前言
最近有些实践,因为后面要去研究fine-tune了,想着记录一下chatgpt+向量数据库构建知识库的一些实操经验,不记我很快就忘了,哈哈。
首先,提一下为啥会出现向量数据库这个技术方案?
大家经过实践发现,如果通过简单的prompt与ChatGPT聊一下专业领域或实时性比较强的内容时,效果是很差的,比如公司有广告投放的业务,我们就需要一批同学去研究不同平台的广告投放文档,这些API文档实时性比较强,你让ChatGPT直接去生成代码,效果就很差。
为了让效果好一点,我们可以将页面的所有内容都复制出来,放到prompt中,类似于:
context:
{document content}
please base the context generate xxxx code use python.我们将最新的内容放到prompt中,ChatGPT就会基于最新的内容去生成代码了,类似的方式,我们可以将公司内部的文档放到prompt中,让ChatGPT基于文档内容回答。
但,ChatGPT有Tokens数量限制,我常用的GPT-3.5-16k,就是有16k的tokens限制,即单次request+response的tokens数不能超过16k,超过则会报错,所以如果文档内容稍微多一点,就无法全丢到prompt中。
目前的折中的解决方案就是使用向量数据库,其原理就是对文本进行embed后,再进行相似度运算。
关于embeddings原理,网上内容很多,我就不费篇章了,推荐一篇比较系统讲embed的文章:https://www.featureform.com/post/the-definitive-guide-to-embeddings
向量数据库基本使用
比较火的例子就是让ChatGPT基于你的PDF文件来聊天,这里的PDF文件可以有多个,比如100个PDF,那变通一下,就可以基于这套来构建公司的知识库。
我找了一张图,来自视频:https://www.youtube.com/watch?v=TLf90ipMzfE
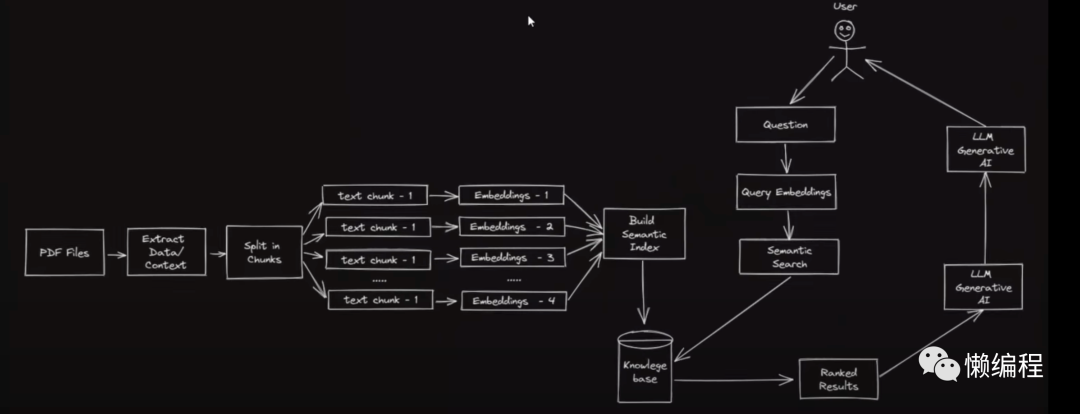
我简单描述一下:
首先要做预处理:
1.你需要将所有的PDF中的内容都抽成纯文档,如果PDF中是不可编辑的图片,你就需要使用OCR来获得内容。
2.获得纯文本后,你需要对文本进行切块,太多内容放在一起生成一个embed vector(嵌入向量)效果是不好的。
3.存入向量数据库
当用户提问时,定义问题为A,首先会将问题A通过同样的embed model转成embed vector,然后再计算问题A的embed vector与之前所有PDF生成的一系列embed vector的相似度(你可以用余弦来算,也可以用其他计算向量距离的算法来算)。
计算后,会获得当前PDF中与问题A最相近的内容(向量在空间上距离最近的),然后将这部分PDF内容和问题A一同输入给ChatGPT,其实就是为ChatGPT提供了上下文,让ChatGPT基于上下文回答。
一些细节:
Q:为何太多内容一起生成一个embed vector效果不好?
A:理论上是,内容多时,一般意思就多(信息多),此时对embed vector做相似计算时,获得一堆意思很多的内容给ChatGPT,生成的效果也是比较差的,我们做向量相似度计算的目的就是将与用户提问最相关的内容找出来,如果你每次都找出一大段的内容,效果就不好,所以这里可以引入很明显的优化点:做好数据的合理切块。
Q:具体要怎么计算相似度?内容那么多,代码上有没有轮子可以用?
