文章目录
- 一、Python生成数据
- 1.1 代码说明
- 1.2 代码参考
- 二、数据迁移
- 2.1 从本机上传至服务器
- 2.2 检查源数据格式
- 2.3 检查大小并上传至HDFS
- 三、beeline建表
- 3.1 创建测试表并导入测试数据
- 3.2 建表显示内容
- 四、csv文件首行列名的处理
- 4.1 创建新的表
- 4.2 将旧表过滤首行插入新表
一、Python生成数据
1.1 代码说明
这段Python代码用于生成模拟的个人信息数据,并将数据保存为CSV文件。
-
导入必要的模块:
csv:用于处理CSV文件的模块。random:用于生成随机数。faker:用于生成模拟数据的库。
-
定义生成数据所需的基本信息:
file_base_path:生成的CSV文件的基本路径。rows_per_file:每个CSV文件中包含的行数。num_rows:要生成的总行数。fake:创建faker.Faker()实例,用于生成模拟数据。
-
定义模拟数据的字典:
nationalities:包含国籍编码和对应的国家。regions:包含区域编码和对应的区域名称。source_codes:包含一组源代码。
-
使用计数器
row_counter来跟踪生成的行数。 -
使用循环生成多个CSV文件,每个文件包含
rows_per_file行数据。 -
在每个文件中,生成随机的个人信息数据,并将其写入CSV文件。
-
数据生成的过程中,每10000行数据打印一次进度。
-
所有数据生成后,打印生成的总行数。
这段代码使用Faker库生成模拟的个人信息数据,每个CSV文件包含一定数量的行数据,数据字段包括 Rowkey, Name, Age, Email, Address, IDNumber, PhoneNumber, Nationality, Region, SourceCode。
1.2 代码参考
import csv
import random
import faker
# 文件基本路径
file_base_path = './output/personal_info_extended'
# 每个文件的行数
rows_per_file = 10000
# 总行数
num_rows = 10000000
# 创建Faker实例
fake = faker.Faker()
# 定义数据字典
nationalities = {
1: 'US',
2: 'CA',
3: 'UK',
4: 'AU',
5: 'FR',
6: 'DE',
7: 'JP',
}
regions = {
1: 'North',
2: 'South',
3: 'East',
4: 'West',
5: 'Central',
}
source_codes = ['A123', 'B456', 'C789', 'D101', 'E202']
# 计数器用于跟踪生成的行数
row_counter = 0
# 循环生成数据文件
for file_number in range(1, num_rows // rows_per_file + 1):
file_path = f"{file_base_path}_{file_number}.csv"
# 打开CSV文件以写入数据
with open(file_path, 'w', newline='') as csvfile:
csv_writer = csv.writer(csvfile)
# 写入CSV文件的标题行
if row_counter == 0:
csv_writer.writerow(['Rowkey', 'Name', 'Age', 'Email', 'Address', 'IDNumber', 'PhoneNumber', 'Nationality', 'Region', 'SourceCode'])
# 生成并写入指定行数的扩展的个人信息模拟数据
for _ in range(rows_per_file):
name = fake.name()
age = random.randint(18, 99)
email = fake.email()
address = fake.address().replace('\n', ' ') // 替换掉地址中的换行,保持数据生成为一行
id_number = fake.ssn()
phone_number = fake.phone_number()
nationality_code = random.randint(1, len(nationalities))
nationality = nationalities[nationality_code]
region_code = random.randint(1, len(regions))
region = regions[region_code]
source_code = random.choice(source_codes)
data_row = [row_counter + 1, name, age, email, address, id_number, phone_number, nationality, region, source_code]
csv_writer.writerow(data_row)
row_counter += 1
print(f'已生成 {row_counter} 行数据')
print(f'{num_rows} 行扩展的个人信息模拟数据已生成')
在这里插入图片描述
二、数据迁移
2.1 从本机上传至服务器
[root@hadoop10 personInfo]# pwd
/opt/data/personInfo
[root@hadoop10 personInfo]# ls -l| wc -l
215
[root@hadoop10 personInfo]# wc -l *
...
