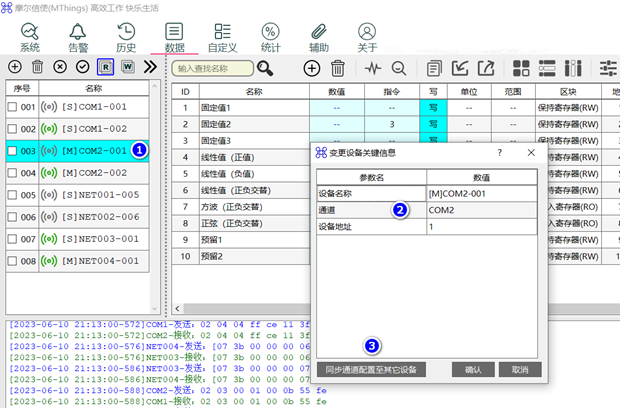
EasyRaft 介绍
EasyRaft是Raft(共识算法)的Java实现,主要目的在于提供一种高性能的分布式一致性协议。
覆盖Jraft实现的功能
分布式一致性
分布式一致性 (distributed consensus) 是分布式系统中最基本的问题,用来保证一个分布式系统的可靠性以及容灾能力。简单的来讲,就是如何在多个机器间对某一个值达成一致, 并且当达成一致之后,无论之后这些机器间发生怎样的故障,这个值能保持不变。 抽象定义上, 一个分布式系统里的所有进程要确定一个值 v,如果这个系统满足如下几个性质, 就可以认为它解决了分布式一致性问题, 分别是:
- Termination: 所有正常的进程都会决定 v 具体的值,不会出现一直在循环的进程。
- Validity: 任何正常的进程确定的值 v’, 那么 v’ 肯定是某个进程提交的。比如随机数生成器就不满足这个性质。
- Agreement: 所有正常的进程选择的值都是一样的。
RAFT
RAFT 是一种新型易于理解的分布式一致性复制协议,由斯坦福大学的 Diego Ongaro 和 John Ousterhout 提出,作为 RAMCloud 项目中的中心协调组件。Raft 是一种 Leader-Based 的 Multi-Paxos 变种,相比 Paxos、Zab、View Stamped Replication 等协议提供了更完整更清晰的协议描述,并提供了清晰的节点增删描述。 Raft 作为复制状态机,是分布式系统中最核心最基础的组件,提供命令在多个节点之间有序复制和执行,当多个节点初始状态一致的时候,保证节点之间状态一致。系统只要多数节点存活就可以正常处理,它允许消息的延迟、丢弃和乱序,但是不允许消息的篡改(非拜占庭场景)。
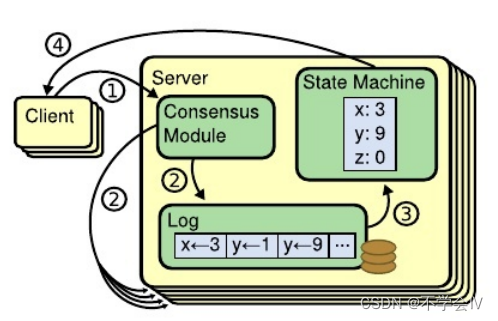
Raft 可以解决分布式理论中的 CP,即一致性和分区容忍性,并不能解决 Available 的问题。其中包含分布式系统中一些通常的功能:
- Leader Election
- Log Replication
- Membership Change
- Log Compaction
RAFT 可以做什么
通过 RAFT 提供的一致性状态机,可以解决复制、修复、节点管理等问题,极大的简化当前分布式系统的设计与实现,让开发者只关注于业务逻辑,将其抽象实现成对应的状态机即可。基于这套框架,可以构建很多分布式应用:
- 分布式锁服务,比如 Zookeeper
- 分布式存储系统,比如分布式消息队列、分布式块系统、分布式文件系统、分布式表格系统等
- 高可靠元信息管理,比如各类 Master 模块的 HA
同时RAFT贴近业务的抽象设计,方便适配业务;
EASY RAFT
一个纯 Java 的 Raft 算法实现库, 基于百度 braft 实现而来, 使用 Java 重写了所有功能, 支持:
Leader election and priority-based semi-deterministic leader election.
