Spring Boot 和 Spring Data JPA 的 Demo演示
我们利用 JPA + Spring Boot 简单做一个 RESTful API 接口,方便你来了解 Spring Data JPA 是干什么用的,具体步骤如下。
第一步:利用 IDEA 和 SpringBoot 2.3.3 快速创建一个案例项目。
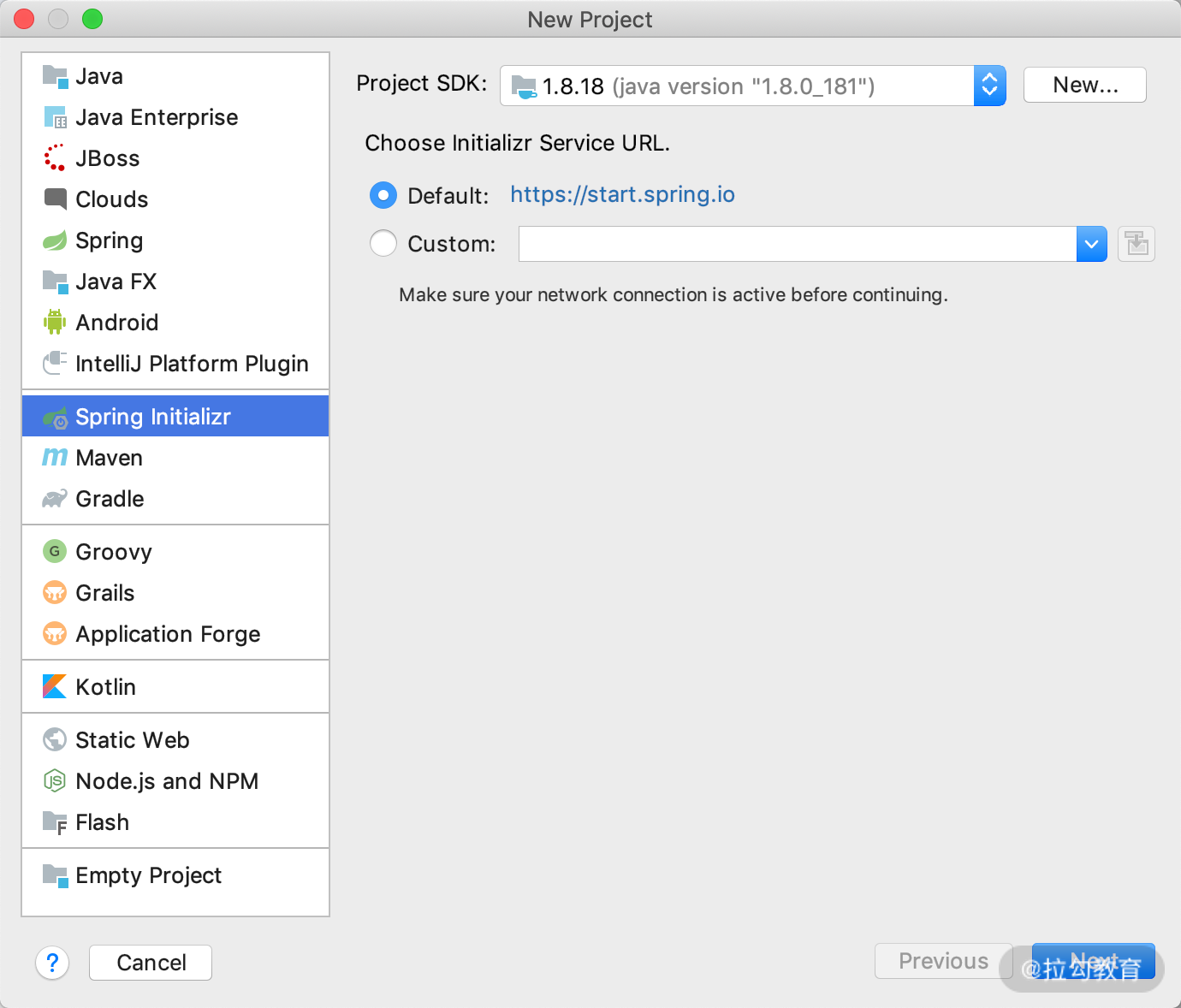
点击“菜单” | New Project 命令,选择 Spring Initializr 选项,如下图所示。
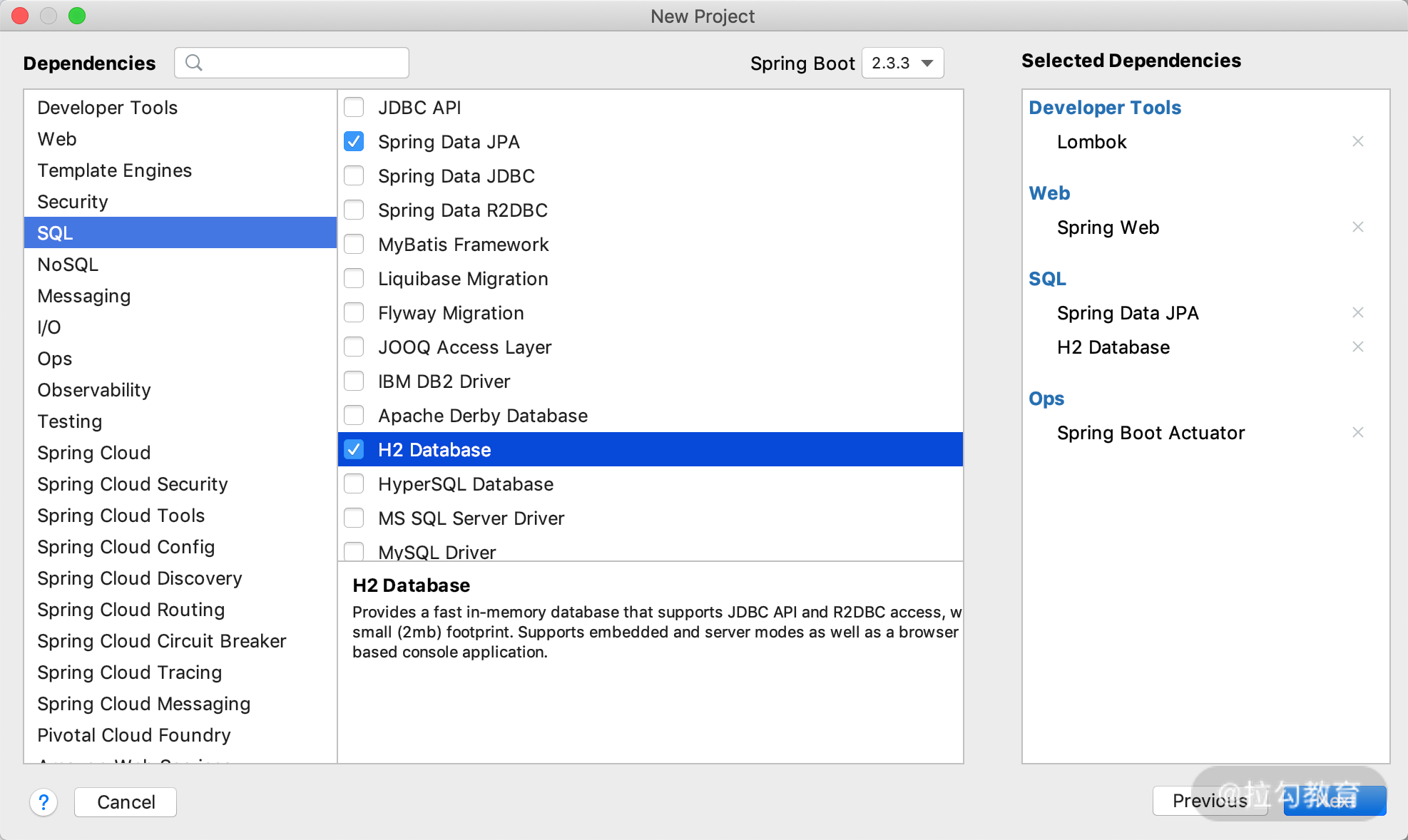
这里我们利用 Spring 官方的 Start 来创建一个项目,接下来选择 Spring Boot 的依赖:
- Lombok:帮我们创建一个简单的 Entity 的 POJO,主要用来省去创建 GET 和 SET 方法;
- Spring Web:MVC 必备组件;
- Spring Data JPA:重头戏,这是本课时的重点内容;
- H2 Database:内存数据库;
- Spring Boot Actuator:监控我们项目状态使用。
然后通过下图操作界面选择上面提到的这些依赖,如下图所示:
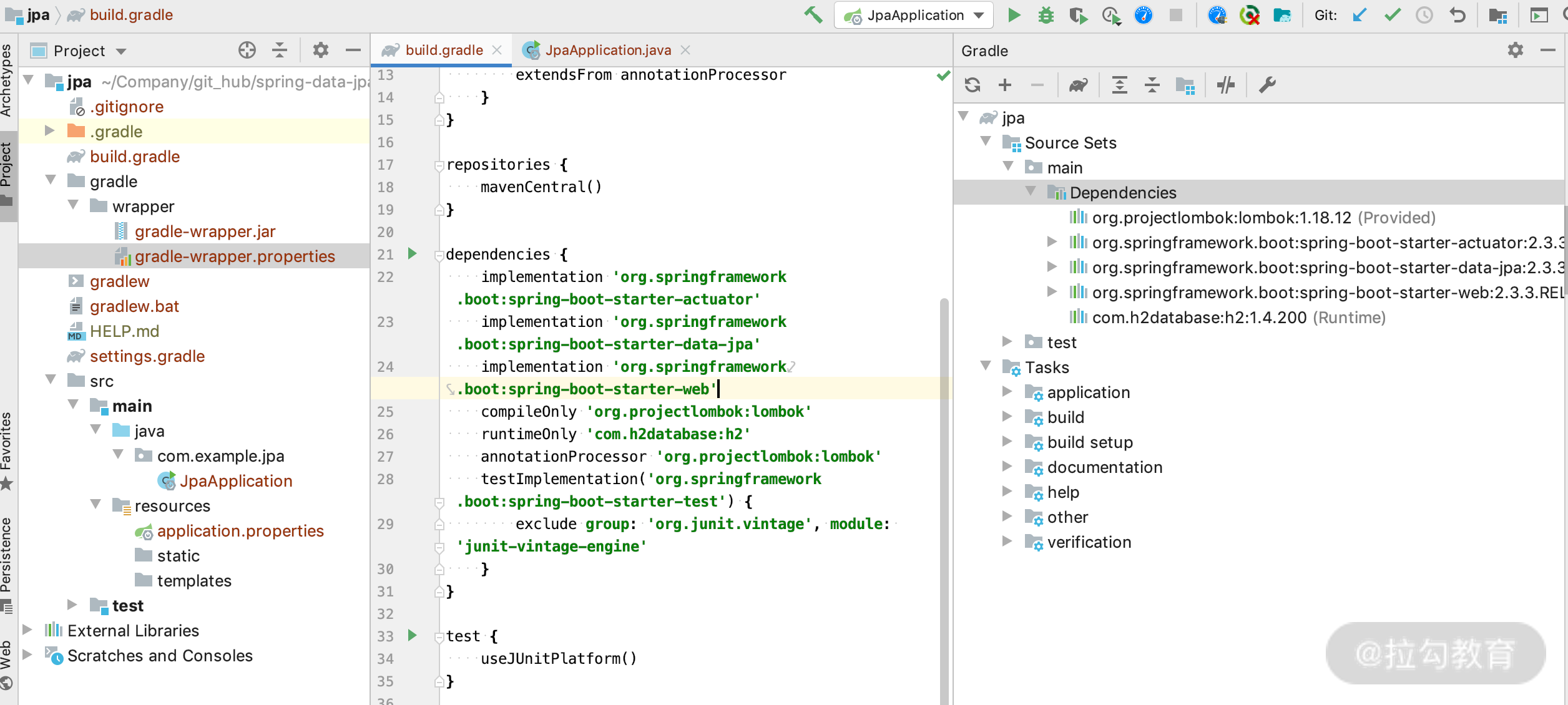
第二步:通过 IDEA 的图形化界面,一路单击 Next 按钮,然后单击 Finsh 按钮,得到一个工程,完成后结构如下图所示:
现在我们已经可以创建一个 Spring Boot + JPA 的项目了,那么接下来我们看看怎么对 User 表进行增删改查操作。
第三步:新增 3 个类来完成对 User 的 CURD。
第一个类:新增 User.java,它是一个实体类,用来做 User 表的映射的,如下所示:
复制代码
package com.example.jpa.example1;
import lombok.Data;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
@Data
public class User {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
}
第二个类:新增 UserRepository,它是我们的 DAO 层,用来操作实体 User 进行增删改成操作,如下所示:
复制代码
package com.example.jpa.example1;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User,Long> {
