YOLO系列概述(yolov1至yolov7)
参考:
- 睿智的目标检测53——Pytorch搭建YoloX目标检测平台
- YoloV7
yolo的发展历史
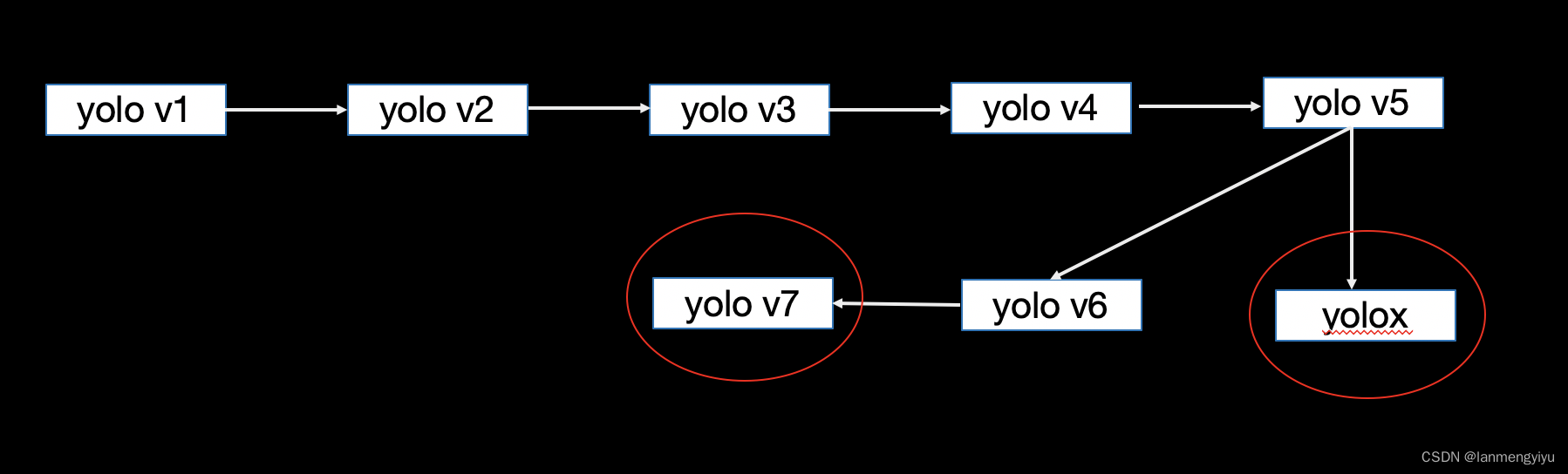
首先我们来看一下yolo系列的发展历史,yolo v1和yolox是anchor free的方法,yolov2,yolov3,一直到yolov7是anchor base的方法。首选我们来回顾下每个版本的yolo都做了些什么
yolo v1是将 416 ∗ 416 416*416 416∗416的图片,分成了 7 ∗ 7 7*7 7∗7的网格,每个网格默认回归两个object,也就是最终预测一个长度为SS(B*5+C)的向量,这里 s = 7 , b = 2 s=7,b=2 s=7,b=2,c是class的类别数量。
那么这里引入一个问题,为什么yolox也是anchor free的方法性能好,而yolo v1性能偏弱呢?这里主要是因为yolox与centernet类似,通过预测中心点,使得模型的预测更为准确。对于yolox会有一个featuremap表示某个位置是中心点的概率,而中心点比起长宽更能表示一个物体的特征。
我们再来看yolov2,因为此时faster rcnn的兴起,在faster rcnn中 最后一层featuremap每个位置可以回归9个anchor,而anchor作为先验知识发挥了巨大的作用,因此引入了yolov2中,当然yolov2也提出了一些训练模型的技巧,比如先训练分类等等。并且因为anchor的存在,在一定程度上解决了yolo的小目标问题。
yolov2之后就到了yolov3,当时fpn的诞生,又进一步解决了小目标问题,由于对于小目标来说经过多层卷机之后feature可能就不见了或者很小了,那么就考虑到,浅层的特征范围还比较大,如果能把浅层特征和深层特征concat到一起,就既有了表层特征又有了语义特征,因为fpn的加入 yolov3取得了较好的性能。
yolov4和yolov5值得一提的除了backbone改进之外,在数据增强上也做了创新,比如mosaic,mixup等方法的引入。其中mosaic指的就是将四张图片拼接成一张用于目标检测,这种方法的优点在于丰富的背景信息有助于检测,而mixup是将两张图片加和到一起。并且neck部分,作者也用了panet的方法,不仅仅通过两次上采样cancat,在此基础上又用了两次下采样。这样可以将特征更有效的融合到一起。
yolox和yolov7将在后面详细介绍.
