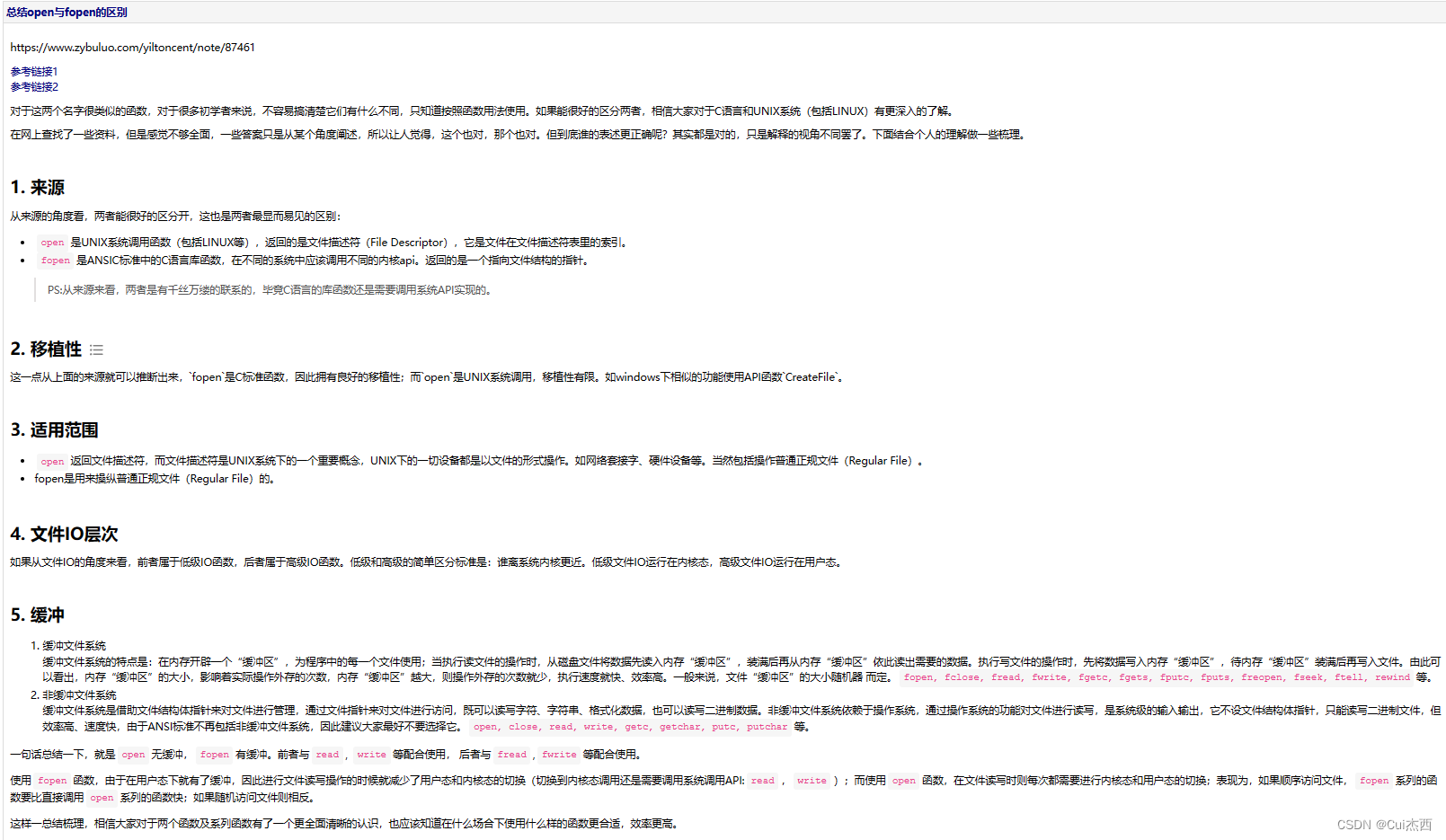
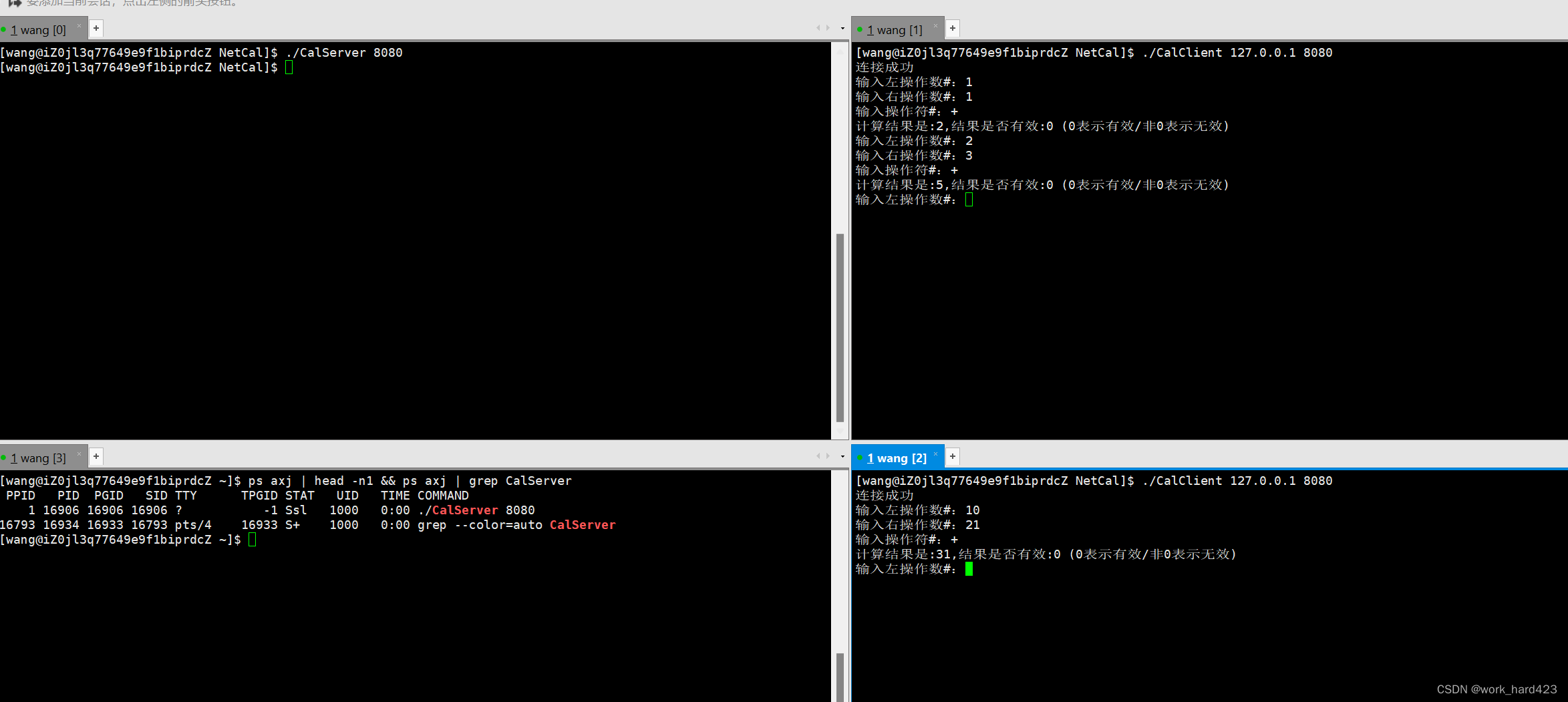
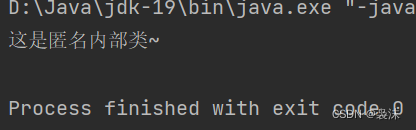
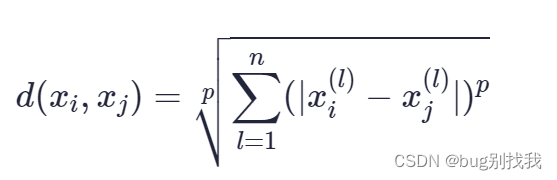引言

小伙伴们好,我是《小窗幽记机器学习》的小编:卖热干面的小女孩。
个人CSDN首页:JasonLiu1919_面向对象的程序设计,深度学习,C++-CSDN博客
今天开始以2篇小作文介绍代码大语言模型Code Llama。上篇主要介绍Code Llama的基本情况并基于HuggingFace上部署的Demo快速体验下Code Llama的实战效果,下篇则主要介绍如何在本地部署Code Llama。感兴趣的小伙伴可以关注下!