}
第三个类:新增 UserController,它是 Controller,用来创建 Rest 的 API 的接口的,如下所示:
复制代码
package com.example.jpa.example1;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping(path = "/api/v1")
public class UserController {
@Autowired
private UserRepository userRepository;
/**
* 保存用户
* @param user
* @return
*/
@PostMapping(path = "user",consumes = {MediaType.APPLICATION_JSON_VALUE})
public User addNewUser(@RequestBody User user) {
return userRepository.save(user);
}
/**
* 根据分页信息查询用户
* @param request
* @return
*/
@GetMapping(path = "users")
@ResponseBody
public Page<User> getAllUsers(Pageable request) {
return userRepository.findAll(request);
}
}
最终,我们的项目结构变成如下图所示的模样:
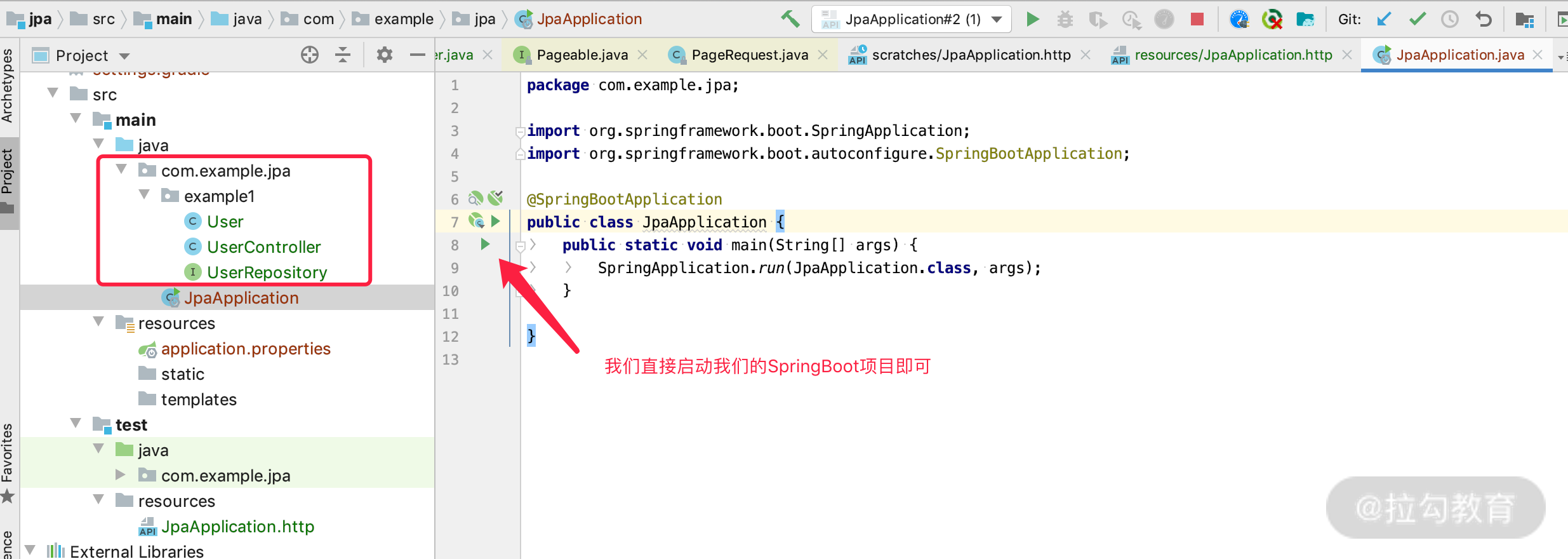
上图中,appliaction.properties 里面的内容是空的,到现在三步搞定,其他什么都不需要配置,直接点击 JpaApplication 这个类,就可启动我们的项目了。
第四步:调用项目里面的 User 相关的 API 接口测试一下。
我们再新增一个 JpaApplication.http 文件,内容如下:
复制代码
POST /api/v1/user HTTP/1.1
Host: 127.0.0.1:8080
Content-Type: application/json
Cache-Control: no-cache
{"name":"jack","email":"123@126.com"}
#######
GET http://127.0.0.1:8080/api/v1/users?size=3&page=0
###
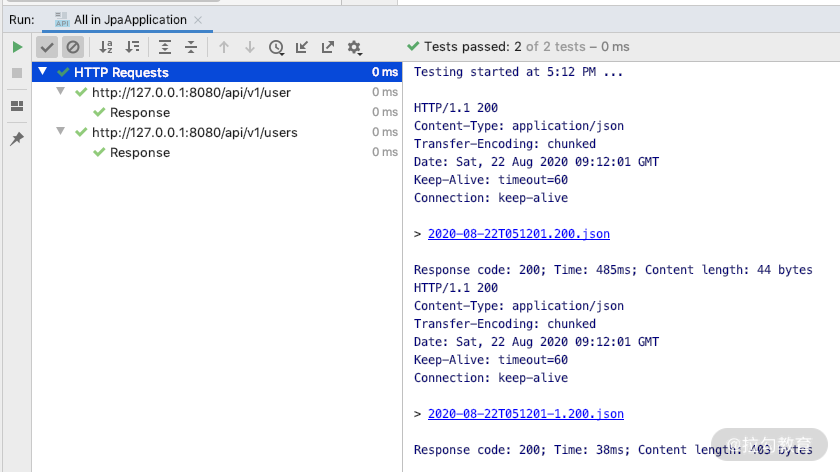
