跟大家分享港科大提出的无监督域自适应夜间场景语义分割方法,该方法对夜间的动态目标和小目标做了针对性的优化。

- 论文标题:Towards Dynamic and Small Objects Refinement for Unsupervised Domain Adaptative Nighttime Semantic Segmentation
- 机构:港科大
- 论文地址:https://arxiv.org/pdf/2310.04747.pdf
- 工程主页:https://rorisis.github.io/DSRNSS/
- 代码即将开源
- 关键词:语义分割、无监督域自适应、夜间场景
1.动机
语义分割在自动驾驶、机器人等应用中发挥着重要的作用。近年来,随着深度神经网络的发展,语义分割取得了显著的进展。然而,现有的方法主要针对白天场景,在夜间场景,尤其是包含动态目标和小目标时,它们的性能急剧下,主要原因是光照不足且标注数据集缺乏。
为了解决这一问题,研究人员开发了无监督域自适应(Unsupervised Domain Adaptation,简称UDA)方法,让从源域(即白天)图像训练的模型对未标记目标域(即夜间)图像进行自适应。
常用方法可分为3类:
(1)使用风格迁移模型(比如CyclelGAN),生成白天或夜间的图像,作为一个中间域来连接源域和目标域。这类方法比较繁琐,因为它们需要多阶段的学习;如果风格迁移失败则难以保证性能。
(2)利用与目标域粗对齐的黄昏图像,从白天逐步适应夜间域。
(3)利用先验的GPS信息或静态损失减少粗对齐的昼夜图像对(day-night image pairs)的影响,提高伪标签的质量。
上述方法很少关注夜间图像的动态目标和小目标,如车辆和交通标志,在低光照条件下很难实现有效的域对齐。
作者提出了一种新的UDA方法用于夜间场景语义分割,该方法更关注动态目标和小目标。
2.方法
该方法包含2个关键技术,其一为DSR(dynamic and small objects refinement,动态目标和小目标精炼)模块,其二为PFA(feature prototype alignment,特征原型对齐)模块。
总体结构如下图所示:

(1)DSR模块
夜间图片中的动态目标和小目标,很难直接从白天域获得准确的伪标签。因此作者首先利用源图像的标签将源域的动态目标和小目标区域混合到夜间图像中,为这种目标提供准确的标签。
将源图片中的标签记作 Y s Y_s Ys,定义:
M ( h , w ) = { 1 , if Y s ( h , w ) ∈ c 0 , otherwise M(h, w)= \begin{cases}1, & \text { if } Y_s(h, w) \in c \\ 0, & \text { otherwise }\end{cases} M(h,w)={1,0, if Ys(h,w)∈c otherwise
上式中 M M M是二值mask, c c c是被选中的类别, h ∈ H h \in H h∈H和 w ∈ W w \in W w∈W分别表示图像的高和宽。