Replication and recovery.
Snapshot and log compaction.
Read-only member (learner).
Membership management.
Fully concurrent replication.
Fault tolerance.
Asymmetric network partition tolerance.
Workaround when quorate peers are dead.
Replication pipeline optimistic
Linearizable read, ReadIndex/LeaseRead.
个性实现
在EasyRAFT中的自主特殊实现,而没使用通用组件库:
- 场景特化的LSM数据库
- 基于原生NIO实现的高并发网络架构
- 角色抽象设计
主要参考
- 《In Search of an Understandable Consensus Algorithm》
- 《数据密集型应用系统设计》
- 《深入理解Kafka-核心设计与实践原理》
- 《Kafka源码解析与实践》
- Kafka源码
- Nacos源码
- Netty源码
- Jraft源码
核心设计
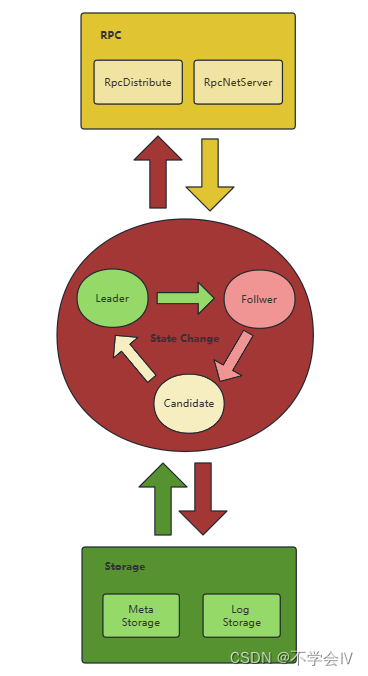
Role State
单一节点会在三种角色中流转状态,采用了状态模式控制行为,如Leader在包含特殊的行为:
- 配置变更
- 同步条目
- 提交日志
- 副本日志维护
存储
包括Meta存储与Log存储,自主研发的实现:
- Log 存储,记录 raft 配置变更和用户提交任务的日志,将从 Leader 复制到其他节点上。LogStorage 是定义接口(可实现其它的储存库),包括缓存、读写日志、截断等。
- Meta 存储,元信息存储,记录 raft 实现的内部状态,比如已提交的偏移量。
RPC
RPC 模块用于节点之间的网络通讯,基于原生NIO、Selector的RPC网络架构,自主研发实现:
- RPCNetServer: 内置于 Node 内的 RPC 服务器,接收其他节点或者客户端发过来的请求。
- RpcDistribute: 转交给对应请求分发给指定监听的方法。
技术实现
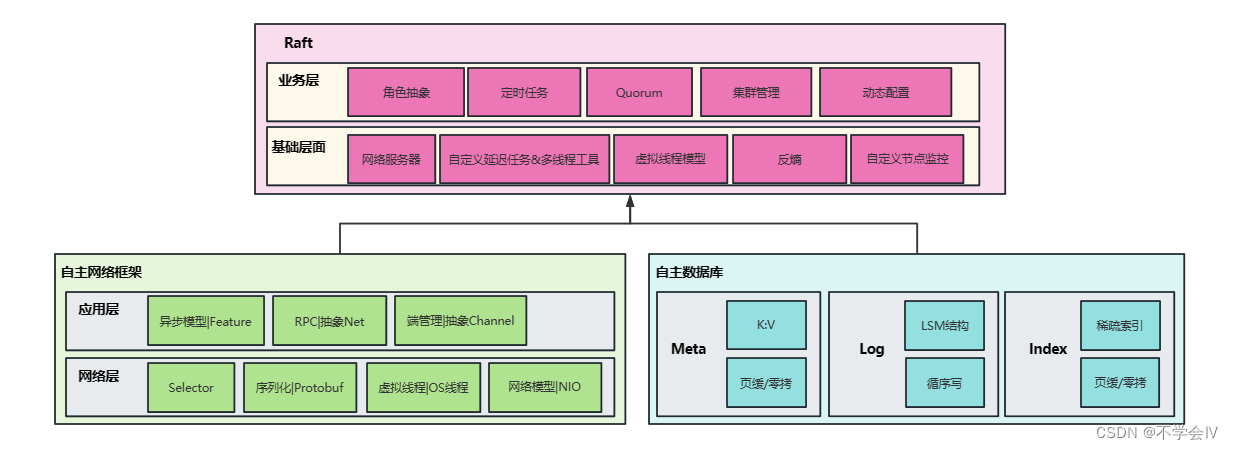
整体模块图
RAFT DB
RAFT DB是专门适配Raft协议的储存库,是LSM类型数据库但没有WAL,同时在日志压缩上做了更匹配RAFT的方案。
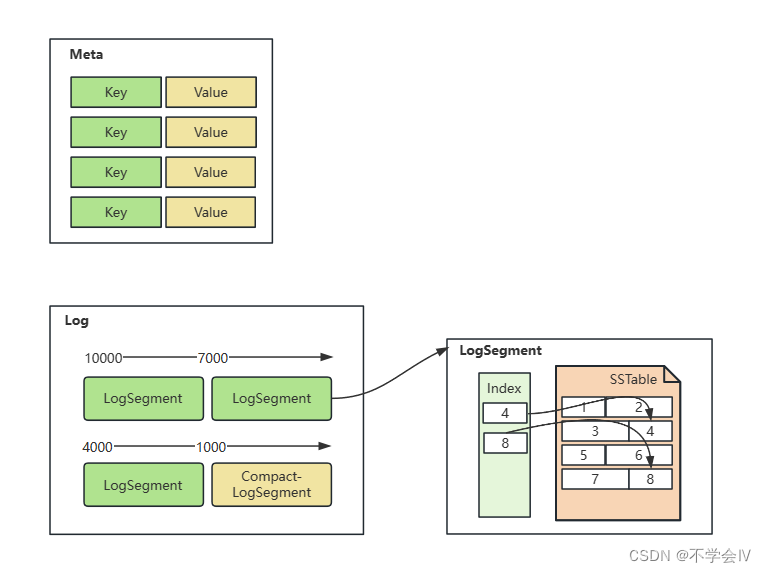
详细实现原理
高性能性能基础原理:
- SSTable:顺序写入。
- Index:MappedByteBuffer(页缓存零拷贝)。
- Meta:MappedByteBuffer(页缓存零拷贝)。
此外在并发控制上:
- 单线程写入。
- 多线程读取。
而在数据结构上:
- SSTable: 非定长数据结构依赖Index定位数据。
- Index:定长的稀疏数据结构,1M即可映射131072条数据。
- Meta:定长的KV结构。
对比性能
Rocks是一个日志式(LSM)K-V数据库,由FaceBook开发旨在提供高速的数据持久化和读写能力,适用于需要快速存储和检索大量数据的应用程序。使用RocksDB的项目包括Flink、TiKV等;
