文章目录
- 前言
- 在数组中寻找第K大的元素
- 堆排序原理
- 合并K个排序链表
- 总结
前言
提示:想要从讨厌的地方飞出来,就得有藏起来的翅膀。 --三岛由纪夫《萨德侯爵夫人》
这里我们主要看一下经典的题目,这三个题目来说都是堆的热点问题。重点再理解处理方式就行。
在数组中寻找第K大的元素
参考题目地址:215. 数组中的第K个最大元素 - 力扣(LeetCode)


这个题目的道理非常简单,主要的方法有三种:
- 选择法
- 堆查找法
- 快速排序法
选择法很简单,就是遍历一边找到最大的元素,然后再遍历一遍找第二大的,然后再遍历一遍找第三大…直到第K次,就可以找到目标值。但是这种方法只适合面试的时候预热,面试官不会让你写这么简单的代码,因为这个方法的时间复杂度为O(NK)。
比较好的方法就是堆排序和快速排序。快速排序我们已经分析过了,这里看看堆排序的,看看怎么解决。
快排推荐⭐⭐⭐⭐:算法通过村第十关-快排|青铜笔记|快排也没那么难-CSDN博客
其实这个题目采用大顶堆和小顶堆都是可以解决的,但是我们这里推荐**“找最大用最小,找最小用最大”**,找中间用两个堆呗,这样更容易理解,适用的范围也更广。我们构造一个大小只有4的小顶堆,为了更好说明问题,我们扩展以下序列:【3,2,3,1,2,4,5,1,5,6,2,3】。
堆满了之后,对于小顶堆,并一定所有新来的元素都可以入堆的,只有大于根元素的才可以插入到堆中,否则就直接抛弃掉。这是一个重要的前提。
另外元素进入的时候,先替换根元素,如果发现左右两个子树都小该怎么办呢?很显然应该是更小的那个比较,这样才能保证根元素一定是当前堆最小的。假如两个子孩的值一样呢?那就随便选一个。
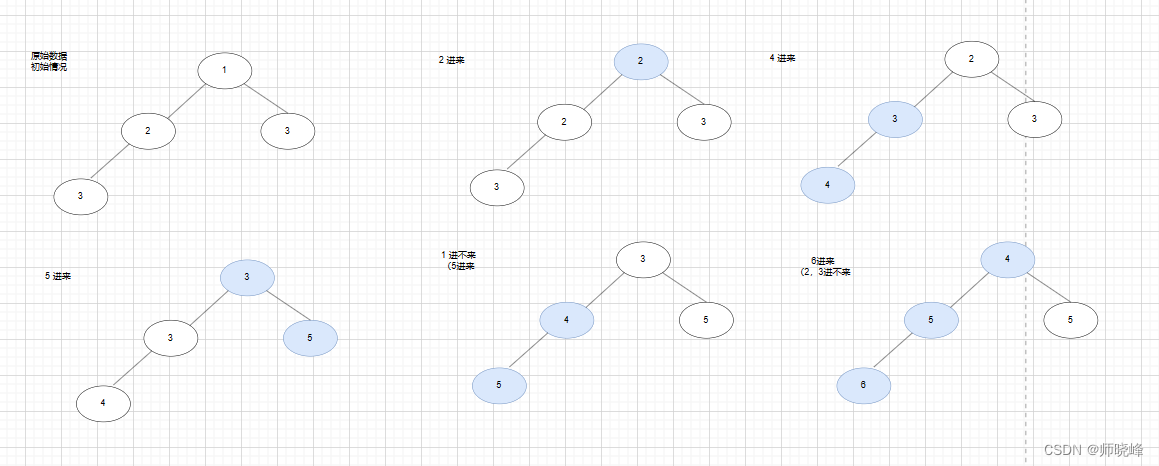
新元素插入的时候只是替换根元素,然后重新构造小顶堆,完成之后,你会神奇的发现此时根的元素正好是第四大的元素。
这时候你会发现,不管要处理多大的序列,或者是不是固定的,根元素每次都是恰好是当前序列下的第K大的元素。上面图的篇幅优先,注意省略了一部分调成的环节,这里好好看看。
上面的代码自己实现起来非常困难,我们可以借助JDK的优先队列来解决,其思路是很简单的。由于第K大的元素,其实就是整个数组排序以后后面半部分最小的那个元素,这里就可以注意,我们可以维护一个有K个元素的最小堆:
- 如果当前堆不满,直接添加
- 堆满的时候,如果新读到的数小于等于堆顶,肯定不是我们要找的元素,只有新遍历到的数大于堆顶的时候,才能将堆顶拿出,然后放入新读到的数,进而让堆自己去调整内部的结构。
说明:这里最适合的操作其实是replace(),即直接把新读到的元素放入堆顶,然后执行下沉(siftDown())操作。Java中PriorityQueue没有提供这个操作,只好先poll再offer
