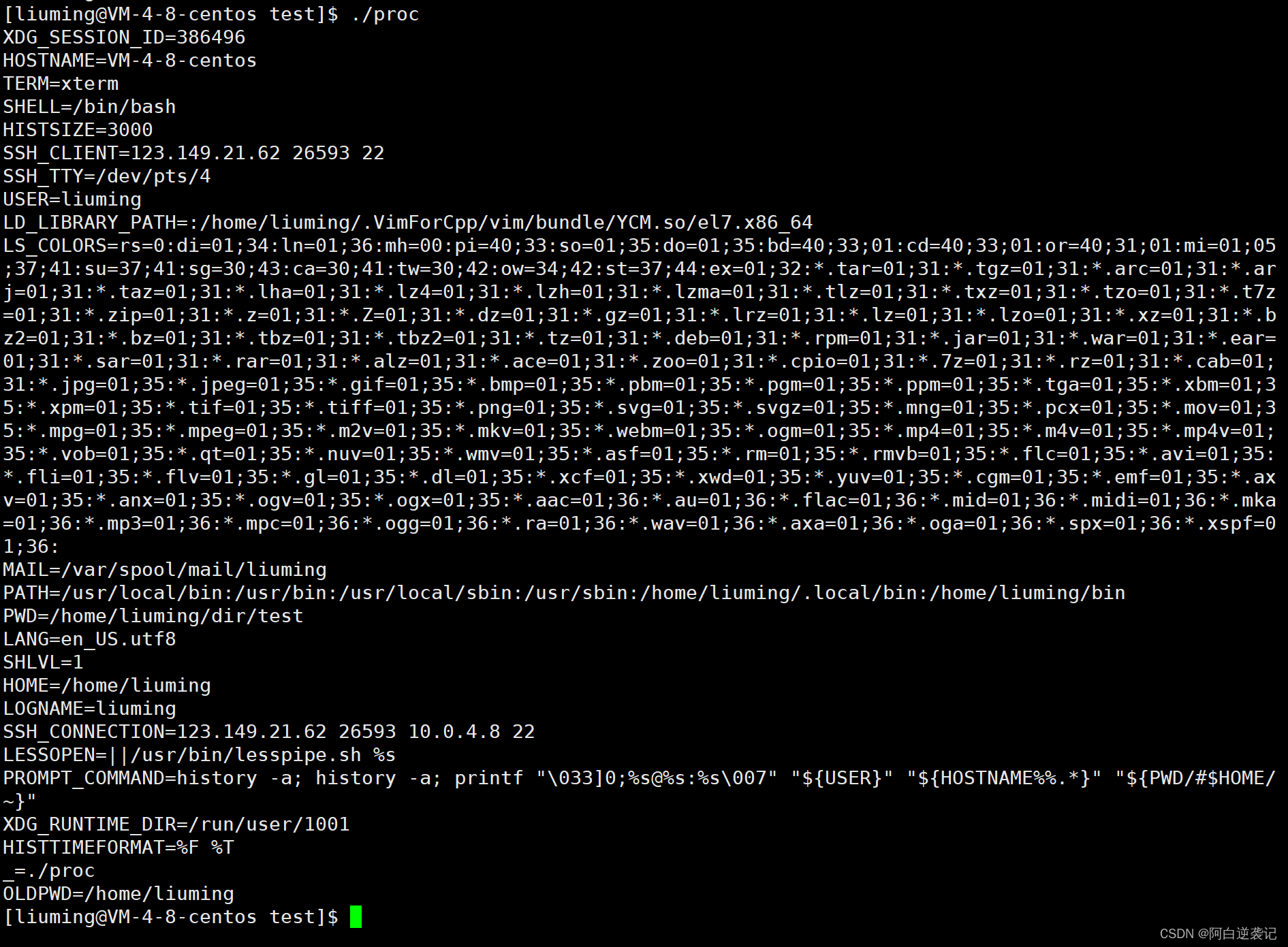
我们发现运行完代码之后获得的环境变量和我们在命令行当中输入env命令查看到的相同。所以就引出了另一个概念:环境变量的继承。
我们在创建一个子进程的时候,main函数当中的环境变量都是从父进程当中或得到的,因此我们获得的环境变量都是从父进程那里继承来的。和我们的环境变量相同。
我们可以尝试改变我们父进程当中的环境变量,再次执行程序观察通过系统调用接口的环境变量是否改变:

本地变量
但是我们应该怎么设置环境变量呢?
