- 以下是我要提取信息的网站: http://zsb.hitwh.edu.cn/home/major/index
文章目录
- 初步尝试(fail)
- 终于改对了!😭
- 继续完善
初步尝试(fail)
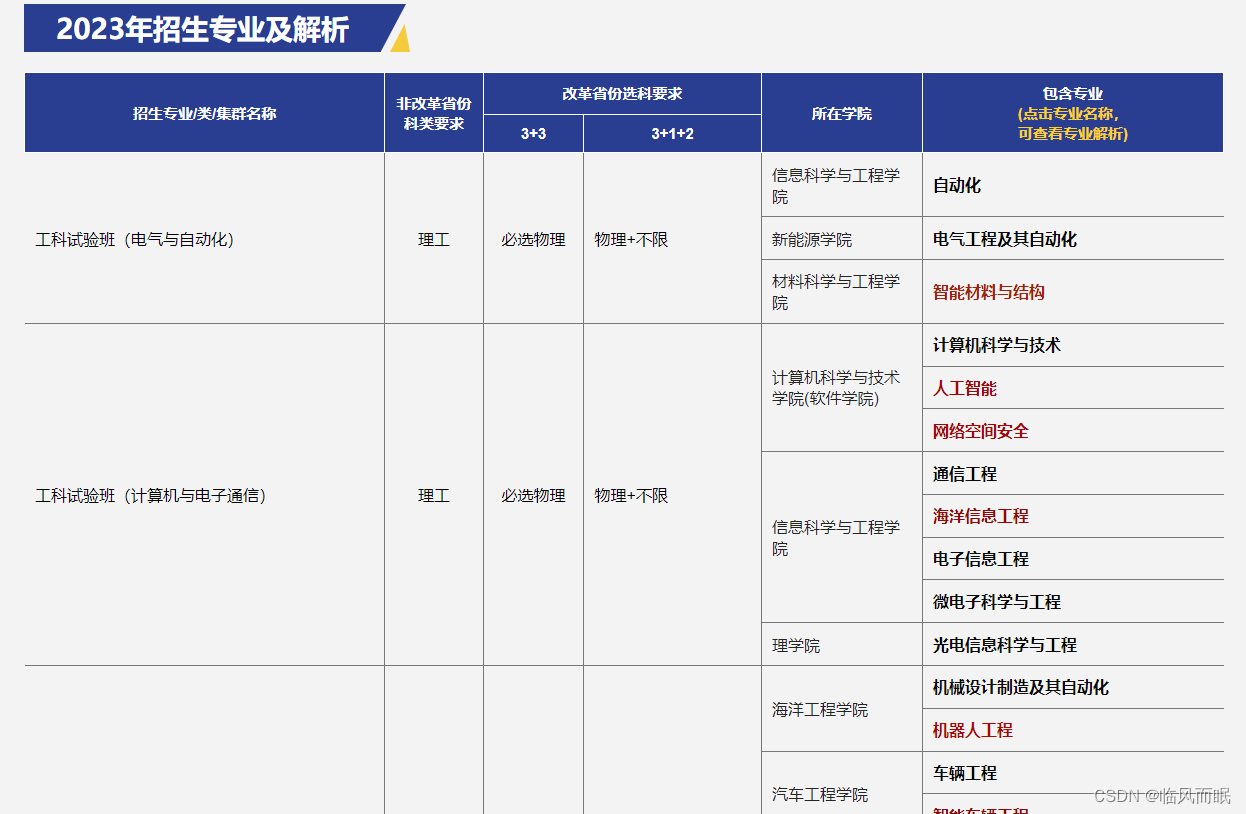
-
用beautifulsoup提取
import requests from bs4 import BeautifulSoup import csv URL = "http://zsb.hitwh.edu.cn/home/major/index" response = requests.get(URL) soup = BeautifulSoup(response.content, 'html.parser') # Extract data from the table rows = soup.select('tbody tr') data = [] for row in rows: # Getting major name major_name = row.select_one('.left-td') # .left-td的意思是class为left-td的标签 if major_name: major_name = major_name.get_text(strip=True) # .get_text(strip=True)的意思是获取标签中的文本内容 # Getting category category = row.select_one('.text-center') # .text-center的意思是class为text-center的标签 if category: category = category.get_text(strip=True) # Getting subject requirements subjects = row.select('td.text-center') # td.text-center的意思是td标签中class为text-center的标签 subject_req = [subj.get_text(strip=True) for subj in subjects[1:]] if len(subjects) > 1 else [] # 这行代码的意思是获取subjects中从第二个元素开始的所有元素 # Getting college details college_detail = row.select_one('td > a') # td > a的意思是td标签下的a标签 college_name = college_detail.get_text(strip=True) if college_detail else None college_link = college_detail['href'] if college_detail else None # Getting major details major_detail = row.select_one('.right-td > a') # .right-td > a的意思是class为right-td的标签下的a标签 major_detail_name = major_detail.get_text(strip=True) if major_detail else None major_detail_link = major_detail['href'] if major_detail else None # Appending data to list data.append({ "Major Name": major_name, "Category": category, "Subject Requirements": subject_req, "College Name": college_name, "College Link": college_link, "Major Detail Name": major_detail_name, "Major Detail Link": major_detail_link }) with open('major_info.csv', 'w', newline='') as csvfile: fieldnames = ['Major Name', 'Category', 'Subject Requirements', 'College Name', 'College Link', 'Major Detail Name', 'Major Detail Link'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) # DictWriter的意思是将字典写入csv文件 writer.writeheader() # writeheader的意思是写入表头 for item in data: writer.writerow(item)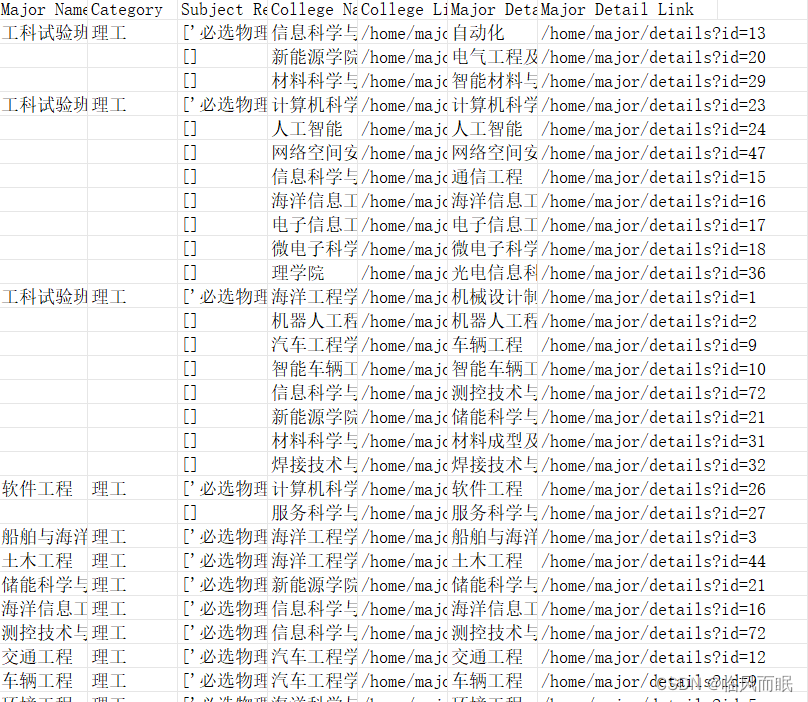
