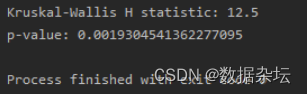
CSP Bottleneck块和C3 类的设计使其非常适合目标检测任务,充分考虑了多尺度特征融合、梯度流动和计算效率等因素。C3 类以及CSP(Cross Stage Partial) Bottleneck块作为YOLOv5中的一部分,具有以下优势,相对于传统的普通神经网络:
-
特定任务定制:
C3类和CSP Bottleneck块是专门为目标检测任务设计的。它们在特征提取和融合方面进行了特定的优化,有助于提高目标检测性能。传统的神经网络结构通常用于通用的图像分类任务,不一定适用于目标检测。 -
多尺度特征融合:CSP Bottleneck块具有特殊的结构,允许多尺度的特征信息进行有效融合。这对于目标检测非常关键,因为目标可能具有不同尺寸和比例,需要在不同尺度下进行检测。
-
快捷连接:CSP Bottleneck块允许引入快捷连接,这对于信息流动和梯度传播至关重要。传统的神经网络通常没有这种结构,而YOLOv5中的C3块通过快捷连接促进了梯度的传递,减轻了梯度消失问题,有助于训练的稳定性。
-
高效性能:尽管CSP Bottleneck块具有更复杂的结构,但它们经过有效的设计,不会引入过多的计算复杂性。这使得YOLOv5能够在相对较短的时间内完成目标检测任务。
一、前期工作
1.1 导入数据集
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
import os,PIL,random,pathlib
data_dir = 'D:/T6star/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
print(classeNames)
1.2 标准化处理
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder("D:/P8/weather_photos/",transform=train_transforms)
print(total_data)

1.3 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset, test_dataset) 
1.4 设置数据加载器
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True, 二、搭建包含CSP Bottleneck块和C3 类的YOLOv5的主干网络
import torch.nn.functional as F
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)# 定义卷积层
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
"""
这个是YOLOv5, 6.0版本的主干网络,这里进行复现
(注:有部分删改,详细讲解将在后续进行展开)
"""
class YOLOv5_backbone(nn.Module):
def __init__(self):
super(YOLOv5_backbone, self).__init__()
self.Conv_1 = Conv(3, 64, 3, 2, 2)
self.Conv_2 = Conv(64, 128, 3, 2)
self.C3_3 = C3(128,128)
self.Conv_4 = Conv(128, 256, 3, 2)
self.C3_5 = C3(256,256)
self.Conv_6 = Conv(256, 512, 3, 2)
self.C3_7 = C3(512,512)
self.Conv_8 = Conv(512, 1024, 3, 2)
self.C3_9 = C3(1024, 1024)
self.SPPF = SPPF(1024, 1024, 5)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=65536, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self, x):
x = self.Conv_1(x)
x = self.Conv_2(x)
x = self.C3_3(x)
x = self.Conv_4(x)
x = self.C3_5(x)
x = self.Conv_6(x)
x = self.C3_7(x)
x = self.Conv_8(x)
x = self.C3_9(x)
x = self.SPPF(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = YOLOv5_backbone().to(device)
print(model)autopad(k, p) 函数:
- 这个函数用于计算卷积操作中的自动填充大小。
- 如果没有提供填充参数
p,则它会根据卷积核大小k的情况自动计算填充大小,以实现“same”填充,即输入和输出特征图具有相同的空间维度。
Conv 类:
- 这个类定义了标准的卷积层,包括卷积、批量归一化和激活函数等。
- 构造函数接受参数
c1(输入通道数)、c2(输出通道数)、k(卷积核大小)、s(步幅)、p(填充)、g(分组卷积)、act(激活函数类型)等。 forward方法执行卷积、批量归一化和激活函数操作,并返回输出。
Bottleneck 类:
- 这个类定义了标准的瓶颈块,用于深层网络中的特征提取。
