1 死锁形成的条件
死锁,是指多个线程或者进程在运行过程中因争夺有限的系统资源而造成的一种僵局,当进程或者线程处于这种僵持状态,若无外力作用,它们将无法再向前推进。如下图所示,线程 A 想获取线
程 B 的锁,线程
B
想获取线程
C
的锁,线程
C
想获取线程
D
的锁,线程
D
想获取线程 A 的。
锁,从而构建了一个资源获取环。
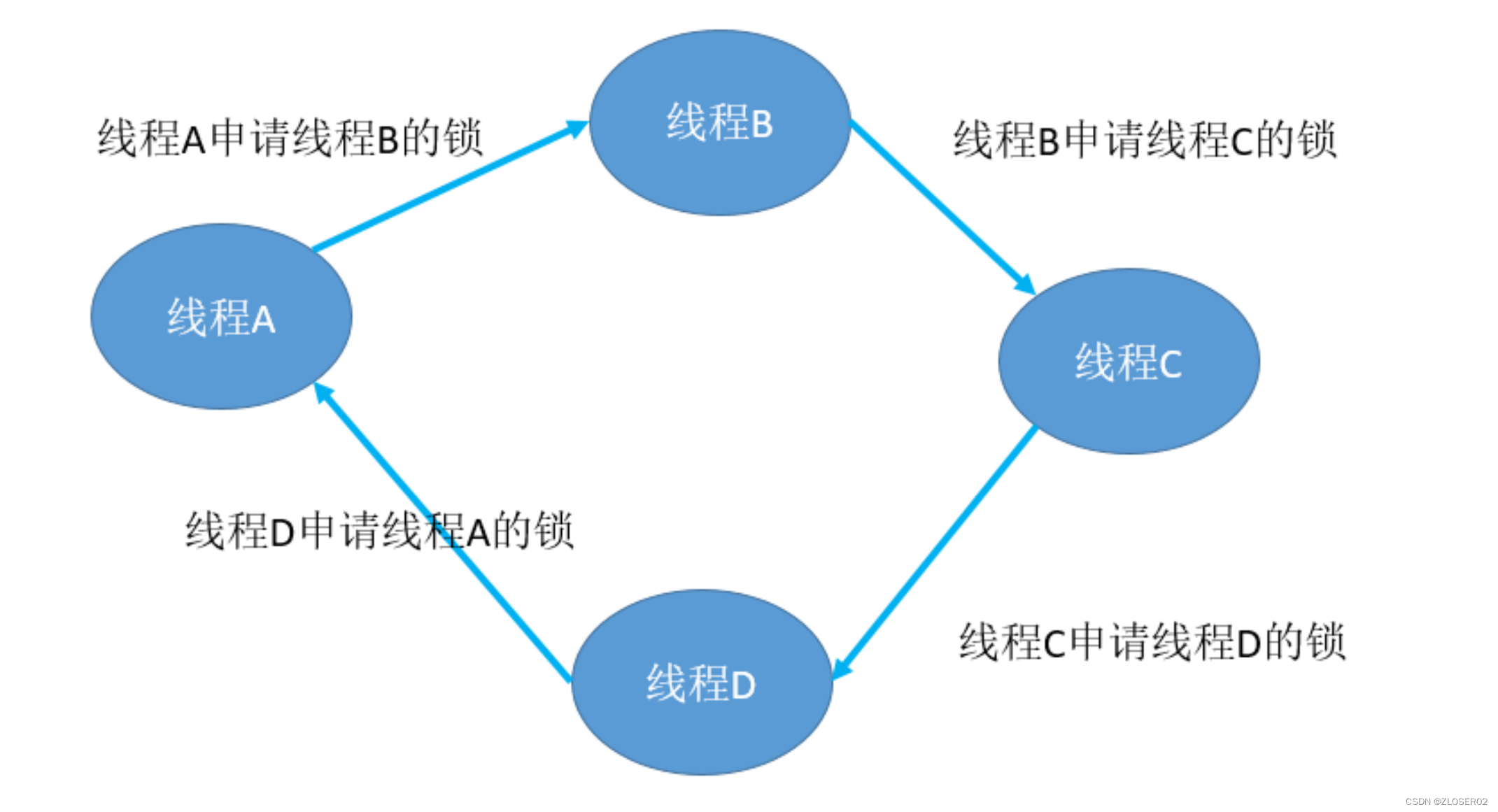
死锁的存在是因为有资源获取环的存在,所以只要能检测出资源获取环,就等同于检测出
死锁的存在。
2.死锁检测原理
死锁检测是计算机系统中的关键组件,用于检测和解决死锁问题,确保系统的正常运行。死锁检测组件的实现原理通常包括以下几个关键步骤:
1. 资源分配图构建:死锁检测通常基于资源分配图来进行。资源分配图是一个有向图,其中节点表示进程和资源,边表示资源的分配关系和请求关系。每个进程和资源都有对应的节点,并且有向边表示进程请求资源和释放资源的行为。
2. 图转化:将资源分配图转化为一种更容易分析的数据结构,通常是一个等待图(Wait-For Graph)或资源分配矩阵。等待图是资源分配图的简化版本,其中只包括等待关系。资源分配矩阵是一个矩阵,其中行代表进程,列代表资源,元素表示资源的分配情况。
3. 检测循环:通过分析等待图或资源分配矩阵,检测是否存在环路。如果存在环路,说明可能存在死锁。这是因为环路表示一组进程之间的资源请求和释放关系,它们彼此之间形成了一个循环,使得每个进程都无法继续执行。
4. 死锁恢复:如果检测到死锁,死锁检测组件可以采取不同的措施来解决死锁。这些措施包括终止某些进程以释放资源、回滚进程的状态、或者等待资源释放。
5. 周期性检测:死锁检测组件通常会定期运行,以便随时检测潜在的死锁情况。这样可以在早期阶段识别和处理死锁,以减小对系统的影响。
需要注意的是,死锁检测虽然可以检测和解决死锁问题,但它不是最高效的方法,因为它需要定期运行,并且可能会引入一些系统开销。更好的方法是通过设计良好的算法和策略来预防死锁的发生。死锁预防的方法包括资源分配策略、资源请求顺序的规定以及进程调度策略等。这些方法有助于降低死锁的概率,从根本上减少死锁问题的发生。
3.死锁检测组件的实现
#define _GNU_SOURCE
#include <dlfcn.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
#if 1
#include <stdint.h>
typedef unsigned long int uint64;
#define MAX 100
enum Type {PROCESS, RESOURCE};
struct source_type {
uint64 id;
enum Type type;
uint64 lock_id;
int degress;
};
struct vertex {
struct source_type s;
struct vertex *next;
};
struct task_graph {
struct vertex list[MAX];
int num;
struct source_type locklist[MAX];
int lockidx;
pthread_mutex_t mutex;
};
struct task_graph *tg = NULL;
int path[MAX+1];
int visited[MAX];
int k = 0;
int deadlock = 0;
struct vertex *create_vertex(struct source_type type) {
struct vertex *tex = (struct vertex *)malloc(sizeof(struct vertex ));
tex->s = type;
tex->next = NULL;
return tex;
}
int search_vertex(struct source_type type) {
int i = 0;
for (i = 0;i < tg->num;i ++) {
if (tg->list[i].s.type == type.type && tg->list[i].s.id == type.id) {
return i;
}
}
return -1;
}
void add_vertex(struct source_type type) {
if (search_vertex(type) == -1) {
tg->list[tg->num].s = type;
tg->list[tg->num].next = NULL;
tg->num ++;
}
}