点击“运行”按钮,效果如下图所示:
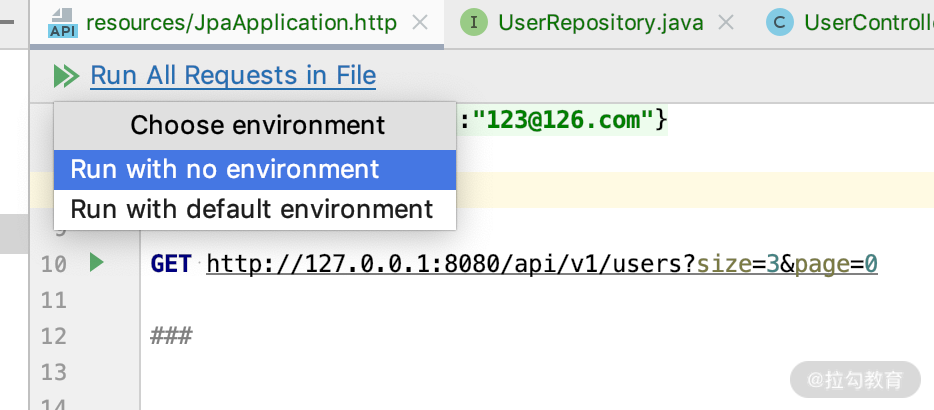
运行结果如下:
复制代码
POST http://127.0.0.1:8080/api/v1/user
HTTP/1.1 200
Content-Type: application/json
Transfer-Encoding: chunked
Date: Sat, 22 Aug 2020 02:48:43 GMT
Keep-Alive: timeout=60
Connection: keep-alive
{
"id": 4,
"name": "jack",
"email": "123@126.com"
}
Response code: 200; Time: 30ms; Content length: 44 bytes
GET http://127.0.0.1:8080/api/v1/users?size=3&page=0
HTTP/1.1 200
Content-Type: application/json
Transfer-Encoding: chunked
Date: Sat, 22 Aug 2020 02:50:20 GMT
Keep-Alive: timeout=60
Connection: keep-alive
{
"content": [
{
"id": 1,
"name": "jack",
"email": "123@126.com"
},
{
"id": 2,
"name": "jack",
"email": "123@126.com"
},
{
"id": 3,
"name": "jack",
"email": "123@126.com"
}
],
"pageable": {
"sort": {
"sorted": false,
"unsorted": true,
"empty": true
},
"offset": 0,
"pageNumber": 0,
"pageSize": 3,
"unpaged": false,
"paged": true
},
"totalPages": 2,
"last": false,
"totalElements": 4,
"size": 3,
"number": 0,
"numberOfElements": 3,
"sort": {
"sorted": false,
"unsorted": true,
"empty": true
},
"first": true,
"empty": false
}
Response code: 200; Time: 59ms; Content length: 449 bytes