10000 personal_info_extended_98.csv
10000 personal_info_extended_99.csv
10000 personal_info_extended_9.csv
2131609 总用量
通过命令显示我们使用了生成的215个csv文件,现在已经上传到了/opt/data/personInfo目录下。
2.2 检查源数据格式
[root@hadoop10 personInfo]# head personal_info_extended_1.csv
Rowkey,Name,Age,Email,Address,IDNumber,PhoneNumber,Nationality,Region,SourceCode
1,Hayley Jimenez,58,garrisonalicia@harris.com,"92845 Davis Circles Apt. 198 East Jerryshire, NV 35424",657-35-2900,(141)053-9917,DE,North,C789
2,Amy Johnson,23,samuelrivera@hall.com,"119 Manning Rapids Suite 557 New Randyburgh, MN 58113",477-76-9570,+1-250-531-6115,UK,North,D101
3,Sara Harper,31,gsandoval@hotmail.com,"98447 Robinson Dale Garzatown, ME 35917",254-77-4980,7958192189,AU,East,A123
4,Alicia Wang,53,kellyreed@evans.com,"531 Lucas Vista New Laura, MO 62148",606-19-1971,001-295-093-9174x819,DE,West,C789
5,Lauren Rodriguez,71,rebeccasaunders@yahoo.com,"060 Gomez Ports Suite 355 Lake Aarontown, CO 38284",186-61-7463,8458236624,DE,East,E202
6,Juan Harris,98,davidsonjohn@hines.com,"50325 Alvarez Forge Apt. 800 New Ericchester, AL 16131",529-53-1492,+1-302-675-5810,CA,East,B456
7,Stephanie Price,90,sroberts@becker.com,"9668 Erik Inlet Port Joshua, MO 62524",303-11-9577,628.011.4670,UK,East,C789
8,Nicole Parker,61,tmcneil@rose-rodriguez.com,"485 Elliott Branch Scottshire, NJ 03885",473-55-5636,001-625-925-3712x952,FR,West,A123
9,Joel Young,54,john03@hotmail.com,"9413 Houston Flats Apt. 095 West Peggy, MD 56240",547-31-2815,920.606.0727x27740,JP,Central,E202
使用head命令查看文件的头,发现了首行字段,我们可以通过首行字段编写建表语句。
2.3 检查大小并上传至HDFS
[root@hadoop10 data]# du -h
282M ./personInfo
282M .
[root@hadoop10 data]# hdfs dfs -put /opt/data/personInfo /testdir/
[root@hadoop10 data]# hdfs dfs -du -h /testdir/
281.4 M 281.4 M /testdir/personInfo
linux本地文件占用282M,上传至HDFS集群/testdir/目录后占用281.4M.
三、beeline建表
3.1 创建测试表并导入测试数据
CREATE TABLE personal_info (
Rowkey STRING,
Name STRING,
Age STRING,
Email STRING,
Address STRING,
IDNumber STRING,
PhoneNumber STRING,
Nationality STRING,
Region STRING,
SourceCode STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
LOAD DATA INPATH '/testdir/personInfo/*.csv' INTO TABLE personal_info;
如果csv文件的每一行都有同样的列名,需要在建表语句最后添加以下代码:TBLPROPERTIES ("skip.header.line.count"="1"),将首行跳过。
本案例由于使用python生成文件,只有第一个csv文件有列名,其余csv没有列名,我们稍后单独处理这一个首行。
3.2 建表显示内容
0: jdbc:hive2://hadoop10:10000> CREATE TABLE personal_info (
. . . . . . . . . . . . . . . > Rowkey STRING,
. . . . . . . . . . . . . . . > Name STRING,
. . . . . . . . . . . . . . . > Age STRING,
. . . . . . . . . . . . . . . > Email STRING,
. . . . . . . . . . . . . . . > Address STRING,