int add_edge(struct source_type from, struct source_type to) {
add_vertex(from);
add_vertex(to);
struct vertex *v = &(tg->list[search_vertex(from)]);
while (v->next != NULL) {
v = v->next;
}
v->next = create_vertex(to);
}
int verify_edge(struct source_type i, struct source_type j) {
if (tg->num == 0) return 0;
int idx = search_vertex(i);
if (idx == -1) {
return 0;
}
struct vertex *v = &(tg->list[idx]);
while (v != NULL) {
if (v->s.id == j.id) return 1;
v = v->next;
}
return 0;
}
int remove_edge(struct source_type from, struct source_type to) {
int idxi = search_vertex(from);
int idxj = search_vertex(to);
if (idxi != -1 && idxj != -1) {
struct vertex *v = &tg->list[idxi];
struct vertex *remove;
while (v->next != NULL) {
if (v->next->s.id == to.id) {
remove = v->next;
v->next = v->next->next;
free(remove);
break;
}
v = v->next;
}
}
}
void print_deadlock(void) {
int i = 0;
printf("cycle : ");
for (i = 0;i < k-1;i ++) {
printf("%ld --> ", tg->list[path[i]].s.id);
}
printf("%ld\n", tg->list[path[i]].s.id);
}
int DFS(int idx) {
struct vertex *ver = &tg->list[idx];
if (visited[idx] == 1) {
path[k++] = idx;
print_deadlock();
deadlock = 1;
return 0;
}
visited[idx] = 1;
path[k++] = idx;
while (ver->next != NULL) {
DFS(search_vertex(ver->next->s));
k --;
ver = ver->next;
}
return 1;
}
int search_for_cycle(int idx) {
struct vertex *ver = &tg->list[idx];
visited[idx] = 1;
k = 0;
path[k++] = idx;
while (ver->next != NULL) {
int i = 0;
for (i = 0;i < tg->num;i ++) {
if (i == idx) continue;
visited[i] = 0;
}
for (i = 1;i <= MAX;i ++) {
path[i] = -1;
}
k = 1;
DFS(search_vertex(ver->next->s));
ver = ver->next;
}
}
#endif
int search_lock(uint64 lock) {
int i = 0;
for (i = 0;i < tg->lockidx;i ++) {
if (tg->locklist[i].lock_id == lock) {
return i;
}
}
return -1;
}
int search_empty_lock(uint64 lock) {
int i = 0;
for (i = 0;i < tg->lockidx;i ++) {
if (tg->locklist[i].lock_id == 0) {
return i;
}
}
return tg->lockidx;
}
void lock_before(uint64_t tid, uint64_t lockaddr) {
int idx = 0;
for(;idx < tg->lockidx; idx++) {