yolox
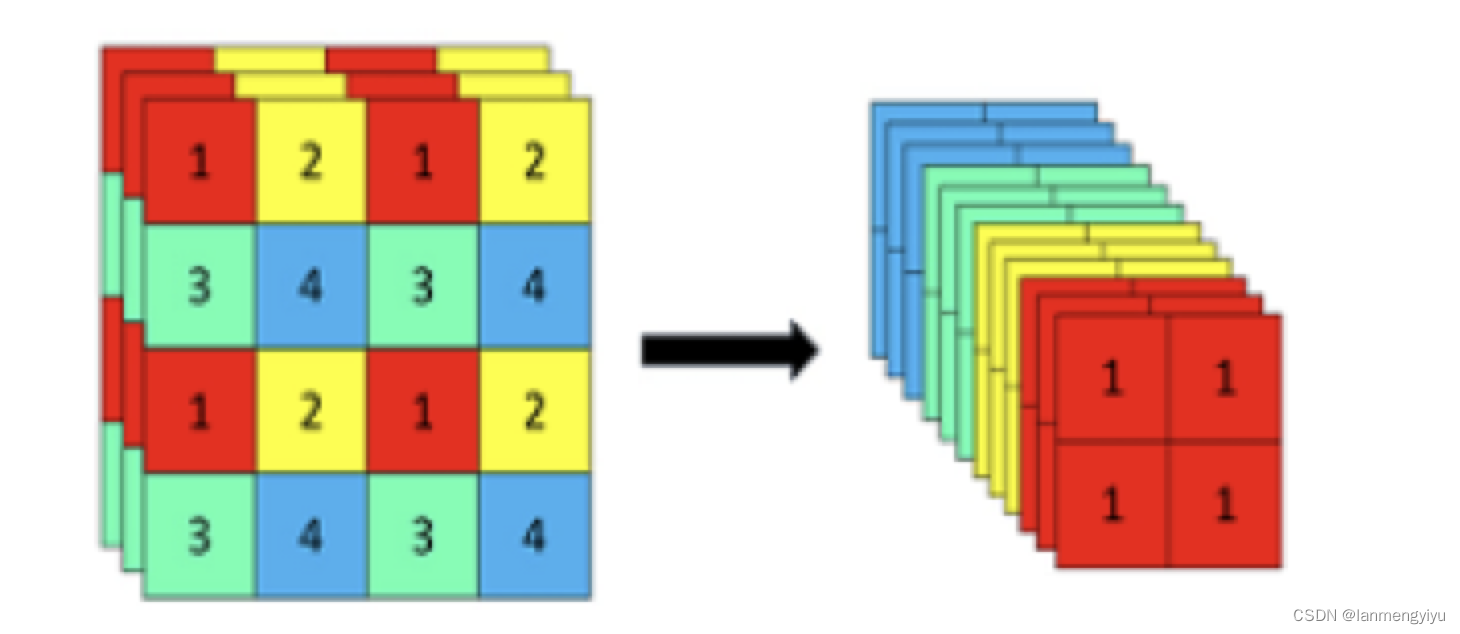
首先,yolox在backbone部分引入的focus网络,类似于pooling的策略,但是他没有像maxpooling一样把小的feature丢掉,而是隔一个位置取一个值后堆叠到channel中,因为我们知道通道数越高,表征能力越强。
