目录
目录
前言
一. GC (垃圾回收机制)
STW问题
二. GC 回收哪部分内存
三. 具体怎么回收
1. 先找出垃圾
a.引用计数
b. 可达性分析
2. 回收垃圾
a. 标记清除
b. 复制算法
c. 标记整理
d. 分代回收
前言
我们都知道 Java 运行时内存的各个区域. 对于程序计数器 虚拟机栈 本地方法栈 这三部分区域而言, 他的生命周期与相关线程有关, 随线程而生, 随线程而灭. 并且这三个区域的内存分配与回收具有确定性, 因为当方法结束或者线程结束时, 内存就自然跟着线程回收了.
那我们的 JVM 到底是怎么进行回收的呢? 又是怎么判断需要回收的呢?
下面我们来看看.
一. GC (垃圾回收机制)
在开始学习C语言的时候, 我们知道, 在C语言里, 创建内存有两种方式:
- 直接定义变量, 变量就对应了内存空间. (出来作用域, 内存释放的时机是确定的)
- malloc 申请内存 (动态内存申请), 还必须要通过 free 来进行内存释放, 如果不手动进行内存释放的话, 这块内存会一直持续到程序结束.
而手动释放, 问题就来了, 我们很有可能会忘记, 这就会造成内存泄露.
这个时候大佬程序猿们就想出了 GC(垃圾回收), 这是个主流方案.
程序猿只需要复制申请内存, 释放内存的工作, 就交给 JVM 来完成. JVM 会自动判定当前的内存是否需要释放, 如果 JVM 认为这个内存不需要使用了, 那么就将他释放掉.
STW问题
GC 中最大的问题, STW问题(Stop the world)
这个问题就好像, 你在家打LOL, 马上打团了, 你老妈叫你给他拿个东西给他, 你给她拿东西这段时间肯定不能操作打团啊, 等你拿完东西回来, 黄花菜都凉了, 团战输了都.
反应在用户这里的话, 就是会造成卡顿的现象.
二. GC 回收哪部分内存
JVM主要内存分为: 堆 方法区 栈 程序计数器这四个部分.
其中, GC 主要就是针对 堆 来进行垃圾回收, 方法区的话加载类对象, 加载之后也不太会回收, 对于栈来说的话, 他释放的时机是确定的, 也不需要回收, 对于程序计数器, 他有固定的内存空间, 也不需要回收.
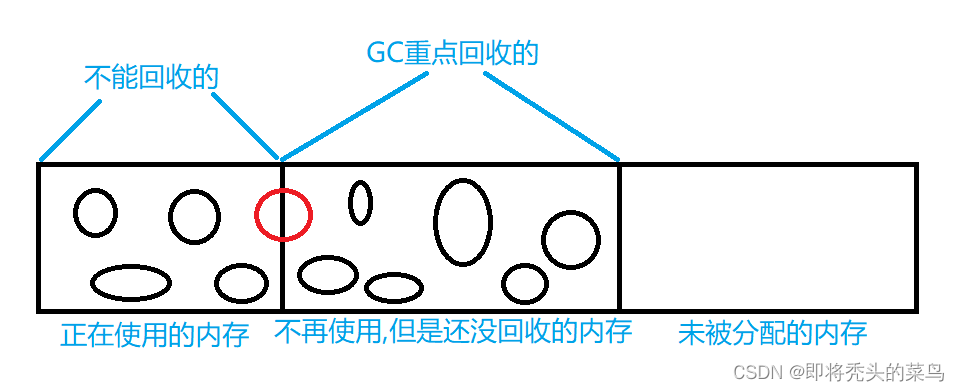
那个红色的圆圈代表, 这个对象, 一半的内存正在使用, 一半的内存不再使用了. 这种情况不会回收, 会等待这个对象彻底不用了, 才会进行回收!!
GC 回收内存, 不是以 "字节" 为单位, 是以 "对象" 为单位.
三. 具体怎么回收
1. 先找出垃圾
如果一个对象再也不用了, 就说明是垃圾了. 在 Java 中, 对象的使用, 需要凭借 引用. 假设一个对象, 已经没有任何引用指向它了, 那么这个对象就无法再被使用了, 就能被回收了.
有两种判断对象是否存在引用的方法:
a.引用计数
引用计数法不是JVM采用的方法, Python 和 PHP 用的这个方法.
引用计数描述的方法: 给每个对象增加一个引用计数器, 每当有一个地方引用它时, 计数器就+1; 当引用失效时, 计数器就-1; 任何时刻计数器为 0 的对象就是不能再被使用的, 即对象已 "死".
很容易的就能看出引用计数的优点: 简单, 容易实现, 执行效率也高.