if(tg->locklist[idx].lock_id == lockaddr) {
struct source_type from;
from.id = tid;
from.type = PROCESS;
add_vertex(from);
struct source_type to;
to.id = tg->locklist[idx].id;
to.type = PROCESS;
add_vertex(to);
tg->locklist[idx].degress++;
if(!verify_edge(from, to))
add_edge(from, to);
}
}
}
void lock_after(uint64_t tid, uint64_t lockaddr) {
int idx = 0;
if(-1 == (idx = search_lock(lockaddr))) {
int edix = search_empty_lock(lockaddr);
tg->locklist[edix].id = tid;
tg->locklist[edix].lock_id = lockaddr;
tg->lockidx ++;
} else{
struct source_type from;
from.id = tid;
from.type = PROCESS;
add_vertex(from);
struct source_type to;
to.id = tg->locklist[idx].id;
to.type = PROCESS;
add_vertex(to);
tg->locklist[idx].degress --;
if(verify_edge(from, to));
remove_edge(from, to);
tg->locklist[idx].id = tid;
}
}
void unlock_after(uint64_t tid, uint64_t lockaddr) {
int idx = search_lock(lockaddr);
if(tg->locklist[idx].degress == 0) {
tg->locklist[idx].id = 0;
tg->locklist[idx].lock_id = 0;
}
}
void check_dead_lock(void) {
int i = 0;
deadlock = 0;
for (i = 0;i < tg->num;i ++) {
if (deadlock == 1) break;
search_for_cycle(i);
}
if (deadlock == 0) {
printf("no deadlock\n");
}
}
static void *thread_routine(void *args) {
while (1) {
sleep(5);
check_dead_lock();
}
}
void start_check(void) {
tg = (struct task_graph*)malloc(sizeof(struct task_graph));
tg->num = 0;
tg->lockidx = 0;
pthread_t tid;
pthread_create(&tid, NULL, thread_routine, NULL);
}
typedef int (*pthread_mutex_lock_t)(pthread_mutex_t *mutex);
pthread_mutex_lock_t pthread_mutex_lock_f = NULL;
typedef int (*pthread_mutex_unlock_t)(pthread_mutex_t *mutex);
pthread_mutex_unlock_t pthread_mutex_unlock_f = NULL;
int pthread_mutex_lock(pthread_mutex_t *mutex) {
pthread_t selfid = pthread_self();
lock_before((uint64_t)selfid,(uint64_t)mutex);
pthread_mutex_lock_f(mutex);
lock_after((uint64_t)selfid,(uint64_t)mutex);
//printf("[%s:%s;%d] pthread_mutex_lock selfid: %ld, %p\n", \
__FILE__,__func__,__LINE__,selfid,mutex);
}
int pthread_mutex_unlock(pthread_mutex_t *mutex) {
pthread_t selfid = pthread_self();
