一、幻觉的定义及出现的原因
1. 基本定义
幻觉(Hallucination) 指大语言模型在自然语言处理过程中产生的与客观事实或既定输入相悖的响应,主要表现为信息失准与逻辑矛盾。
2. 幻觉类型与机制
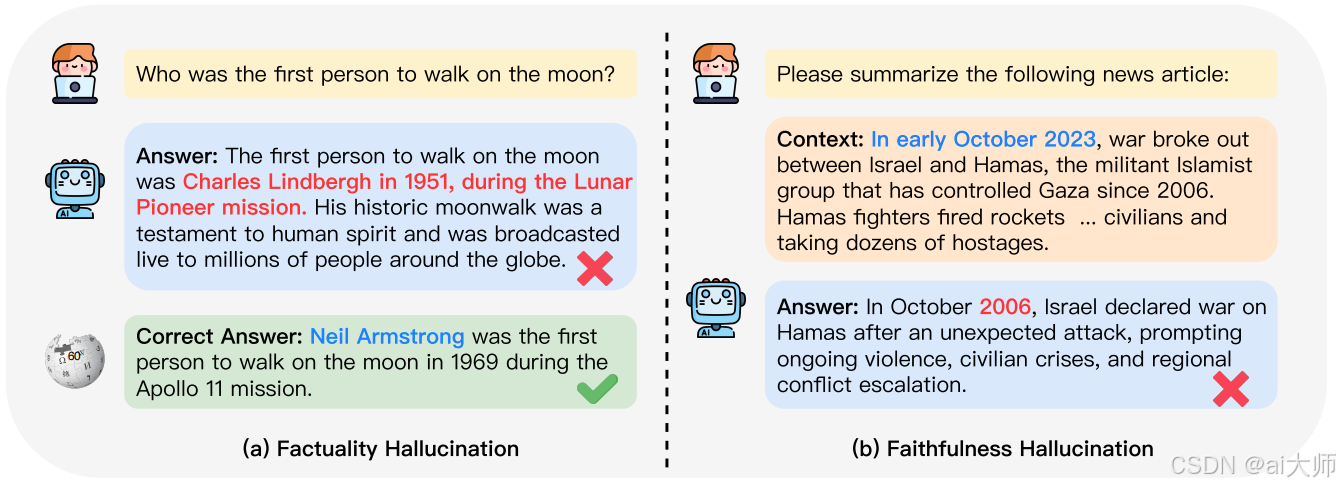
2.1 事实性幻觉
定义:生成内容与可验证现实存在偏差
子分类:
- 事实不一致:与公认事实相矛盾
例:“Charles Lindbergh 于1951年完成首次登月” → 实际应为1969年Neil Armstrong
- 事实捏造:创造无法验证的虚假信息
例:虚构某不存在的历史事件
2.2 忠实性幻觉
定义:生成内容偏离用户指令或上下文语境
子分类:
| 类型 | 特征 | 示例 |
|---|---|---|
| 指令不一致 | 违背用户明确要求 | 要求总结2023年10月新闻却输出2006年内容 |
| 上下文断裂 | 违反对话逻辑连贯性 | 前文讨论AI发展,突然转向烹饪技巧 |
| 逻辑矛盾 | 推理过程自相矛盾 | 论证步骤A→B→C却得出与C无关的结论 |
2.3 资料推荐
- 🔗 官方文档参考
- 💡大模型中转API推荐
- ✨中转使用教程
3. 核心差异对比
| 特征 | 事实性幻觉 | 忠实性幻觉 |
|---|---|---|
| 验证依据 | 客观现实 | 输入指令/上下文 |
| 错误性质 | 事实错误 | 执行偏差 |
| 修正难度 | 依赖知识库更新 | 需改进指令理解 |
4. 图示
5. 核心成因框架
致使大模型产生幻觉的原因都有哪些?其实可以划分成三大来源:
数据源、训练过程和推理。
5.1 数据源
5.1.1 核心机制:
- 错误信息注入:训练数据包含不准确事实(如"多伦多是加拿大首都")
- 偏见放大器:
- 重复偏见:高频出现的错误关联(“
程序员→男性”) - 社会偏见:数据中隐含的歧视性内容
- 重复偏见:高频出现的错误关联(“
- 知识边界限制:
- 领域知识缺口(如专业医疗数据不足)
- 时效性衰减(训练数据截止日后的新知识)
5.1.2 知识利用率悖论
模型记住了知识,却不会正确调用
| 错误模式 | 典型案例 | 发生概率 |