- 构造函数接受参数
c1(输入通道数)、c2(输出通道数)、shortcut(是否包含快捷连接)、g(分组卷积)、e(扩展系数)、groups 卷积操作中的分组参数,通常为1,表示标准卷积。在深度可分离卷积等操作中,该值可能不为1。 bias 设置为False,表示卷积操作不使用偏置项。 forward方法执行一系列卷积操作,包括卷积核为1x1和3x3的卷积,以及可选的快捷连接操作。
C3 类:
- 这个类定义了CSP(Cross Stage Partial) Bottleneck块,它包含3个卷积操作。
forward方法执行一系列卷积操作,包括卷积核为1x1的卷积、2个不同的卷积核为1x1的卷积和可选的快捷连接操作。
SPPF 类:
SPPF层是指"Spatial Pyramid Pooling - Fast"层,它是YOLOv5中的一种特殊层,用于多尺度特征融合。SPPF层的作用是对输入特征图进行空间金字塔池化,以捕获不同尺度的特征信息,从而提高目标检测性能。
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
nn.MaxPool2d是PyTorch中的最大池化层,用于进行池化操作。kernel_size参数设定了池化核的大小,这里使用了k作为参数,表示池化核的大小为k x k。stride参数设置为1,表示池化操作的滑动步幅为1。padding参数设置为k // 2,表示对输入特征图进行填充以保持输出特征图的尺寸与输入相同。
nn.MaxPool2d层被用于执行空间金字塔池化,其中kernel_size的不同取值对应于不同尺度的池化区域。这有助于在不同尺度上捕获特征信息,从而提高目标检测性能。在这个特定的情况下,k的取值是5,9和13,相应地表示了3个不同尺度的池化操作,从而构成了空间金字塔池化。
- 这个类定义了SPPF(Spatial Pyramid Pooling - Fast)层,用于多尺度特征融合。
forward方法执行空间金字塔池化操作,将不同尺度的特征图拼接在一起。
YOLOv5_backbone 类:
- 定义主干网络的各个层(
Conv_1、Conv_2、C3_3、Conv_4、C3_5、Conv_6、C3_7、Conv_8、C3_9和SPPF)用于逐步提取输入图像的特征。。 classifier是一个全连接网络层,用于分类任务。forward方法定义了整个主干网络的前向传播过程,包括各个层次的卷积和特征融合。
小结:
在上述代码中,forward 函数在不同类中的作用如下:
-
forward函数在Conv类中的作用:Conv类代表标准的卷积层,其forward函数用于执行卷积操作。- 输入
x是卷积层的输入特征图。 - 通过卷积操作、批量归一化(Batch Normalization)、激活函数等一系列操作,将输入特征图
x转化为经过卷积层处理后的输出。
-
forward函数在Bottleneck类中的作用:Bottleneck类代表标准的瓶颈块,其forward函数用于执行瓶颈块的前向传播。- 输入
x是瓶颈块的输入特征图。 - 瓶颈块包括一系列卷积层和残差连接(如果
shortcut为True),将输入特征图x转化为经过瓶颈块处理后的输出。
-
forward函数在C3类中的作用:C3类代表一种特殊的 CSP(Cross-Stage-Partial)瓶颈块,包括三个卷积操作。- 输入
x是C3瓶颈块的输入特征图。 forward函数首先执行两个不同卷积操作self.cv1和self.cv2,然后将它们的输出与输入x进行拼接(Concatenate),并传递给第三个卷积操作self.cv3。- 最后,通过一系列堆叠的
Bottleneck块(self.m中的循环),将输入特征图x通过多次瓶颈块的处理,生成经过C3块处理后的输出。
-
forward函数在SPPF类中的作用:SPPF类代表空间金字塔池化(Spatial Pyramid Pooling - Fast)层。- 输入
x是SPPF层的输入特征图。 forward函数执行空间金字塔池化操作,将输入特征图x通过最大池化操作self.m在不同尺度上池化,然后将池化后的结果进行拼接,生成SPPF层的输出特征。
-
forward函数在YOLOv5_backbone类中的作用:YOLOv5_backbone类代表整个YOLOv5的主干网络,包括多个卷积层和瓶颈块,以及SPPF层。forward函数按照网络的顺序将输入特征图x通过各个组件,包括卷积层、瓶颈块、SPPF层,然后通过全连接网络层self.classifier进行分类。- 返回经过主干网络处理后的特征表示,用于目标检测的进一步处理。
运行结果:
YOLOv5_backbone(
(Conv_1): Conv(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(Conv_2): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_3): C3(