测试一.插入数据
在此基准测试运行开始时,数据库为空,并逐渐填满。数据加载过程中未读取任何数据。
| 数据库类型 | 版本 | 平均吞吐量 | 标准差 | 最小 | 最大 | 波动程度 | 置信率 | 同比差率 |
|---|---|---|---|---|---|---|---|---|
| RaftDB | 1.0 | 390592.650 | 3469.357 ops/s | 384407.308 | 395535.143 | 1865.434 | 99.9% | 100% |
| RocksDB | 8.3 | 298498.660 | 2671.176 ops/s | 293204.765 | 302760.628 | 2498.620 | 99.9% | 76.4% |
测试二.随机读取
测量性能以随机读取现有数据(1000w数据为基础)。
| 数据库类型 | 版本 | 缓存 | 平均吞吐量 | 标准差 | 最小 | 最大 | 波动程度 | 置信率 | 同比差率 |
|---|---|---|---|---|---|---|---|---|---|
| RaftDB | 1.0 | 关闭 | 102574.692 | 1030.314 ops/s | 100099.588 | 103989.586 | 963.757 | 99.9% | 88.1% |
| RocksDB | 8.3 | 关闭 | 116429.139 | 3580.538 ops/s | 108565.503 | 119586.128 | 3349.237 | 99.9% | 100% |