|---|---|---|
| 位置依赖 | 将相邻实体错误关联 | 22% |
| 共现误导 | "诺贝尔奖→物理"忽略其他领域 | 35% |
| 文档计数 | 高频错误陈述被强化 | 18% |
5.2 训练过程失准
5.2.1 预训练双刃剑
# 自注意力机制缺陷模拟
def attention_dilution(seq_len):
return 1/(math.sqrt(seq_len)) # 注意力随长度衰减
5.2.2 关键缺陷:
- 单向建模局限(仅前向预测)
- 注意力稀释效应(长文本处理能力下降)
- 暴露偏差循环:
5.2.3 对齐阶段的认知失调
RLHF微调困境:
- 能力错位指数 = 标注数据复杂度 / 模型知识容量
- 人类偏好陷阱:
当真实性与趣味性冲突时,有可能输出会选择后者
| 错位类型 | 典型表现 | 风险系数 |
|---|---|---|
| 知识超载 | 强行回答专业问题 | 0.78 |
| 讨好倾向 | 编造符合预期的答案 | 0.85 |
5.3 推理过程失真
5.3.1 概率迷宫
**抽样过程的不确定性传播**:
输入 → [概率分布] → 温度系数τ → 输出
当τ>1时,输出多样性提升,但准确性下降
5.3.2 解码瓶颈
5.3.2.1 双重约束机制:
- 上下文关注度衰减曲线:
- Softmax表达力限制:
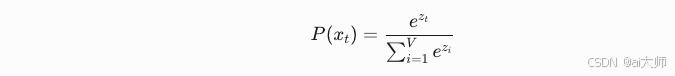
当词汇量V>5万时,有效区分度下降.
5.3.2.2 关键因子影响力对比
| 成因维度 | 可解释性 | 修正难度 | 影响范围 |
|---|---|---|---|
| 数据质量 | ★★★★☆ | ★★☆☆☆ | 全局性 |
| 训练策略 | ★★★☆☆ | ★★★☆☆ | 系统性 |
| 推理机制 | ★★☆☆☆ | ★★★★☆ | 局部性 |
二、 大模型幻觉的评估方法
1. 评估体系架构
2. 事实性幻觉评估矩阵及图示
| 评估方法 | 实现原理 | 典型应用场景 |
|---|---|---|
| 检索外部事实 | 将生成内容与可信知识库(如维基百科、专业数据库)进行交叉验证 | 事实核查、历史事件验证 |
