文章目录
- 并发的理解
- 程序运行时的数据
- 进程切换的过程
- 内核的调度队列和调度原理
并发的理解
前面总结到了,关于并发的概念,并发针对的是单核的CPU上同时运行很多情况,并不是某个程序在CPU上运行就一直运行,而是根据一定的时间片和调度算法来进行合理的调度,因而引出了优先级的概念,造成的最终目的就是可以让每一个进程都享受到CPU上的资源,否则会导致进程饥饿
那么本篇来解决的两个问题:
- 操作系统是如何进行调度的?
- 在进行进程切换的过程中会发生什么事?
程序运行时的数据
从学C语言开始,就有各种各样的函数,有些函数是有返回值的,可以被函数外的变量进行接收,但是由函数的栈帧我们知道,函数在创建后,执行到最后函数栈帧是会被销毁的,但函数的数据呢?外面的程序要进行接收的数据从哪里进行获取?
实际上,在函数的栈帧中其实已经知道了,函数栈帧的传值是通过CPU中的寄存器进行的传值,其实在程序运行的过程中,产生的各种各样的临时数据都被存储在寄存器中,而在CPU要进行进程切换的时候,就会把现在当前正在运行的程序的一些临时数据都存储到一个地方,在老版本的内核中,这个存储的位置就是进程的PCB,在现在的版本中并不是直接放在进程的PCB中,但也是和进程的PCB相关的存储位置,也就是说程序运行时的数据是直接或间接的存储在PCB中,这样在未来,当这个进程重新被调回来的时候,寄存器可以从进程的PCB中获取到当时运行的位置时产生的数据,再在此基础上进行接着运行,这样就可以实现进程的切换,但是程序运行时产生的数据不会被丢失的情况
进程切换的过程
有了上面的铺垫,进程的切换过程是通俗易懂的,用下图来表示:

要注意的是,在进行进程切换的过程中,程序B的临时数据是直接在A程序的寄存器上运行的,直接进行的是数据的覆盖,而不是先清空寄存器的数据再进行使用
内核的调度队列和调度原理
下面来解决的是,Linux内核中是如何进行调度队列的呢?调度原理又是什么?
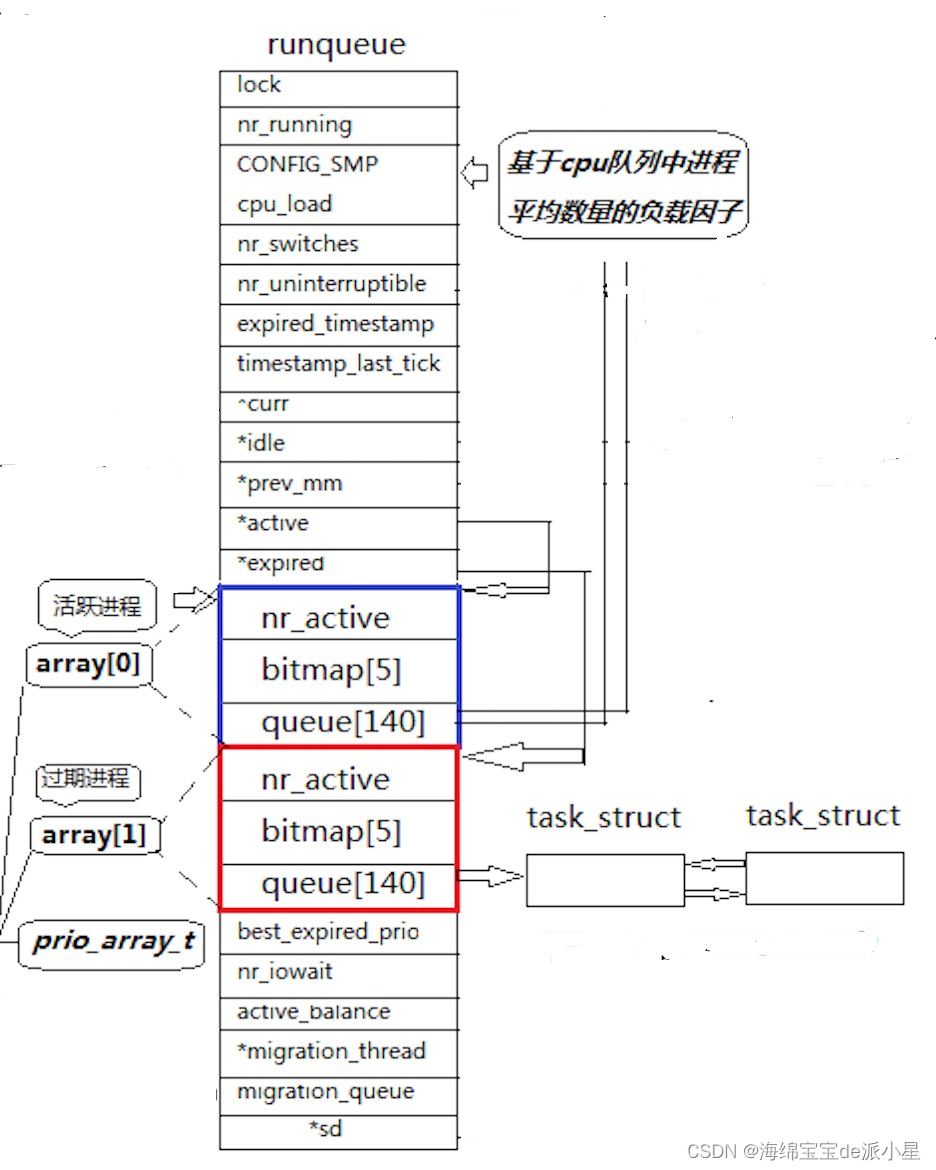
上面这张图展示的就是Linux内核中的调度队列示意图,那么具体是如何进行队列调度的呢?