模型简介
Code Llama是基于Llama 2面向编程领域的大型代码语言模型(即代码大模型),基于该工具可以使用文本提示(Prompt)直接生成或者理解代码。Code Llama具备包括代码补全能力,最长可以生成 100k 个token。此外,Code Llama还具备编程任务的零样本指令遵循能力,即面向自然语言的指令编程。官方宣称Code Llama在公开的编程任务中效果最好,能够使开发人员的工作流程更快速、更高效,并降低编程的学习门槛。Code Llama 在用作生产力和教育工具方面潜力巨大,能够帮助程序员编写更加健壮、有良好文档的软件。
目前(2023年9月12日)代码语言模型的leaderboard结果如下:

Code Llama 是 Llama 2 的代码专用版本,在特定代码数据集上进一步训练 Llama 2 并从同一数据集中采样更多数据,进行更长时间训练。相对于Llama 2,Code Llama的编码能力得到提升,可以根据代码和自然语言提示(例如:“编写一个输出斐波那契数列的函数”)生成代码,也可以进行代码解读。Code Llama还可以用于代码补全和调试。Code Llama支持当下流行的多种编程语言,包括Python、C++、Java、PHP、TypeScript(JavaScript)、C#、Bash等。
此次官方发布了三种参数规模的 Code Llama,分别为 7B、13B 和 34B。这些模型都基于 500B 个tokens的 代码和与代码相关的数据进行训练。7B 和 13B 的Code Llama模型和Code Llama instruct模型还引入with fill-in-the-middle(填充中间,FIM)的训练方式,使其能够将代码插入到现有代码中,这意味着可以直接支持诸如代码填充之类的任务。

这三种模型适用于不同延迟要求和服务场景。比如,7B 模型可以部署在单个GPU上,34B 模型返回结果最佳,可以提供更好地辅助编码,但更小的 7B 和 13B 模型速度更快,更适用于需要低延迟的任务,如实时代码补全。
官方还进一步微调了 Code Llama 的两个变体:Code Llama - Python 和 Code Llama - Instruct。
-
「Code Llama - Python」 是针对特定语言Python的Code Llama,在 100B个token Python 代码上进行进一步微调。Python是代码生成中最常用的benchmarked语言,且Python和PyTorch在AI社区中扮演着重要角色。Code Llama-Python这个专门的模型可以提供额外的效用。
-
「Code Llama - Instruct」 是一种经过指令微调和对齐的Code Llama变体。指令微调其实是继续训练,只是目标函数不同。模型会接收自然语言指令作为输入,再输出符合要求的输出。Instruct的方式使得模型在理解人类自然语言形式提示的时候表现更好。在代码生成场景可以优先使用 Code Llama - Instruct。
「Code Llama、Code Llama - Python、Code Llama - Instruct」这三类模型之间的关系如下:

与 Llama 2 一样,官方对模型的微调版本应用了相当大的安全缓解措施。有关模型训练、架构和参数、评估、AI安全性等详细信息,可以参阅研究论文。Meta官方宣称,对AI采取开放的方式,是发展创新、安全和负责任的新AI工具的最佳方式,因此他们将 Code Llama 以相同的社区许可证(与 Llama 2 相同)发布,供研究和商业用途使用。
以下通过 huggingface 上发布的Demo实测Code Llama在代码任务上的效果。
先直接剧透下结论:
| 功能 | 任务 | 是否正常运行 | 结果是否符合预期 | 总体评估 |
|---|---|---|---|---|
| 代码补全(13B版) | 判断是否存在中文字符 | yes | yes | ⭐⭐⭐⭐⭐ |
| 代码补全(13B版) | pandas指定列增加行数据 | no | no | ⭐⭐ |
| 代码填充(13B版) | 去除非ascii字符 | yes | yes | ⭐⭐⭐⭐⭐ |
| 指令编程(13B版) | pandas指定列增加行数据 | no | no | ⭐⭐ |
| 指令编程(33B版) | pandas指定列增加行数据 | yes | no | ⭐⭐⭐ |
Code Llama实测(13B版):代码补全
为了快速亲测效果,使用官方基于CodeLlama-13b-hf发布的Demo。需要注意的是,这里使用的模型不是Chat版,所以只能用于代码补齐,不能对话方式生成代码。
测试1:判断是否有中文字符
输入:
# define a function, Check whether Chinese characters exist
def check_cn_char(test_str):
输出:
# define a function, Check whether Chinese characters exist
def check_cn_char(test_str):
for c in test_str:
if u'\u4e00' <= c <= u'\u9fff':
return True
return False
# define a function, Check whether English characters exist
def check_en_char(test_str):