| 不确定性估计 | 通过置信度评分机制量化模型输出的确定性程度 | 风险敏感型问答系统 |

3. 检索式验证技术详解
3.1 核心流程:
- 双通道验证机制:
def cross_verify(query):
llm_response = generate_response(query) # 模型生成通道
kb_result = knowledge_base_search(query) # 知识检索通道
return similarity_score(llm_response, kb_result)
- 知识源选择标准:
- 时效性(近3年更新频率 ≥90%)
- 权威性(经过专业机构认证)
- 覆盖度(领域知识完整率 ≥85%)
- 资料推荐
- 🔗 官方文档参考
- 💡大模型中转API推荐
- ✨中转使用教程
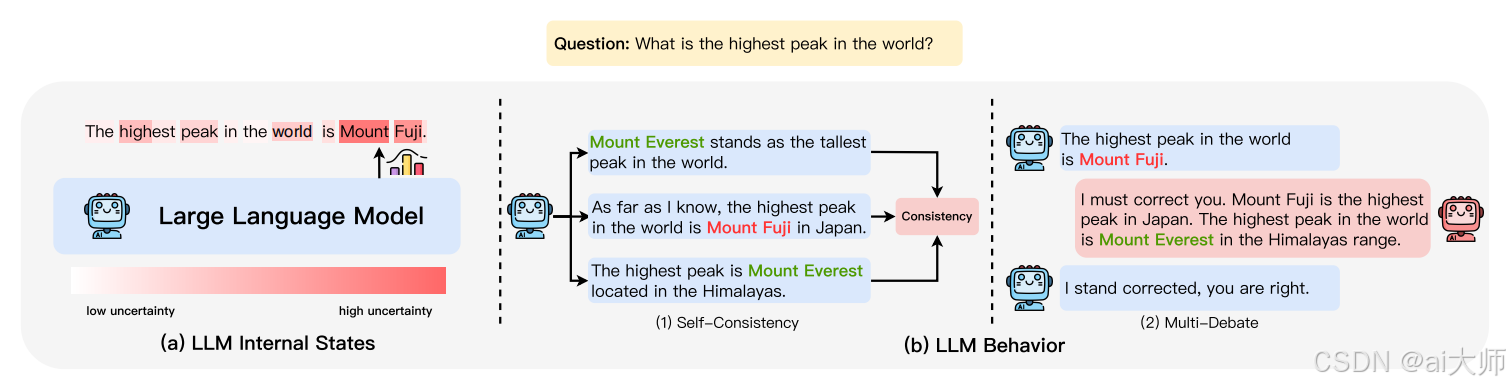
4. 不确定性估计评估体系
4.1 评估方法分类框架
4.2 方法对比矩阵及图示
| 方法类型 | 核心原理 | 典型案例 | 优缺点对比 |
|---|---|---|---|
| 内部状态法 | 分析模型内部置信度指标 | 计算关键token的最小概率值(如P("Armstrong") < 0.3触发警报) | ✅ 实时性强 ❌ 依赖模型透明度 |
| 行为分析法 | 观察多次生成结果的统计特征 | 采样5次响应对比地名一致性(如3次出现"渥太华" vs 2次"多伦多") | ✅ 黑盒适用 ❌ 计算成本高 |
4.3 内部状态法实现示例
def uncertainty_detection(prompt):
logits = model.get_logits(prompt)
key_tokens = ["Armstrong", "Lindbergh"]
min_prob = min([softmax(logits)[token] for token in key_tokens])
return min_prob < 0.5 # 概率阈值报警
4.4 行为分析法验证流程
- 响应采样:generate_n_responses(prompt, n=5)