优先队列的写法有很多,这里只例举一个有代表性,其他的写法都差不多,没有本质区别。
看代码如下:
/**
* 数组中的第K个最大元素
* @param nums
* @param k
* @return
*/
public static int findKthLargest(int[] nums, int k) {
// 当然k不合理,就直接结束
if (k > nums.length) {
return -1;
}
// 获取数组长度
int n = nums.length;
// 创建包含k个元素的小顶堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>(k, (a, b) -> a - b);
for (int i = 0; i < k; i++) {
minHeap.add(nums[i]);
}
for (int i = k; i < n; i++) {
// 获取堆顶元素 比较是否需要替换
Integer topEle = minHeap.peek();
// 这里只有大于 才能进
if (nums[i] > topEle) {
minHeap.poll();
minHeap.offer(nums[i]);
}
}
return minHeap.peek();
}
堆查找与一般的查找一个显著的优势点是可以对于超大数量的数据进行查找,还能堆数量位置的流数据进行查找。推荐一个题目⭐⭐⭐⭐:
703. 数据流中的第 K 大元素 - 力扣(LeetCode)
这里重要的是记住:找第k大用小顶堆,找第K小用大顶堆。
具体来说:
k多大就建立多大的固定堆
找最大用小顶堆
只和根元素比较,满足条件在能进去
堆排序原理
查找:找小用大,找大用小
排序:升序用小,降序用大
前面介绍了如何使用堆来进行特殊情况的查找,堆的另一个很重要的作用就是排序,那么要怎么排序呢?其实非常简单,我们直到再大顶堆中,根节点是整个结构最大的元素,我们将其拿走,剩下的元素将会重排,此时根节点的第二大的元素,我们再拿走,依次类推。最后堆只剩一个元素的时候,是不是拿走的数据也就排好了?
具体来说,建堆结束之后,数组中的数据已经按照大顶堆的特性来组织了,数组中的第一个元素就是堆顶,也就是最大元素,我们只要他和最后一个元素交换,那个最大元素就放到下标为n的位置上了。
这个过程上面有点类型“删除堆顶元素”的操作,当堆顶元素移除之后,我们把剩下标为n的元素放到堆顶,然后再通过堆的结构化调整,将剩下的n - 1个元素重新构建成堆,堆调整之后,我们再去取元素,这样一直循环,直至重复下去,直到堆最后剩下一个元素,也就是排序完成了。
