文章目录
- 🌟介绍一波
- 🌟小安装
- 🌟配置环境变量
- ⭐️tesseract-ocr配置
- ⭐️tessdata语言配置
- ⭐️检测环境变量是否安装成功
- 🌟语言包的配置使用
- 🌟CMD命令框中进行图片识别操作
- ⭐️举例一:识别数字
- ⭐️举例二:识别文字
- 🌟pycharm中进行图片识别操作
- ⭐️举例一:识别文字
- 🌟唠唠问题
🌟介绍一波
Tesseract-OCR 是一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎。与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
(别问我咋知道,百度一下,你就知道😛)
🌟小安装
- 安装Tesseract-OCR(64位的安装包链接)
tesseract-ocr-setup-4.00.00dev.exe - tesseract各种语言集合包
tesseract各种语言集合包
🌟配置环境变量
⭐️tesseract-ocr配置
-
下载 tesseract-ocr-setup-4.00.00dev.exe 完成后,对tesseract-ocr进行安装,找到tesseract.exe所在的文件路径,复制该文件所在的路径。
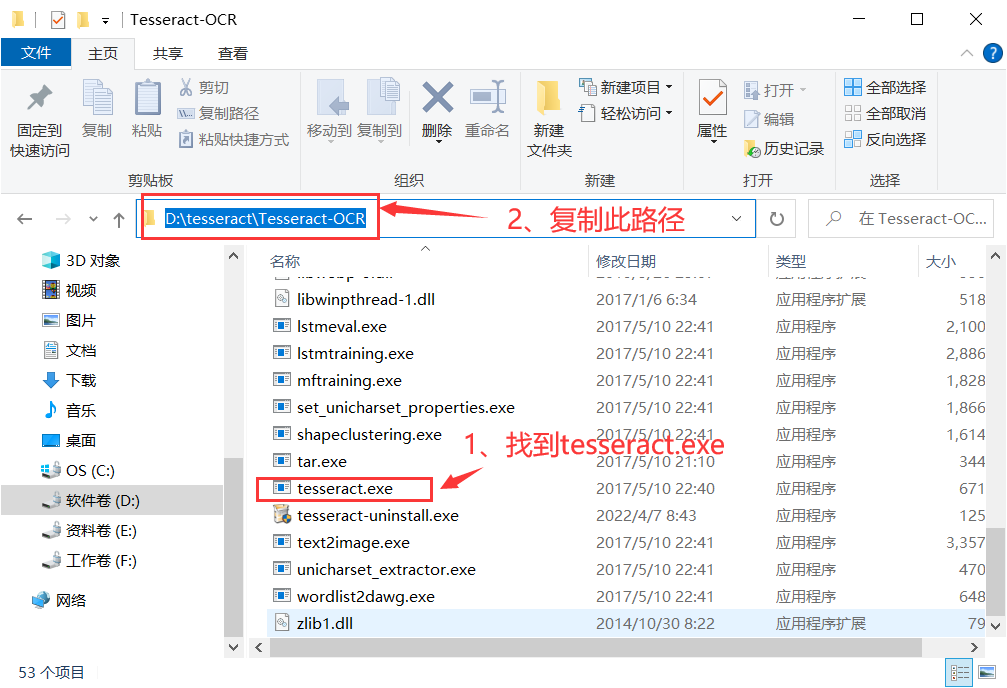
-
打开环境变量:打开控制面板——>输入“环境”,回车——>点击“编辑系统环境变量”——>点击“环境变量”。
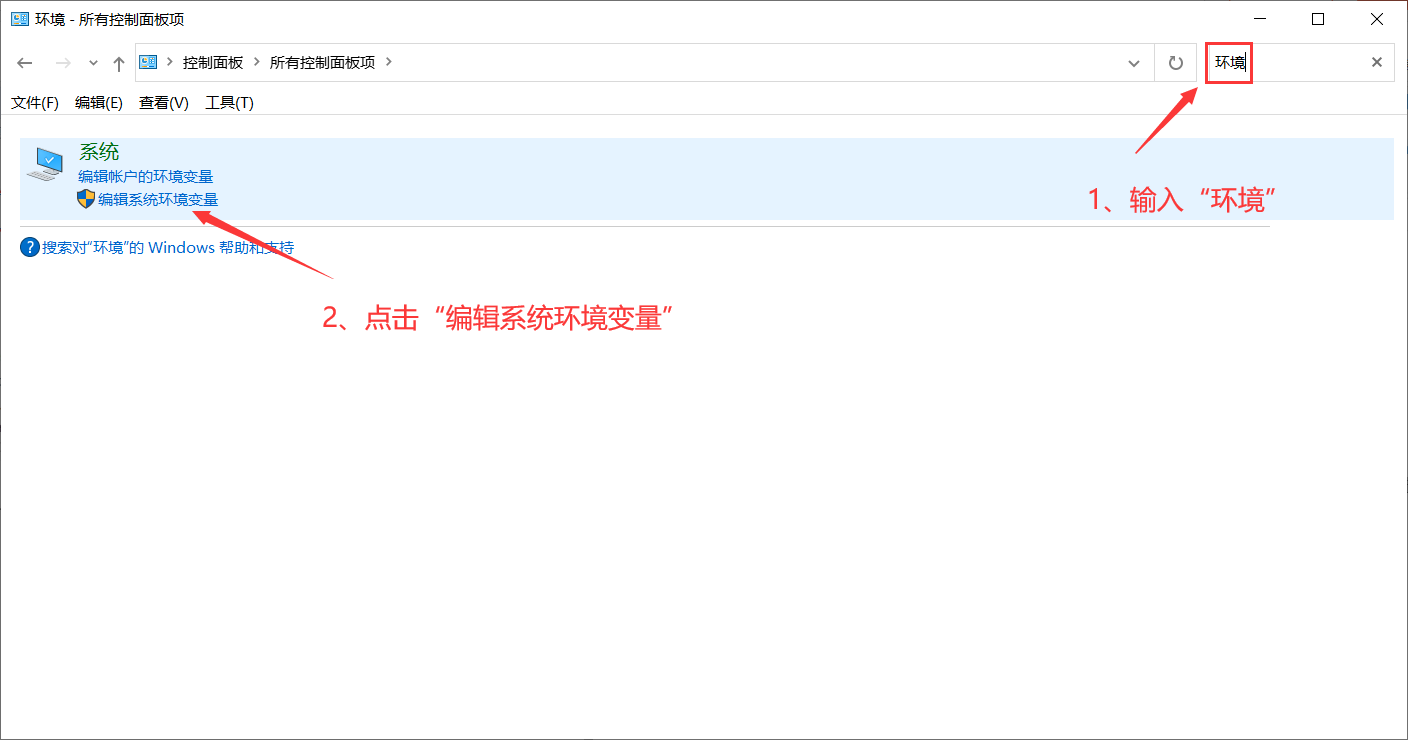
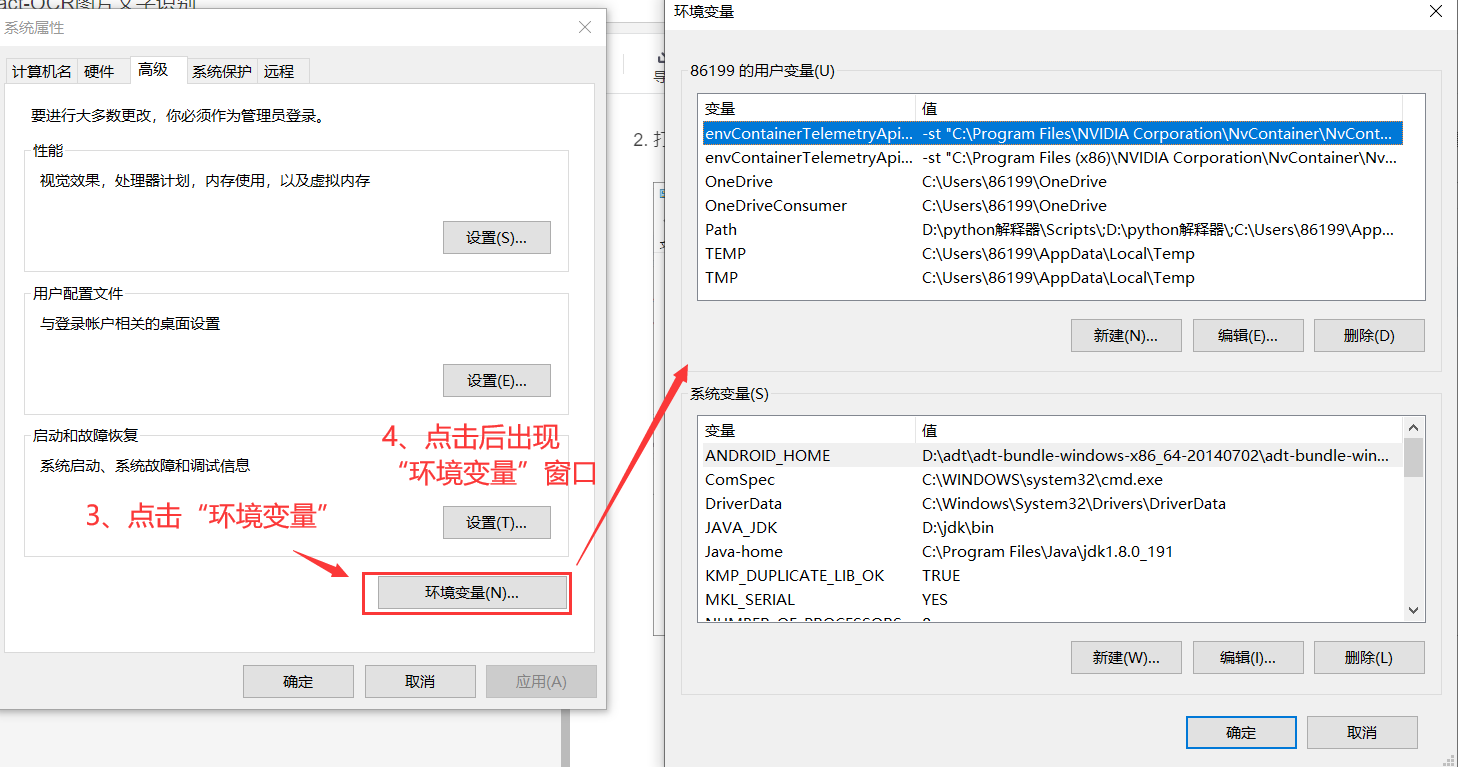
3、在用户变量和系统变量的Path中分别粘贴之前复制的路径,最后一直点击“确定”即可。