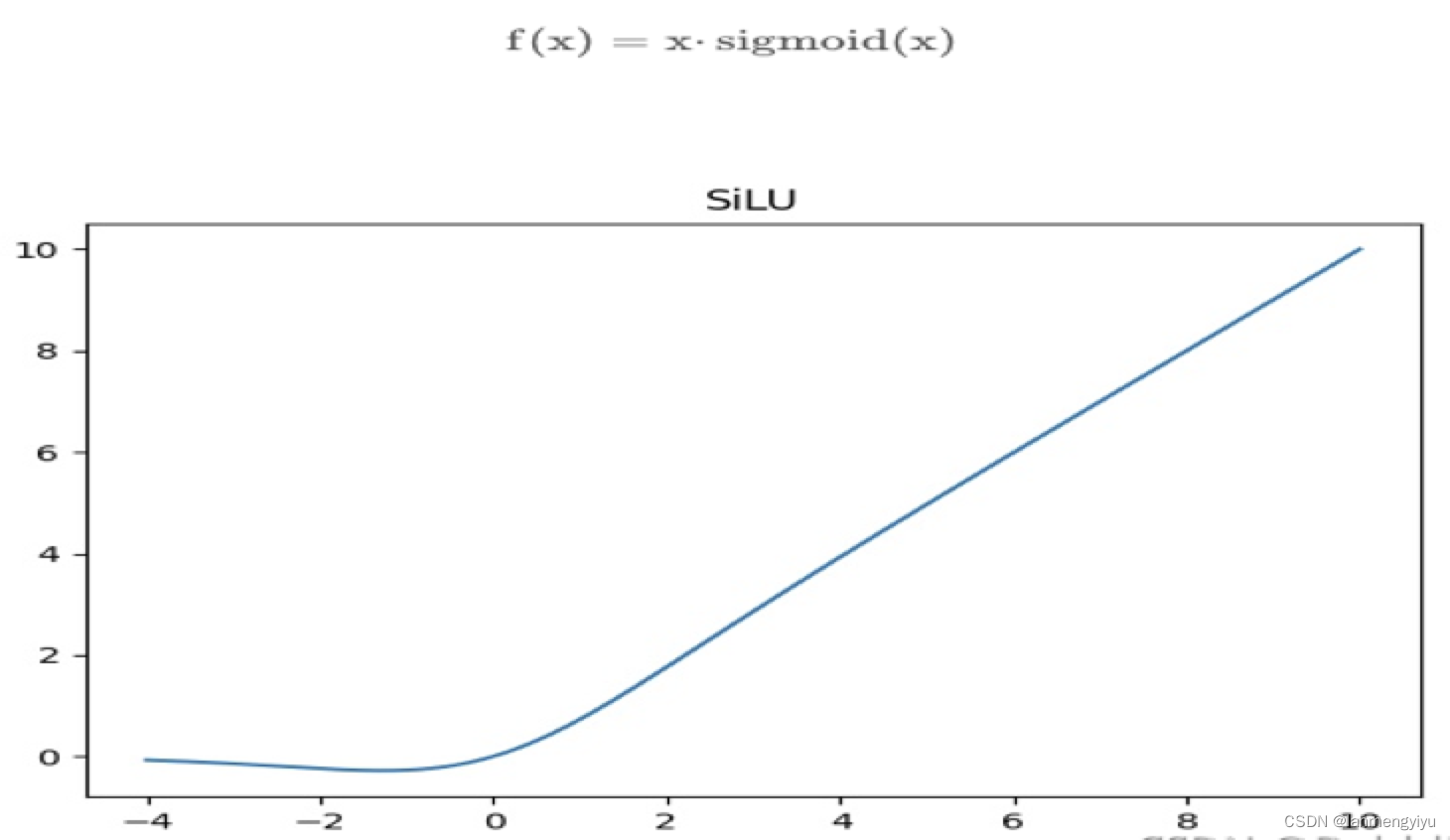
再次我们看一下作者用silu替换了relu,silu的优势在于它是全局可导的,不存在不可导的0点。
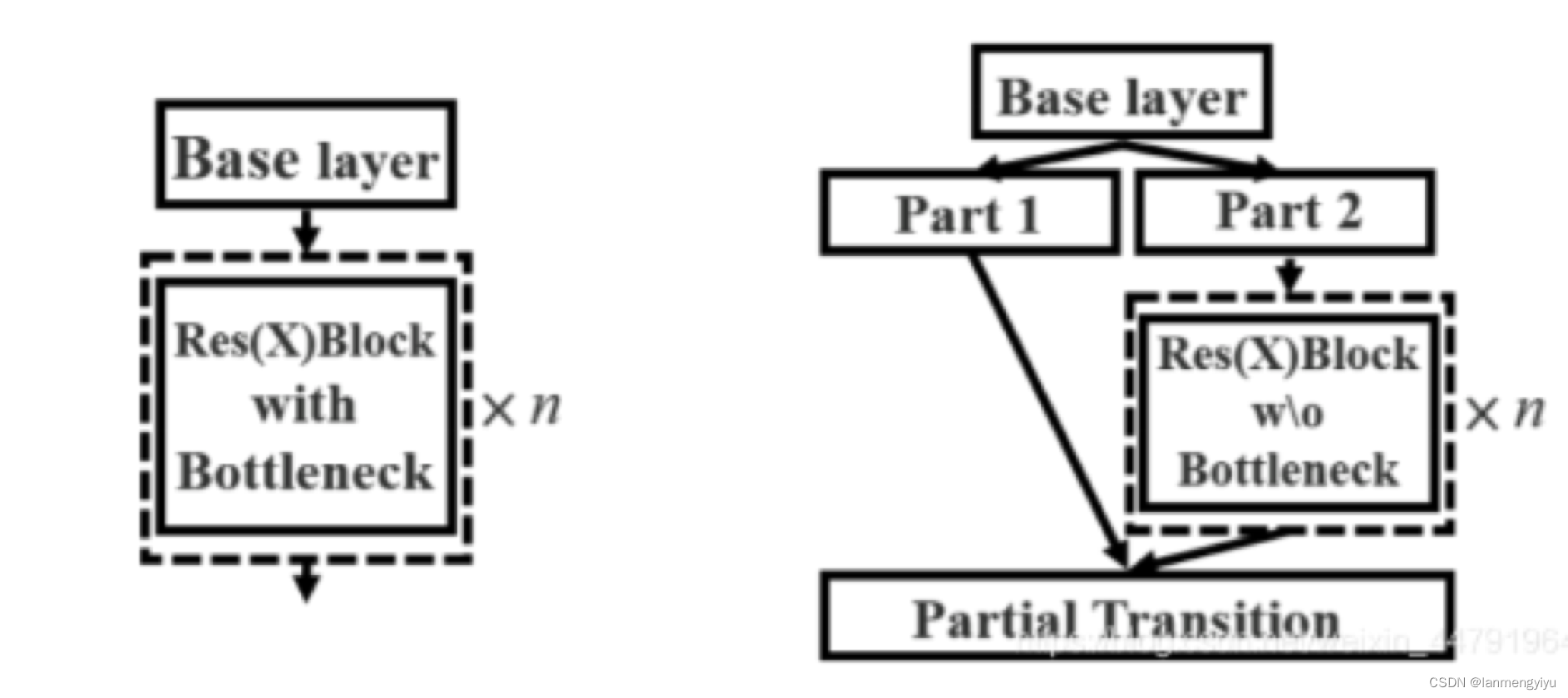
另外,在backbone部分,我们可以得到的启示就是,怎样将小的conv+bn+silu组成的基本卷积结构构造成不同类型的残差结构。
