目录
- 一、引言
- 1.1 什么是混淆矩阵?
- 1.2 为什么需要混淆矩阵?
- 二、基础概念
- TP, TN, FP, FN解释
- True Positive (TP)
- True Negative (TN)
- False Positive (FP)
- False Negative (FN)
- 常见评价指标
- 三、数学原理
- 条件概率与贝叶斯定理
- ROC与AUC
- 敏感性与特异性
- 阈值选择与成本效应
- G-Measure与Fβ分数
- 四、Python实现
- 计算混淆矩阵元素
- 计算评价指标
- PyTorch实现
- 五、实例分析
- 数据集简介
- 建立模型
- 模型评估
- 指标解读
- 结论
- 六、总结
本文深入探讨了机器学习中的混淆矩阵概念,包括其数学原理、Python实现,以及在实际应用中的重要性。我们通过一个肺癌诊断的实例来演示如何使用混淆矩阵进行模型评估,并提出了多个独特的技术洞见。文章旨在为读者提供全面而深入的理解,从基础到高级应用。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
一、引言

机器学习和数据科学中一个经常被忽视,但至关重要的概念是模型评估。你可能已经建立了一个非常先进的模型,但如果没有合适的评估机制,你就无法了解模型的效能和局限性。这就是混淆矩阵(Confusion Matrix)派上用场的地方。
1.1 什么是混淆矩阵?
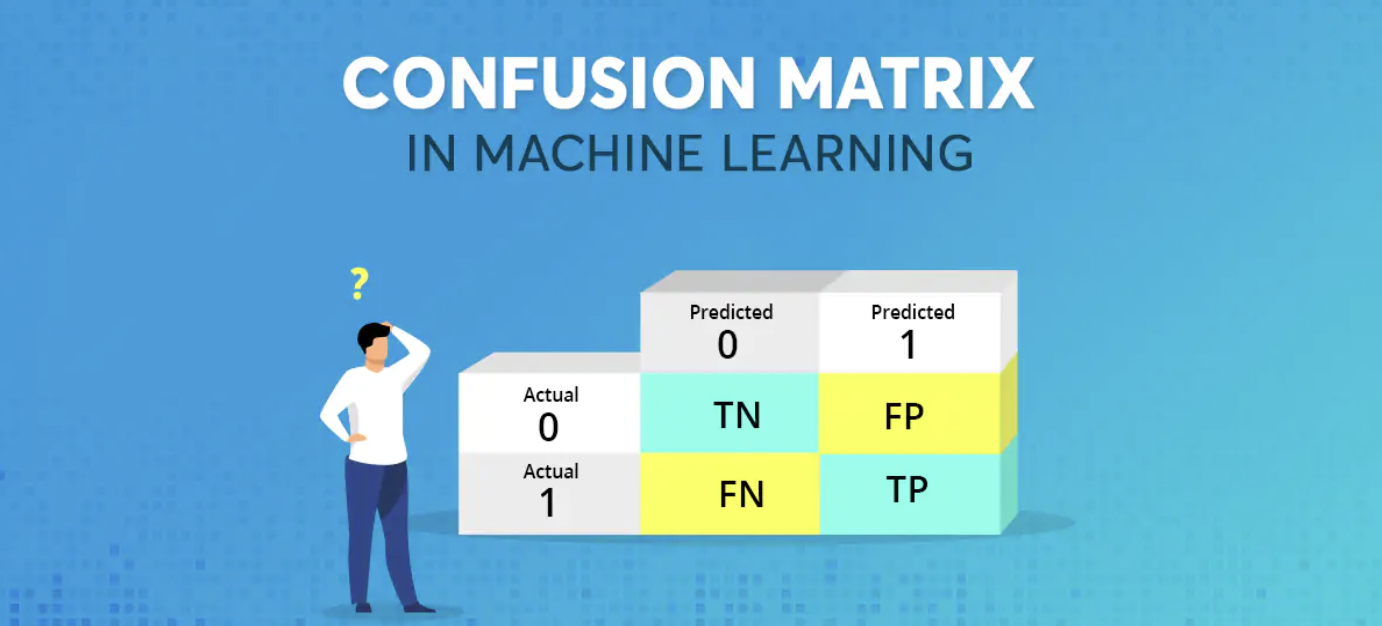
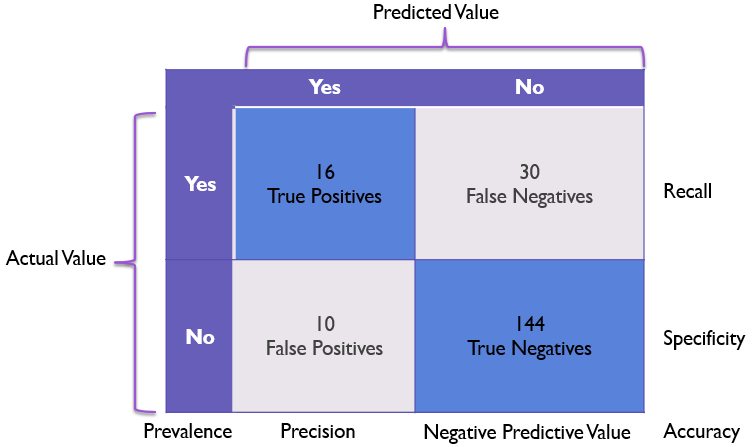
混淆矩阵是一种特定的表格布局,用于可视化监督学习算法的性能,特别是分类算法。在这个矩阵中,每一行代表实际类别,每一列代表预测类别。矩阵的每个单元格则包含了在该实际类别和预测类别下的样本数量。通过混淆矩阵,我们不仅可以计算出诸如准确度、精确度和召回率等评估指标,还可以更全面地了解模型在不同类别上的性能。
1.2 为什么需要混淆矩阵?