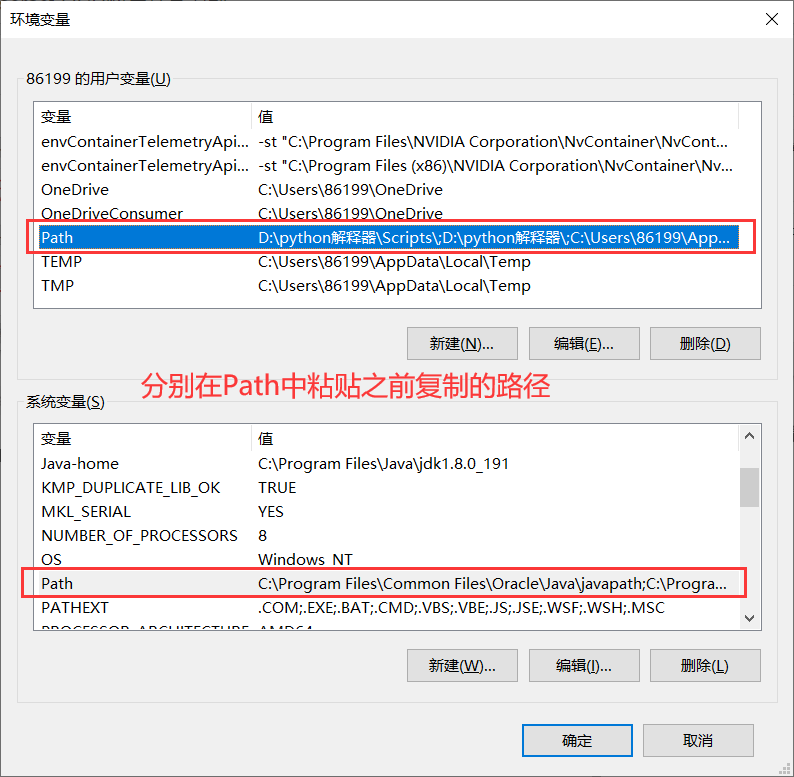
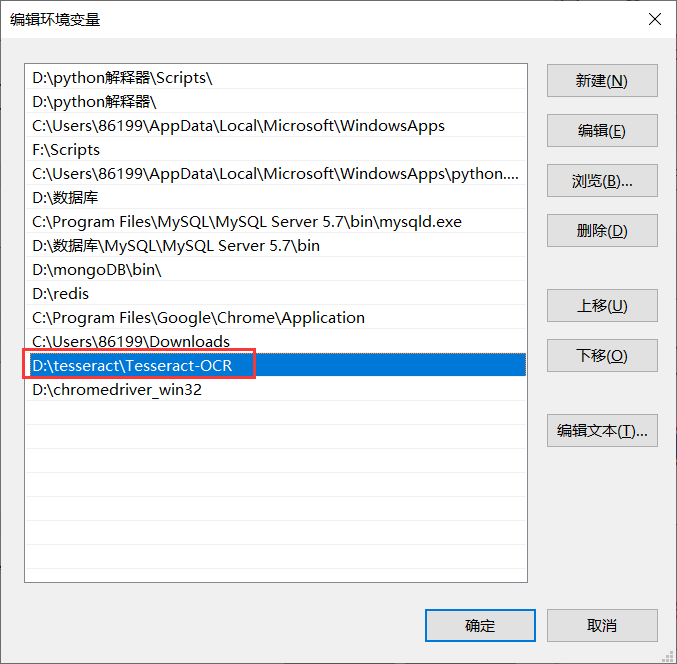
⭐️tessdata语言配置
- 在Tesseract-OCR的文件夹中找到tessdata文件夹并进入(此文件夹中包含的是各种语言包,提供识别功能)并复制此路径。
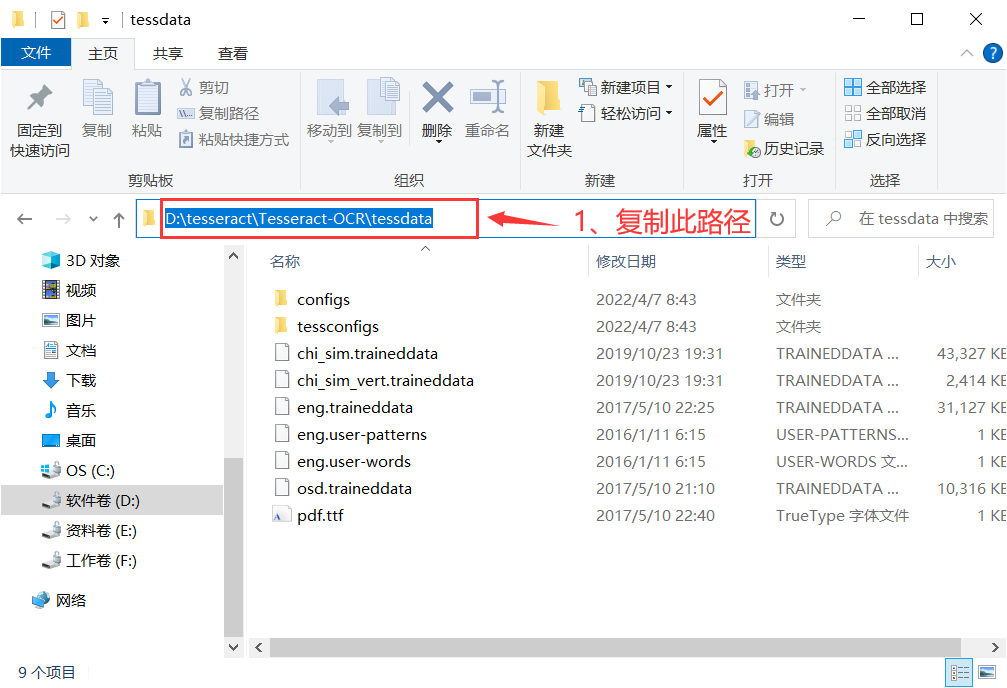
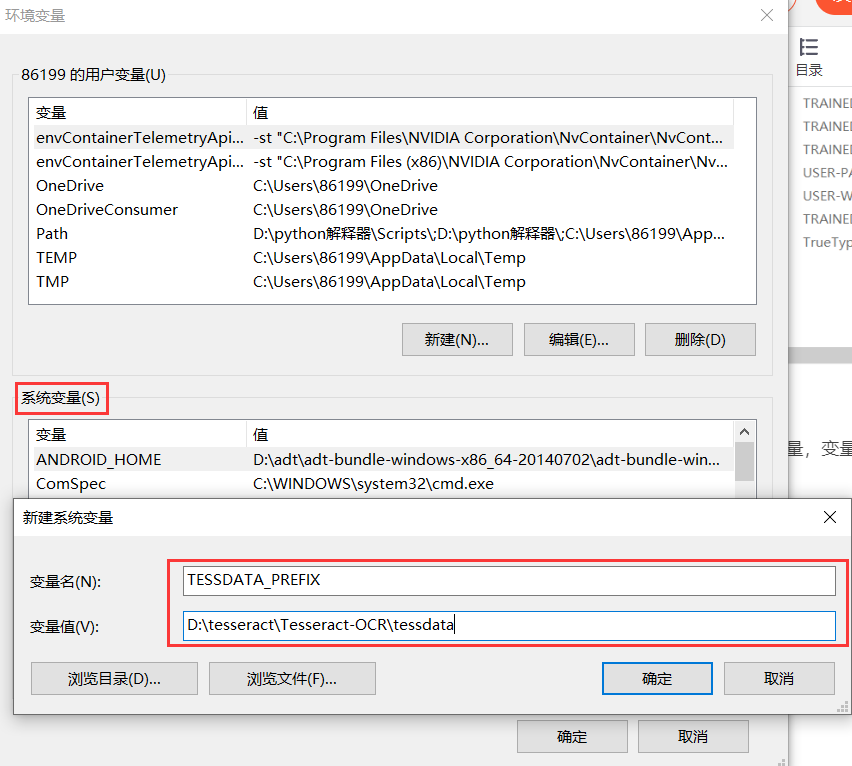