测试三.Raft场景特化案例
此外还有更多的测试用例,不一一展示了
RPC Net
RPC Net是基于JDK NIO实现的RPC架构,设计核心是高并发、可控。
抽象设计
根据Selector模型的事件抽象出,建立连接与读写操作分离的模型。
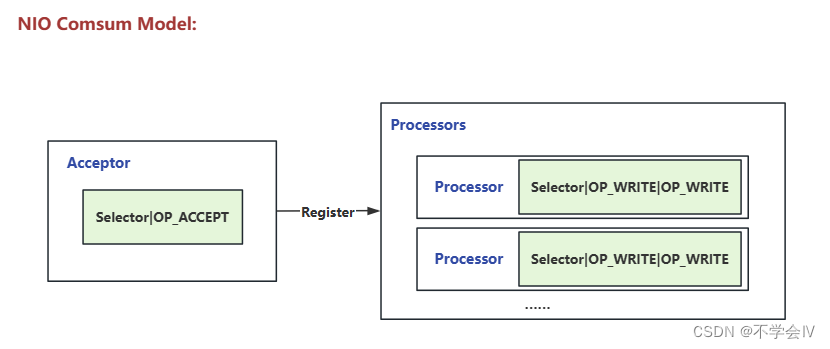
线程与消费模型
整体是一个非阻塞的模型,所以不需要很多的线程(读取后投递队列,不处理业务),合适的线程配置是1:4,即一个线程负责接收连接,4个线程负责接收与写入数据等
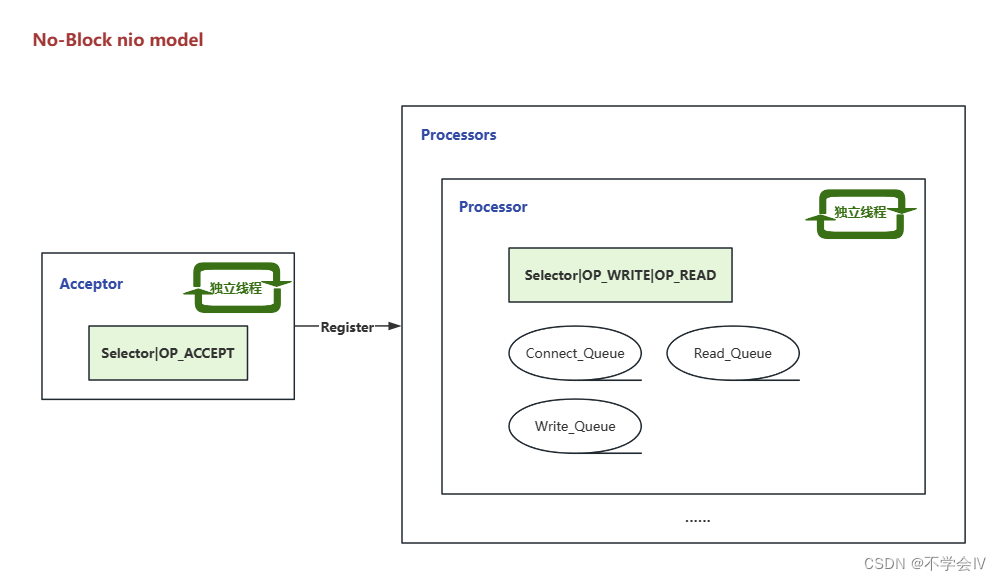
更加详细的网络模型
四个队列实现非阻塞的操作,所以该模型可以用少量的线程完成高并发的运转
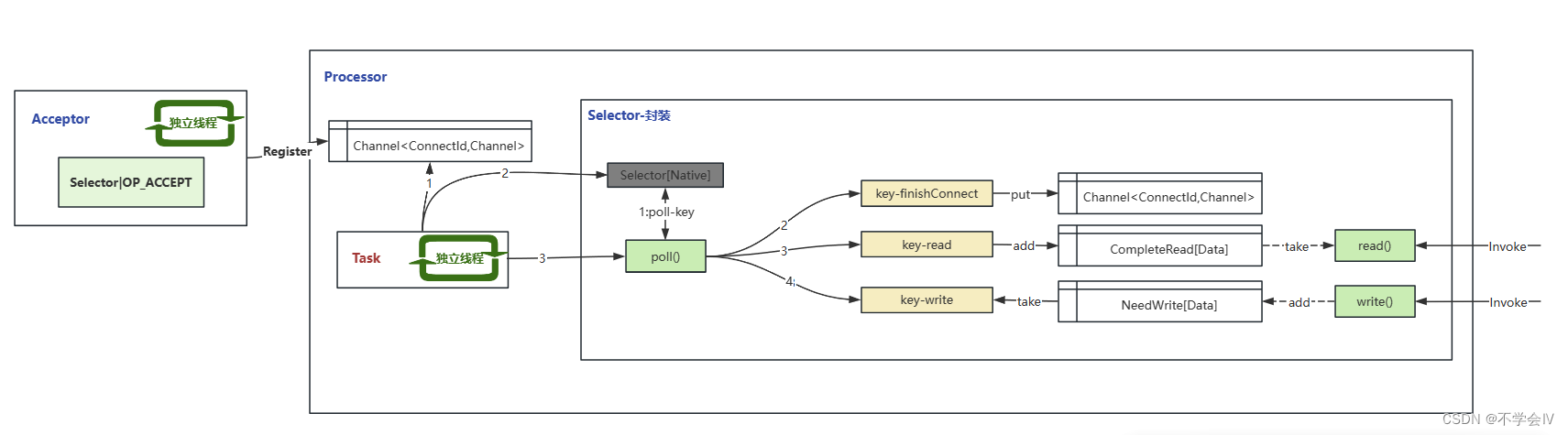
并发测试用例
| 网络框架 | 版本 | 平均吞吐量 | 同比差率 |
|---|---|---|---|
| RPC Net | 1.0 | 349083.983 | 100% |
| Netty | 4.1 | 319393.519 | 91.4% |
并发控制
项目中有大量的并发风险控制、延迟任务,定制适合场景的多线程工具,精化场景,以下是类图:
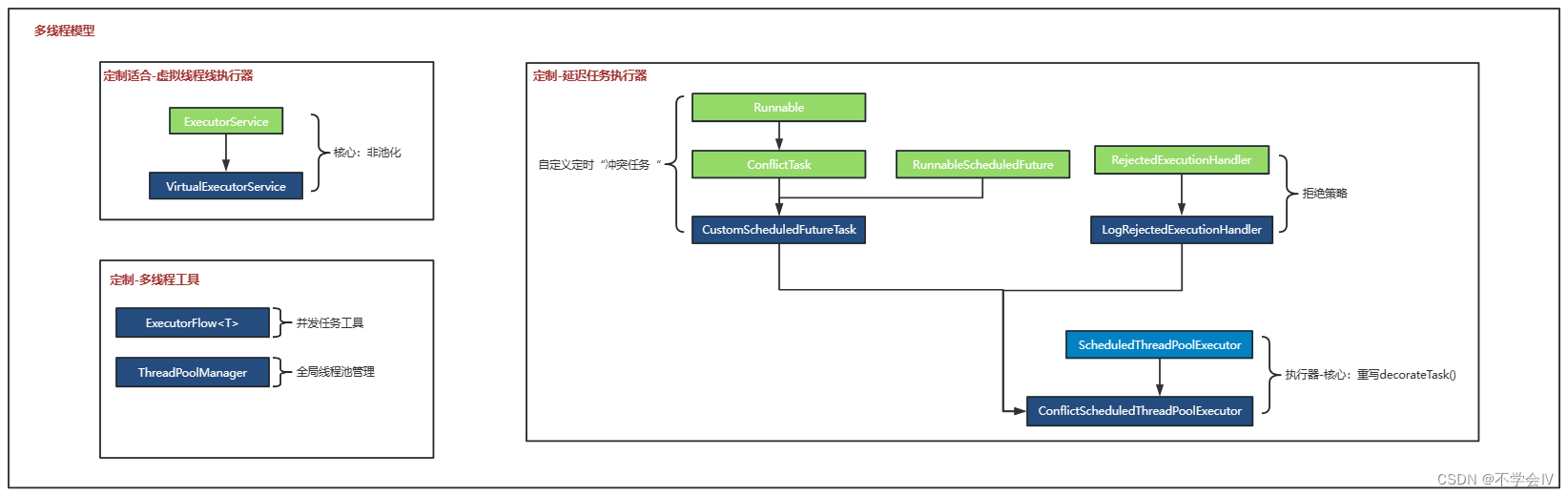
使用指南
基本概念
- log index 提交到 raft group 中的任务都将序列化为一条日志存储下来,每条日志一个编号,在整个 raft group 内单调递增并复制到每个 raft 节点。