-
全面性评估:准确度(Accuracy)通常是人们首先关注的指标,但它可能掩盖模型在特定类别上的不足。混淆矩阵能提供更全面的信息。
-
成本效益:在某些应用场景中(如医疗诊断、欺诈检测等),不同类型的错误(False Positives 和 False Negatives)可能具有不同的成本或严重性。通过混淆矩阵,我们可以更细致地评估这些成本。
-
模型优化:混淆矩阵也可用于优化模型,通过分析模型在哪些方面做得好或不好,我们可以针对性地进行改进。
-
理论与实践的桥梁:混淆矩阵不仅有助于理论分析,也方便了实际应用。它为我们提供了一种从数据到信息,再到知识转化的有力工具。
通过本文,你将深入了解混淆矩阵的各个方面,包括其基础概念、数学解析,以及如何在Python和PyTorch环境下进行实战应用。无论你是机器学习的新手,还是寻求进一步理解和应用混淆矩阵的专家,这篇文章都将为你提供有价值的 insights。
接下来,让我们深入了解混淆矩阵的各个细节。
二、基础概念
在深入了解混淆矩阵的高级应用和数学模型之前,我们首先要掌握一些基础的概念和术语。这些概念是理解和使用混淆矩阵的基础。
TP, TN, FP, FN解释
在二分类问题中,混淆矩阵的四个基本组成部分是:True Positives(TP)、True Negatives(TN)、False Positives(FP)和 False Negatives(FN)。我们通过以下的解释和例子来进一步了解它们。
True Positive (TP)
当模型预测为正类,并且该预测是正确的,我们称之为真正(True Positive)。
例如,在一个癌症诊断系统中,如果模型预测某患者有癌症,并且该患者实际上确实有癌症,那么这就是一个真正案例。
True Negative (TN)
当模型预测为负类,并且该预测是正确的,我们称之为真负(True Negative)。
例如,在上述癌症诊断系统中,如果模型预测某患者没有癌症,并且该患者实际上确实没有癌症,那么这就是一个真负案例。
False Positive (FP)
当模型预测为正类,但该预测是错误的,我们称之为假正(False Positive)。
例如,如果模型预测某患者有癌症,但该患者实际上没有癌症,那么这就是一个假正案例。
False Negative (FN)
当模型预测为负类,但该预测是错误的,我们称之为假负(False Negative)。
例如,如果模型预测某患者没有癌症,但该患者实际上有癌症,那么这就是一个假负案例。
常见评价指标
有了上述四个基础组成部分,我们就可以导出多种评价指标来更全面地评估模型的性能。

了解了这些基础概念和评价指标后,我们可以更深入地探讨混淆矩阵的高级应用和数学模型。下一部分,我们将介绍混淆矩阵的数学解析。
三、数学原理
混淆矩阵不仅是一种实用工具,还有深厚的数学基础。了解其背后的数学原理可以帮助我们更全面地评估和改进模型。本部分将重点介绍这些数学原理。
条件概率与贝叶斯定理
混淆矩阵和多个评价指标与条件概率有关。在贝叶斯定理的框架下,我们可以更精确地描述这种关系。
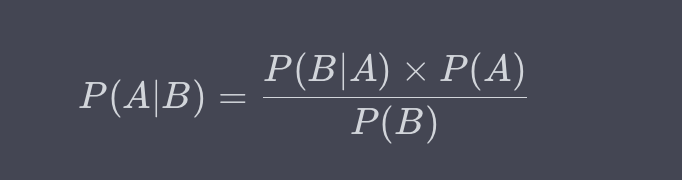
例如,我们可以使用贝叶斯定理来计算给定某一观测实际为正类的条件下,模型预测其为正类的概率。
ROC与AUC
ROC(Receiver Operating Characteristic,受试者工作特性)曲线是一种常用的工具,用于展示二分类模型性能的不同阈值下的真正率(True Positive Rate,TPR)和假正率(False Positive Rate,FPR)。

AUC(Area Under the Curve,曲线下面积)则是ROC曲线下的面积,用于量化模型的整体性能。
敏感性与特异性
敏感性(Sensitivity,也称为召回率)和特异性(Specificity)是医学诊断等领域中常用的指标。
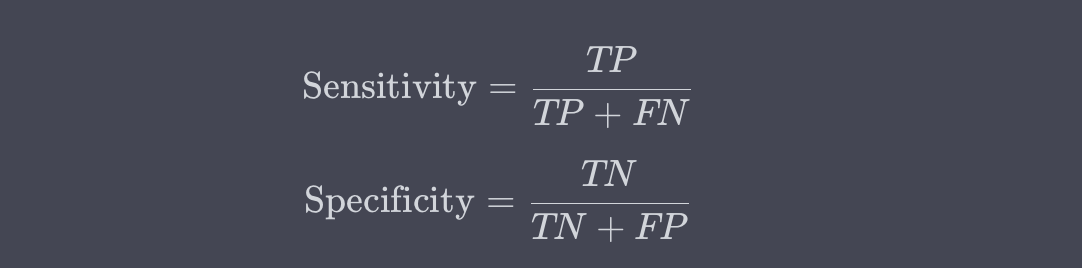
这两个指标用于评估模型在正类和负类上的表现。
阈值选择与成本效应