首先,图中有两个queue[140],这个就是所谓的队列结构,其中有一个就是所谓的运行队列,也就是直接向CPU上进行调度的结构,那么140就意味着这当中有140个格子,每个格子对应的是一个优先级,对于0-99号格子是普通优先级,目前不考虑它的作用,而对于100-139号格子,对应的是优先级为60-99,每当有一个优先级为这个区间内的进程来临的时候,就将它放到对应格子的队列中,这样CPU就可以在调度的时候,根据优先级的大小来进行调度了
其次,为什么这里有两个queue?假设下面的场景,有一个优先级为99的进程,它的优先级是最低的,从理论上来说应该是被最后进行调度的进程,但是在前面进程运行的过程中,一直有优先级为80的进程不断的插入队列,不停的插入,那么就意味着这个优先级为99的进程始终不能被放到CPU上运行,CPU的资源无法供应到这个进程,就会造成进程饥饿现象,对于这种情况,调度队列的设计就采用了两个队列来进行解决这个问题,对于一个进程想要进入待调度的队列中,会把它放在另外一个队列中,CPU会优先调度CPU目前维护的队列,当这个队列中的程序全部都运行结束后,再调度另外一个队列中的进程,那么CPU如何知道自己现在要调度哪一个队列?这就用到了另外两个参数,分别是*active和*expired,这两个参数表示的就是目前CPU正在调度的队列和CPU以后会调度的队列,当active队列中的进程全部调度结束后,就和expired队列进行交换,再接着进行运行,新插入的进程始终都是插入到expired队列中的
最后,是关于CPU如何知道队列中的调度状态的问题,通常来说是通过遍历就可以知道调度情况,但是Linux内核是采用的位图的思想,在蓝红框所框选的内容中,还有一个是bitmap,里面存储了五个数据,这五个数据本质上都是int类型的数据,而一个int是32个bit位,而五个就是160个bit位,正好可以存储下对应的140个队列中的状态值,如果某个位置有等待运行的进程,就将这个进程对应的优先级找到在位图中的位置,再将它标记位1即可,这样就完成了标记
用了如此大的篇幅,讲清楚了内核中的调度队列和调度原理,整个算法流程的时间复杂度是O(1),因此它的名字就叫做进程调度的O(1)算法





![[23] T^3Bench: Benchmarking Current Progress in Text-to-3D Generation](https://img-blog.csdnimg.cn/3138c2fb35ee4adb8d30bcaf423a72e6.png)