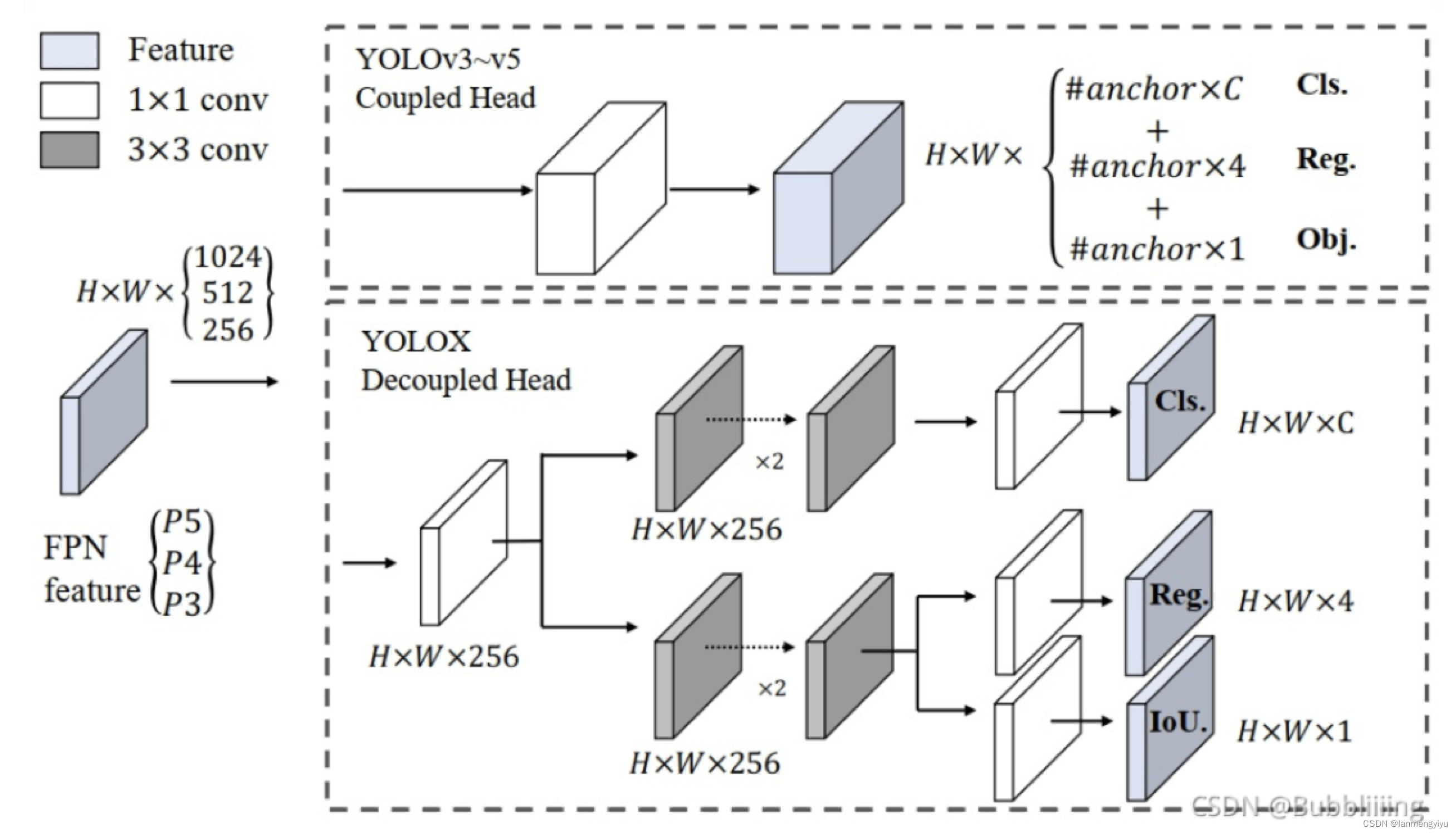
另外,在head部分,作者认为yolov3中的类别和坐标放到一个
1
∗
1
1*1
1∗1卷积得到,会相互影响。因此把它分成两个分支。
最后,SimOTA就是一个动态分配正样本的算法,将预测框中十个iou最大的值加起来,近似得到的值就是将用来训练的正样本数量。