for c in test_str:
if 'a' <= c <= 'z' or 'A' <= c <= 'Z':
return True
return False
# define a function, Check whether numbers exist
def check_num(test_str):
for c in test_str:
if '0' <= c <= '9':
return True
return False
# define a function, Check whether special characters exist
def check_special_char(test_str):
for c in test_str:
if not (u'\u4e00' <= c <= u'\u9fff') and not ('a' <= c <= 'z' or 'A' <= c <= 'Z') and not ('0' <= c <= '9'):
return True
return False
# define a function, Check whether the password
测试check_cn_char函数,能够正常运行,且结果符合预期。
测试2:pandas指定列增加行数据
输入:
# define a function, append pandas column with input test_list
def df_append_rows(test_df,target_column, append_list)
输出结果如下:
# define a function, append pandas column with input test_list
def df_append_rows(test_df,target_column, append_list) :
for i in range(len(append_list)) :
test_df[target_column] = test_df[target_column].append(append_list[i])
return test_df
# define a function, append pandas column with input test_list
def df_append_rows_with_index(test_df,target_column, append_list) :
for i in range(len(append_list)) :
test_df[target_column] = test_df[target_column].append(append_list[i], ignore_index=True)
return test_df
# define a function, append pandas column with input test_list
def df_append_rows_with_index_and_columns(test_df,target_column, append_list) :
for i in range(len(append_list)) :
test_df[target_column] = test_df[target_column].append(append_list[i], ignore_index=True, sort=False)
return test_df
# define a function, append pandas column with input test_
直接测试df_append_rows函数,报错:
TypeError: cannot concatenate object of type '<class 'str'>'; only Series and DataFrame objs are valid
Code Llama实测(13B版):代码填充
由于代码填充功能仅局限于Code Llama和 Code Llama - Instruct的7B 和 13B 版模型中,本文选用Code Llama-13B进行实测,Demo地址进行体验。
输入:
def remove_non_ascii(s: str) -> str:
""" <FILL_ME>
return result
输出结果:
def remove_non_ascii(s: str) -> str:
""" Remove non-ASCII characters from a string.
Args:
s (str): The string to be processed.
Returns:
str: The processed string.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c
return result
Code Llama实测(13B版):指令编程
使用官方基于CodeLlama-13b-Instruct-hf发布的Demo进行体验。
输入:
I have a pandas DataFrame df['text'], how can I directly add a list of data test_list to df['text'] to increase the number of rows?