. . . . . . . . . . . . . . . > IDNumber STRING,
. . . . . . . . . . . . . . . > PhoneNumber STRING,
. . . . . . . . . . . . . . . > Nationality STRING,
. . . . . . . . . . . . . . . > Region STRING,
. . . . . . . . . . . . . . . > SourceCode STRING
. . . . . . . . . . . . . . . > )
. . . . . . . . . . . . . . . > ROW FORMAT DELIMITED
. . . . . . . . . . . . . . . > FIELDS TERMINATED BY ','
. . . . . . . . . . . . . . . > STORED AS TEXTFILE;
No rows affected (0.147 seconds)
0: jdbc:hive2://hadoop10:10000> LOAD DATA INPATH '/testdir/personInfo/*.csv' INTO TABLE personal_info;
No rows affected (2.053 seconds)
0: jdbc:hive2://hadoop10:10000> select * from personal_info limit 5;
+-----------------------+---------------------+--------------------+----------------------------+------------------------------------------------+-------------------------+----------------------------+----------------------------+-----------------------+---------------------------+
| personal_info.rowkey | personal_info.name | personal_info.age | personal_info.email | personal_info.address | personal_info.idnumber | personal_info.phonenumber | personal_info.nationality | personal_info.region | personal_info.sourcecode |
+-----------------------+---------------------+--------------------+----------------------------+------------------------------------------------+-------------------------+----------------------------+----------------------------+-----------------------+---------------------------+
| Rowkey | Name | Age | Email | Address | IDNumber | PhoneNumber | Nationality | Region | SourceCode |
| 1 | Hayley Jimenez | 58 | garrisonalicia@harris.com | "92845 Davis Circles Apt. 198 East Jerryshire | NV 35424" | 657-35-2900 | (141)053-9917 | DE | North |
| 2 | Amy Johnson | 23 | samuelrivera@hall.com | "119 Manning Rapids Suite 557 New Randyburgh | MN 58113" | 477-76-9570 | +1-250-531-6115 | UK | North |
| 3 | Sara Harper | 31 | gsandoval@hotmail.com | "98447 Robinson Dale Garzatown | ME 35917" | 254-77-4980 | 7958192189 | AU | East |
| 4 | Alicia Wang | 53 | kellyreed@evans.com | "531 Lucas Vista New Laura | MO 62148" | 606-19-1971 | 001-295-093-9174x819 | DE | West |
+-----------------------+---------------------+--------------------+----------------------------+------------------------------------------------+-------------------------+----------------------------+----------------------------+-----------------------+---------------------------+
5 rows selected (0.52 seconds)
四、csv文件首行列名的处理
4.1 创建新的表
解决思路是通过将整表的数据查询出,插入到另一个新表中,而后删除旧的表,该方法如果在生产环境中使用应考虑机器性能和存储情况。
CREATE TABLE pinfo (
Rowkey STRING,