这么一看, 好像这方法很不错啊, 那为什么我们的JVM不采用这种方法呢?
最主要的原因就是引用计数法无法解决对象循环引用的问题, 次要原因是空间利用率低, 尤其是小对象.
举个例子: 比如计数器是个int, 如果你的对象本身里面只有一个int成员, 占4个字节就可以了, 但是现在还要存一个计数器, 需要8个字节了, 如果当对象数量过大的时候, 这样就会浪费很多内存空间.
来看下面这段代码:
class Test {
Test x;
}
Test A = new Test();
Test B = new Test();
现在内存空间里, 是这样的, 下面我们进行这些动作:
a.x = b;
b.x = a;那么现在, 计数器对应的就是两次引用.
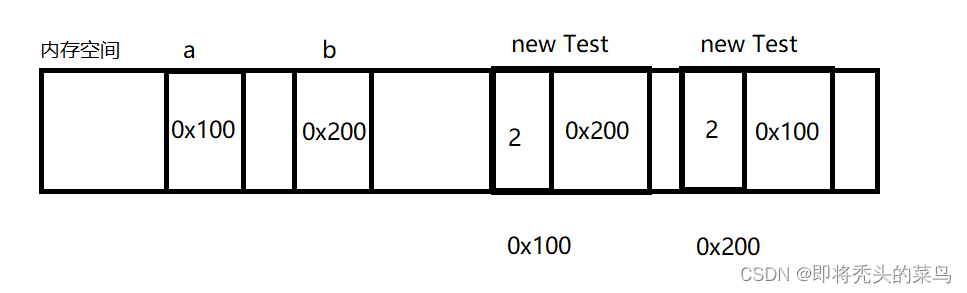
再然后我们这么做:
a = null;
b = null;它本身对应的值就变成了null, 它所对应的引用计数也会-1, 变成1.

到这个时候, 虽然这俩对象引用计数唯一, 但是实际上是两个对象在相互引用, 此时, 外界的代码无法访问和使用这俩对象的, 而又由于引用计数不为0, 这俩对象又无法进行释放, 问题就出现了.
b. 可达性分析
JVM采用的这个方法.
约定一些特殊的变量, 成为 "GC roots". 每隔一段时间, 从 GC roots 出发, 进行遍历, 看当前那些变量能被访问到, 能被访问到的变量就称为 "可达", 否则称为 "不可达".
GC roots 呢, 在Java里面约定了这些:
- 栈上的变量.
- 常量池引用的对象.
- 方法区里, 引用类型的静态变量.
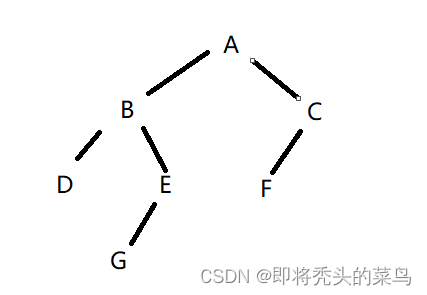
就像二叉树一样, 知道了根节点之后, 我们可以顺藤摸瓜找他的子节点. root.left 就能访问到 B, root.right 就能访问到 C. 通过这种 root. 的方式访问到的对象就是可达的, 假设这个时候我们把 A 和 C之间的连接断开, 那么 root.right 就访问不到C了, 此时C 和 F 就不可达了, 就是垃圾了.
找到垃圾之后我们下面我们来看具体怎么回收垃圾的.
2. 回收垃圾
a. 标记清除
假设现在有这样一块内存空间, 其中标记颜色的就是垃圾.

标记出垃圾之后, 直接把对象对应的内存空间进行释放了, 蓝色的部分就是已经释放的内存空间.
这样的方法最大的问题就是: 会产生内存碎片.
例如上图, 假设每个蓝色的区域是1k的空间, 这个时候就有4k的空闲空间, 但是由于空间是分散的, 我们申请就不能申请例如2k啊 3k的连续内存空间.
b. 复制算法
复制算法就是针对上述所说的内存碎片问题引入的方法了.
假设有这么一块内存区域, 他被划分成了两半, 其中标号的就是对象, 我们使用一侧空间的时候, 另一半空间是不使用的, 在垃圾回收的使用才使用.

假设我们使用了2号和4号内存空间之后需要回收这两块空间, 这个时候就不再是原地释放内存占用了, 而是先把"非垃圾" (还能继续使用的对象, 也就是图中未标色的三个区域) 拷贝到另一侧, 然后再把之前整个这一半给释放掉.