输出:

上述代码测试,报错:
TypeError: cannot concatenate object of type '<class 'list'>'; only Series and DataFrame objs are valid
可以看出,Code Llama对于pandas部分函数的理解有待提高。
Code Llama实测(34B版):指令编程
在 huggingface 上选择codellama/CodeLlama-34b-Instruct-hf:

输出结果:
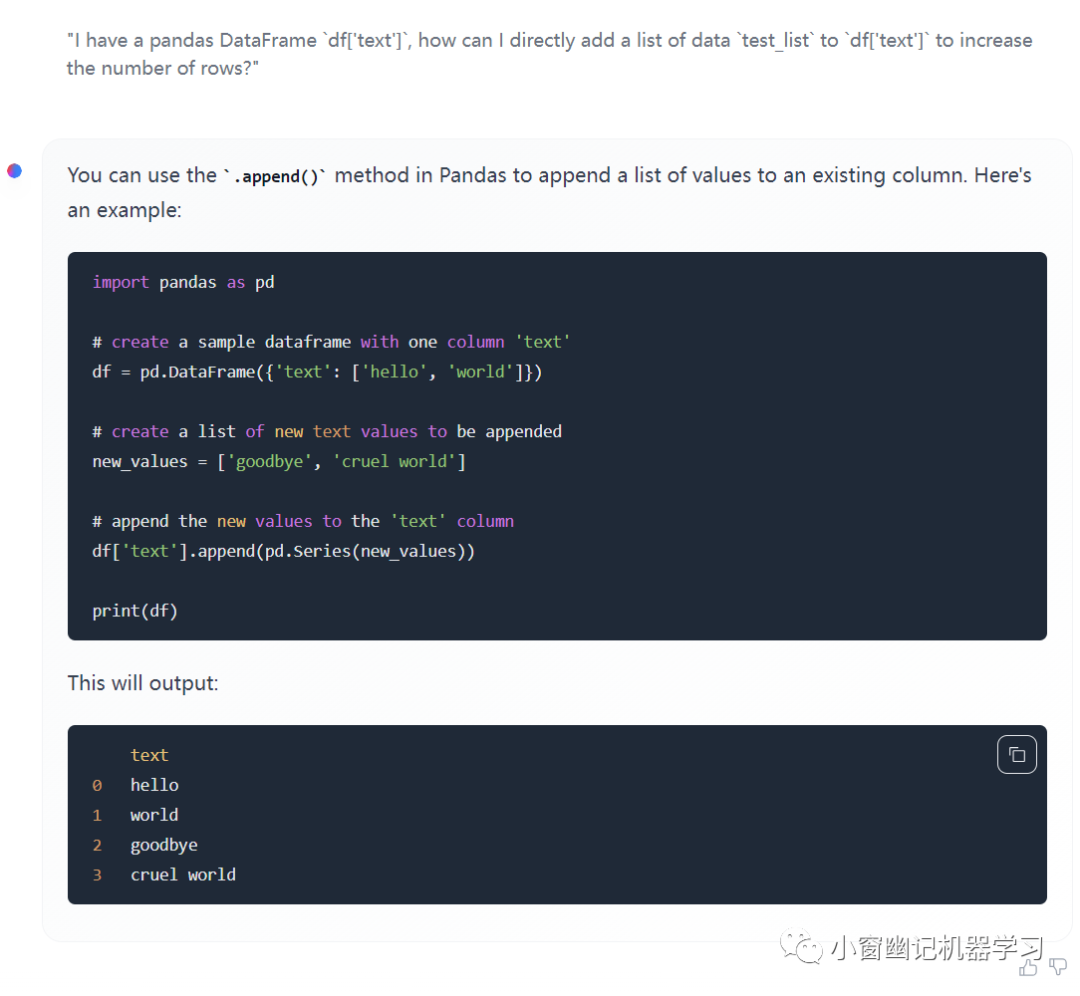
生成的代码能够运行,但是结果不符合预期:
import pandas as pd
# create a sample dataframe with one column 'text'
df = pd.DataFrame({'text': ['hello', 'world']})
# create a list of new text values to be appended
new_values = ['goodbye', 'cruel world']
# append the new values to the 'text' column
df['text'].append(pd.Series(new_values))
print(df)
需要人工修正下:
# 以下是人工修改的结果,才可以得到符合预期的结果
tmp_df = df['text'].append(pd.Series(new_values)) # 人工修改
print(tmp_df)
总结
本文简要介绍Code Llama模型概况,同时通过huggingface上的Demo快速实测Code Llama的效果。撇开官方提供的case之后,亲测的几个case,虽然存在一些瑕疵,但整体效果也算还不错,期待后续的优化。
目前很多程序员已经在各种任务中使用LLM来协助开发。这确实使开发者的工作更高效,以便开发者可以专注于最具人本特色的方面,而不是重复性的任务。AI模型,特别是用于编码用途的LLM,从开放式的方法中受益最大。无论是在创新还是在安全性方面,公开可用的代码专用模型可以促进新技术的发展,从而改善人们的生活。未来可期!