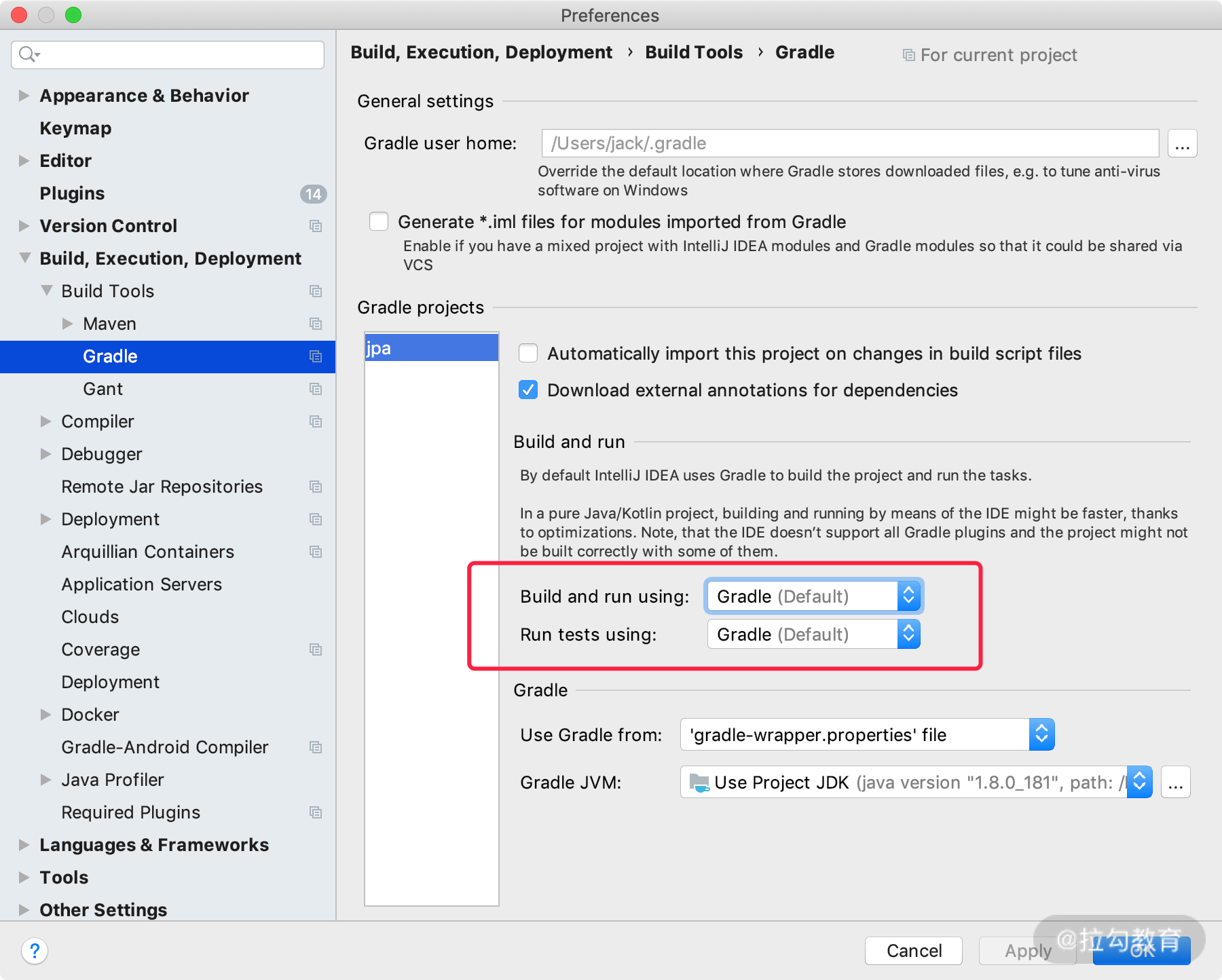
关于 IDEA 运行 Gradle 项目的小技巧: 在实际工作中,我们启动运行或者是跑测试用例的时候,经常以 Gradle 的方式运行,或者用 Application 的方式运行,两种方式进行随意切换,需要设置的地方如下图所示:
通过以上案例,我们知道了 Spring Data JPA 可以帮我们做数据的 CRUD 操作,掌握到了JPA + Spring Boot 如何启动和集成 JPA,以及对如何创建一个数据库操作也有了一定的了解。那么接下来,我们看下是如何切换默认数据源的,如切换成 MySQL。
JPA 如何整合 MySQL 数据库?
关于 JPA 与 MySQL 的集成我们分为两部分来展开:如何切换 MySQL 数据源、如何写测试用例进行测试。
1. 切换 MySQL 数据源
上面的例子,我们采用的是默认 H2 数据源的方式,这个时候你肯定会问:“H2 重启,数据丢失了怎么办?”那么我们调整一下上面的代码,以 MySQL 作为数据源,看看需要改动哪些。
第一处改动,application.properties 内容如下:
复制代码
spring.datasource.url=jdbc:mysql://localhost:3306/test
spring.datasource.username=root
spring.datasource.password=root
spring.jpa.generate-ddl=true
第二处改动,删除 H2 数据源,新增 MySQL 数据库驱动:
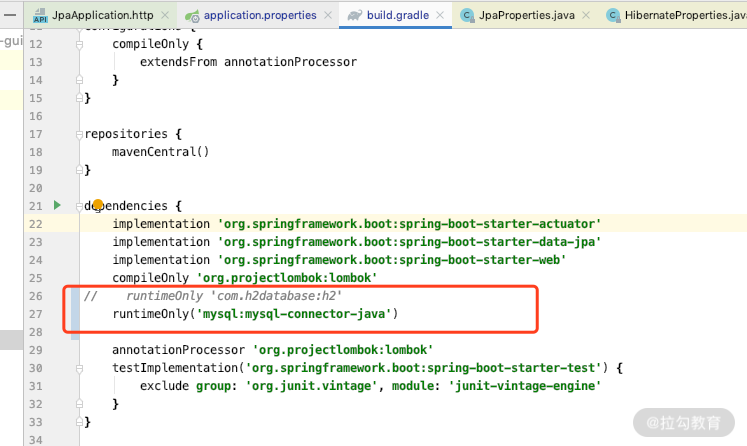
调整完毕之后,我们重启这个项目,以同样的方式测试上面的两个接口依然 OK。
其实这个时候可以发现一件事情,那就是我没有手动去创建任何表,而 JPA 自动帮我创建了数据库的 DDL,并新增了 User 表,所以当我们用 JPA 之后创建表的工作就不会那么复杂了,我们只需要把实体写好就可以了。
以上是切换 MySQL 数据源需要进行的操作,接下来看看测试用例怎么写,在修改代码的时候我们就不需要频繁重启项目了,当你掌握 JUnit 之后,可以提升开发效率。
2. Spring Data JPA 测试用例的写法
我们这里只关注 Repository 的测试用例的写法,Controller 和 Service 等更复杂的测试我们在测试课时再详细介绍,这里我们先快速体验一下。
第一步,在 Test 目录里增加 UserRepositoryTest 类:
复制代码
package com.example.jpa.example1;
import org.junit.Assert;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import java.util.List;
@DataJpaTest
public class UserRepositoryTest {
@Autowired
private UserRepository userRepository;
@Test
public void testSaveUser() {
User user = userRepository.save(User.builder().name("jackxx").email("123456@126.com").build());
Assert.assertNotNull(user);
List<User> users= userRepository.findAll();
System.out.println(users);
Assert.assertNotNull(users);
}
}
第二步,我们可直接运行测试用例,进行真实的 DB 操作,通过控制台来看下我们的测试用例是否能够跑通,如下图所示:

通过上图可以看到,测试的时候执行的 SQL 有哪些,那么我们到底是连接的 MySQL 做的测试用例,还是连接的 H2 做的测试呢?在后面的第 30 课时(单元测试和集成测试)的时候我会为你详细揭晓,到时你会发现测试用例写起来也是如此简单。
整体认识 JPA
通过上面的两个例子我们已经快速入门了,知道了 Spring Boot 结合 Spring Data JPA 怎么配置和启动一个项目 ,之后当你熟悉了 JPA 之后,你还会发现 Spring Boot JPA 要比我们配置 MyBatis 简单很多。下面我们来整体认识一下 Java Persistence API 究竟是什么。
介绍 JPA 协议之前,我们先来对比了解下市面上的 ORM 框架有哪些,分别有哪些优缺点,做到心里有数。
1. 市场上 ORM 框架比对
下表是市场上比较流行的 ORM 框架,这里我罗列了 MyBatis、Hibernate、Spring Data JPA 等,并对比了下它们的优缺点。
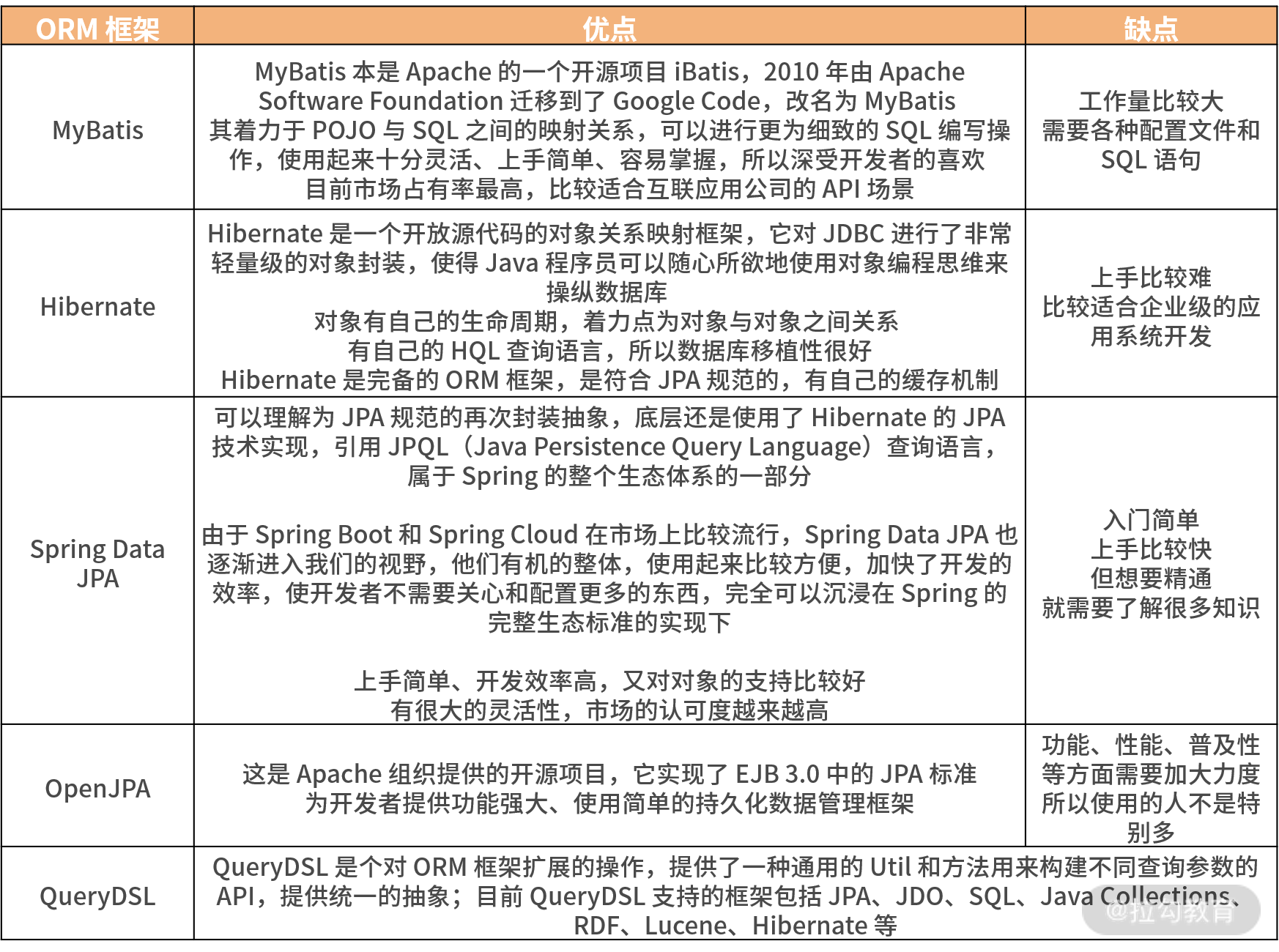
经过对比,你可以看到我们正在学习的 Spring Data JPA 还是比较前卫的,很受欢迎,继承了 Hibernate 的很多优点,上手又比较简单。所以,我非常建议你好好学习一下。