这一方法也在后续的yolo中被使用。
yolov7
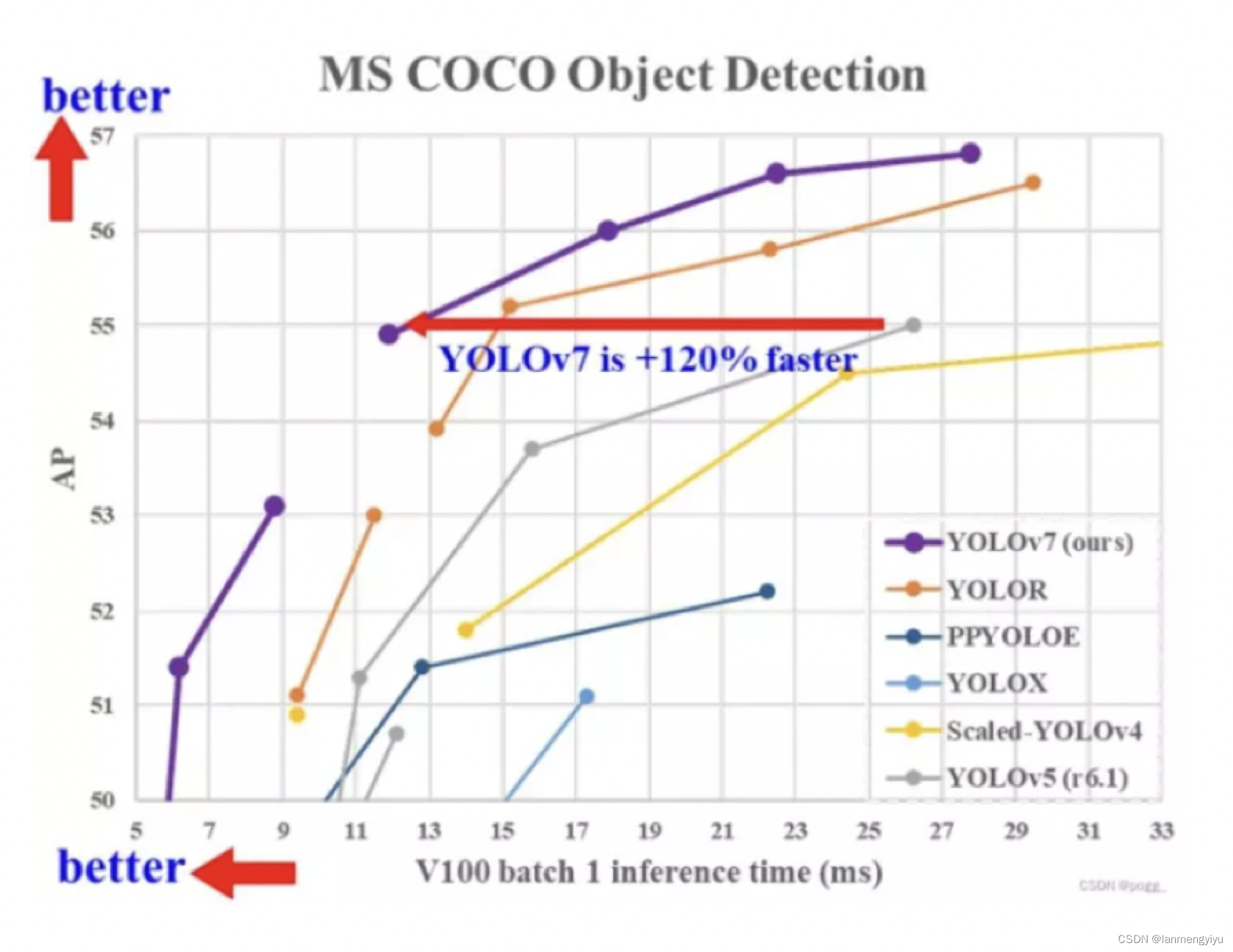
22年夏天,又有大神提出了yolov7,可以看到同等fps下,ap比yolox可以提高5个点,那么我们就来看看有什么创新。
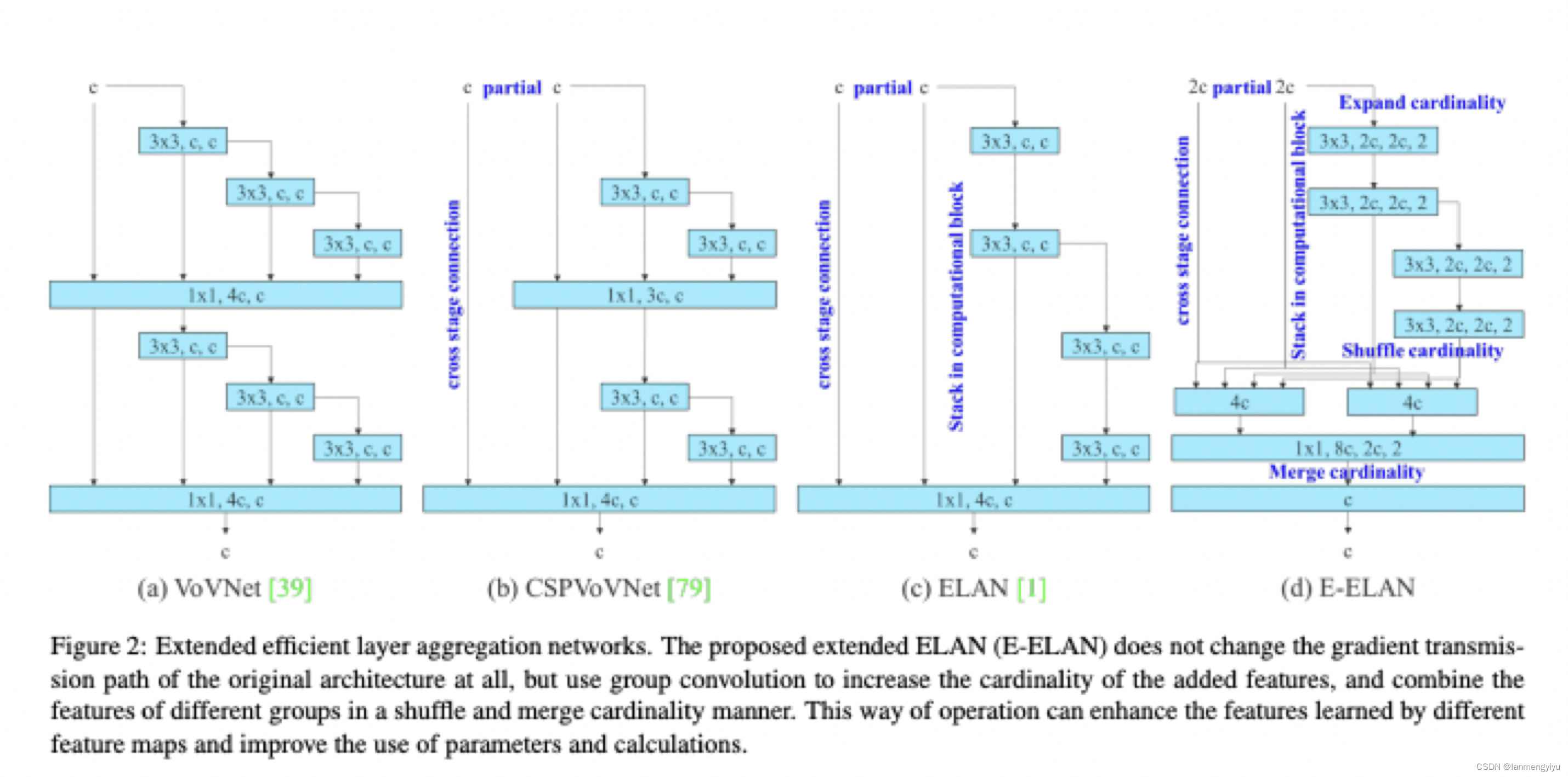