A:一般不自己计算,而是交给向量数据库,通过SQL或相应的方法直接查询结果,向量数据库底层会帮你做向量相似度的计算。
上面整个流程其实在langchain文档中都给了具体的代码,30行左右的代码:https://colab.research.google.com/drive/181BSOH6KF_1o2lFG8DQ6eJd2MZyiSBNt?usp=sharing
当然熟练了上面的代码后,你会发现langchain给我们提供了RetrieverQA这个类,它做的就是将上面的过程再简化,5行左右的代码搞定基于文档的简单问答系统,详情:https://python.langchain.com/docs/use_cases/question_answering/vector_db_qa
一些问题
我实操了一些项目,通过这20行代码已经可以实现基本的知识库了,但深入使用后,还是会感到有点不足:
1.准确度有时比较低
2.会发散回答一些无关的内容
2个问题都无法100%解决,因为这不是工程问题,而是因为GPT模型本身的基底是概率性质的,但实践后,确实有一些改进方法。
过发散问题
首先说一些GPT发散回答的问题,最基本的改进方法就是在prompt中强调不要发散回答,要严格基于提供的上下文回答,如果上下文没有相关的内容,则回答不知道,例如:
# Context
{content from vector database}
# Requirements:
- 1. Before responding, please assess whether you have sufficient Context knowledge to answer the question. If you cannot answer, please reply directly with: "I'm sorry, I cannot answer your question."
- 2. Respond to questions using the provided Context knowledge.。
# Question:
{question}进一步,就需要自己再做一层工程过滤,比如收集相关的问题,训练一个二分类模型,参考分类垃圾邮件相关的算法就好了。
准确度问题
关于准确度的问题,简单思索会发现有2个方面会影响最终生成内容的准确度:
1.数据预处理
2.embed算法和相似度算法
数据预处理
经过实践,发现数据做好预处理,准确度确实有所改进。
我有个项目,是做代码文档知识库的,这是为我个人打造的,场景是:我需要使用新的技术解决方案时,比如我要学openai怎么用,我就希望自己简单知道概念后,直接让ChatGPT帮我写代码,我做一套简单的解决方案:
1.爬虫递归爬取相关的文档
2.利用类似上文提到的PDF方案,20~30行代码,解决了核心功能(基于文档的问答系统)
3.用streamlit弄了一个UI
但深入用时,会发现生成的代码,有时问题比较多。
因为常见的文本切分都是按固定字数切分的,这种方法可能会将语义连贯的部分切分开,导致计算相似向量时,获得的内容不全,然后因为是技术文档,通常会有example code,按字数切分容易将code切开,就很尴尬。
langchain本身提供了一个方法来降低这种影响,就是文档切开后,可以留一部分重复的内容,比如切块后的最后50字,与第二块的前50字是一样的,从而维持关联性,方法代码如下:
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 1000,
# 维持关联性
chunk_overlap = 200,
length_function = len,
)但效果没有太大改善,所以我做了一些数据预处理:
1.按title来分,通常一个title中的内容是强关联的,不再按字数分,如果一个title下的内容很多,就拆分一下,但title依旧会带上,例如:
原文:
title 1
content(1800 char)
预处理后(按1000char切分):