- term 在整个 raft group 中单调递增的一个 int 数字,可以简单地认为表示一轮投票的编号,成功选举出来的 leader 对应的 term 称为 leader term,在这个 leader 没有发生变更的阶段内提交的日志都将拥有相同的 term 编号。
配置和辅助类
本节主要介绍 Easy RAFT 的配置和辅助工具相关接口和类。核心包括:
Endpoint 表示一个服务地址。
PeerId 表示一个 raft 参与节点。
Configuration 表示一个 raft group 配置,也就是节点列表。
节点
SERVICE_LOCAL_NODES表示一个服务地址,包括 IP 和端口, 并设置了比重,该比重影响优先选举权,如下例:
Properties properties = new Properties();
properties.put(ConfigConstants.SERVICE_ID, "id");
//本地节点&优先选举比重
properties.put(ConfigConstants.SERVICE_LOCAL_NODES, "1,localhost:9094,[node_weight:500]");
//集群节点
properties.put(ConfigConstants.SERVICE_NODES, "2,localhost:9091;3,localhost:9092;3,localhost:9093;");
ServerConfig serverConfig = new ServerConfig(properties);
配置
其中包括但不限于以下配置:
SERVICE_ROOT_DIR //根目录
SERVICE_QUORUM_RATE //quorum比例
SERVICE_RECORDING_LEVEL//监控等级
SEGMENT_MAX_SIZE//单个Segment大小
SEGMENT_OFFSET_INDEX_MAX_SIZE//Segment稀疏索引大小
SEGMENT_OFFSET_INTERVAL//稀疏索引间隔(默认4k)
LOG_TYPE//日志类型
LOG_CLEAN_OPEN//压缩日志服务
LOG_CLEAN_ALGORITHM//压缩hash算法
......
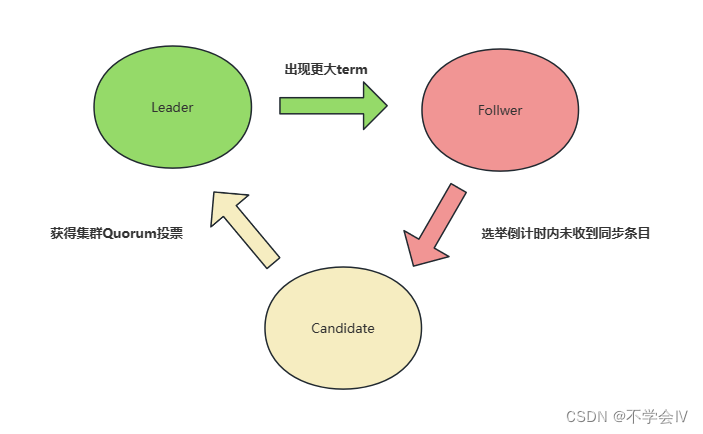
Leader选举
下图中节点在不同角色流转的核心条件,其中Leader的详细条件包括:
- Follower时未收到其他Leader的条目同步
- Candidate发起投票后得到集群节点半数以上的投票
- 未收到Term大于自己的同步条目
- 持有最新日志条目
优化计划
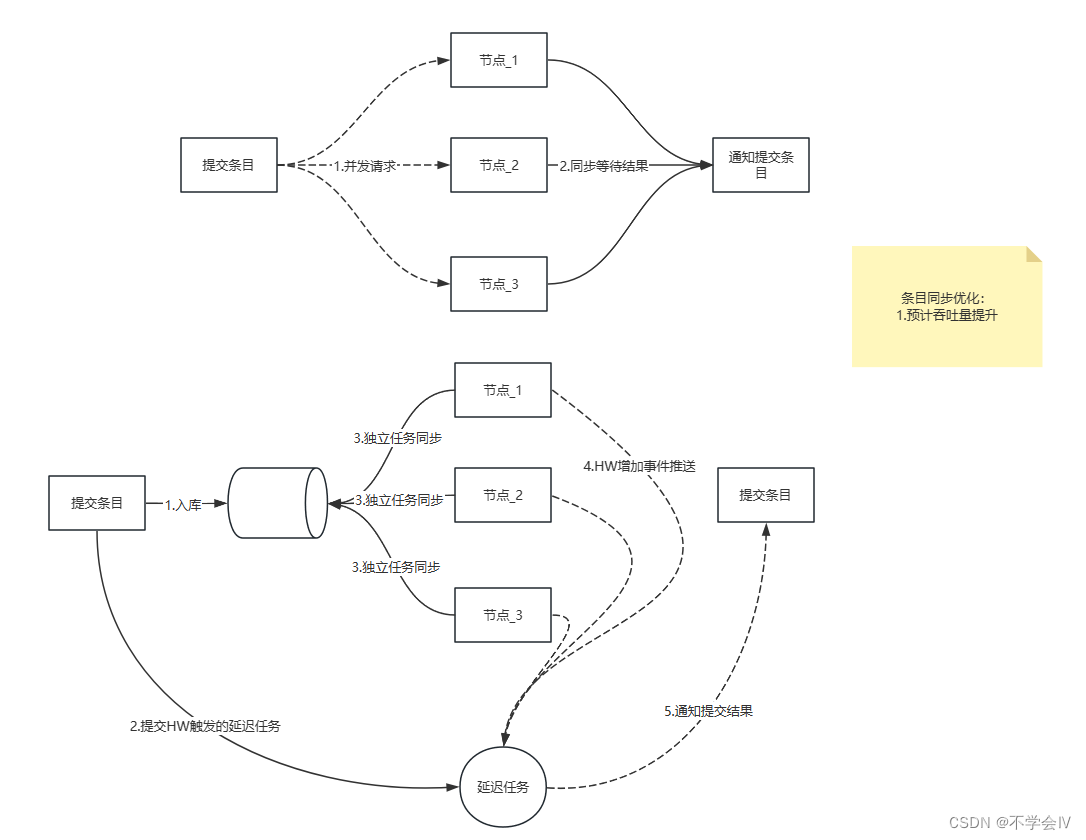
日志提交任务
此优化在独立日志水位后,异步执行同步任务,可预期的结果能够提升并发。
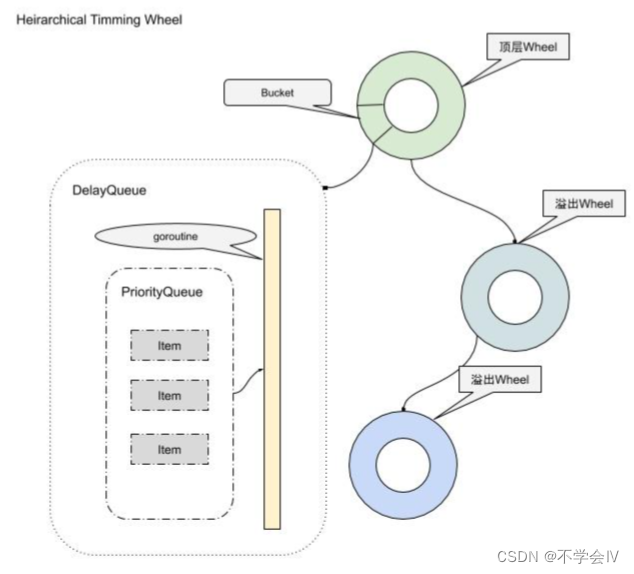
时间轮延迟任务
相比于JDK-ScheduledThreadPoolExecutor的时间复杂度为O(nlogn),采用此方法时间复杂度能够达到O(1)。
源码地址
https://gitee.com/weKie/easy-raft.git