- 打开环境变量(以上已有,不再赘述),在系统变量中点击新建,添加一个系统变量,变量名为TESSDATA_PREFIX,变量值为tessdata文件夹的路径。
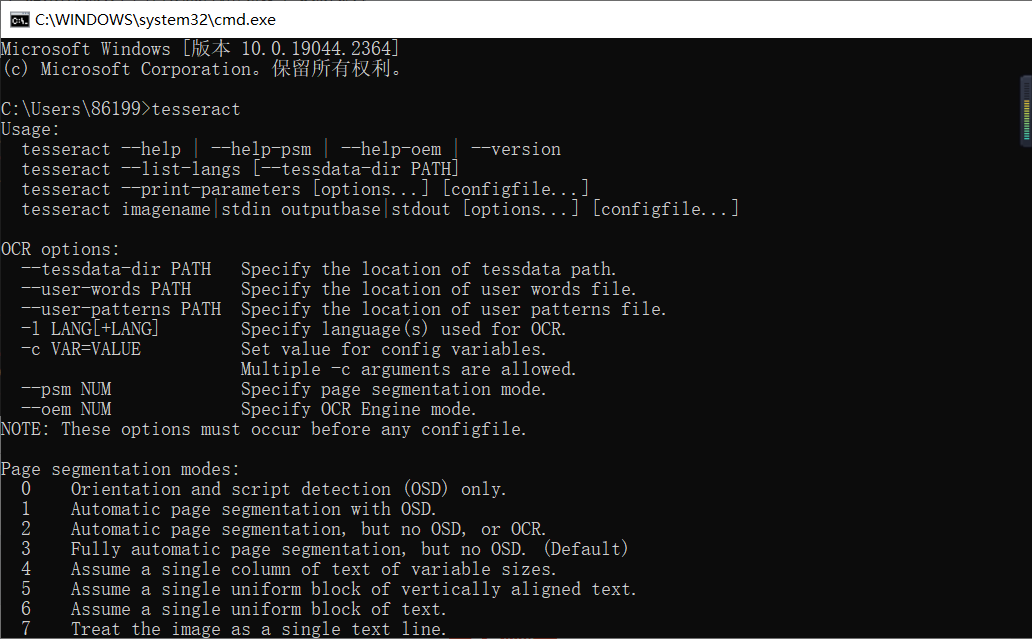
⭐️检测环境变量是否安装成功
👉打开cmd命令框并输入tesseract后回车,如果出现以下内容则表示环境变量安装成功。
🌟语言包的配置使用
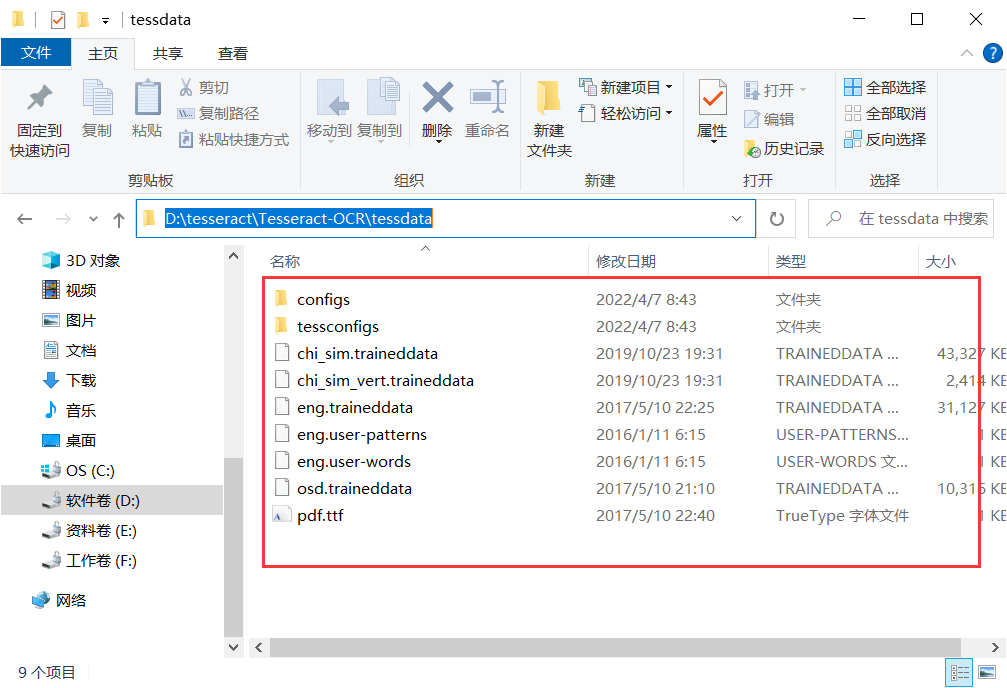
下载好tessdata各语言集合包并解压后点击进入文件,即可看见里面有很多语言包(chi_sim是中文识别包,equ是数学公式包,eng是英文包 ),可将对应的语言包复制并粘贴到Tesseract-OCR的文件夹下的tessdata文件夹中。
🌟CMD命令框中进行图片识别操作
- 在CMD中进入所要识别图片的路径。
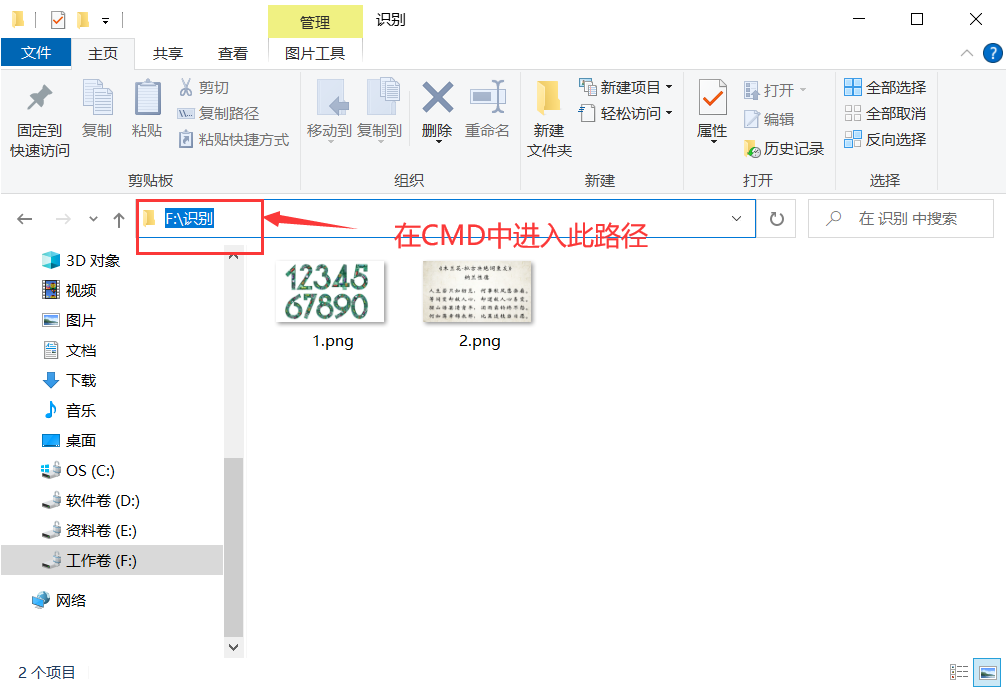
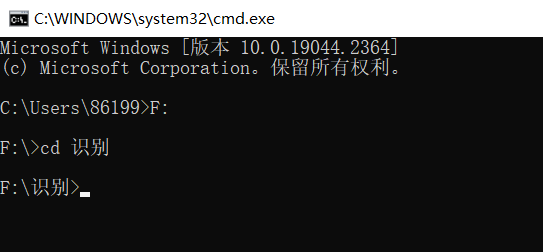
⭐️举例一:识别数字
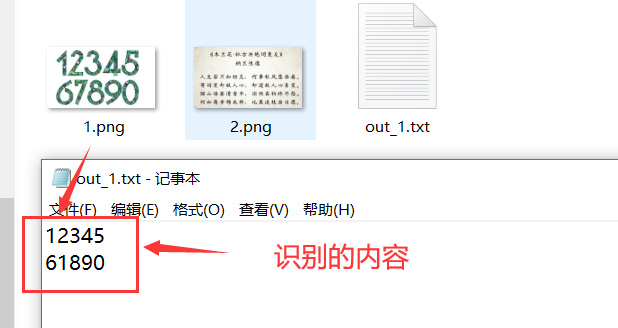
命令(举例):tesseract 1.png out_1 -1 eng