针对随机选择的类别,使用上述方式可以得到 M r M_r Mr;针对动态目标和小目标,使用上述方式可以得到 M m M_m Mm,将混合后的mask记作 M c M_c Mc,则:
M c = M r ∪ M m M_c=M_r \cup M_m Mc=Mr∪Mm
使用 M c M_c Mc,可使用源图片中的小目标和动态目标对夜间图片进行增强。可以使用 M c M_c Mc对源域图片和目标域图片进行混合:
X m = M c ⊙ X s ( 1 − M c ) ⊙ X n X_m=M_c \odot X_s\left(1-M_c\right) \odot X_n Xm=Mc⊙Xs(1−Mc)⊙Xn
上式中 X s X_s Xs表示源域的图片, X n X_n Xn表示目标域的图片(即夜间的图片)。
类似地,使用 M c M_c Mc混合源域图片的标注 Y s Y_s Ys和目标域的伪标签 y n ′ y_n^{\prime} yn′,得到 X m X_m Xm的标签:
Y m = M c ⊙ Y s + ( 1 − M c ) ⊙ y n ′ Y_m=M_c \odot Y_s+\left(1-M_c\right) \odot y_n^{\prime} Ym=Mc⊙Ys+(1−Mc)⊙yn′
为进一步提升性能,作者将长尾分布类别从源域中引入到目标域中,图片和伪标签的构造公式如下:
X m ′ = B m ⊙ B i + ( 1 − B m ) ⊙ X m Y m ′ = B m ⊙ B l + ( 1 − B m ) ⊙ Y m \begin{aligned} X_m^{\prime} & =B_m \odot B_i+\left(1-B_m\right) \odot X_m \\ Y_m^{\prime} & =B_m \odot B_l+\left(1-B_m\right) \odot Y_m \end{aligned} Xm′Ym′=Bm⊙Bi+(1−Bm)⊙Xm=Bm⊙Bl+(1−Bm)⊙Ym
上式中的 B m B_m Bm表示mask, B i B_i Bi表示源域图片, B l B_l Bl表示源域图片的标注。
利用学生模型 F s F_s Fs对混合后的图片 X m ′ X_m^{\prime} Xm′做预测,得到 y m ′ = F s ( X m ′ ) y_m^{\prime}=F_s\left(X_m^{\prime}\right) ym′=Fs(Xm′),构造损失函数保证 y m ′ y_m^{\prime} ym′和 Y m ′ Y_m^{\prime} Ym′的一致性:
L m i x = − ∑ c = 0 C ∑ w = 0 W ∑ h = 0 H Y m ′ c , h , w log ( y m ′ c , h , w ) \mathcal{L}_{m i x}=-\sum_{c=0}^C \sum_{w=0}^W \sum_{h=0}^H Y_m^{\prime c, h, w} \log \left(y_m^{\prime c, h, w}\right) Lmix=−c=0∑Cw=0∑Wh=0∑HYm′c,h,wlog(ym′c,h,w)