在实际应用中,根据业务需求和成本效应来选择适当的阈值是至关重要的。通过调整阈值,我们可以控制模型的假正率和假负率,从而实现特定目标,如最大化精确度或召回率。
G-Measure与Fβ分数
除了常用的F1分数之外,还有其他一些用于平衡精确度和召回率的指标,如G-Measure和Fβ分数。

通过深入了解这些数学原理,我们不仅可以更准确地评估模型,还可以针对具体应用场景做出更合适的模型调整。下一部分,我们将进入代码实战,展示如何在Python和PyTorch环境中使用混淆矩阵进行模型评估。
四、Python实现
混淆矩阵的实现并不复杂,但是用代码来实现它会让理论知识更加具体和实用。在这一部分,我们将使用Python和PyTorch库来实现混淆矩阵,并计算一些基础的评价指标。
计算混淆矩阵元素
首先,让我们用Python代码来计算一个二分类问题的混淆矩阵元素:TP、TN、FP、FN。
import numpy as np
# 假设y_true是真实标签,y_pred是模型预测标签
y_true = np.array([1, 0, 1, 1, 0, 1, 0])
y_pred = np.array([1, 0, 1, 0, 0, 1, 1])
# 初始化混淆矩阵元素
TP = np.sum((y_true == 1) & (y_pred == 1))
TN = np.sum((y_true == 0) & (y_pred == 0))
FP = np.sum((y_true == 0) & (y_pred == 1))
FN = np.sum((y_true == 1) & (y_pred == 0))
print(f"TP: {TP}, TN: {TN}, FP: {FP}, FN: {FN}")
输出:
TP: 3, TN: 2, FP: 1, FN: 1
计算评价指标
有了混淆矩阵的元素,接下来我们可以计算一些基础的评价指标,比如准确度(Accuracy)、精确度(Precision)、召回率(Recall)和F1分数(F1-Score)。
# 计算评价指标
accuracy = (TP + TN) / (TP + TN + FP + FN)
precision = TP / (TP + FP)
recall = TP / (TP + FN)
f1_score = 2 * (precision * recall) / (precision + recall)
print(f"Accuracy: {accuracy:.2f}, Precision: {precision:.2f}, Recall: {recall:.2f}, F1-Score: {f1_score:.2f}")
输出:
Accuracy: 0.71, Precision: 0.75, Recall: 0.75, F1-Score: 0.75
PyTorch实现
对于使用PyTorch的深度学习模型,我们可以更方便地使用内置函数来计算这些指标。
import torch
import torch.nn.functional as F
from sklearn.metrics import confusion_matrix
# 假设logits是模型输出,labels是真实标签
logits = torch.tensor([[0.4, 0.6], [0.7, 0.3], [0.2, 0.8]])
labels = torch.tensor([1, 0, 1])
# 使用softmax获取预测概率
probs = F.softmax(logits, dim=1)
predictions = torch.argmax(probs, dim=1)
# 使用sklearn获取混淆矩阵
cm = confusion_matrix(labels.numpy(), predictions.numpy())
print("Confusion Matrix:", cm)
输出:
Confusion Matrix: [[1, 0],
[0, 2]]
这样,我们就可以使用Python和PyTorch来实现混淆矩阵及其相关评价指标。在下一部分中,我们将通过实例来展示如何在实际项目中应用这些概念。