(cv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_4): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_5): C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_6): Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_7): C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_8): Conv(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_9): C3(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(SPPF): SPPF(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=65536, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=4, bias=True)
)
)查看模型详情:
# 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 113, 113] 1,728
BatchNorm2d-2 [-1, 64, 113, 113] 128
SiLU-3 [-1, 64, 113, 113] 0
Conv-4 [-1, 64, 113, 113] 0
Conv2d-5 [-1, 128, 57, 57] 73,728
BatchNorm2d-6 [-1, 128, 57, 57] 256
SiLU-7 [-1, 128, 57, 57] 0
Conv-8 [-1, 128, 57, 57] 0
Conv2d-9 [-1, 64, 57, 57] 8,192
BatchNorm2d-10 [-1, 64, 57, 57] 128
SiLU-11 [-1, 64, 57, 57] 0
Conv-12 [-1, 64, 57, 57] 0
Conv2d-13 [-1, 64, 57, 57] 4,096
BatchNorm2d-14 [-1, 64, 57, 57] 128
SiLU-15 [-1, 64, 57, 57] 0
Conv-16 [-1, 64, 57, 57] 0
Conv2d-17 [-1, 64, 57, 57] 36,864
BatchNorm2d-18 [-1, 64, 57, 57] 128
SiLU-19 [-1, 64, 57, 57] 0
Conv-20 [-1, 64, 57, 57] 0
Bottleneck-21 [-1, 64, 57, 57] 0
Conv2d-22 [-1, 64, 57, 57] 8,192
BatchNorm2d-23 [-1, 64, 57, 57] 128
SiLU-24 [-1, 64, 57, 57] 0
Conv-25 [-1, 64, 57, 57] 0
Conv2d-26 [-1, 128, 57, 57] 16,384
BatchNorm2d-27 [-1, 128, 57, 57] 256
SiLU-28 [-1, 128, 57, 57] 0
Conv-29 [-1, 128, 57, 57] 0
C3-30 [-1, 128, 57, 57] 0
Conv2d-31 [-1, 256, 29, 29] 294,912
BatchNorm2d-32 [-1, 256, 29, 29] 512
SiLU-33 [-1, 256, 29, 29] 0
Conv-34 [-1, 256, 29, 29] 0
Conv2d-35 [-1, 128, 29, 29] 32,768
BatchNorm2d-36 [-1, 128, 29, 29] 256
SiLU-37 [-1, 128, 29, 29] 0
Conv-38 [-1, 128, 29, 29] 0
Conv2d-39 [-1, 128, 29, 29] 16,384
BatchNorm2d-40 [-1, 128, 29, 29] 256
SiLU-41 [-1, 128, 29, 29] 0
Conv-42 [-1, 128, 29, 29] 0
Conv2d-43 [-1, 128, 29, 29] 147,456
BatchNorm2d-44 [-1, 128, 29, 29] 256
SiLU-45 [-1, 128, 29, 29] 0
Conv-46 [-1, 128, 29, 29] 0
Bottleneck-47 [-1, 128, 29, 29] 0
Conv2d-48 [-1, 128, 29, 29] 32,768
BatchNorm2d-49 [-1, 128, 29, 29] 256
SiLU-50 [-1, 128, 29, 29] 0
Conv-51 [-1, 128, 29, 29] 0
Conv2d-52 [-1, 256, 29, 29] 65,536
BatchNorm2d-53 [-1, 256, 29, 29] 512
SiLU-54 [-1, 256, 29, 29] 0
Conv-55 [-1, 256, 29, 29] 0
C3-56 [-1, 256, 29, 29] 0
Conv2d-57 [-1, 512, 15, 15] 1,179,648
BatchNorm2d-58 [-1, 512, 15, 15] 1,024
SiLU-59 [-1, 512, 15, 15] 0
Conv-60 [-1, 512, 15, 15] 0
Conv2d-61 [-1, 256, 15, 15] 131,072
BatchNorm2d-62 [-1, 256, 15, 15] 512
SiLU-63 [-1, 256, 15, 15] 0
Conv-64 [-1, 256, 15, 15] 0