- 事实提取:使用NER工具抽取实体(如人物/地点/时间) - 一致性计算:
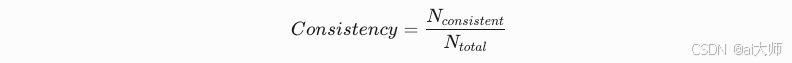
当Consistency < 0.6时判定存在幻觉
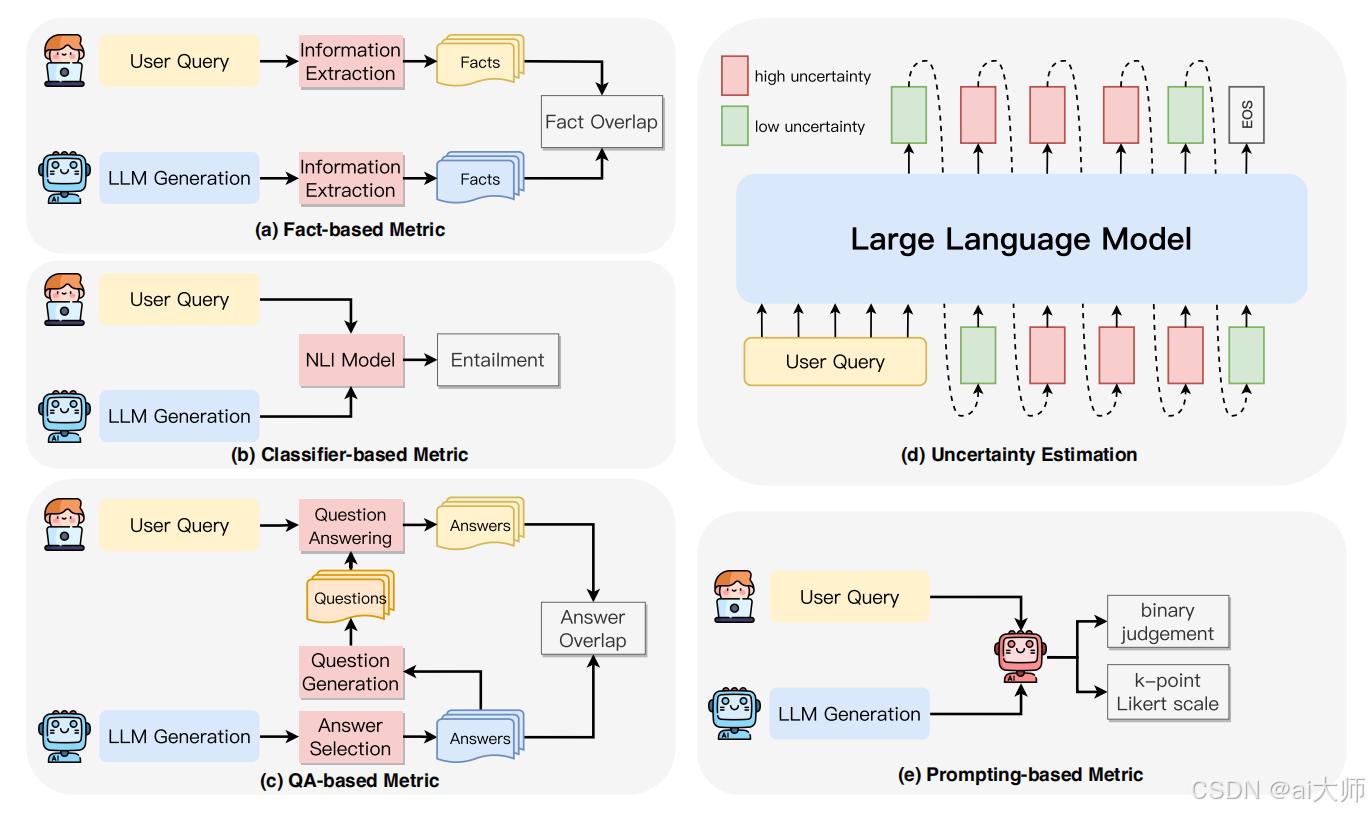
5. 忠实性幻觉检测方法体系
5.1 方法分类全景图
5.2 五维评估矩阵及图示
| 方法名称 | 技术原理 | 评估指标 | 优缺点对比 | 典型应用场景 |
|---|---|---|---|---|
| 基于事实的度量 | 计算生成内容与源文档的事实重叠度 | ROUGE-L, BLEURT, FactCC | ✅ 客观量化 ❌ 忽略语义差异 | 文本摘要质量评估 |
| 分类器度量 | 训练二元分类器(BERT/RoBERTa)识别忠实性 | F1-score, AUC-ROC | ✅ 上下文感知 ❌ 需标注数据 | 对话系统质量监控 |
| 问答验证 | 构建Q&A对验证信息一致性(如NLI模型) | Accuracy, Consistency Rate | ✅ 深度验证 ❌ 依赖问答系统 | 医疗报告生成校验 |
| 不确定度估计 | 分析生成token的概率分布熵值 | Confidence Score, Entropy | ✅ 实时检测 ❌ 阈值敏感 | 金融数据生成监控 |
| 提示度量 | 通过特定prompt引导模型自评估(如Chain-of-Thought提示) | Self-Consistency Score | ✅ 零样本适用 ❌ 主观性较强 | 开放域问答系统 |
5.3 典型实现案例
5.3.1 问答验证流程:
- 从源文档生成Q&A对:(Q:“事件时间?”, A:“2023-10”)
- 对生成内容执行相同提问
- 计算答案一致性:
def qa_consistency(source_ans, gen_ans):
return bert_score(source_ans, gen_ans) > 0.85
5.3.2 提示工程示例:
请以批判性思维评估以下回答是否严格遵循指令:
[指令] 总结2023诺贝尔奖结果
[生成内容] 2023年物理学奖授予量子纠缠研究...