Name STRING,
Age STRING,
Email STRING,
Address STRING,
IDNumber STRING,
PhoneNumber STRING,
Nationality STRING,
Region STRING,
SourceCode STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
查询旧表中的行数。
0: jdbc:hive2://hadoop10:10000> select count(*) from personal_info;
+----------+
| _c0 |
+----------+
| 2131609 |
+----------+
1 row selected (45.762 seconds)
4.2 将旧表过滤首行插入新表
INSERT OVERWRITE TABLE pinfo
SELECT
t.Rowkey,
t.Name,
t.Age,
t.Email,
t.Address,
t.IDNumber,
t.PhoneNumber,
t.Nationality,
t.Region,
t.SourceCode
FROM (
SELECT
Rowkey,
Name,
Age,
Email,
Address,
IDNumber,
PhoneNumber,
Nationality,
Region,
SourceCode
FROM personal_info
) t
WHERE t.Name != 'Name';
0: jdbc:hive2://hadoop10:10000> select * from pinfo limit 5;
+---------------+-------------------+------------+----------------------------+------------------------------------------------+-----------------+--------------------+-----------------------+---------------+-------------------+
| pinfo.rowkey | pinfo.name | pinfo.age | pinfo.email | pinfo.address | pinfo.idnumber | pinfo.phonenumber | pinfo.nationality | pinfo.region | pinfo.sourcecode |
+---------------+-------------------+------------+----------------------------+------------------------------------------------+-----------------+--------------------+-----------------------+---------------+-------------------+
| 1 | Hayley Jimenez | 58 | garrisonalicia@harris.com | "92845 Davis Circles Apt. 198 East Jerryshire | NV 35424" | 657-35-2900 | (141)053-9917 | DE | North |
| 2 | Amy Johnson | 23 | samuelrivera@hall.com | "119 Manning Rapids Suite 557 New Randyburgh | MN 58113" | 477-76-9570 | +1-250-531-6115 | UK | North |
| 3 | Sara Harper | 31 | gsandoval@hotmail.com | "98447 Robinson Dale Garzatown | ME 35917" | 254-77-4980 | 7958192189 | AU | East |
| 4 | Alicia Wang | 53 | kellyreed@evans.com | "531 Lucas Vista New Laura | MO 62148" | 606-19-1971 | 001-295-093-9174x819 | DE | West |
| 5 | Lauren Rodriguez | 71 | rebeccasaunders@yahoo.com | "060 Gomez Ports Suite 355 Lake Aarontown | CO 38284" | 186-61-7463 | 8458236624 | DE | East |
+---------------+-------------------+------------+----------------------------+------------------------------------------------+-----------------+--------------------+-----------------------+---------------+-------------------+
5 rows selected (0.365 seconds)
0: jdbc:hive2://hadoop10:10000>
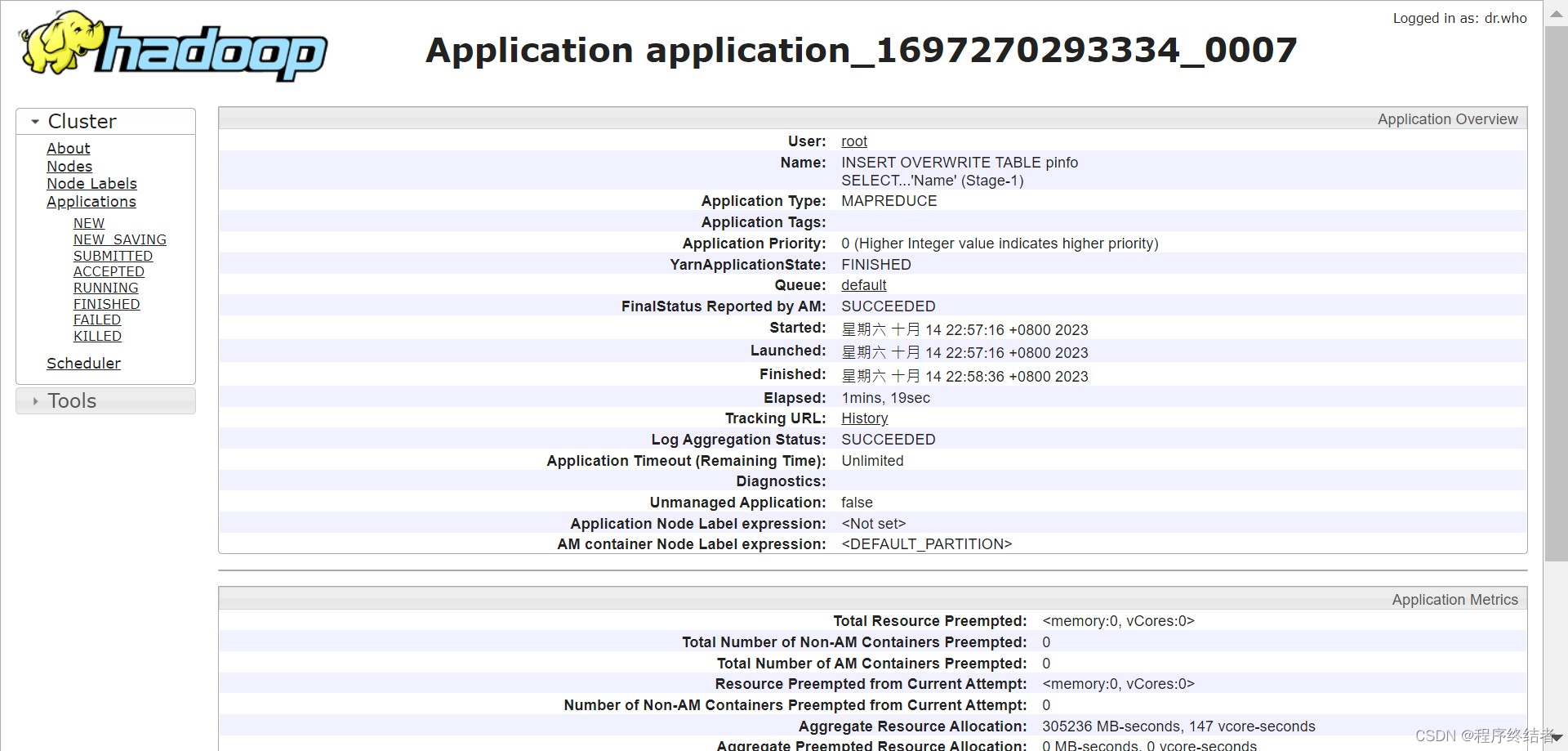
在yarn中查看新表插入的进度。
最后新表的查询结果显示比旧表少1行即为插入处理完成。
0: jdbc:hive2://hadoop10:10000> select count(*) from pinfo;
+----------+
| _c0 |
+----------+
| 2131608 |
+----------+
1 row selected (0.291 seconds)