-
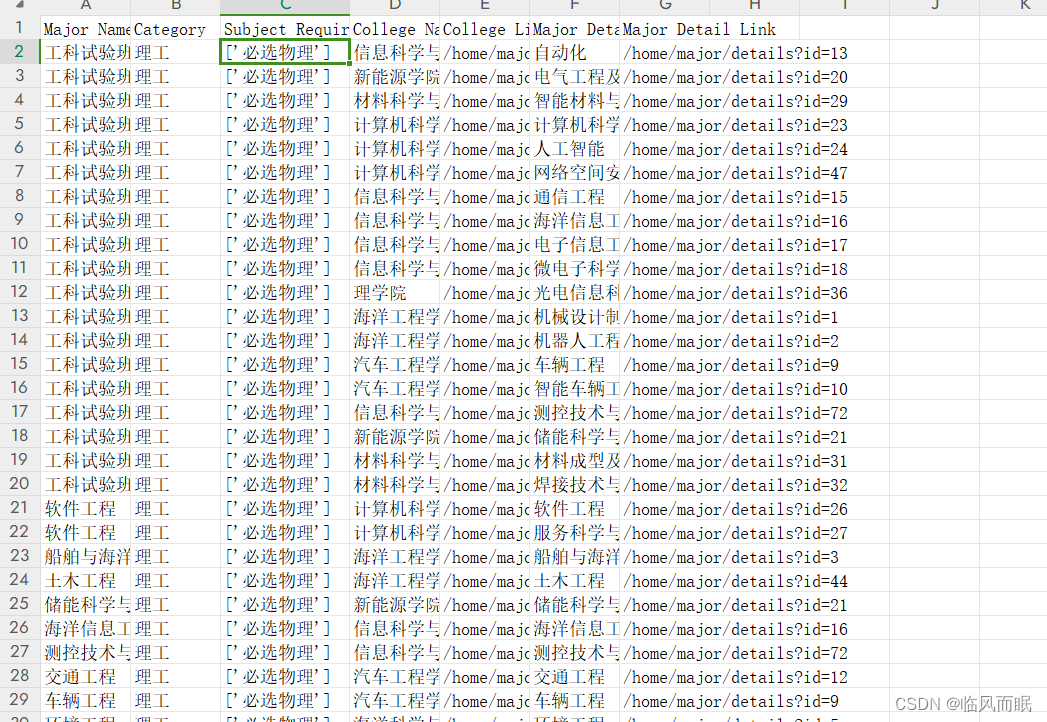
爬出来的问题在于,学院信息那里跨行的地方没有
终于改对了!😭
- 当时急着想别的办法,试了xpath啥的 …
- 但是应该抓住主要矛盾,静下心来分析为什么会有问题!!!
- 问题就在于
td 下的 a 标签 ,不能区分下面这个学院和专业!

-
那么他们的区别在哪?
- 一个有rowspan,一个没有😂…
- 所以只需要微微改动即可!!!!!
-
就是这个地方

继续完善
-
如果我想把空缺的地方填满该咋做?
-
逻辑是每一个tr放到一个row变量里面,然后爬取,那么我们每个row变量长啥样,我存到文件里康康:
rows = soup.select('tbody tr')
data = []
# 把rows[0]存到txt文件中
with open('major_info.txt', 'w', encoding='utf-8') as f:
f.write(str(rows[0]))
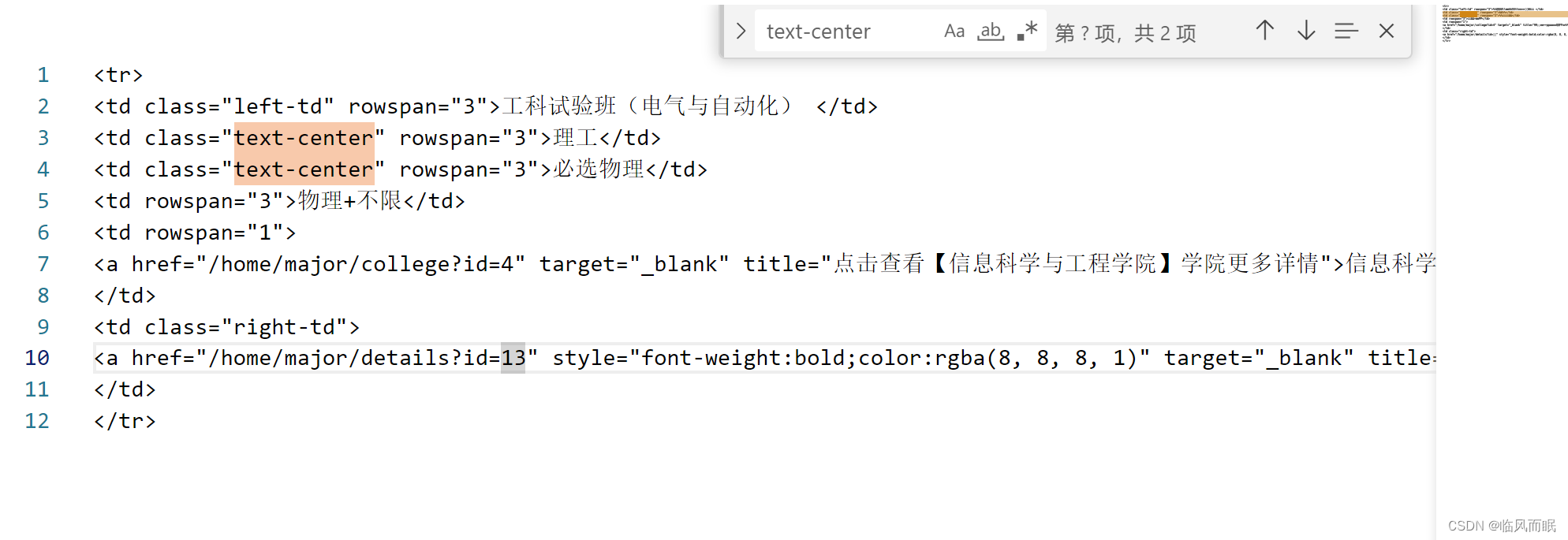
-
改成前6行rows[:5]
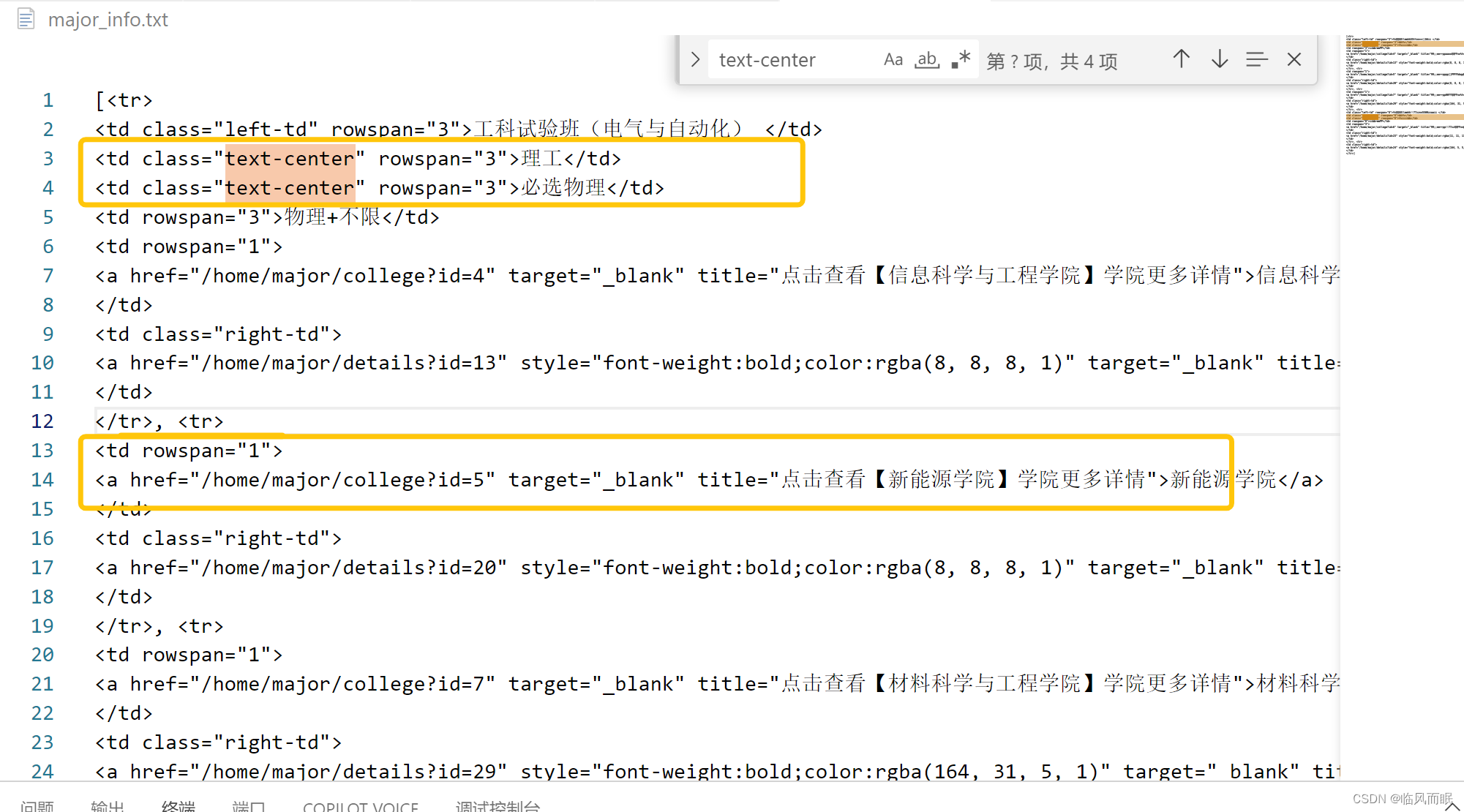
可以看到前三列在第二行确实没再写一次,确实是rowspan了 -
我们只需要把rowspan里面的值利用好就行
使用 rowspan 属性来处理在HTML表格中跨多行的字段。当字段在多行中都保持不变时,它会具有 rowspan 属性。
为了处理 rowspan,我们为每一个可能有 rowspan 的字段维护两个外部变量:一个用来存储当前值,另一个用来追踪剩余的行数。
每次循环时,我们都会检查是否还有剩余的行数。如果有,我们就使用当前的值并减少剩余的行数。否则,我们就从当前行提取新的值。
# 导入必要的库 import requests from bs4 import BeautifulSoup import csv # 设置要抓取数据的网址 URL = "http://zsb.hitwh.edu.cn/home/major/index" # 使用requests库获取网页内容 response = requests.get(URL) # 使用BeautifulSoup解析网页内容,选择使用'html.parser'作为解析器 soup = BeautifulSoup(response.content, 