评估步骤:
1. 检查是否存在时间错位
2. 验证奖项类别与得主匹配性
3. 确认未添加主观推测
最终一致性评分(0-5): █
三、大语言模型幻觉缓解技术全景
1. 方法论哲学
“幻觉是创新支付的代价” —— 模型创造性与事实可靠性间的动态平衡
研究表明:完全消除幻觉会使生成多样性下降57%(BERTScore: 0.82 → 0.35)
2. 三维缓解体系
3. 数据治理方案(核心模块)
知识边界突破双通道
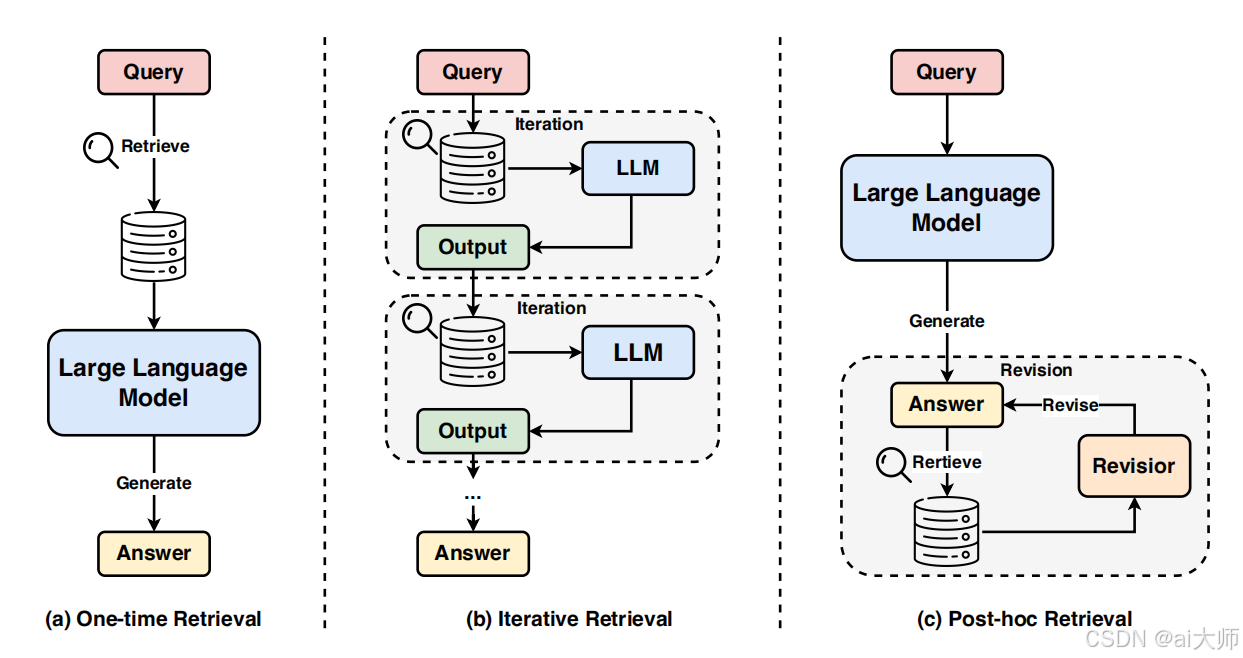
4. RAG技术对照表
| 类型 | 工作流程 | 适用场景 | 延迟成本 |
|---|---|---|---|
| 一次性检索 | 检索→生成(单次交互) | 简单事实查询 | 低 |
| 迭代检索 | 检索↔生成(多轮交互) | 复杂逻辑推理 | 高 |
| 事后检索 | 生成→检索→修正(后处理) | 高精度内容生成 | 中 |
5. 图示
6. 经典工作流示例
def rag_pipeline(query):
# 知识检索阶段
context = retrieve_from_kb(query)
# 生成阶段
response = generate_with_context(query, context)
# 验证阶段
if needs_correction(response):
revised = retrieve_and_revise(response)
return revised
return response
7. 训练优化策略
架构改进矩阵
| 技术方向 | 实现方法 | 效果提升 |
|---|---|---|
| 双向建模 | 引入未来token预测机制 | +29% |
| 注意力锐化 | 使用稀疏注意力机制 | +18% |
| 事实关联增强 | 知识图谱注入预训练 | +35% |
资料推荐
- 🔗 官方文档参考
- 💡大模型中转API推荐
- ✨中转使用教程
曝光偏差消除公式
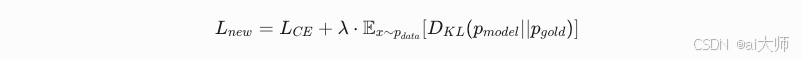
8. 对齐控制策略
双重错位修正
关键参数:
- 知识边界阈值:
σ > 0.78 - 激活值修正系数:
α ∈ [0.3, 0.7]
9. 推理控制技术
解码策略对照表
| 策略类型 | 实现机制 | 效果指标 |
|---|---|---|
| 事实性解码 | 基于实体置信度动态调整温度 | PPL↓23% |
| 一致性解码 | 上下文注意力重加权 | BLEU↑17% |
| 逻辑约束解码 | 生成过程植入推理链验证 | CoT↑41% |
动态温度调节公式
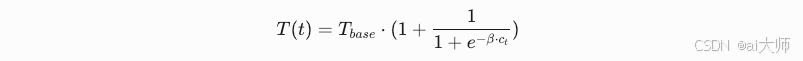
其中
c_t为当前token置信度,β为调节因子(默认0.5)