首先在backbone中,我们可以看到,其实作者改进的E-ELAN只是将原来4倍通道提高到了8倍,所以这也印证了我们之前说的,高通道有更强的特征表达能力。而E-ELAN没有采用残差的加和方式,而是采用了堆叠的方式,毫无疑问计算量更大,但是表征力更强,如果考虑轻量化,或许可以考虑改成加和的方式。
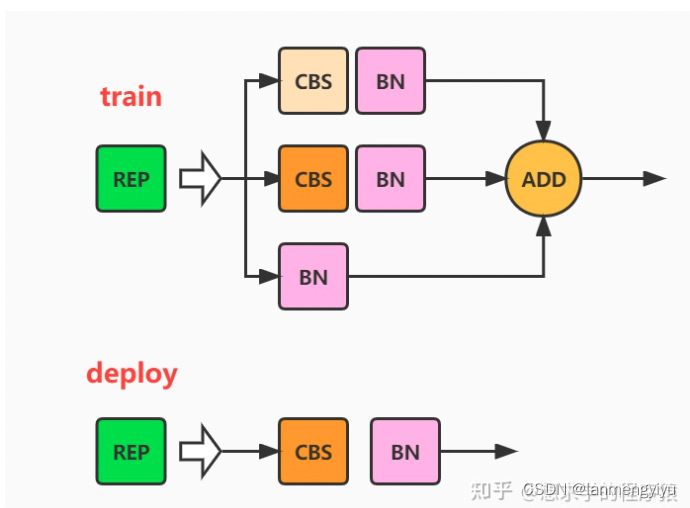
另外在检测头部分采用的rep网络,当训练时,有三个分支,分别是 1 ∗ 1 1*1 1∗1卷积, 3 ∗ 3 3*3 3∗3卷积,和只有bn三个分支,但是预测时候,只保留主分支 3 ∗ 3 3*3 3∗3分支,这就比较像dropout,它会让一部分节点失活,或许可以起到跟dropout同样的作用,减少过拟合。