2. Java Persistence API 介绍和开源实现
JPA 是 JDK 5.0 新增的协议,通过相关持久层注解(@Entity 里面的各种注解)来描述对象和关系型数据里面的表映射关系,并将 Java 项目运行期的实体对象,通过一种Session持久化到数据库中。
想象一下,一旦协议有了,大家都遵守了此种协议进行开发,那么周边开源产品就会大量出现,比如我们在后面要介绍的第 29 课时(Spring Data Rest 是什么?和 JPA 是什么关系?)就可以基于这套标准,进而对 Entity 的操作再进行封装,从而可以得到更加全面的 Rest 协议的 API接口。
再比如 JSON API(https://jsonapi.org/)协议,就是雅虎的大牛基于 JPA 的协议的基础,封装制定的一套 RESTful 风格、JSON 格式的 API 协议,那么一旦 JSON API 协议成了标准,就会有很多周边开源产品出现。比如很多 JSON API 的客户端、现在比较流行的 Ember 前端框架,就是基于 Entity 这套 JPA 服务端的协议,在前端解析 API 协议,从而可以对普通 JSON 和 JSON API 的操作进行再封装。
所以规范是一件很有意思的事情,突然之间世界大变样,很多东西都一样了,我们的思路就需要转换了。
JPA 的内容分类
- 一套 API 标准定义了一套接口,在 javax.persistence 的包下面,用来操作实体对象,执行 CRUD 操作,而实现的框架(Hibernate)替代我们完成所有的事情,让开发者从烦琐的 JDBC 和 SQL 代码中解脱出来,更加聚焦自己的业务代码,并且使架构师架构出来的代码更加可控。
- 定义了一套基于对象的 SQL:Java Persistence Query Language(JPQL),像 Hibernate 一样,我们通过写面向对象(JPQL)而非面向数据库的查询语言(SQL)查询数据,避免了程序与数据库 SQL 语句耦合严重,比较适合跨数据源的场景(一会儿 MySQL,一会儿 Oracle 等)。
- ORM(Object/Relational Metadata)对象注解映射关系,JPA 直接通过注解的方式来表示 Java 的实体对象及元数据对象和数据表之间的映射关系,框架将实体对象与 Session 进行关联,通过操作 Session 中不通实体的状态,从而实现数据库的操作,并实现持久化到数据库表中的操作,与 DB 实现同步。
详细的协议内容你感兴趣的话也可以看一下官方的文档。
JPA 的开源实现