title 1
content(0~1000 char)
title 1(不同块都带上原本的title)
content(1000~1800 char)2.特殊内容直接业务处理,比如我处理的是代码文档,其中的example code挺重要的,我会将其单独存起来,不做embed vector,而是直接存原内容,然后通过id与相关的embed vector关联上,例如:
原文:
title 1
content(300 char)
code(100 char)
content(200 char)
title 2:
content(1200 char)
code(100 char)
content(200 char)
预处理后(按1000char切分)
title 1 + all content(300+500) = embed vector , code(100 char)存表获得code id => 表里会记录 embed vector 与 code_id的关联关系
title 2 + 1000 char + code_id
title 2 + 400 char(200 + 200) + code_id这样相似度搜索后,我会将相关的code_id的内容也直接从数据库搜出来,将code直接输入给chatgpt,从而提高生成代码的合理性(当然很多文档本身就是屎一样,example code的代码就是有问题的,这种就是硬伤,但还是可以省点时间)
3.在prmopt中加上一些背景知识,还是以代码文档为例,比如我希望生成Python代码,有些文档的example只给了curl的请求方式,此时就可以在system prompt中加上,如:遇到curl转成python requests的代码之类的。
替换模型和算法
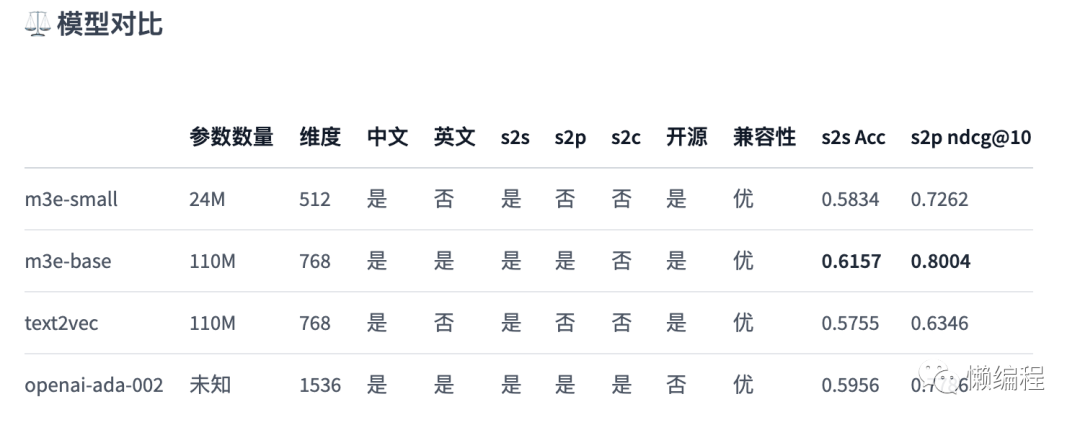
我目前主要使用openai的text-embedding-ada-002,但其实还有很多embedding model,上huggingface翻阅一下,然后看看对比,比如m3e的对比数据就比openai的ada-002要好一点:
然后就是相似度算法,可以尝试替换,这里,我目前主要使用supabase来做,抛开supabase提供的其他功能,可以单纯将supabase当成Postgres database,然后开始白嫖,supabase中怎么做向量相似度计算的方案如下:
你如果不太了解,可以阅读supabase的这篇文章:https://supabase.com/blog/openai-embeddings-postgres-vector
基于supabase + vercel + nextjs,你会发现,做一个知识库项目早期只需要花域名钱和OpenAI的API钱,向量数据库、服务器这些,都可以白嫖。
其他方案
Bybrid Search
我们可以参考其他系统,比如推荐系统,如果遇到推荐不准确时,一个常用的方案就是多路召回,直白说,就是除了从向量数据库通过向量相似度计算获得数据外,再通过其他方式获得相关数据,做多一路。
看langchain的人twitter分享,将关键词搜索加入其中,准确率提高了20%,他将这种方式称为:Bybrid Search。
Bybrid Search的代码目前只存在langchain JS版本中,Python版本是没有的,用起来很简单:https://js.langchain.com/docs/modules/data_connection/retrievers/integrations/supabase-hybrid,替换一下参数就好了。
langchain这个库多数时候都这样,功能帮你封装好,你要用,很简单的,你要定制化的用,抱歉,你需要自己解决,所以很多人吐槽langchain的过度封装,我自己到感觉还好,我的很多需求,确实需要定制化,但也很简单,继承langchain的类,将需要重写的方法重写掉,通常只需要加一点点自己的业务代码就好了。
改写用户提问