当然再上面的过程用,放到最后一个位置的元素就不参与排序和计算了。
看一个例子,我们对一个序列进行排序[2,21,4,53,64,78,90,102],先构造大顶堆,然后然根元素出堆,继续调整大顶堆:
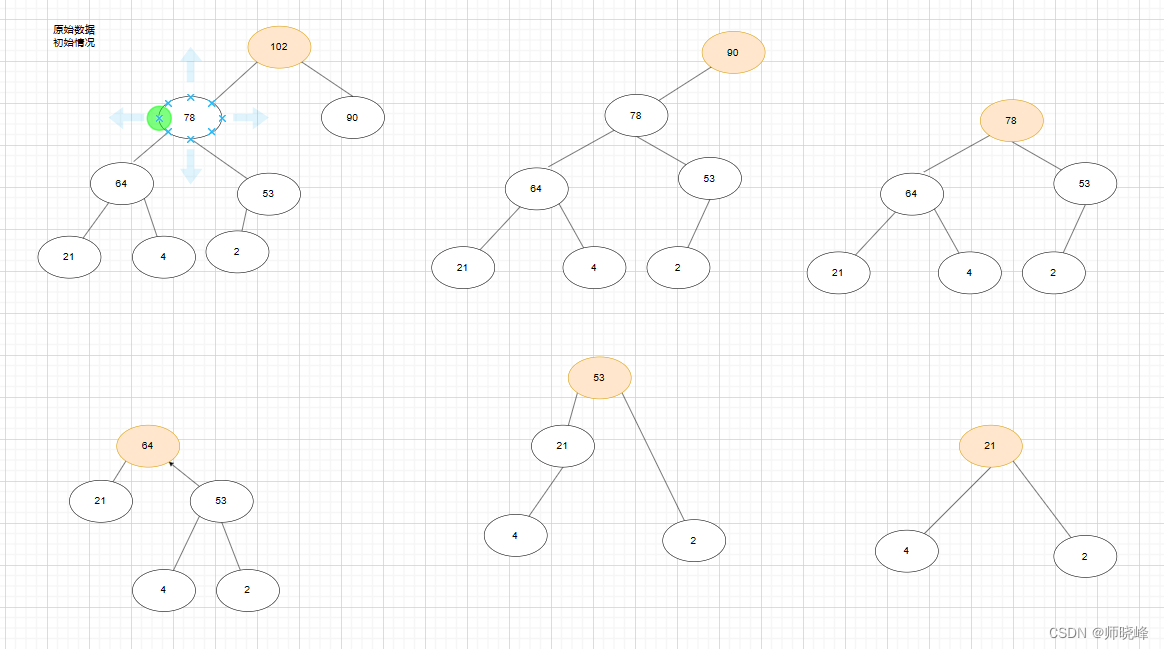
这时候你会发现出堆的序列刚好是:102,90,78,64,53…。也就是从大到小排列。
所以这里可以明白了,如果是小顶堆的化,自然是升序的。所以再排序的时候:
升序用小,降序用大。
记住这个对解题很有用。
合并K个排序链表
参考题目介绍:23. 合并 K 个升序链表 - 力扣(LeetCode)



这个问题的解法五花八门,我们看下用堆排序要怎么处理,因为每个队列都是从小到大排序的,我们每次需要拿到最小值,也就是说我们需要使用小顶堆,构建党法和操作与大顶堆完全一样,不同的是每次比较谁更小。使用堆和并的策略是不过几个链表,最终都是按照顺序来的。每次都是剩余节点的最小值加到输出链表的尾部,然后进行堆的调整,最后合并就完成了。
还有一个问题,这个堆应该有多大呢,给了对少个链表,堆就定义多大。
/**
* 合并 K 个升序链表
*
* @param lists
* @return
*/
public ListNode mergeKLists(ListNode[] lists) {
if (lists.length == 0 || lists == null) {
return null;
}
// 创建堆
PriorityQueue<ListNode> q = new PriorityQueue<ListNode>(Comparator.comparing(node -> node.val));
for (int i = 0; i < lists.length; i++) {
if (lists[i] != null) {
q.add(lists[i]);
}
}
// 虚拟节点
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
while (!q.isEmpty()) {
tail.next = q.poll(); // 取最小
tail = tail.next; // 链接下一个
if (tail.next != null) { // 判断是否到底
q.add(tail.next); // 重复下一个
}
}
return dummy.next;
}
总结
提示:堆经典问题;大顶堆和小顶堆;手绘原理;堆排序解析;堆查询特点
如果有帮助到你,请给题解点个赞和收藏,让更多的人看到 ~ ("▔□▔)/
如有不理解的地方,欢迎你在评论区给我留言,我都会逐一回复 ~
也欢迎你 关注我 ,喜欢交朋友,喜欢一起探讨问题。