JPA 的宗旨是为 POJO 提供持久化标准规范,可以集成在 Spring 的全家桶使用,也可以直接写独立 application 使用,任何用到 DB 操作的场景,都可以使用,极大地方便开发和测试,所以 JPA 的理念已经深入人心了。Spring Data JPA、Hibernate 3.2+、TopLink 10.1.3 以及 OpenJPA、QueryDSL 都是实现 JPA 协议的框架,他们之间的关系结构如下图所示:
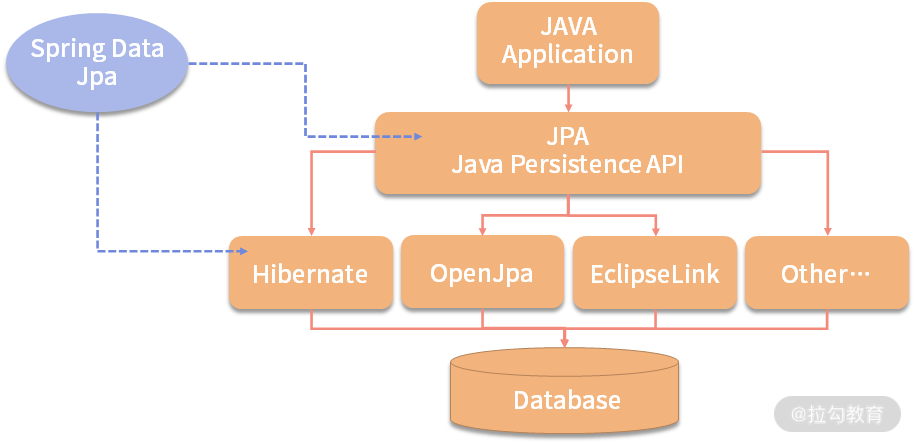
俗话说得好:“未来已经来临,只是尚未流行”,大神资深开发用 Spring Data JPA,编程极客者用 JPA;而普通 Java 开发者,不想去挑战的 Java“搬砖者”用 Mybatis。
到这里,相信你已经对 JPA 有了一定的认识,接下来我们了解一下 Spring Data,看看它都有哪些子项目。
Spring Data 认识
1. Spring Data 介绍
Spring Data 项目是从 2010 年开发发展起来的,Spring Data 利用一个大家熟悉的、一致的、基于“注解”的数据访问编程模型,做一些公共操作的封装,它可以轻松地让开发者使用数据库访问技术,包括关系数据库、非关系数据库(NoSQL)。同时又有不同的数据框架的实现,保留了每个底层数据存储结构的特殊特性。
Spring Data Common 是 Spring Data 所有模块的公共部分,该项目提供了基于 Spring 的共享基础设施,它提供了基于 repository 接口以 DB 操作的一些封装,以及一个坚持在 Java 实体类上标注元数据的模型。
Spring Data 不仅对传统的数据库访问技术如 JDBC、Hibernate、JDO、TopLick、JPA、MyBatis 做了很好的支持和扩展、抽象、提供方便的操作方法,还对 MongoDb、KeyValue、Redis、LDAP、Cassandra 等非关系数据的 NoSQL 做了不同的实现版本,方便我们开发者触类旁通。
其实这种接口型的编程模式可以让我们很好地学习 Java 的封装思想,实现对操作的进一步抽象,我们也可以把这种思想运用在自己公司写的 Framework 上面。
下面来看一下 Spring Data 的子项目都有哪些。
2. Spring Data 的子项目有哪些
下图为目前 Spring Data 的框架分类结构图,里面都有哪些模块可以一目了然,也可以知道哪些是我们需要关心的项目。
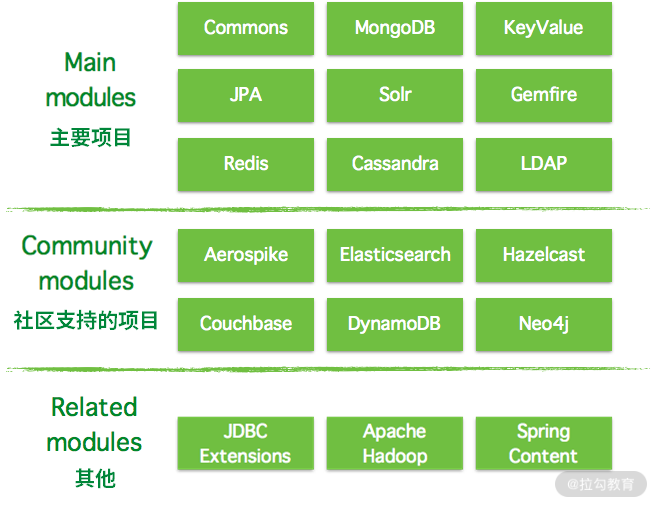
主要项目(Main Modules):