Conv2d-65 [-1, 256, 15, 15] 65,536
BatchNorm2d-66 [-1, 256, 15, 15] 512
SiLU-67 [-1, 256, 15, 15] 0
Conv-68 [-1, 256, 15, 15] 0
Conv2d-69 [-1, 256, 15, 15] 589,824
BatchNorm2d-70 [-1, 256, 15, 15] 512
SiLU-71 [-1, 256, 15, 15] 0
Conv-72 [-1, 256, 15, 15] 0
Bottleneck-73 [-1, 256, 15, 15] 0
Conv2d-74 [-1, 256, 15, 15] 131,072
BatchNorm2d-75 [-1, 256, 15, 15] 512
SiLU-76 [-1, 256, 15, 15] 0
Conv-77 [-1, 256, 15, 15] 0
Conv2d-78 [-1, 512, 15, 15] 262,144
BatchNorm2d-79 [-1, 512, 15, 15] 1,024
SiLU-80 [-1, 512, 15, 15] 0
Conv-81 [-1, 512, 15, 15] 0
C3-82 [-1, 512, 15, 15] 0
Conv2d-83 [-1, 1024, 8, 8] 4,718,592
BatchNorm2d-84 [-1, 1024, 8, 8] 2,048
SiLU-85 [-1, 1024, 8, 8] 0
Conv-86 [-1, 1024, 8, 8] 0
Conv2d-87 [-1, 512, 8, 8] 524,288
BatchNorm2d-88 [-1, 512, 8, 8] 1,024
SiLU-89 [-1, 512, 8, 8] 0
Conv-90 [-1, 512, 8, 8] 0
Conv2d-91 [-1, 512, 8, 8] 262,144
BatchNorm2d-92 [-1, 512, 8, 8] 1,024
SiLU-93 [-1, 512, 8, 8] 0
Conv-94 [-1, 512, 8, 8] 0
Conv2d-95 [-1, 512, 8, 8] 2,359,296
BatchNorm2d-96 [-1, 512, 8, 8] 1,024
SiLU-97 [-1, 512, 8, 8] 0
Conv-98 [-1, 512, 8, 8] 0
Bottleneck-99 [-1, 512, 8, 8] 0
Conv2d-100 [-1, 512, 8, 8] 524,288
BatchNorm2d-101 [-1, 512, 8, 8] 1,024
SiLU-102 [-1, 512, 8, 8] 0
Conv-103 [-1, 512, 8, 8] 0
Conv2d-104 [-1, 1024, 8, 8] 1,048,576
BatchNorm2d-105 [-1, 1024, 8, 8] 2,048
SiLU-106 [-1, 1024, 8, 8] 0
Conv-107 [-1, 1024, 8, 8] 0
C3-108 [-1, 1024, 8, 8] 0
Conv2d-109 [-1, 512, 8, 8] 524,288
BatchNorm2d-110 [-1, 512, 8, 8] 1,024
SiLU-111 [-1, 512, 8, 8] 0
Conv-112 [-1, 512, 8, 8] 0
MaxPool2d-113 [-1, 512, 8, 8] 0
MaxPool2d-114 [-1, 512, 8, 8] 0
MaxPool2d-115 [-1, 512, 8, 8] 0
Conv2d-116 [-1, 1024, 8, 8] 2,097,152
BatchNorm2d-117 [-1, 1024, 8, 8] 2,048
SiLU-118 [-1, 1024, 8, 8] 0
Conv-119 [-1, 1024, 8, 8] 0
SPPF-120 [-1, 1024, 8, 8] 0
Linear-121 [-1, 100] 6,553,700
ReLU-122 [-1, 100] 0
Linear-123 [-1, 4] 404
================================================================
Total params: 21,729,592
Trainable params: 21,729,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 137.59
Params size (MB): 82.89
Estimated Total Size (MB): 221.06
----------------------------------------------------------------
None三、训练函数
3.1 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss3.2 编写测试函数
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss3.3 正式训练
import copy
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 60
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(best_model.state_dict(), PATH)