通常情况下我们通过name=value的形式进行环境变量的设置。但是如果只使用这种形式进行设置环境变量的话,我们会发现在env当中查看不到我们先添加进入的环境变量。例如:

我们将这种可以被echo查看的环境变量,但是不能被env指令查看的环境变量叫做本地变量。由于我们子进程继承的环境变量是和env当中的环境变量相一致的。所以我们新设置的环境变量是父进程所特殊的,并不会被子进程继承。
export添加环境变量
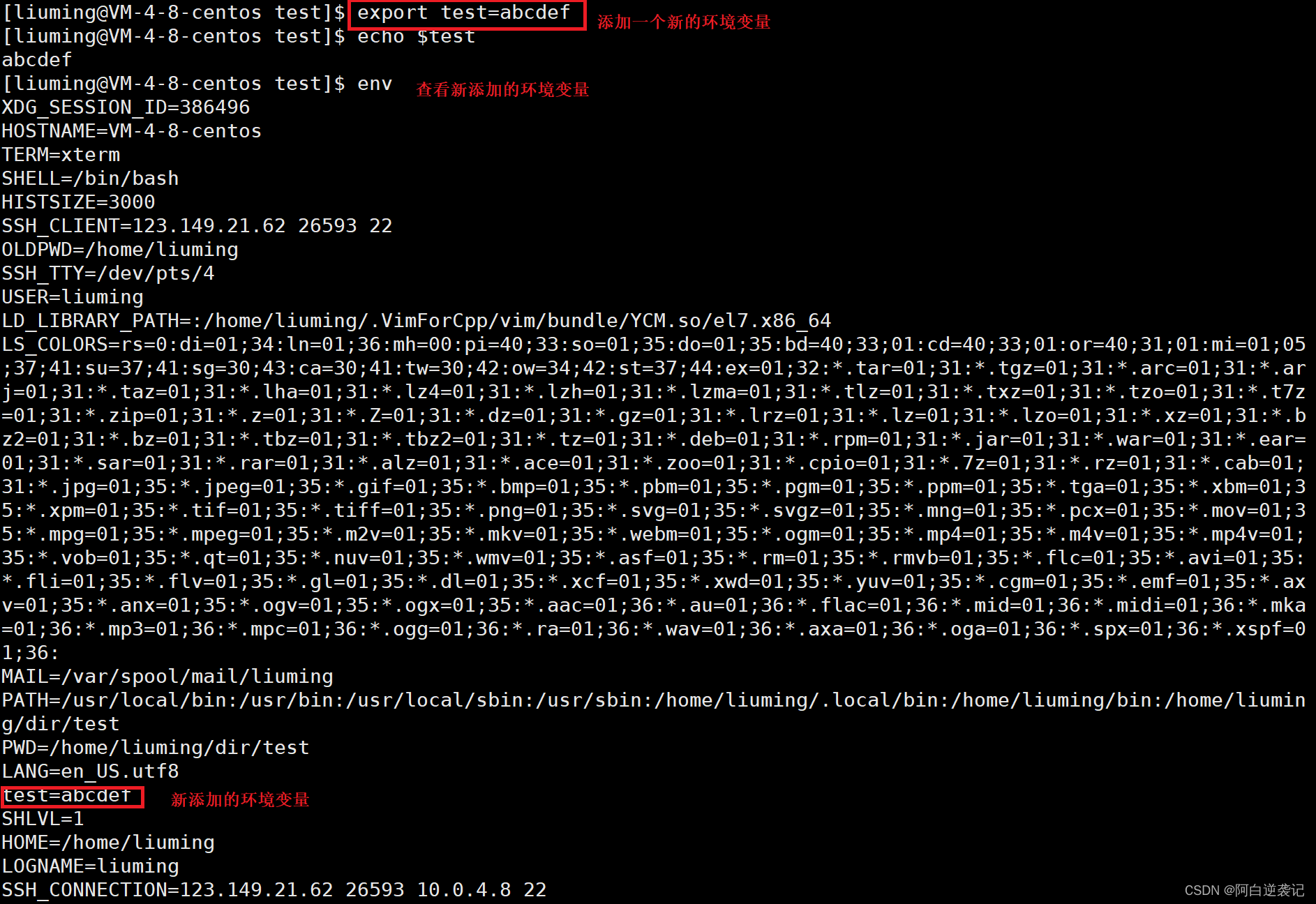
如果想要添加新的可以被子进程继承的环境变量我们需要在添加的时候补上一个export例如:
unset删除环境变量
有添加就会有删除,我们可以通过unset命令删除指定的环境变量:
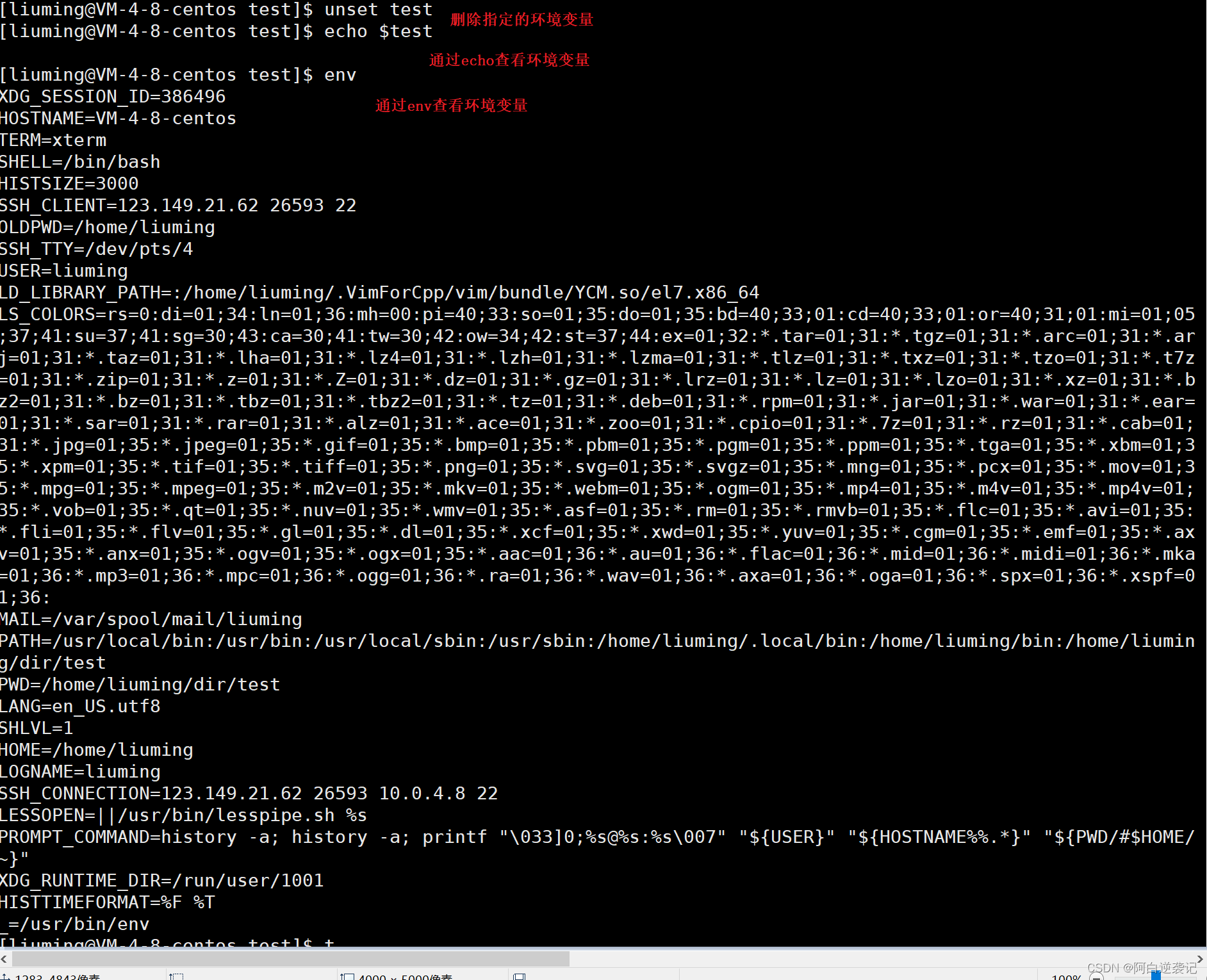
在调用unset命令之后直接跟环境变量名即可删除指定的环境变量。删除之后的环境变量无论是通过echo命令还是通过env命令查看都查看不到。






![2023年中国车载导航仪产量、销量及市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/7324d13d72e7d14cffdb8762145838f1.png)