工作流程表示如下:

用于生成伪标签的教师模型的权重 ϕ t ′ \phi_t^{\prime} ϕt′在训练时,每 t t t次迭代使用学生模型的权重 ϕ t \phi_t ϕt更新一次,表示如下:
ϕ t ′ = λ ϕ ˙ t − 1 ′ + ( 1 − λ ) ϕ ˙ t \phi_t^{\prime}=\lambda \dot{\phi}_{t-1}^{\prime}+(1-\lambda) \dot{\phi}_t ϕt′=λϕ˙t−1′+(1−λ)ϕ˙t
上式中的 λ \lambda λ表示EMA衰减, λ ∈ [ 0 , 1 ] \lambda \in [0,1] λ∈[0,1]。
(2)FPA模块
DSR模块产生了混合域,作者构造了FPA模块用于对齐源域、目标域和混合域。
为了学习域不变特征,对不同域同类目标的像素级别的特征进行累加,使用源域标注 Y s Y_s Ys和混合域伪标签 Y m ′ Y_m^{\prime} Ym′得到每一类的原型(prototypes):
ρ s c = ∑ h H ∑ w W f s h , w Y s c , h , w ∑ h H ∑ w W Y s c , h , w , ρ m c = ∑ h H ∑ w W f m h , w Y m ′ c , h , w ∑ h H ∑ w W Y m ′ c , h , w \rho_s^c=\frac{\sum_h^H \sum_w^W f_s^{h, w} Y_s^{c, h, w}}{\sum_h^H \sum_w^W Y_s^{c, h, w}}, \rho_m^c=\frac{\sum_h^H \sum_w^W f_m^{h, w} Y_m^{\prime c, h, w}}{\sum_h^H \sum_w^W Y_m^{\prime c, h, w}} ρsc=∑hH∑wWYsc,h,w∑hH∑wWfsh,wYsc,h,w,ρmc=∑hH∑wWYm′c,h,w∑hH∑wWfmh,wYm′c,h,w
上式中 ρ s c \rho_s^c ρsc和 ρ m c \rho_m^c ρmc分别为源域和混合域中类别 c c c的原型, f s f_s fs和 f m f_m fm为学生模型 F s F_s Fs在源域图片和混合域图片中提取到的特征。
使用原型和特征计算跨域对比损失,使用源域和混合域中同类别目标的像素特征和原型作为positive pairs,这样可以最大化同类别像素特征和原型的一致性:
S m → s c = ( s ( f m h , w , ρ s c , h , w ) / τ ) ⋅ W c S_{m \rightarrow s}^c=\left(s\left(f_m^{h, w}, \rho_s^{c, h, w}\right) / \tau\right) \cdot W^c Sm→sc=(s(fmh,w,ρsc,h,w)/τ)⋅Wc
上式中 s ( ⋅ , ⋅ ) s(\cdot, \cdot) s(⋅,⋅)表示余弦相似度, τ \tau τ表示温度参数, W c W^c Wc表示类别 c c c的相似度权重,使用如下公式计算对比损失:
L m → s = − ∑ c C ∑ h H ∑ w W y n ′ c , h , w log exp ( S m → s c ) ∑ c exp ( S m → s c ) \mathcal{L}_{m \rightarrow s}=-\sum_c^C \sum_h^H \sum_w^W y_n^{\prime c, h, w} \log \frac{\exp \left(S_{m \rightarrow s}^c\right)}{\sum_c \exp \left(S_{m \rightarrow s}^c\right)} Lm→s=−c∑Ch∑Hw∑Wyn′c,h,wlog∑cexp(Sm→sc)exp(Sm→sc)
L m → s \mathcal{L}_{m \rightarrow s} Lm→s表示源域原型和混合域特征的对比损失。与之类似,还有:
S s → m c = ( s ( f s h , w , ρ m c , h , w ) / τ ) ⋅ W c S_{s \rightarrow m}^c=\left(s\left(f_s^{h, w}, \rho_m^{c, h, w}\right) / \tau\right) \cdot W^c Ss→mc=(s(fsh,w,ρmc,h,w)/τ)⋅Wc
L s → m = − ∑ c C ∑ h H ∑ w W Y s c , h , w log exp ( S s → m c ) ∑ c exp ( S s → m c ) \mathcal{L}_{s \rightarrow m}=-\sum_c^C \sum_h^H \sum_w^W Y_s^{c, h, w} \log \frac{\exp \left(S_{s \rightarrow m}^c\right)}{\sum_c \exp \left(S_{s \rightarrow m}^c\right)} Ls→m=−c∑Ch∑Hw∑WYsc,h,wlog∑cexp(Ss→mc)exp(Ss→mc)
为解决类别不均衡问题,作者提出了一种自适应的重加权算法,专门针对重叠区域包含动态目标和小目标的情况。通过给这些原型分配权重,我们可以调整相应的像素级特征,相似度权重定义如下:
W
c
=
{
1
,
if
c
∈
C
o
s
+
1
/
s
if
c
∈
C
l
0
,
otherwise
W^c= \begin{cases}1, & \text { if } c \in C_o \\ s+1 / s & \text { if } c \in C_l \\ 0, & \text { otherwise }\end{cases}
Wc=⎩
⎨
⎧1,s+1/s0, if c∈Co if c∈Cl otherwise
上式中
s
s
s表示相互重叠的类别数量,
C
o
C_o
Co包括重叠类别但是不包括长尾类别,
C
l
C_l
Cl包括重叠类中的长尾类。
总体的原型对比损失如下:
L proto = L n → s + L s → n + L m → s + L s → m \mathcal{L}_{\text {proto }}=\mathcal{L}_{n \rightarrow s}+\mathcal{L}_{s \rightarrow n}+\mathcal{L}_{m \rightarrow s}+\mathcal{L}_{s \rightarrow m} Lproto =Ln→s+Ls→n+Lm→s+Ls→m
(3)整体损失函数
除了上文中的2个损失函数,作者还使用交叉熵损失,用标注的源域图片监督分割模型,表示如下:
L sup = − ∑ h = 0 H ∑ w = 0 W ∑ c = 0 C 1 ( Y s c , h , w ) log ( y s c , h , w ) \mathcal{L}_{\text {sup }}=-\sum_{h=0}^H \sum_{w=0}^W \sum_{c=0}^C \mathbb{1}\left(Y_s^{c, h, w}\right) \log \left(y_s^{c, h, w}\right) Lsup =−h=0∑Hw=0∑Wc=0∑C1(Ysc,h,w)log(ysc,h,w)
上式中的 1 ( ⋅ ) \mathbb{1}(\cdot) 1(⋅)表示one-hot编码。
总体损失函数如下:
L = L sup + α L mix + β L proto \mathcal{L}=\mathcal{L}_{\text {sup }}+\alpha \mathcal{L}_{\text {mix }}+\beta \mathcal{L}_{\text {proto }} L=Lsup +αLmix +βLproto
上式中的 α \alpha α和 β \beta β为用于平衡3种损失的超参数, α = 1.0 \alpha=1.0 α=1.0, β = 0.1 \beta=0.1 β=0.1。
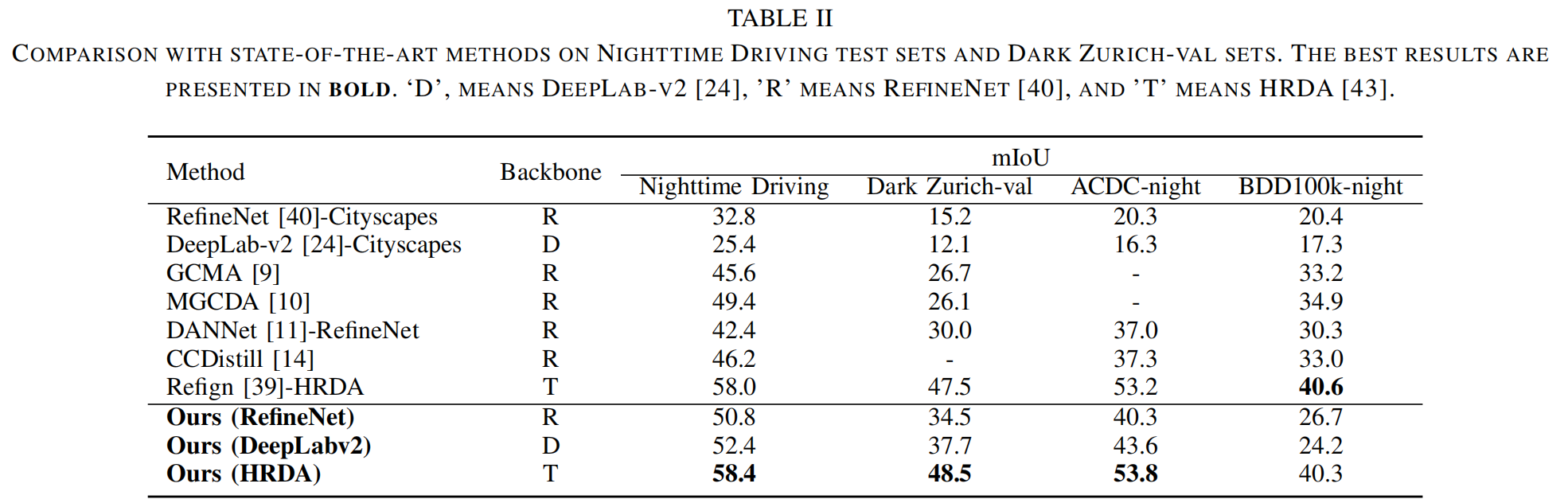
3.实验
(1)实验设置

(2)实验结果
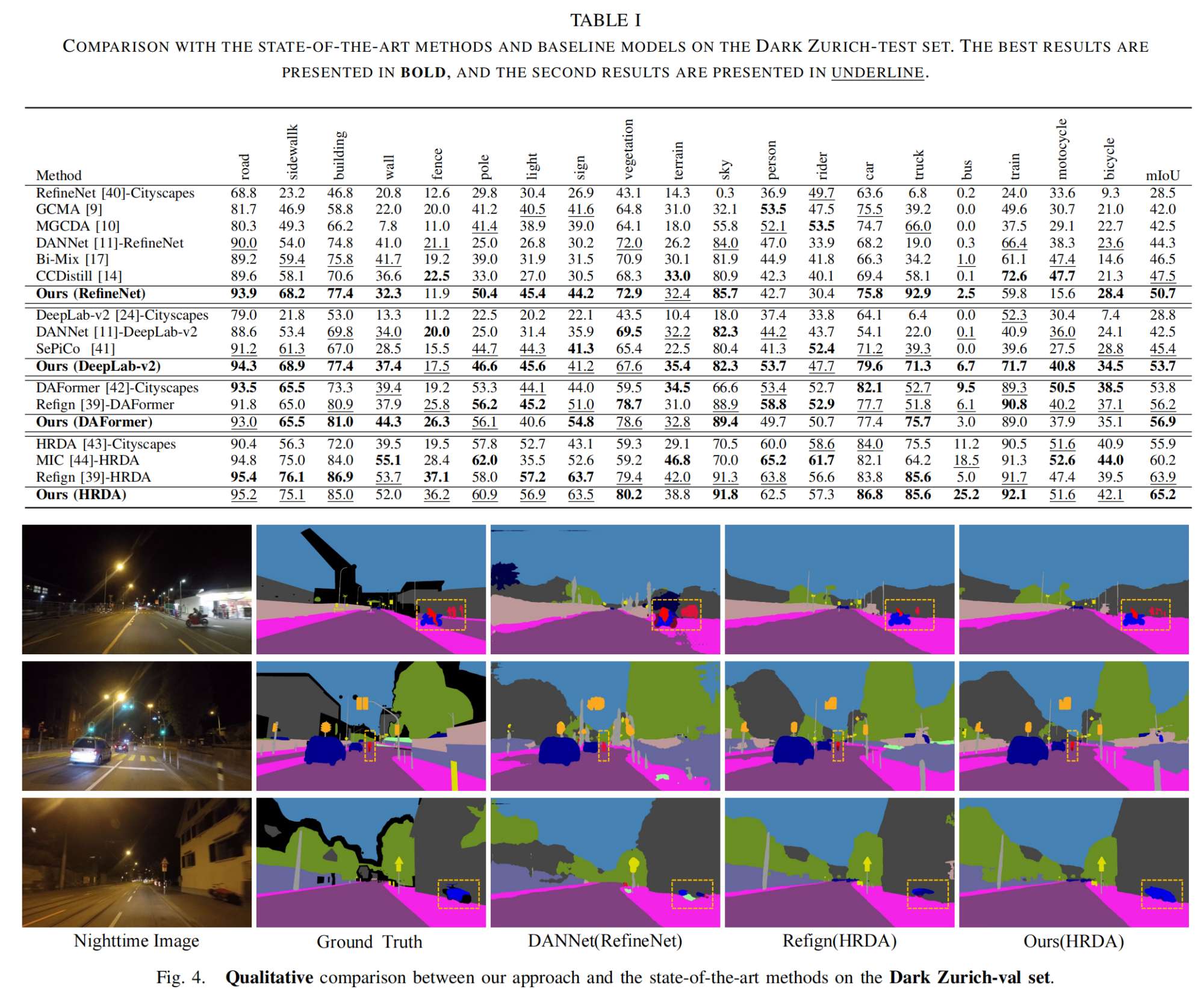


4.总结
作者提出了一种新的UDA方法用于夜间分割,重点关注动态目标和小目标,该方法包括DSR模块和FPA模块。DSR模块将动态目标和小目标进行组合,同时引入长尾分布类。FPA模块通过特征和原型对齐约束混合过程,减少了不同域中的域偏移。
推荐阅读:
EViT:借鉴鹰眼视觉结构,南开大学等提出ViT新骨干架构,在多个任务上涨点
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
CV计算机视觉每日开源代码Paper with code速览-2023.10.13
CV计算机视觉每日开源代码Paper with code速览-2023.10.12
CV计算机视觉每日开源代码Paper with code速览-2023.10.10


![[Zookeeper:基于容器化]:快速部署安装](https://img-blog.csdnimg.cn/544f64162e8c45d8aadd7500c7315f01.png)