print('Done')运行结果:
cpu
cpu
Epoch: 1, Train_acc:53.0%, Train_loss:1.110, Test_acc:64.4%, Test_loss:0.690, Lr:1.00E-04
cpu
cpu
Epoch: 2, Train_acc:60.8%, Train_loss:0.851, Test_acc:60.4%, Test_loss:0.783, Lr:1.00E-04
cpu
cpu
Epoch: 3, Train_acc:68.3%, Train_loss:0.723, Test_acc:74.7%, Test_loss:0.628, Lr:1.00E-04
cpu
cpu
Epoch: 4, Train_acc:73.4%, Train_loss:0.634, Test_acc:75.6%, Test_loss:0.455, Lr:1.00E-04
cpu
cpu
Epoch: 5, Train_acc:74.4%, Train_loss:0.598, Test_acc:76.0%, Test_loss:0.554, Lr:1.00E-04
cpu
cpu
Epoch: 6, Train_acc:76.8%, Train_loss:0.578, Test_acc:81.3%, Test_loss:0.403, Lr:1.00E-04
cpu
cpu
Epoch: 7, Train_acc:80.4%, Train_loss:0.480, Test_acc:83.6%, Test_loss:0.359, Lr:1.00E-04
cpu
cpu
Epoch: 8, Train_acc:82.4%, Train_loss:0.450, Test_acc:82.7%, Test_loss:0.423, Lr:1.00E-04
cpu
cpu
Epoch: 9, Train_acc:82.6%, Train_loss:0.403, Test_acc:89.3%, Test_loss:0.275, Lr:1.00E-04
cpu
cpu
Epoch:10, Train_acc:86.8%, Train_loss:0.345, Test_acc:87.6%, Test_loss:0.373, Lr:1.00E-04
cpu
cpu
Epoch:11, Train_acc:87.1%, Train_loss:0.319, Test_acc:91.6%, Test_loss:0.240, Lr:1.00E-04
cpu
cpu
Epoch:12, Train_acc:88.3%, Train_loss:0.296, Test_acc:84.0%, Test_loss:0.408, Lr:1.00E-04
cpu
cpu
Epoch:13, Train_acc:88.6%, Train_loss:0.284, Test_acc:77.8%, Test_loss:0.519, Lr:1.00E-04
cpu
cpu
Epoch:14, Train_acc:91.9%, Train_loss:0.242, Test_acc:89.8%, Test_loss:0.246, Lr:1.00E-04
cpu
cpu
Epoch:15, Train_acc:93.0%, Train_loss:0.193, Test_acc:89.8%, Test_loss:0.316, Lr:1.00E-04
cpu
cpu
Epoch:16, Train_acc:92.2%, Train_loss:0.201, Test_acc:85.3%, Test_loss:0.451, Lr:1.00E-04
cpu
cpu
Epoch:17, Train_acc:90.6%, Train_loss:0.229, Test_acc:86.7%, Test_loss:0.535, Lr:1.00E-04
cpu
cpu
Epoch:18, Train_acc:92.3%, Train_loss:0.198, Test_acc:80.4%, Test_loss:0.586, Lr:1.00E-04
cpu
cpu
Epoch:19, Train_acc:92.6%, Train_loss:0.196, Test_acc:90.2%, Test_loss:0.251, Lr:1.00E-04
cpu
cpu
Epoch:20, Train_acc:94.8%, Train_loss:0.155, Test_acc:90.7%, Test_loss:0.223, Lr:1.00E-04
cpu
cpu
Epoch:21, Train_acc:95.2%, Train_loss:0.132, Test_acc:90.7%, Test_loss:0.282, Lr:1.00E-04
cpu
cpu
Epoch:22, Train_acc:95.9%, Train_loss:0.121, Test_acc:79.6%, Test_loss:0.744, Lr:1.00E-04
cpu
cpu
Epoch:23, Train_acc:96.8%, Train_loss:0.102, Test_acc:92.9%, Test_loss:0.183, Lr:1.00E-04
cpu
cpu
Epoch:24, Train_acc:97.1%, Train_loss:0.083, Test_acc:87.6%, Test_loss:0.380, Lr:1.00E-04