'html.parser') # 从HTML中选择所有tbody下的tr标签,这些标签代表了表格中的每一行 rows = soup.select('tbody tr') # 初始化一个空列表来存储提取出来的数据 data = [] # 对于那些带有rowspan属性的字段,我们需要定义一些外部的变量来追踪其值和它们应该持续的行数 # 这样我们可以在接下来的行中重用这些值 # 专业名称相关变量 remaining_rows_major_name = 0 current_major_name = None # 类别相关变量 remaining_rows_category = 0 current_category = None # 必修课程相关变量 remaining_rows_subjects = 0 current_subjects = None # 学院详情相关变量 remaining_rows_college_detail = 0 current_college_name = None current_college_link = None # 遍历每一行,从中提取所需的信息 for row in rows: # 以下部分的逻辑是为了处理带有rowspan属性的字段 # 如果一个字段的值在多行中都是相同的(由rowspan属性决定),我们只在第一行中提取它 # 然后在接下来的行中重用这个值,直到达到rowspan指定的行数 # 获取专业名称 if remaining_rows_major_name > 0: major_name = current_major_name remaining_rows_major_name -= 1 else: major_name_ele = row.select_one('.left-td') if major_name_ele: major_name = major_name_ele.get_text(strip=True) current_major_name = major_name if 'rowspan' in major_name_ele.attrs: remaining_rows_major_name = int(major_name_ele['rowspan']) - 1 # 获取类别 if remaining_rows_category > 0: category = current_category remaining_rows_category -= 1 else: category_ele = row.select_one('.text-center') if category_ele: category = category_ele.get_text(strip=True) current_category = category if 'rowspan' in category_ele.attrs: remaining_rows_category = int(category_ele['rowspan']) - 1 # 获取必修课程 if remaining_rows_subjects > 0: subject_req = current_subjects remaining_rows_subjects -= 1 else: subjects = row.select('td.text-center') subject_req = [subj.get_text(strip=True) for subj in subjects[1:]] if len(subjects) > 1 else [] current_subjects = subject_req if subjects and 'rowspan' in subjects[0].attrs: remaining_rows_subjects = int(subjects[0]['rowspan']) - 1 # 获取学院详情 if remaining_rows_college_detail > 0: college_name = current_college_name college_link = current_college_link remaining_rows_college_detail -= 1 else: college_detail = row.select_one('td[rowspan] > a') if college_detail: college_name = college_detail.get_text(strip=True) college_link = college_detail['href'] current_college_name = college_name current_college_link = college_link if 'rowspan' in college_detail.find_parent().attrs: remaining_rows_college_detail = int(college_detail.find_parent()['rowspan']) - 1 # 获取专业详情名称和链接 major_detail = row.select_one('.right-td > a') major_detail_name = major_detail.get_text(strip=True) if major_detail else None major_detail_link = major_detail['href'] if major_detail else None # 将提取的数据保存为一个字典,并将其添加到data列表中 data.append({ "Major Name": major_name, "Category": category, "Subject Requirements": subject_req, "College Name": college_name, "College Link": college_link, "Major Detail Name": major_detail_name, "Major Detail Link": major_detail_link }) # 使用csv模块将data列表写入CSV文件 with open('major_info3.csv', 'w', newline='') as csvfile: fieldnames = ['Major Name', 'Category', 'Subject Requirements', 'College Name', 'College Link', 'Major Detail Name', 'Major Detail Link'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() for item in data: writer.writerow(item) -
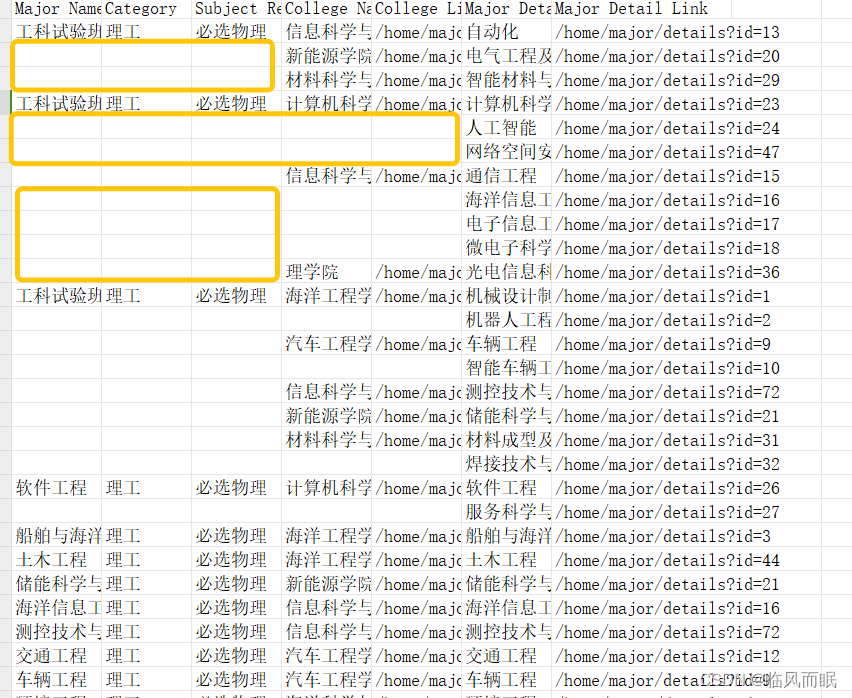
逻辑
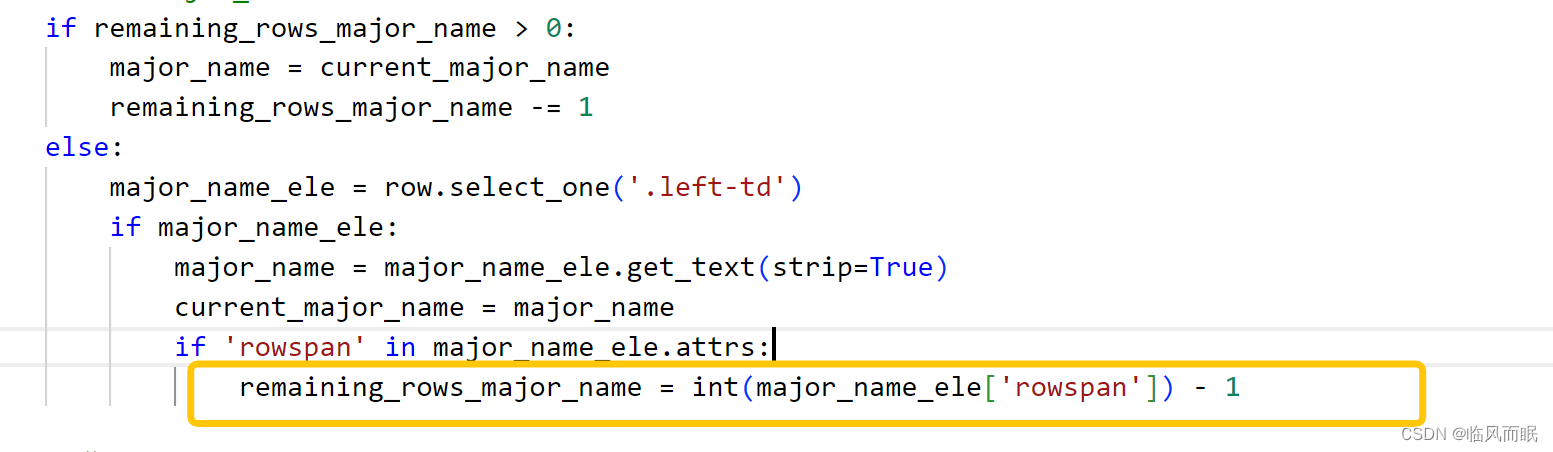
这样的话,第一次遇到有rowspan属性,不仅提取了内容(get-text),还记下了循环次数 也就是上图中圈出来的地方,接下来rowspan-1次循环,每循环一次,减少一次remaining次数,并且赋值给major_name -
nice