1.png:图片名称
out_1:识别后形成的文本文件名称
-l:不是数字1,而是字母L的小写
eng:识别的是数字或英文

- 这时则在图片路径下生成一个名为out_1的文本文件,文件中写入的是识别的内容。
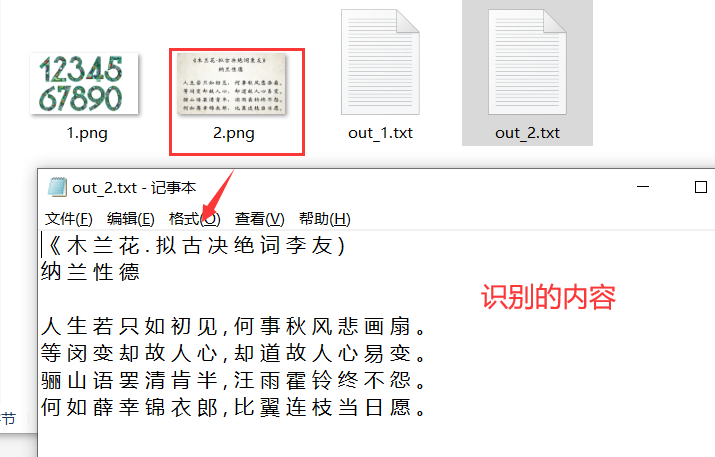
⭐️举例二:识别文字

🌟pycharm中进行图片识别操作
- 需要下载的模块:
pip install PIL
pip install pytesseract
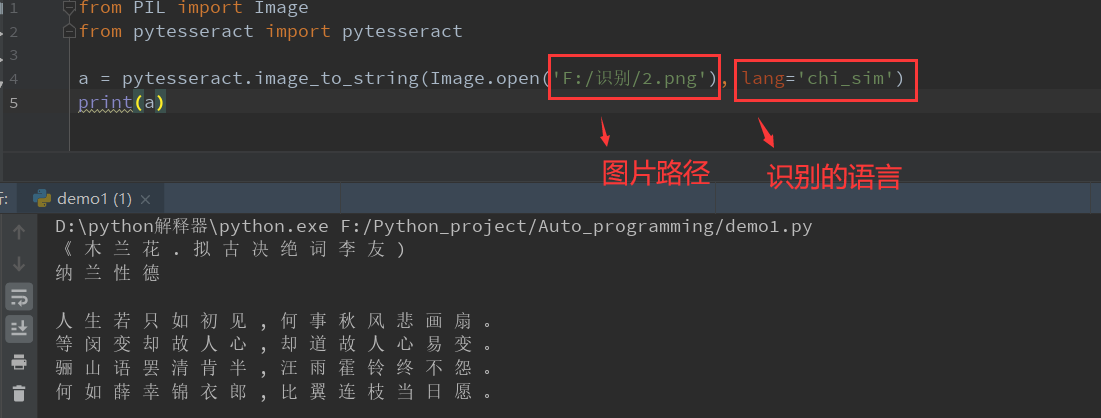
⭐️举例一:识别文字
from PIL import Image
from pytesseract import pytesseract
a = pytesseract.image_to_string(Image.open('F:/识别/2.png'), lang='chi_sim')
print(a)
🌟唠唠问题
大家可以发现👀,使用Tesseract-OCR进行图片文字识别时会出现识别错误的情况,也就是识别精度较低。当我们想识别文字较多,内容较为复杂的图片时,就很难识别出来了,这可咋办?
莫慌莫慌,想要知道如何解决,请听下回分解😜