cpu四、完整代码
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
import os,PIL,random,pathlib
def main():
data_dir = 'D:/P8/weather_photos/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
print(classeNames)
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder("D:/P8/weather_photos/",transform=train_transforms)
print(total_data)
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset, test_dataset)
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
import torch.nn.functional as F
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)# 定义卷积层
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
"""
这个是YOLOv5, 6.0版本的主干网络,这里进行复现
(注:有部分删改,详细讲解将在后续进行展开)
"""
class YOLOv5_backbone(nn.Module):
def __init__(self):
super(YOLOv5_backbone, self).__init__()
self.Conv_1 = Conv(3, 64, 3, 2, 2)
self.Conv_2 = Conv(64, 128, 3, 2)
self.C3_3 = C3(128,128)
self.Conv_4 = Conv(128, 256, 3, 2)
self.C3_5 = C3(256,256)
self.Conv_6 = Conv(256, 512, 3, 2)
self.C3_7 = C3(512,512)
self.Conv_8 = Conv(512, 1024, 3, 2)
self.C3_9 = C3(1024, 1024)
self.SPPF = SPPF(1024, 1024, 5)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=65536, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self, x):
x = self.Conv_1(x)
x = self.Conv_2(x)
x = self.C3_3(x)
x = self.Conv_4(x)
x = self.C3_5(x)
x = self.Conv_6(x)
x = self.C3_7(x)
x = self.Conv_8(x)
x = self.C3_9(x)
x = self.SPPF(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = YOLOv5_backbone().to(device)
print(model)
# 统计模型参数量以及其他指标
import torchsummary as summary
print(summary.summary(model, (3, 224, 224)))
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
import copy
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 60
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(best_model.state_dict(), PATH)
print('Done')
if __name__ == '__main__':
main()torch.save(model.state_dict(), PATH) 和 torch.save(model, PATH) 之间有很大的区别:
-
torch.save(model.state_dict(), PATH)保存的是模型的参数字典(state_dict),而不是整个模型对象。这意味着只有模型的权重和偏置等参数会被保存,而模型的结构、图层和其他属性不会被保存。这种方式通常用于保存和加载模型的参数,而不包括模型的结构。 -
torch.save(model, PATH)保存的是整个模型对象,包括模型的结构、图层、参数和其他属性。这意味着整个模型的状态都会被保存,包括模型的结构和权重。这种方式通常用于保存和加载完整的模型,包括模型的结构和参数。
copy.deepcopy(model)
copy.deepcopy(model): 这部分代码使用 Python 的 copy.deepcopy 函数创建了模型的深度拷贝。这意味着它会复制整个模型对象,包括模型的架构、权重、参数等。通常情况下,这用于创建一个独立的模型副本,以便进一步的处理或修改,而不会影响原始模型或其他引用。






![博华网龙设备命令执行漏洞复现 [附POC]](https://img-blog.csdnimg.cn/69540ab6a8594d1b9506775af030d445.png)