这是一个有风险的操作,毕竟你的改写可能会改变用户的语义,你可以用一些工具尝试改写一下,或将是否改写的选择权交给用户,比如UI上弄一个按钮:【优化提问】,之类的。
你可以尝试一下直接套多一层ChatGPT,让ChatGPT帮你将用户的问题在不改变语义的情况下,将问题写的更详细,这是有效果的。
或者,你可以直接使用PromptPerfect这类工具(我还没用过)

multi-Document Agents
multi-Document Agents的核心思路就是构建Agent和不同的文档索引方案,让Agent帮你选择,具体如下图:
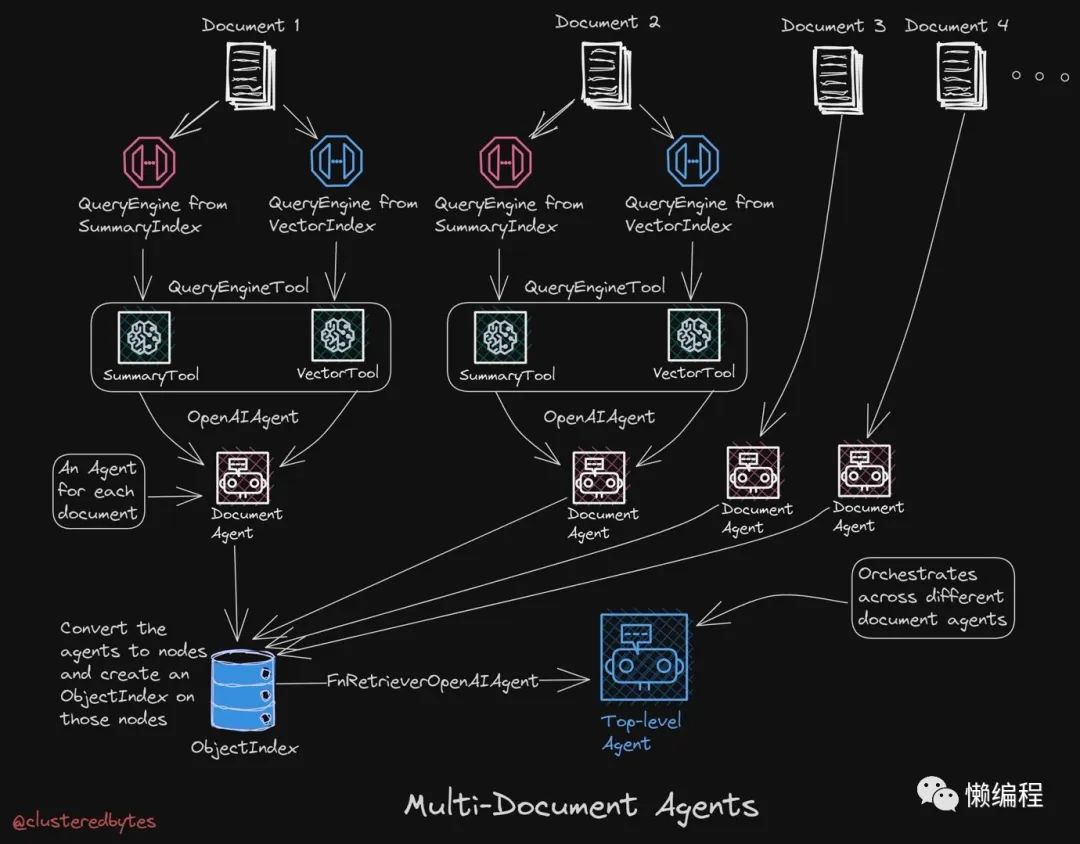
我第一次了解这个方式是在LlamaIndex框架创始人的twitter上看见的,他在twitter上说受到了递归文档代理(Recursive Document Agents)的启发,弄了Multi-Dcouemtn Agents,相关推文:https://twitter.com/jerryjliu0/status/1693421308674289822。
在我看来,langchain定义是更通用的框架,它的功能非常多,而LlamaIndex主要目的是构建一个索引、搜索的LLM框架,因为langchain也有这部分功能,所以挺多人会对比一下,社区间主流的观点是LlamaIndex会快一点,如果大量的数据处理,推荐用LlamaIndex,而Langchain功能更多更灵活一些,在文档检索+LLM这个领域(狭义点就是知识库领域),两者都强调自己的Retrieval-Augending Generation(RAG,检索增强生成)的功能可以帮助你更好的利用文档内容😄。
回到Multi-Dcouemtn Agents,代码基本的细节可以看LlamaIndex文档:https://gpt-index.readthedocs.io/en/latest/examples/query_engine/recursive_retriever_agents.html。
获得实时性强的回答
有时,我们希望ChatGPT除了可以基于知识库回答一些专业性比较强的问题外,还希望可以回答外部实时性比较强的问题,比如行业咨询等。
这里的核心依旧是,通过某种方式可以获得外部数据,然后将其放到Prompt中,这样ChatGPT就知道了。嗯,具体怎么做呢?
假设,你希望通过Google获得实时性的信息,你就需要写一个Google爬虫,Google爬虫要比较稳定的运行,需要购买住宅IP,不然很容易被Google风控限了,当然,我建议你直接用相关的SaaS,比如:https://serpapi.com/,直接付费,然后就可以通过api获取Google数据了。
然后你会发现Langchain提供了serpaper相关的工具:SerpAPIWrapper,直接使用,便可以将Google获取的信息直接加到你现有的知识库项目中了。
如果还是不够清晰,可以直接看完整的代码解决方案:https://colab.research.google.com/drive/1Q-lm-apSJRYwoPvUZGiwYMezeky0yQXD?usp=sharing#scrollTo=XbOXzzQh-ASf
作者利用Langchain的RetrievalQA + SerpAPIWrapper构建了一个可以查询实时信息的知识库。
结尾
以上就是我实操过或简单尝试过的一些方案,简单而言,要构建一个好用的知识库,数据的预处理比较重要,有些企业会让员工人为的整理好原始的QA数据集,然后再基于这个QA做知识库,优质的预处理数据可以比较明显的提升知识库的效果,此外,直接基于原始QA数据集去做问答知识库的方案也被人拓展了一下,假设原数据是单纯的文档数据,那么就让ChatGPT帮你将文档数据转成QA数据集嘛,写个Prompt,让他基于内容问题之类的,但这个我没实操过,所以我也不清楚效果。
有了比较好的预处理数据,再结合本文上面的各种技巧,就可以获得一个准确度比较高的知识库解决方案了。
文章有点长,你居然看到了最后?不打赏一下增加我们的革命友谊吗?