pthread_mutex_unlock_f(mutex);
unlock_after((uint64_t)selfid,(uint64_t)mutex);
//printf("[%s:%s;%d] pthread_mutex_lock selfid: %ld, %p\n",\
__FILE__,__func__,__LINE__,selfid,mutex);
}
void init_hook(void) {
if(!pthread_mutex_lock_f) {
pthread_mutex_lock_f = dlsym(RTLD_NEXT, "pthread_mutex_lock");
}
if(!pthread_mutex_unlock_f) {
pthread_mutex_unlock_f = dlsym(RTLD_NEXT, "pthread_mutex_unlock");
}
}
/*
只需在需要检测死锁的程序中添加该文件,并且在程序的main函数中添加下面两句代码编译执行即可
init_hook();
start_check();
*/
#if 0
pthread_mutex_t r1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t r2 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t r3 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t r4 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t r5 = PTHREAD_MUTEX_INITIALIZER;
void *t1_cb(void *arg) {
pthread_mutex_lock(&r1);
sleep(1);
pthread_mutex_lock(&r2);
pthread_mutex_unlock(&r2);
pthread_mutex_unlock(&r1);
}
void *t2_cb(void *arg) {
pthread_mutex_lock(&r2);
sleep(1);
pthread_mutex_lock(&r3);
pthread_mutex_unlock(&r3);
pthread_mutex_unlock(&r2);
}
void *t3_cb(void *arg) {
pthread_mutex_lock(&r3);
sleep(1);
pthread_mutex_lock(&r4);
pthread_mutex_unlock(&r4);
pthread_mutex_unlock(&r3);
}
void *t4_cb(void *arg) {
pthread_mutex_lock(&r4);
sleep(1);
#if 1
pthread_mutex_lock(&r2);
pthread_mutex_unlock(&r2);
#endif
pthread_mutex_unlock(&r4);
}
void *t5_cb(void *arg) {
pthread_mutex_lock(&r5);
sleep(1);
#if 0
pthread_mutex_lock(&r1);
pthread_mutex_unlock(&r1);
#endif
pthread_mutex_unlock(&r5);
}
int main(void) {
init_hook();
start_check();
pthread_t t1,t2,t3,t4,t5;
pthread_create(&t1, NULL,t1_cb, NULL);
pthread_create(&t2, NULL,t2_cb, NULL);
pthread_create(&t3, NULL,t3_cb, NULL);
pthread_create(&t4, NULL,t4_cb, NULL);
pthread_create(&t5, NULL,t5_cb, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
pthread_join(t5, NULL);
printf("complete\n");
return 0;
}
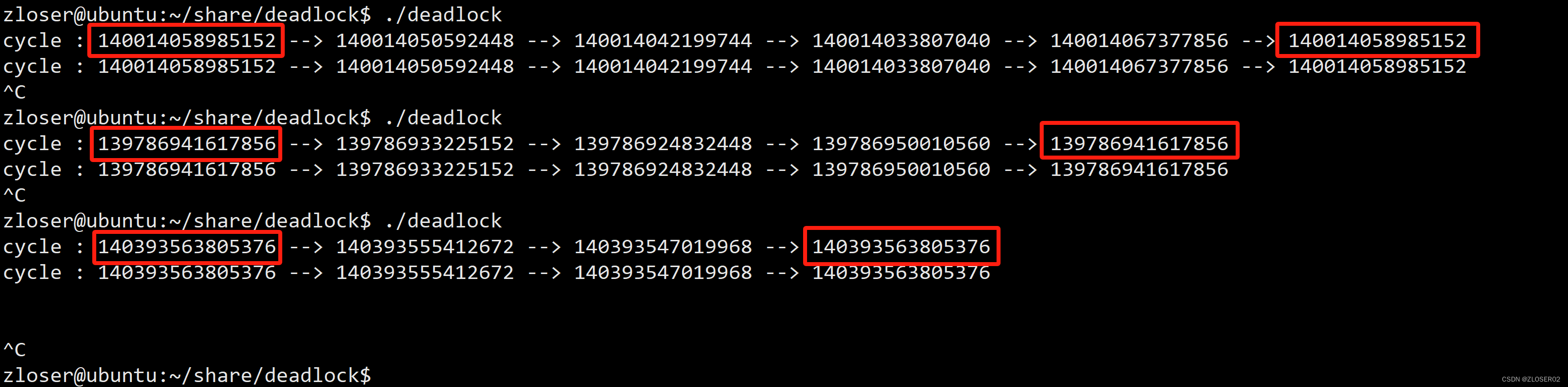
#endif通过模拟不同的死锁场景得到的结果:



![[0xGameCTF 2023] web题解](https://img-blog.csdnimg.cn/d45723854d5c4768b126a3ed73e6a925.png)