- Spring Data Commons,相当于定义了一套抽象的接口,下一课时我们会具体介绍
- Spring Data Gemfire
- Spring Data JPA,我们关注的重点,对 Spring Data Common 的接口的 JPA 协议的实现
- Spring Data KeyValue
- Spring Data LDAP
- Spring Data MongoDB
- Spring Data REST
- Spring Data Redis
- Spring Data for Apache Cassandra
- Spring Data for Apache Solr
社区支持的项目(Community Modules):
- Spring Data Aerospike
- Spring Data Couchbase
- Spring Data DynamoDB
- Spring Data Elasticsearch
- Spring Data Hazelcast
- Spring Data Jest
- Spring Data Neo4j
- Spring Data Vault
其他(Related Modules):
- Spring Data JDBC Extensions
- Spring for Apache Hadoop
- Spring Content
关于 Spring Data 的子项目,除了上面这些,还有很多开源社区版本,比如 Spring Data、MyBatis 等,这里就不一一介绍了,感兴趣的同学可以到 Spring 社区,或者 GitHub 上进行查阅。
总结
本课时的主要目的是带领你快速入门,从 H2 数据源和 Mysql 数据源两个方面为你介绍了 Spring Data JPA 数据操作的概念,了解了 Repository 的写法,快速体验一把 Spring Data JPA 的便捷之处。
希望你通过本节课的学习可以对 Spring Data JPA + Spring Boot 有一个整体的认识,为以后的技术进阶打下良好的基础。在掌握了基本知识以后,你会发现 Spring Data JPA 是 ORM 的效率利器,后面课程我会一一揭开 Spring Data JPA 的神秘面纱,带你掌握其实现原理和实战经验,让你在实际开发中游刃有余。
对于本课时所讲的知识点,欢迎你在下方留言区表达自己的学习感悟,大家一起讨论,共同进步。
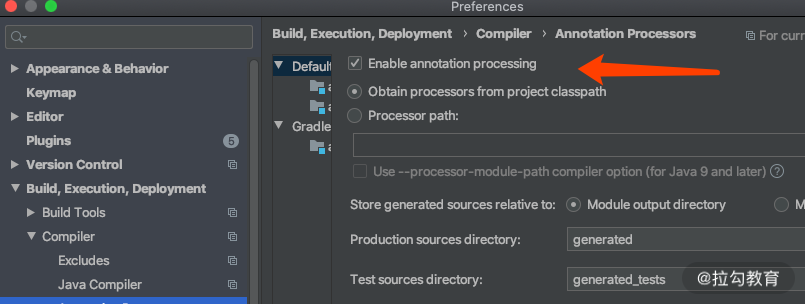
补充一个TIPS:课程中的案例是依赖 lombok 插件的,如下图所示:
并开启 annotation processing。