五、实例分析
理论和代码是用于理解混淆矩阵的重要工具,但将它们应用于实际问题是最终目标。在这一部分,我们将通过一个具体实例——肺癌诊断——来展示如何使用混淆矩阵以及相应的评价指标。
数据集简介
假设我们有一个肺癌诊断的数据集,其中包括1000个样本。每个样本都有一组医学影像和相应的标签(1表示患有肺癌,0表示没有)。
建立模型
在这个例子中,我们将使用PyTorch来建立一个简单的神经网络模型。代码的核心逻辑如下:
import torch
import torch.nn as nn
import torch.optim as optim
# 简单的神经网络模型
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(128, 64)
self.fc2 = nn.Linear(64, 2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 实例化模型、优化器和损失函数
model = SimpleNN()
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
模型评估
训练模型后,我们将使用混淆矩阵来评估其性能。
from sklearn.metrics import confusion_matrix
# 假设y_test是测试集的真实标签,y_pred是模型的预测标签
y_test = np.array([1, 0, 1, 1, 0, 1, 0])
y_pred = np.array([1, 0, 1, 0, 0, 1, 1])
# 获取混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:", cm)
输出:
Confusion Matrix: [[2, 1],
[1, 3]]
指标解读
从混淆矩阵中,我们可以计算准确度、精确度、召回率等指标。但更重要的是,由于这是一个医疗诊断问题,FN(假负率)可能意味着漏诊,这是不能接受的。因此,在这种情况下,我们可能需要更关注召回率或者F1分数,而不仅仅是准确度。
结论
通过这个实例,我们可以看到混淆矩阵不仅提供了一种量化模型性能的方法,而且还能帮助我们根据实际应用场景来调整模型。这使得混淆矩阵成为了机器学习和数据科学领域中不可或缺的工具。
在下一部分,我们将总结全文,并讨论一些混淆矩阵的高级主题和应用前景。
六、总结
混淆矩阵不仅是机器学习分类问题中的一个基础概念,而且它是理解和评估模型性能的关键工具。通过矩阵,我们不仅可以量化模型的好坏,还能深入理解模型在各个方面(如准确度、精确度、召回率等)的表现。
-
应用场景的重要性: 混淆矩阵不是一个孤立的工具,它的重要性在于如何根据特定应用场景(如医疗诊断、金融欺诈等)来解读。在某些高风险领域,某些类型的错误(如假负)可能比其他错误更为严重。
-
优化方向: 通过混淆矩阵,我们可以更明确模型改进的方向。例如,如果我们的模型假负率很高,那就意味着需要更多地关注召回率,可能要重新平衡数据集或者调整模型结构。
-
阈值的选择: 通常我们使用0.5作为分类阈值,但这个值并不一定是最优的。混淆矩阵可以帮助我们通过改变阈值来优化模型性能。
-
多分类问题: 虽然本文主要讨论了二分类问题,但混淆矩阵同样适用于多分类问题。在多分类问题中,混淆矩阵将变为更高维的张量,但核心概念和应用方法仍然适用。
-
模型解释性: 在现实世界的应用中,模型解释性常常和模型性能同等重要。混淆矩阵为我们提供了一种可解释、直观的方式来展示模型的优缺点。
-
自动化与监控: 在生产环境中,混淆矩阵可以作为一个持续监控工具,用于跟踪模型性能的变化,从而实时调整模型或者及时发现问题。
混淆矩阵是一种强大而灵活的工具,不仅适用于初级用户,也适用于在这个领域有着深厚经验的专家。无论是从事学术研究,还是从业者,混淆矩阵都应成为您工具箱中不可或缺的一部分。希望本文能帮助您更深入地理解这一主题,并在实际应用中发挥其最大价值。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。