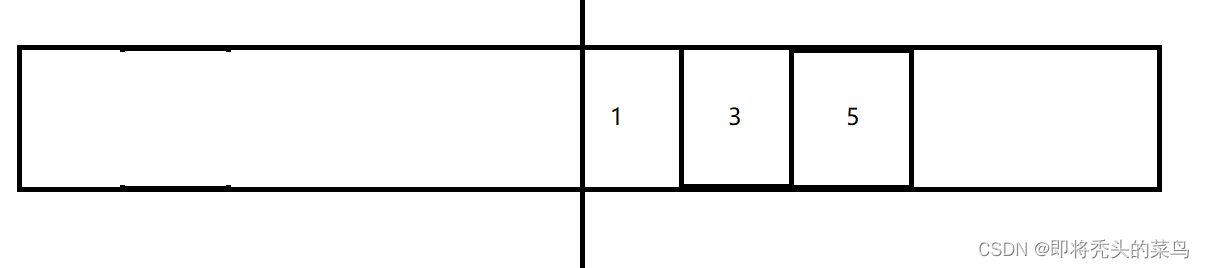
这样内存碎片的问题就得到了妥善的解决, 但是呢, 复制算法的缺点一样很明显, 空间利用率更低了(用一半丢一半), 如果一轮 GC下来, 大部分的对象要保留下来, 只有少数几个对象要回收, 这个时候拷贝的开销就很大了.
c. 标记整理
类似于 顺序表 删除元素进行的搬运操作.
 假设还是蓝色的区域是需要清除的垃圾, 这里进行搬运操作就是清除垃圾区域, 然后把 "非垃圾" 区域搬运到前面区. 如下图:
假设还是蓝色的区域是需要清除的垃圾, 这里进行搬运操作就是清除垃圾区域, 然后把 "非垃圾" 区域搬运到前面区. 如下图:

这个方法相对于上述的复制算法来说, 空间利用率提升了, 并且也能解决内存碎片的问题, 但是搬运操作也是毕竟耗费时间的.
d. 分代回收
前面的三种方法都存在一点问题, 这个时候就引入了 "分代回收" 策略, 把上面的方法综合了一下, 根据对象不同的特点, 来采取不同的回收方式.
根据对象年龄来划分的.
依据 GC 的轮次来计算的, 假设在一组线程里, 周期性的扫描代码里的对象, 如果一个对象, 经历了一次GC, 没有被回收, 就认为是年龄 +1.
基于上述内容, 就针对对象的年龄进行了分类, 把堆里的对象分成了 新生代(年龄小的对象), 老年代(年龄大的对象). 对于新生代 GC 扫描的频率更高, 而对于老年代 GC 扫描的的频率要低一些.
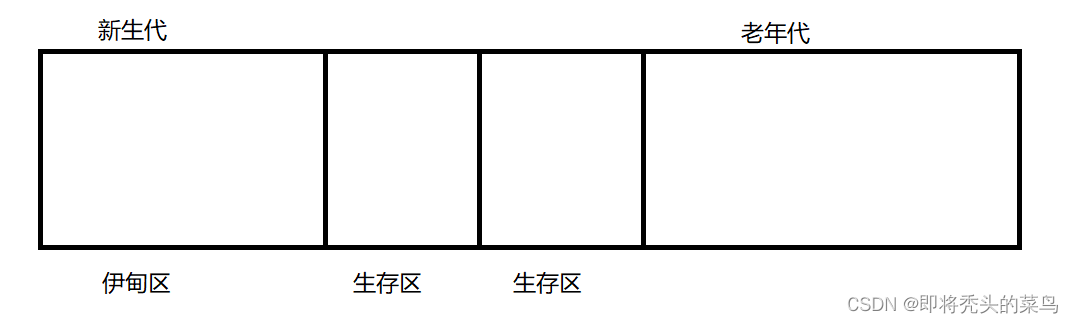
规则:
刚创建出来的新对象, 就进入伊甸区, 如果这些新对象经过一轮GC, 还没被回收, 就通过复制算法, 复制到 生存区 里去. 生存区里的对象呢, 没经过一轮GC, 继续通过复制算法拷贝到另外一个生存区里去, 只要这个对象不消亡, 那么就会在这个两个生存区之间来回拷贝, 反复横跳, 但是我们要知道的是, 每一轮拷贝, 没一轮GC都是会筛选掉一大波对象的. 如果一个对象在生存区反复横跳了很多次还没回收的话, 那么就会进入 老年代了, 进入老年代之后也会继续定期进行GC, 只是频率变低了, 这里采取的是标记整理的方法来清除老年代的对象了.
然后上述规则还有一个特殊情况, 如果对象是一个非常大的对象, 那么就直接进入老年代, 原因很简单, 你耗费这么大力气创建的对象, 肯定不是立即销毁的.